文章目录
简单来讲,半加器不考虑低位进位来的进位值,只有两个输入,两个输出。由一个与门和异或门构成.
真值表:
| 输入 | 输出 | ||
|---|---|---|---|
| A | B | C | S |
| 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 |
| 1 | 0 | 0 | 1 |
| 1 | 1 | 1 | 0 |
半加器不考虑低位向本位的[进位],因此它不属于[时序逻辑电路],有两个输入端和两个输出。
设加数(输入端)为A、B ;和为S ;向高位的进位为Ci+1
逻辑表达式:
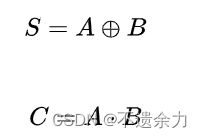
verilog 数据流级描述:
//半加器模块
module adder_half( input wire a,
input wire b,
output reg sum,
output reg cout);
always @(*)
begin
sum = a ^ b;
cout = a & b;
end
endmodule
RTL电路
全加器比半加器多了一位进位:
输入:A、B、Ci-1
输出:S、Ci
真值表:
| 输入 | 输出 | |||
|---|---|---|---|---|
| Ci-1 | Ai | Bi | Si | Ci |
| 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 1 | 1 | 0 |
| 0 | 1 | 0 | 1 | 0 |
| 0 | 1 | 1 | 0 | 1 |
| 1 | 0 | 0 | 1 | 0 |
| 1 | 0 | 1 | 0 | 1 |
| 1 | 1 | 0 | 0 | 1 |
| 1 | 1 | 1 | 1 | 1 |
一位全加器的表达式如下:
Si=Ai⊕Bi⊕Ci-1
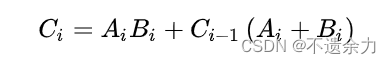
