ElasticSearch 使用 canal 同步数据
Canal 下载
需要下载
canal.adapter-1.1.5.tar.gz
canal.admin-1.1.5.tar.gz
canal.deployer-1.1.5.tar
| 应用 | 端口 | 版本 |
|---|---|---|
| MySQL | 3306 | 5.7 |
| Elasticsearch | 9200 | 7.6.2 |
| Kibanba | 5601 | 7.6.2 |
| canal-server | 11111 | 1.1.15 |
| canal-adapter | 8081 | 1.1.15 |
| canal-admin | 8089 | 1.1.15 |
由于canal是通过订阅MySQL的binlog来实现数据同步的,所以我们需要开启MySQL的binlog写入功能,并设置binlog-format为ROW模式
my.ini 主要修改部分
[mysqld]
## 设置server_id,同一局域网中需要唯一
server_id=101
## 指定不需要同步的数据库名称
binlog-ignore-db=mysql
## 开启二进制日志功能
log-bin=mall-mysql-bin
## 设置二进制日志使用内存大小(事务)
binlog_cache_size=1M
## 设置使用的二进制日志格式(mixed,statement,row)
binlog_format=row
## 二进制日志过期清理时间。默认值为0,表示不自动清理。
expire_logs_days=7
## 跳过主从复制中遇到的所有错误或指定类型的错误,避免slave端复制中断。
## 如:1062错误是指一些主键重复,1032错误是因为主从数据库数据不一致
slave_skip_errors=1062
配置完成后需要重新启动MySQL,命令查看binlog是否启用和binlog模式;
mysql> show variables like '%log_bin%';
+---------------------------------+----------------------------------------------------------------------+
| Variable_name | Value |
+---------------------------------+----------------------------------------------------------------------+
| log_bin | ON |
| log_bin_basename | D:\Programs\phpstudy_pro\Extensions\MySQL5.7.26\data\mysql-bin |
| log_bin_index | D:\Programs\phpstudy_pro\Extensions\MySQL5.7.26\data\mysql-bin.index |
| log_bin_trust_function_creators | OFF |
| log_bin_use_v1_row_events | OFF |
| sql_log_bin | ON |
+---------------------------------+----------------------------------------------------------------------+
6 rows in set (0.03 sec)
mysql> show variables like 'binlog_format%';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| binlog_format | ROW |
+---------------+-------+
1 row in set (0.01 sec)
创建一个拥有从库权限的账号,用于订阅binlog,创建的账号为canal:canal
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
FLUSH PRIVILEGES;
创建好测试用的数据库canal-test,新建数据表作为demo
CREATE TABLE `product` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`title` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`sub_title` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`price` decimal(10, 2) NULL DEFAULT NULL,
`pic` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 2 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
