现在test表有三个字段 用户: user_id 日期:dt 订单金额 price,
计算出一个消费者历史上“首次”在近30天周期内累计消费金额达到1W的日期
(1)数据准备
create table test as
select 'a' as user_id,7000 as price,'2022-07-01' as dt
union all
select 'a' as user_id,4000 as price,'2022-08-22' as dt
union all
select 'a' as user_id,8000 as price,'2022-08-23' as dt
(2) 分析
目标字段:消费者,日期
条件:首次”在近30天周期内累计消费金额达到1W的日期
第一步:如何求近30天周期内累计消费金额
一般此类问题我们容易想到如下解法
sum(price) over(partition by user_id order by dt rows between prceding 30 and current row)但是改解法有个问题,我们采用rows的时候计算的是实际物理行数,但是实际数据中用户的时间并不是连续的,也就是存在时间断层或缺失的现象,此时用rows计算的实际结果则会偏大,显然不对。而对于hive的计算引擎提供了,range计算方法,他表示的是排序行的逻辑计算值,并在此范围内的所有数据,即[dt -30,dt],刚好反应了所要表达的意思,近30天的结果。因此可以按照如下求法
sum(price) over(partition by user_id order by cast (dt as date) range between prceding 30 and current row)第二步:求首次日期
首次:min(dt) --最早
拓展:最近、最新、末次日期max(dt)
完整的SQL如下:
select user_id,min(dt)
from (
select dt
, user_id
, sum(price)
over (partition by user_id order by cast(dt as date) range between 30 preceding and current row) as order_price
from (select 'a' as user_id, 7000 as price, '2022-07-01' as dt
union all
select 'a' as user_id, 4000 as price, '2022-08-22' as dt
union all
select 'a' as user_id, 8000 as price, '2022-08-23' as dt
) t
) t
where order_price > 10000
group by user_id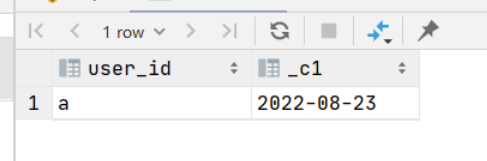
对比rows求得结果:
select user_id, min(dt)
from (
select dt
, user_id
, sum(price)
over (partition by user_id order by dt rows between 30 preceding and current row) as order_price
from (select 'a' as user_id, 7000 as price, '2022-07-01' as dt
union all
select 'a' as user_id, 4000 as price, '2022-08-22' as dt
union all
select 'a' as user_id, 8000 as price, '2022-08-23' as dt
) t
) A
where order_price > 10000
group by user_id
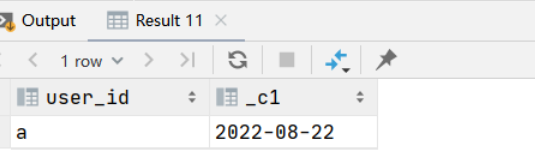