第二个表达式也可用一个异或门来代替或门对其中两个输入信号进行求和:
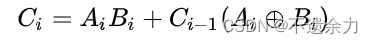
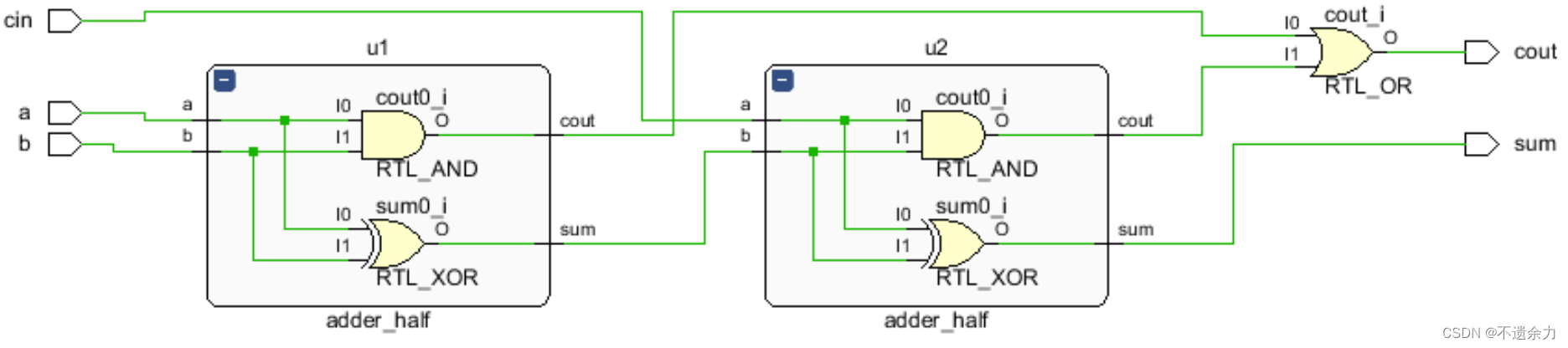
verilog代码实现一(用两个半加器和一个或门实现一个全加器)结构性描述:
//full_adder
module adder_full(a,b,cin,,cout,sum);
input a,b,cin;
output cout,sum;
wire w1,w2,w3;
adder_half u1(.a(a),.b(b),.sum(w1),.cout(w2));
adder_half u2(.a(cin),.b(w1),.sum(sum),.cout(w3));
assign cout = w2 | w3;
endmodule
结构性描述的RTL电路
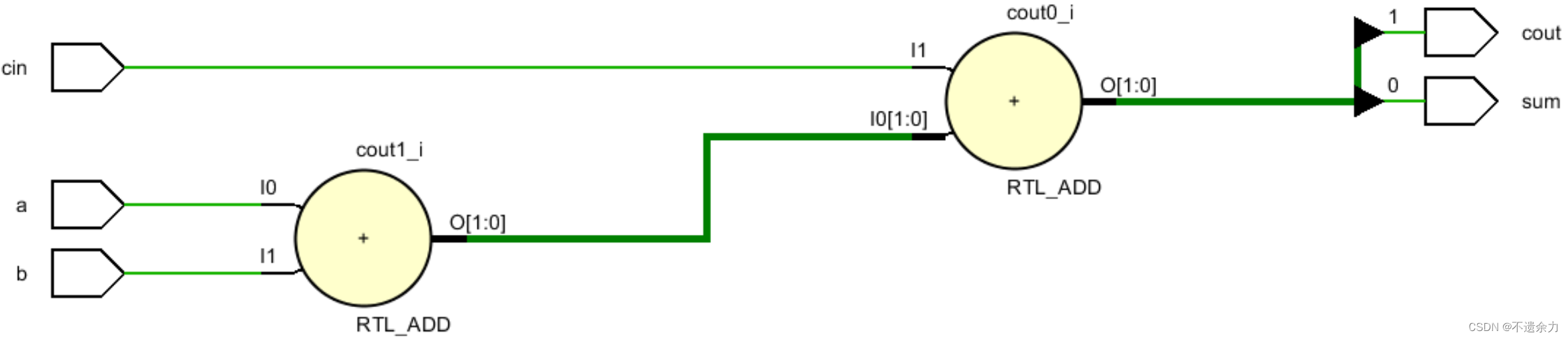
2.verilog代码实现二行为级描述:
//full_adder
module adder_full(a,b,cin,,cout,sum);
input a,b,cin;
output cout,sum;
assign {cout,sum} = a+b+cin;
endmodule
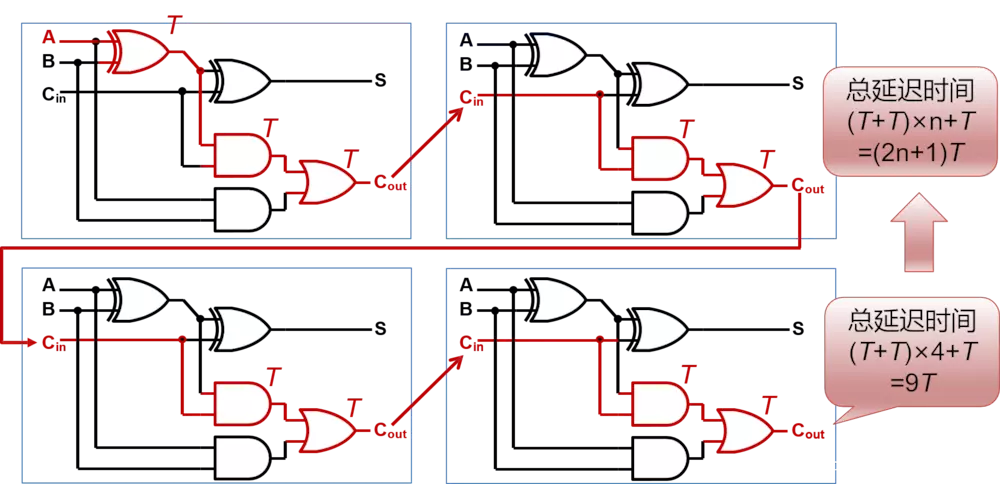
其关键路径如图中红线所示:则其延迟时间为(T+T)*4+T=9T。假设经过一个门电路的延迟时间为T。
对于一个n bit的行波加法器,其延时为(T+T)*n+T=(2n+1)T。
超前进位加法器(Carry-lookahead adder [1] )是对普通的全加器进行改良而设计成的并行加法器,主要是针对普通全加器串联时互相进位产生的延迟进行了改良。超前进位加法器是通过增加了一个不是十分复杂的逻辑电路来做到这点的