修改配置文件conf/example/instance.properties,按如下配置即可,主要是修改数据库相关配置;如果账号(上述创建)和端口一致可以在bin目录中启动,linux 用户启动sh,Windows用户启动bat
# 需要同步数据的MySQL地址
canal.instance.master.address=127.0.0.1:3306
canal.instance.master.journal.name=
canal.instance.master.position=
canal.instance.master.timestamp=
canal.instance.master.gtid=
# 用于同步数据的数据库账号
canal.instance.dbUsername=canal
# 用于同步数据的数据库密码
canal.instance.dbPassword=canal
# 数据库连接编码
canal.instance.connectionCharset = UTF-8
# 需要订阅binlog的表过滤正则表达式
canal.instance.filter.regex=.*\\..*
canal-adapter配置
记得启动ElasticSearch服务
修改配置文件conf/application.yml,按如下配置即可,主要是修改canal-server配置、数据源配置和客户端适配器配置;建议直接备份原配置,可以直接替换内容
server:
port: 8081
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_null
canal.conf:
mode: tcp # 客户端的模式,可选tcp kafka rocketMQ
flatMessage: true # 扁平message开关, 是否以json字符串形式投递数据, 仅在kafka/rocketMQ模式下有效
zookeeperHosts: # 对应集群模式下的zk地址
syncBatchSize: 1000 # 每次同步的批数量
retries: 0 # 重试次数, -1为无限重试
timeout: # 同步超时时间, 单位毫秒
accessKey:
secretKey:
consumerProperties:
# canal tcp consumer
canal.tcp.server.host: 127.0.0.1:11111 #设置canal-server的地址
canal.tcp.zookeeper.hosts:
canal.tcp.batch.size: 500
canal.tcp.username:
canal.tcp.password:
srcDataSources: # 源数据库配置
defaultDS:
url: jdbc:mysql://127.0.0.1:3306/canal_test?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai
username: canal
password: canal
canalAdapters: # 适配器列表
- instance: example # canal实例名或者MQ topic名
groups: # 分组列表
- groupId: g1 # 分组id, 如果是MQ模式将用到该值
outerAdapters:
- name: logger # 日志打印适配器
- name: es7 # ES同步适配器
hosts: http://127.0.0.1:9200 # ES连接地址
properties:
mode: rest # 模式可选transport(9300) 或者 rest(9200)
# security.auth: test:123456 # only used for rest mode
cluster.name: elasticsearch # ES集群名称
添加配置文件…/conf/es7/product.yml,用于配置MySQL中的表与Elasticsearch中索引的映射关系;
dataSourceKey: defaultDS # 源数据源的key, 对应上面配置的srcDataSources中的值
destination: example # canal的instance或者MQ的topic
groupId: g1 # 对应MQ模式下的groupId, 只会同步对应groupId的数据
esMapping:
_index: canal_product # es 的索引名称
_id: _id # es 的_id, 如果不配置该项必须配置下面的pk项_id则会由es自动分配
sql: "SELECT
p.id AS _id,
p.title,
p.sub_title,
p.price,
p.pic
FROM
product p" # sql映射
etlCondition: "where a.c_time>={}" #etl的条件参数
commitBatch: 3000 # 提交批大小
linux 用户启动sh,Windows用户启动bat
