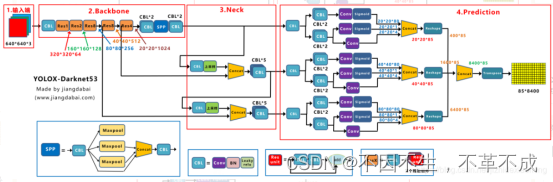
主干网络加入Fcous结构,将图片宽高信息缩小,减小参数量,提升网络计算速度
Fcous结构:将输入的图片先经过Fcos结构对图片进行每隔一个像素取出一个值,得到四个特征层,然后再进行concat。从而图片宽高的信息缩小,通道数增加。在原始信息丢失较少的情况下,减小了参数量(由于fcous替代了两层卷积与一层bottleneck)
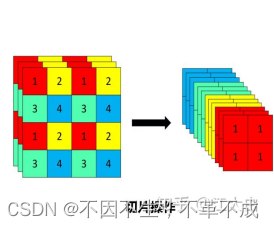
图 1 Fcous示意
silu函数相比于rule非线性能力更强,解决了rule当有负数输入输出为0,发生梯度弥散的缺点。同时继承了relu收敛更快的优点。
silu函数=x*sigmoid(x),是relu与sigmoid的结合。可以看做是一个平滑的Relu,对比来看,silu解决了relu具有负数输入输出为0的缺点,不会发生梯度弥散的问题。
(上层神经元通过加权求和,得到输出值,然后被作用一个激活函数,得到下一层的输入值。引入激活函数的目的是为了增加神经网络的非线性拟合能力。)
(被fcous处理后的feature map会被用silu激活函数的,残差卷积层进行卷积,卷积后进入
CSPLayer。)
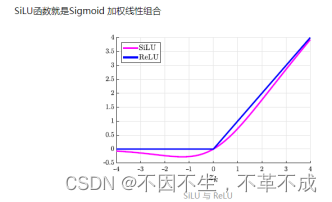
图 2 silu激活函数
CSPLayer:内部的主要特征提取利用残差结构,但csplayer将feature map分为两部分,一部分进入残差块,与瓶颈结构,特征提取,另一部分与特征提取后的feature map进行concat操作从而进行信息融合。(需要注意从代码上,part1与part2是一样的输入)
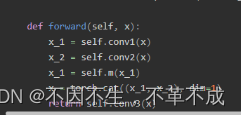
图 3 CSPLayer结构与源码
这里的SPPneck主要通过不同大小的池化核,对图像进行池化,增大网络感受野,提取更多的特征。

图 4 空间金字塔池化公式
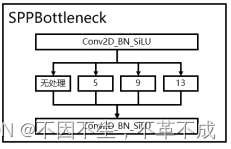
图 5 SPPneck(空间金字塔池化)
总而言之,主干网络卷积层的主要作用是特征提取与特征融合,相比于之前的YOLO版本,更换激活函数带来了一些非线性能力的提升。在主干网络中加入SPPneck增大了网络感受野。
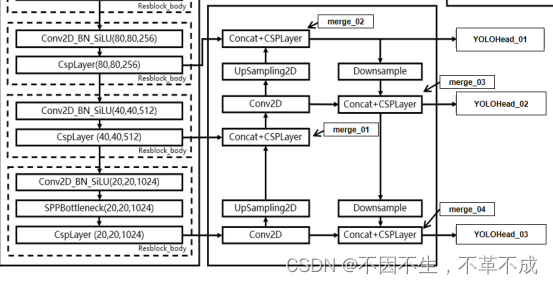
在特征利用部分,YoloX提取多特征层进行目标检测,一共提取三个特征层。
三个特征层位于主干部分CSPdarknet的不同位置,分别位于中间层,中下层,底层,当输入为(640,640,3)的时候,三个特征层的shape分别为feat1=(80,80,256)、feat2=(40,40,512)、feat3=(20,20,1024)。
第一条的路径:主干卷积(20,20,1024)特征图上采样,与主干卷积(40,40,512)特征图进行concat和卷积下采样,融合信息与进一步特征提取得到merge_01。
第二条路径:merge_01通过1x1卷积降通道上采样与主干(80,80,256)concat和卷积下采样得到(80,80,256)大小的merge_02输出到YOLOHead_01(个人理解该层的特征偏向(80,80)的特征图)
第三条路径:merge02下采样与merge01进行concat与卷积下采样操作得到(40,40,512)的(40,40,512)大小的merge_03输出到YOLOHead_02(个人理解该层的特征偏向(40,40)的特征图)
第四条路径:merge_03下采样与主干卷积到(20,20,1024)的特征图进行concat与卷积下采样操作,得到(20,20,1024)的merge_04输出到YOLOHead_03(个人理解该层的特征偏向(20,20)的特征图)
总结:FPN层对3个维度的特征图进行了融合,但是每个输出都有一定的侧重,为了对不同尺度的目标有更好的检测效果。
YOLOV3中最后的回归框与置信度在1*1的卷积中一起实现,而在YOLOX通过解耦头,分别将置信度与回归框分别实现,在预测时合为一体。
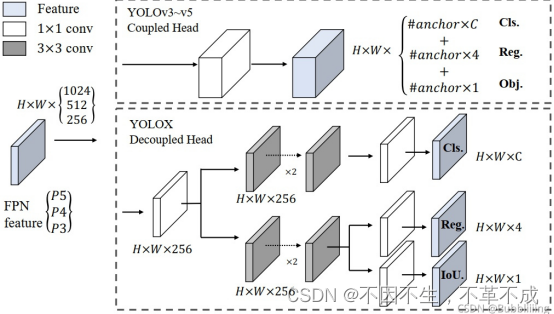

将三个预测结果进行堆叠,每个特征层获得的结果为:
Out(h,w,4+1+num_classses)前四个参数用于判断每一个特征点的回归参数,回归参数调整后可以获得预测框;第五个参数用于判断每一个特征点是否包含物体;最后num_classes个参数用于判断每一个特征点所包含的物体种类。
将检测头解耦相对于YOLOV3检测头直接融合out输出而言,无疑会增加运算的复杂度,但是作者最终使用 1个1x1 的卷积先进行降维,并在分类和回归分支里各使用了 2个3x3 卷积,最终调整到仅仅增加一点点参数。解耦操作从逻辑上,对一个任务的精度而言有着绝对优势,缺点是在于增加运算的复杂程度。如何平衡性能与速度则是解耦方法是否优秀的关键。
解码目标:由yolox中的decoupled_head输出后concat的形状为((numcls+5)*8400)的网格点图。
经过concat与维度转换的网格点,每一行都是代表着一个预测框信息的(numcls、中心点与宽高、判断该预测点是否有物体的obj)的anchorpoint
解码主要解码中心点坐标,以及宽高(x,y,h,w)。
解码中心点坐标是通过torch.meshgrid生成网格数据为网格点的行列索引,将中心点的偏移量x,y加上索引号再乘上缩放倍数。即可解码还原到原图。具体操作为:outputs[..., :2] = (outputs[..., :2] + grids) * strides