Si=Ai⊕Bi⊕Ci-1
考虑每一级的进位:
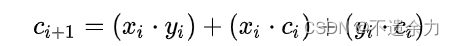
下面简述超前进位加法器的主要原理。我们先来考虑构成[多位加法器]的单个全加器从其低一位获得的进位[信号],我们可以将它变换为
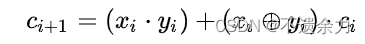
现在为二级制数的每一位[构建]两个新[信号]:
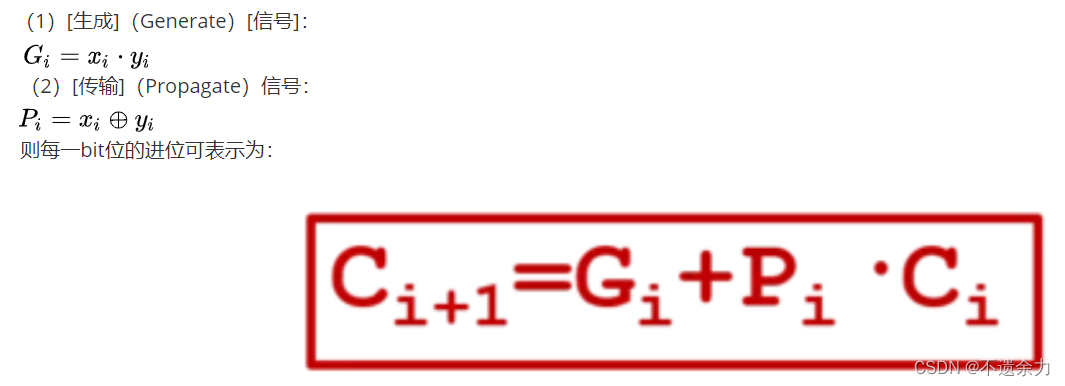
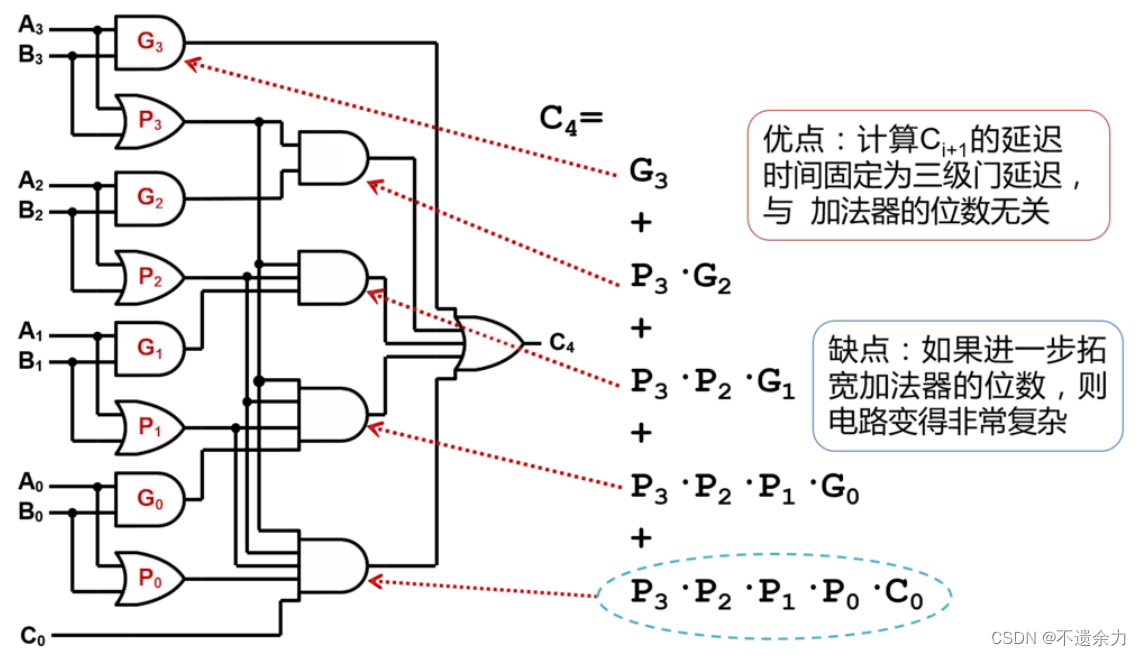
则对于4 bit的加法器,每个进位如下,可以看出,每个进位都不需要等待地位,直接计算可以得到。由此我们得到了提前计算进位输出的方法, 用这样的方法实现了加法器就被称为超前进位加法器
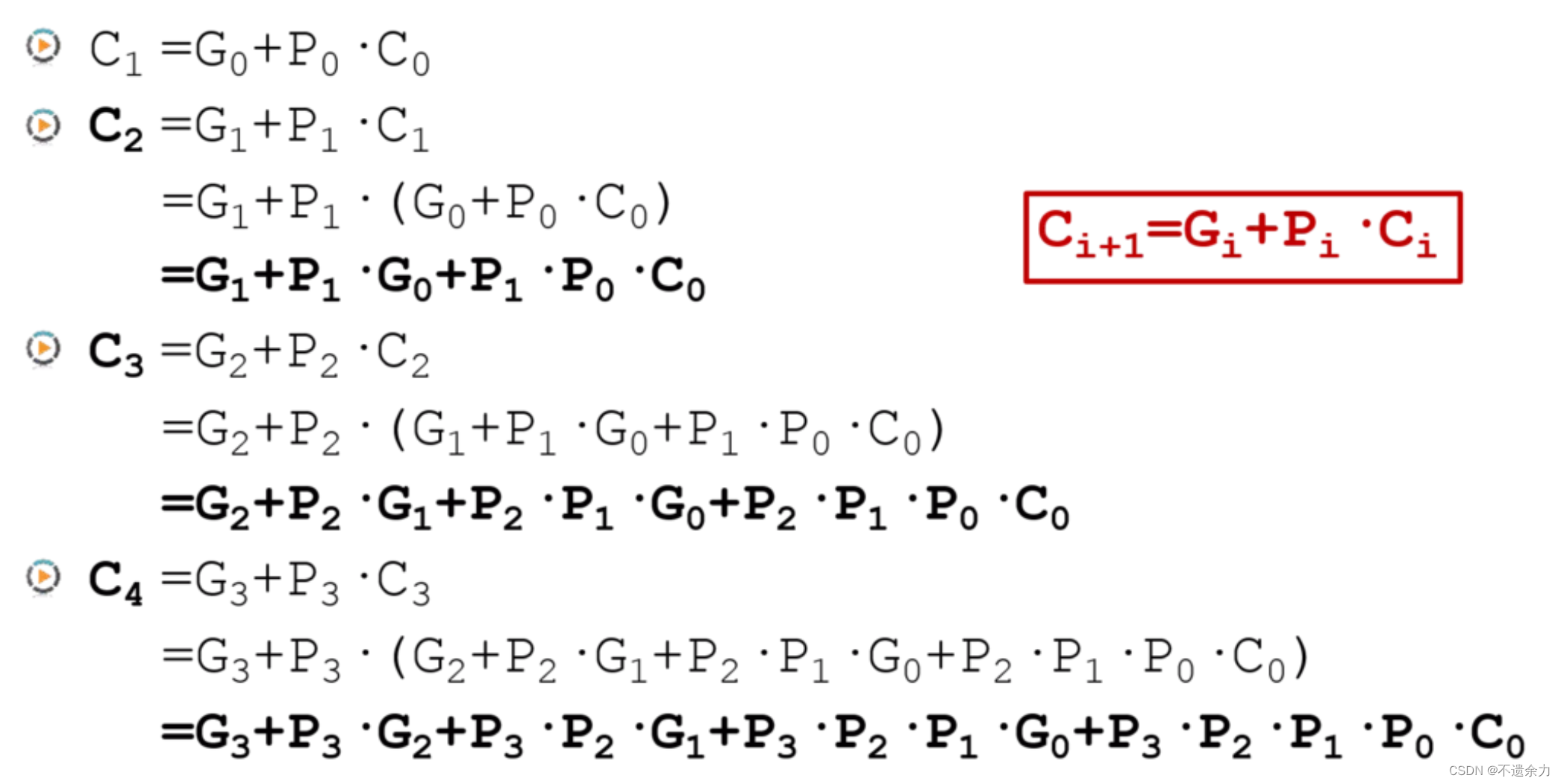
其组合电路如下:
进位延时只有三个门的延时,加上最后一级全加器的延时,最多四个延时时间。
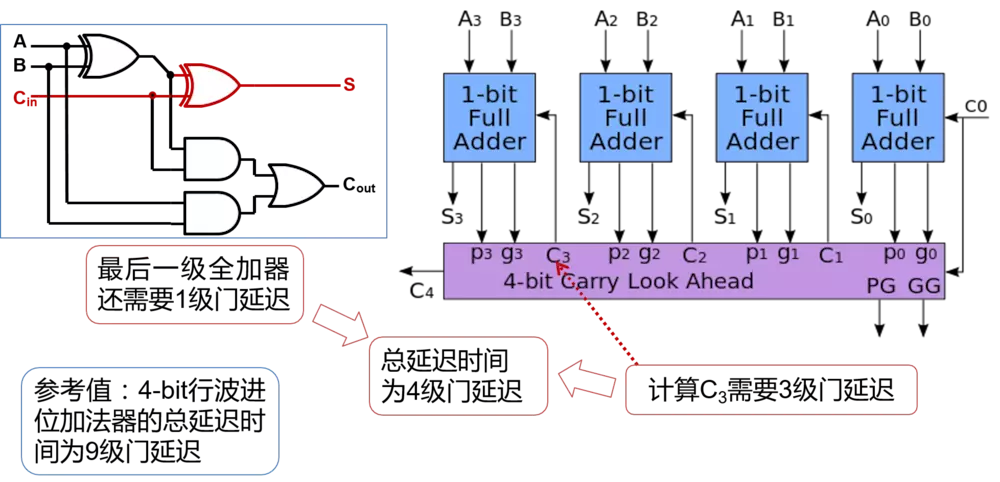
最关键的是:生成每个bit的进位信号、将进位信号进行依次合并
Si=Ai⊕Bi⊕Ci-1
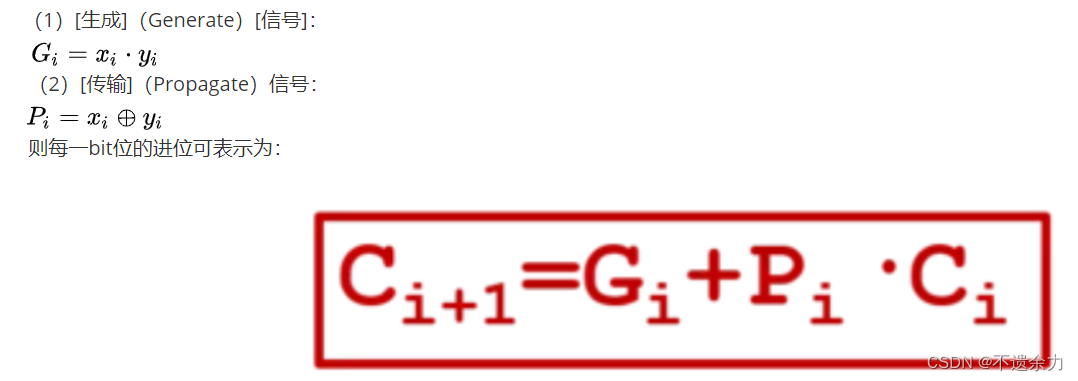
出于好奇,为什么在注入(inject)/归约方法中将累加器称为memo?它的命名背后有什么背景/历史吗?它实际上是指“备忘录”还是备忘录代表什么?http://ruby-doc.org/core-2.0/Enumerable.html#method-i-injecthttp://ruby-doc.org/core-2.0/Enumerable.html#method-i-reduce 最佳答案 “memo”表示在内存中,注入(inject)在整个迭代过程中使用来保存中间对象状态,以便在下一次迭代中使用它。