明显rows求得的结果不对,2022-07-01日期就不在2022-08-22近30天日期范围内
中间结果如下:
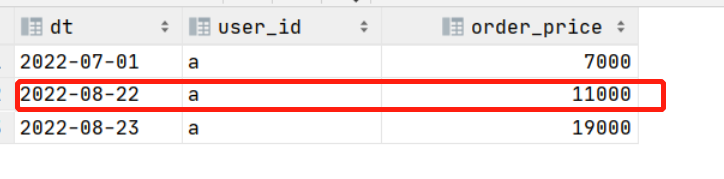
对于有的数据库没有range函数的,此时如何求呢?我们可以借助时间维度表去补全日期数据,这也是常见的通用方法,比如我们有一张日期全的维度表dim_date
可以看出日期是连续的,由于partition by 后需要按照用户(user_id)分组,所以用户的维度需要补齐在时间维度表中,这种补齐维度的操作我们一般采用自关联SQL如下:
with data as
(select 'a' as user_id, 7000 as price, '2022-07-01' as dt
union all
select 'a' as user_id, 4000 as price, '2022-08-22' as dt
union all
select 'a' as user_id, 8000 as price, '2022-08-23' as dt
)
,dim_user AS
(select 'a' user_id
UNION ALL
select 'b' user_id
UNION ALL
select 'c' user_id
)
select *
from
( select d.date_id, u.user_id
from (select date_id
from dim.dim_date
where date_format(date_id, 'yyyy-MM') >= '2022-06'
) d,
dim_user u
) d
具体结果如下:
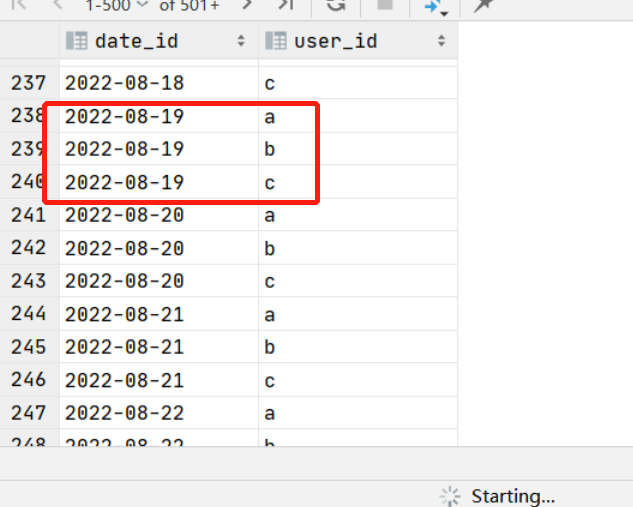
可以看出每个时间记录上,都得到了相应用户的维度值。
最后我们用该表作为主表left join数据表,通过关联条件将数据唯一对应过来
with data as
(select 'a' as user_id, 7000 as price, '2022-07-01' as dt
union all
select 'a' as user_id, 4000 as price, '2022-08-22' as dt
union all
select 'a' as user_id, 8000 as price, '2022-08-23' as dt
)
,dim_user AS
(select 'a' user_id
UNION ALL
select 'b' user_id
UNION ALL
select 'c' user_id
)
select *
from
( select d.date_id, u.user_id
from (select date_id
from dim.dim_date
where date_format(date_id, 'yyyy-MM') >= '2022-06'
) d,
dim_user u
) d
left join data
on d.date_id = data.dt and d.user_id=data.user_id具体结果如下:
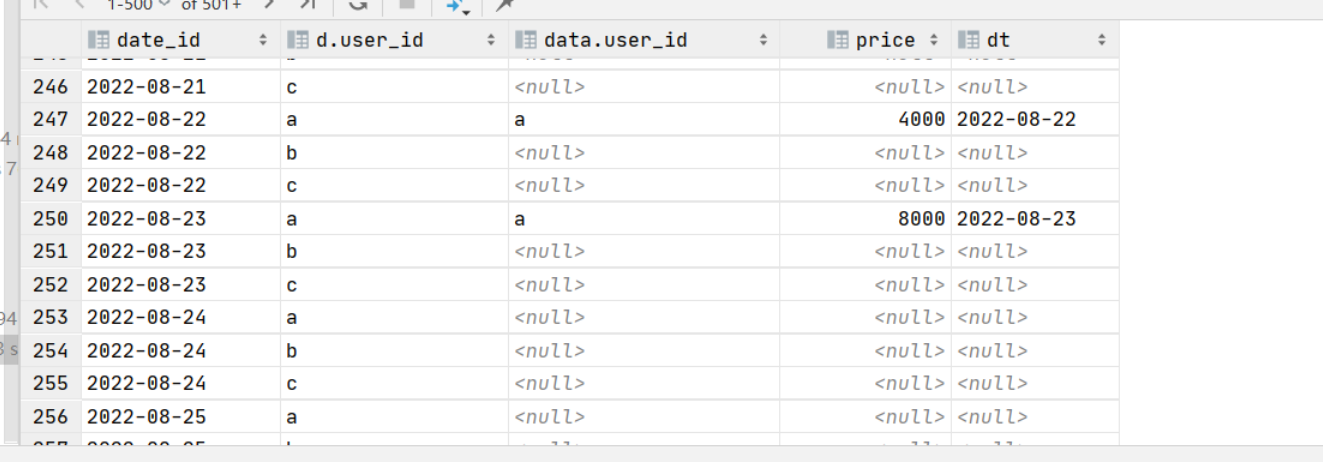
我们可以看到主表是比较全的维表,拥有所有的时间、用户属性,order by 后的日期应该是维表中的日期,partition by后的user_id应该为主表中的user_id,此时再用rows 求解就没有问题。
最终SQL如下:
with data as
(select 'a' as user_id, 7000 as price, '2022-07-01' as dt
union all
select 'a' as user_id, 4000 as price, '2022-08-22' as dt
union all
select 'a' as user_id, 8000 as price, '2022-08-23' as dt