解码宽高w,h则是通过output输出宽高部分直接乘以步长再求对数获得。具体操作为:
outputs[..., 2:4] = torch.exp(outputs[..., 2:4]) * strides
SimOTA主要的作用是为每个正样本(网络输出预测框)分配一个GT框,让正样本去拟合该GT框。从而替代之前的anchor方案去拟合anchor,从而实现anchor free
一、通过中心先验(GT框)确定fixed center area的范围fixed center area中的anchorpoint即为初筛正样本。
二、将所mask内的anchorpoint都与对应的GT框进行cost代价矩阵计算。同时计算iou,获得dynamic_k(Cost代价矩阵由:cls_loss和rge_loss组成:cij=Lijcls+λLijreg+100000*~is_in_boxes_and_center。)
1.Reg部分,利用真实框和预测框计算IOU损失,作为Reg部分的Loss组成。
2.Obj部分,所有真实框对应的特征点都是正样本,剩余的特征点均为负样本,根据正负样本和特征点的是否包含物体的预测结果计算交叉熵损失,作为Obj部分的Loss组成。
3.Cls部分,计算交叉熵损失,作为Cls部分的Loss组成。
4.损失公式如下:
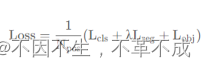
其中Lcls代表分类损失;
Lreg代表定位损失;
Lobj代表obj损失;
λ代表定位损失的平衡系数源码中设置是5.0;
Npos代表被分为正样的Anchor Point数;
感谢对本文有所帮助的人们!!
睿智的目标检测53——Pytorch搭建YoloX目标检测平台_Bubbliiiing的博客-CSDN博客
YOLOX之函数dynamic_k_matching解析 - 知乎 dynamic_k_match源码解析
yolox Head-Decoupled head源码解读_Mr.Q的博客-CSDN博客_yolox的head部分 yolo_head.py源码解析
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
简而言之错误:NOTE:Gem::SourceIndex#add_specisdeprecated,useSpecification.add_spec.Itwillberemovedonorafter2011-11-01.Gem::SourceIndex#add_speccalledfrom/opt/local/lib/ruby/site_ruby/1.8/rubygems/source_index.rb:91./opt/local/lib/ruby/gems/1.8/gems/rails-2.3.8/lib/rails/gem_dependency.rb:275:in`==':und
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
我正在使用ruby2.1.0我有一个json文件。例如:test.json{"item":[{"apple":1},{"banana":2}]}用YAML.load加载这个文件安全吗?YAML.load(File.read('test.json'))我正在尝试加载一个json或yaml格式的文件。 最佳答案 YAML可以加载JSONYAML.load('{"something":"test","other":4}')=>{"something"=>"test","other"=>4}JSON将无法加载YAML。JSON.load("
我想用Nokogiri解析HTML页面。页面的一部分有一个表,它没有使用任何特定的ID。是否可以提取如下内容:Today,3,455,34Today,1,1300,3664Today,10,100000,3444,Yesterday,3454,5656,3Yesterday,3545,1000,10Yesterday,3411,36223,15来自这个HTML:TodayYesterdayQntySizeLengthLengthSizeQnty345534345456563113003664354510001010100000344434113622315
我使用的第一个解析器生成器是Parse::RecDescent,它的指南/教程很棒,但它最有用的功能是它的调试工具,特别是tracing功能(通过将$RD_TRACE设置为1来激活)。我正在寻找可以帮助您调试其规则的解析器生成器。问题是,它必须用python或ruby编写,并且具有详细模式/跟踪模式或非常有用的调试技术。有人知道这样的解析器生成器吗?编辑:当我说调试时,我并不是指调试python或ruby。我指的是调试解析器生成器,查看它在每一步都在做什么,查看它正在读取的每个字符,它试图匹配的规则。希望你明白这一点。赏金编辑:要赢得赏金,请展示一个解析器生成器框架,并说明它的
我有这样的HTML代码:Label1Value1Label2Value2...我的代码不起作用。doc.css("first").eachdo|item|label=item.css("dt")value=item.css("dd")end显示所有首先标记,然后标记标签,我需要“标签:值” 最佳答案 首先,您的HTML应该有和中的元素:Label1Value1Label2Value2...但这不会改变您解析它的方式。你想找到s并遍历它们,然后在每个你可以使用next_element得到;像这样:doc=Nokogiri::HTML(