VHDL程序结构:条件语句if_then_else_endif数据类型BIT类型(取逻辑位’1’或’0’)、整数类型INTEGER、布尔类型BOOLEAN(取TRUE或FALSE)、标准逻辑类型STD_LOGIC等进程语句与顺序语句process(敏感信号表)_endprocessVHDL中所有的顺序语句都必须放在进程语句中端口语句port(端口模式;端口数据类型);端口模式in:输入端口out:输出端口inout:双向端口buffer:缓冲端口关键字(不区分大小写)entity、architecture、end、if、else、in、out等;标识符(不区分大小写)自定义实体名、结构体名、端
我正在尝试添加以下内容,但它一直连接并返回一个字符串。varnums=[1.99,5.11,2.99];vartotal=0;nums.forEach(function(i){total+=parseFloat(i).toFixed(2);});是的,我需要它来返回/加上小数。不确定要做什么 最佳答案 如果你想要一个更实用的方法,你也可以使用Array.reduce:varnums=[1.99,5.11,2.99];varsum=nums.reduce(function(prev,cur){returnprev+cur;},0);最
如果你评估{}+1你得到1,但是如果你将相同的表达式分配给一个变量,比如x={}+1,该变量将保存一个字符串"[objectObject]1"。为什么赋值会改变右侧表达式的语义?右边的表达式不应该是“上下文无关的”吗? 最佳答案 {}+1被解释为后跟+1的代码块,其计算结果为1。奥托:x={}+1被评估为newObject()加上1如果您将原始语句更改为:newObject()+1您将看到[objectObject]1"作为结果。 关于JavaScript赋值改变了加法运算语义?,我们在