)
,dim_user AS
(select 'a' user_id
UNION ALL
select 'b' user_id
UNION ALL
select 'c' user_id
)
select user_id, min(dt)
from (
select dt
, d.user_id
, sum(price)
over (partition by d.user_id order by d.date_id rows between 30 preceding and current row) as order_price
from (
select d.date_id, u.user_id
from (select date_id
from dim.dim_date
where date_format(date_id, 'yyyy-MM') >= '2022-06'
) d,
dim_user u
) d
left join data
on d.date_id = data.dt and d.user_id=data.user_id
) A
where order_price > 10000
group by user_id可以看出最终求解的结果值和range的结果是一致 的。
小结:是否需要补全其他维度值,看partition by后的分组字段,有多少个就需要补全哪些,因为直接用时间维度表做主表,partition by无法正确分组,需要补全 后面的分组字段才行。改方法性能上肯定比较差,但也是比较通用的方法,对于一些窗口不支持range子句的则也只能采取这样的方法。
本文讲解了一种求近30天消费金额的方法,给出了2种思路,2种方法都比较通用,都需要掌握。
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
给定这段代码defcreate@upgrades=User.update_all(["role=?","upgraded"],:id=>params[:upgrade])redirect_toadmin_upgrades_path,:notice=>"Successfullyupgradeduser."end我如何在该操作中实际验证它们是否已保存或未重定向到适当的页面和消息? 最佳答案 在Rails3中,update_all不返回任何有意义的信息,除了已更新的记录数(这可能取决于您的DBMS是否返回该信息)。http://ar.ru
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
我需要从一个View访问多个模型。以前,我的links_controller仅用于提供以不同方式排序的链接资源。现在我想包括一个部分(我假设)显示按分数排序的顶级用户(@users=User.all.sort_by(&:score))我知道我可以将此代码插入每个链接操作并从View访问它,但这似乎不是“ruby方式”,我将需要在不久的将来访问更多模型。这可能会变得很脏,是否有针对这种情况的任何技术?注意事项:我认为我的应用程序正朝着单一格式和动态页面内容的方向发展,本质上是一个典型的网络应用程序。我知道before_filter但考虑到我希望应用程序进入的方向,这似乎很麻烦。最终从任何
我想要做的是有2个不同的Controller,client和test_client。客户端Controller已经构建,我想创建一个test_clientController,我可以使用它来玩弄客户端的UI并根据需要进行调整。我主要是想绕过我在客户端中内置的验证及其对加载数据的管理Controller的依赖。所以我希望test_clientController加载示例数据集,然后呈现客户端Controller的索引View,以便我可以调整客户端UI。就是这样。我在test_clients索引方法中试过这个:classTestClientdefindexrender:template=>