启动如果提醒druid报错:class com.alibaba.druid.pool.DruidDataSource cannot be cast to
项目中多模块中的druid jar包冲突导致。
下载1.1.5 源码,修改项目中子项目client-adapter下escore的pom中druid包的scope为provided模式。
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<scope>provided</scope> #新增 让es的xxxx-with-dependency.jar不包含druid相关包
</dependency>
canal 源码根目录打包
mvn clean install -Dmaven.test.skip=true
将client-adapter.es7x-1.1.5-jar-with-dependencies.jar 替换 plugin文件夹中的jar包
canal 源码目录下 …/client-adapter/es7x 下target中
打包好的jar client-adapter.es7x-1.1.5-jar-with-dependencies.jar
偷懒可以直接用,不收费
在Elasticsearch中创建索引,和MySQL中的product表相对应,直接在Kibana的Dev Tools中使用如下命令创建即可;
PUT canal_product
{
"mappings": {
"properties": {
"title": {
"type": "text"
},
"sub_title": {
"type": "text"
},
"pic": {
"type": "text"
},
"price": {
"type": "double"
}
}
}
}

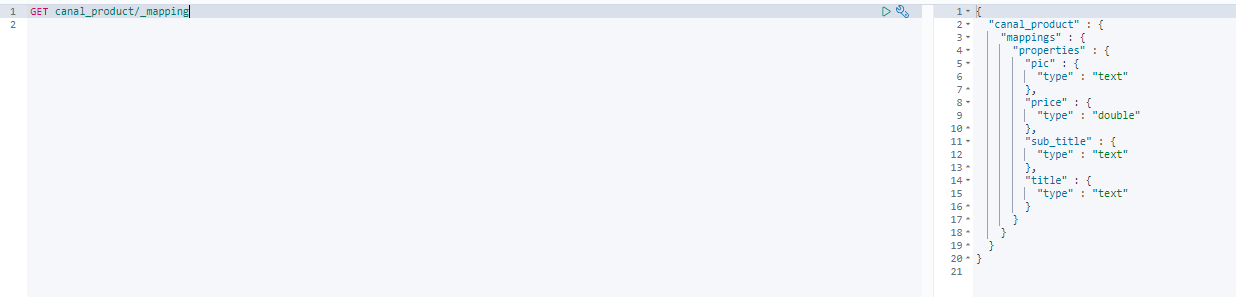
创建完成后可以查看下索引的结构;
GET canal_product/_mapping
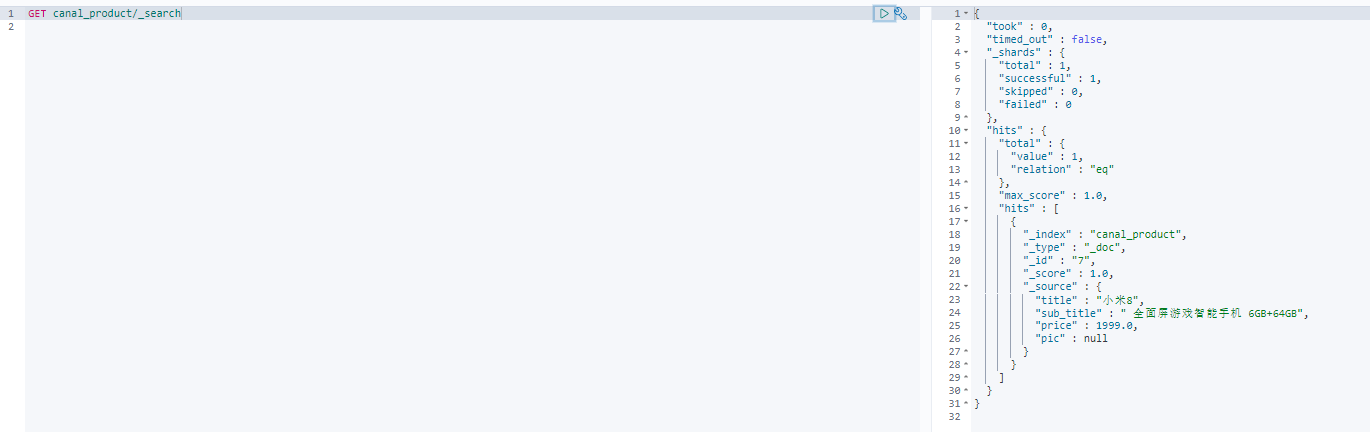
创建一条记录;
INSERT INTO product (title, sub_title, price, pic ) VALUES ( '小米8', ' 全面屏游戏智能手机 6GB+64GB', 1999.00, NULL );
Elasticsearch搜索查看是否同步
GET canal_product/_search
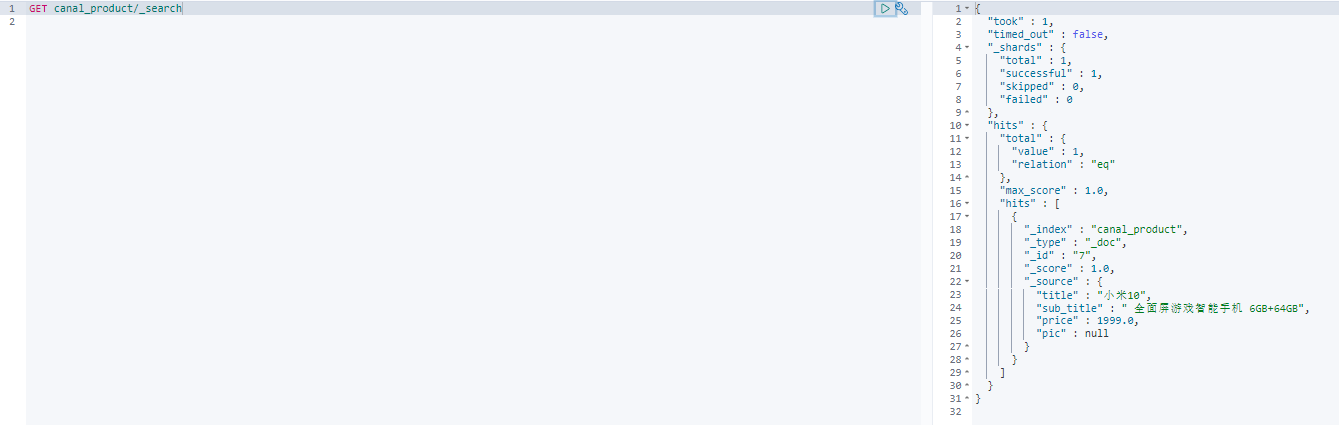
对数据进行修改
UPDATE product SET title='小米10' WHERE id=5
再次查看发现也同步了
创建canal-admin需要使用的数据库canal_manager,创建SQL脚本为canal-admin目录下的 …conf/canal_manager.sql

修改配置文件conf/application.yml,按如下配置即可,主要是修改数据源配置和canal-admin的管理账号配置,注意需要用一个有读写权限的数据库账号,比如root:root;
此部分为默认配置文件信息,一致则无需修改
server:
port: 8089
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
spring.datasource:
address: 127.0.0.1:3306
database: canal_manager
username: root
password: root
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?useUnicode=true&characterEncoding=UTF-8&useSSL=false
hikari:
maximum-pool-size: 30
minimum-idle: 1
canal:
adminUser: admin
adminPasswd: admin
修改canal-server的conf/canal_local.properties文件进行配置,主要是修改canal-admin的配置,修改完成后使用sh bin/startup.sh local 或者 .\bin\startup.bat local重启canal-server
# register ip
canal.register.ip =
# canal admin config
canal.admin.manager = 127.0.0.1:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
# admin auto register
canal.admin.register.auto = true
canal.admin.register.cluster =
启动canal-admin服务,输入账号密码admin:123456登录
http://localhost:8089/

更多查看官方文档
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po