这个问题在这里已经有了答案:Whatdoescompoundlet/constassignmentmean?(1个回答)关闭5年前。在某些版本的node中,a+=b明显比a=a+b慢,但在浏览器和更高版本中类似。是什么导致它们运行如此不同?nodev6.10.0(V85.1.281.93),慢75%,或者反向快4倍nodev8.0.0(V85.8.283.41),慢86%,或者反向快7倍nodev8.2.1(V85.8.283.41),慢86%,或者反向快7倍nodev8.3.0(V86.0.286.52),类似nodev8.7.0(v86.1.534.42),类似nodev8.9.2
我正在测试我的一些代码,在javascript中我添加了.1+.2,它给了我.30000000000000004而不是.3。我不明白这一点。但是当我添加.1+.3时,它给了我.4。我用谷歌搜索并找到了关于double加法的内容。但我不知道它是什么。 最佳答案 这是强制性链接:WhatEveryComputerScientistShouldKnowAboutFloating-PointArithmetic基本上,有许多以10为底的数字无法用大多数计算机使用的浮点格式准确表示,因此您会遇到与您突出显示的问题类似的问题。
数字电路——加法器组合电路(可略过)加法器半加器全加器我们之前了解了门,电路就是门的组合。电路又可以分为两大类,组合电路和时序电路。但作为计算机和编程的知识铺垫,我们要了解的是组合电路的使用方法。所以本篇讲的是组合电路的运算(电路的布尔运算。)推导过程略看也行。建议还是看看,了解一下。组合电路(可略过)输出仅由输入值确定的电路把一个门的输出作为另一个门的输入,就可以把门组合电路.如上图,两个与门的输出被用作或门的输入。注意:A同时是两个与门的输入。两条交叉的连接线的交汇处没有连接点,应该看做是一条连接线跨做了一条,他们互不影响电路分析我们倒着看,按照门来分析如果X=1则说明,D和E至少有一个是
这个问题在这里已经有了答案:Isfloatingpointmathbroken?(31个答案)Whyarefloatingpointnumbersinaccurate?(5个答案)关闭3年前。我发现了以下奇怪的行为。添加一些float会导致“随机”准确度。所以我先跑go版本go1.12darwin/amd64在带有Inteli72,6Ghz的macOSMojave(10.14.3)上行为发生在以下示例中:funcTestFloatingAddition(t*testing.T){f1:=float64(5)f2:=float64(12.1)f5:=float64(-12.1)f3:=f
这个问题在这里已经有了答案:OverflowingofUnsignedInt(3个答案)C/C++unsignedintegeroverflow(4个答案)关闭5年前。有ULARGE_INTEGERunion对于不支持64位算术的编译器。如果最后一行的加法溢出,下面的代码会发生什么?ULARGE_INTEGERu;u.LowPart=ft->dwLowDateTime;u.HighPart=ft->dwHighDateTime;u.LowPart+=10000;//whatifoverflow?相关问题:WhatisthepointoftheULARGE_INTEGERunion?
我想优化这段代码:publicvoidPopulatePixelValueMatrices(GenericImageimage,intWidth,intHeight){for(intx=0;x这将用于图像处理,我们目前正在为大约200张图像运行它。我们优化了GetPixel值以使用不安全的代码,并且我们没有使用image.Width或image.Height,因为这些属性增加了我们的运行时成本。但是,我们仍然停留在低速。问题是我们的图像是640x480,所以循环中间被调用了大约640x480x200次。我想问一下是否有办法以某种方式加快它的速度,或者让我相信它已经足够快了。也许一种方法