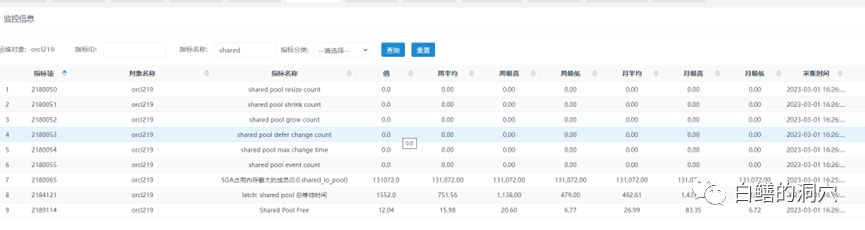
 在D-SMART的共享池数据采集方面,我也是十分谨慎的,不希望因为监控工具设计的不慎而导致原本负载过高的数据库实例被监控脚本搞垮。在V2.2版本的D-SMART中,和SHARED POOL相关的指标都是通过比较稳妥的系统视图采集的。如今要加强共享池数据的采集,首先想到的就是v$sgastat,因为Oracle的AWR也会采集这个视图里的数据。为了确认访问的视图的风险,我们需要找出视图访问的基础数据结构,如果需要大量扫描共享池,那么就应该尽可能避免。通过下面的脚本可以查找相关信息。SELECT view_definition FROM v$fixed_view_definition WHERE view_name='GV$SGASTAT';
在D-SMART的共享池数据采集方面,我也是十分谨慎的,不希望因为监控工具设计的不慎而导致原本负载过高的数据库实例被监控脚本搞垮。在V2.2版本的D-SMART中,和SHARED POOL相关的指标都是通过比较稳妥的系统视图采集的。如今要加强共享池数据的采集,首先想到的就是v$sgastat,因为Oracle的AWR也会采集这个视图里的数据。为了确认访问的视图的风险,我们需要找出视图访问的基础数据结构,如果需要大量扫描共享池,那么就应该尽可能避免。通过下面的脚本可以查找相关信息。SELECT view_definition FROM v$fixed_view_definition WHERE view_name='GV$SGASTAT'; 可以看出,GV$SGASTAT的基础视图是x$ksmfs ,x$ksmss ,x$ksmls ,x$ksmjs ,x$ksmns, x$ksmstrs,这些基础数据结构都是汇总KGH的数据的,本身不需要遍历KGH,因此风险都不大。
可以看出,GV$SGASTAT的基础视图是x$ksmfs ,x$ksmss ,x$ksmls ,x$ksmjs ,x$ksmns, x$ksmstrs,这些基础数据结构都是汇总KGH的数据的,本身不需要遍历KGH,因此风险都不大。 比如ksmss存储了共享对象的一些属性,虽然不会在访问该对象时持有shared pool的闩锁,不过访问过程中也会对共享池内的对象的变更产生影响。因此虽然我们可以比较安全的采集数据,不过也不适合过于频繁。这样的指标的采集,每个小时一次就可以了。column indx heading "indx|indx num" column kghlurcr heading "RECURRENT|CHUNKS"column kghlutrn heading "TRANSIENT|CHUNKS"column kghlufsh heading "FLUSHED|CHUNKS"column kghluops heading "PINS AND|RELEASES"column kghlunfu heading "ORA-4031|ERRORS"column kghlunfs heading "LAST ERROR|SIZE"select indx, kghlurcr, kghlutrn, kghlufsh, kghluops, kghlunfu, kghlunfs from sys.x$kghlu where inst_id = userenv('Instance')
比如ksmss存储了共享对象的一些属性,虽然不会在访问该对象时持有shared pool的闩锁,不过访问过程中也会对共享池内的对象的变更产生影响。因此虽然我们可以比较安全的采集数据,不过也不适合过于频繁。这样的指标的采集,每个小时一次就可以了。column indx heading "indx|indx num" column kghlurcr heading "RECURRENT|CHUNKS"column kghlutrn heading "TRANSIENT|CHUNKS"column kghlufsh heading "FLUSHED|CHUNKS"column kghluops heading "PINS AND|RELEASES"column kghlunfu heading "ORA-4031|ERRORS"column kghlunfs heading "LAST ERROR|SIZE"select indx, kghlurcr, kghlutrn, kghlufsh, kghluops, kghlunfu, kghlunfs from sys.x$kghlu where inst_id = userenv('Instance')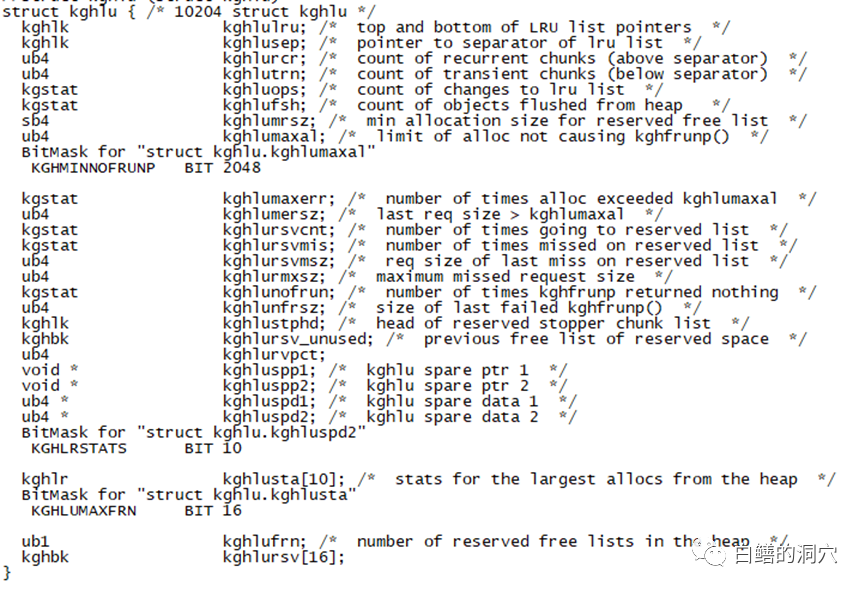 对于监控共享池的情况来说,kghlu数据结构更为有效,可以十分详细地查看到共享池中的每个子池的统计信息。
对于监控共享池的情况来说,kghlu数据结构更为有效,可以十分详细地查看到共享池中的每个子池的统计信息。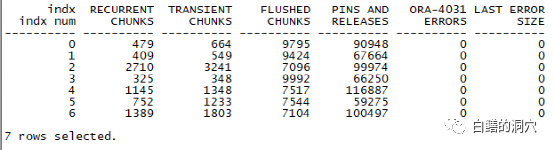 特别是kghlunfu/ kghlunfs这两个字段,显示了每个子池出现的ORA-4031错误的次数以及最后一次分配错误所需分配的空间的大小。一般来说如果在某个子池中分配共享池空间失败只是一个miss,此时会从另外一个池中分配,直到所有的子池中都无法分配空间,才会真正的出现FAILURE。因此ERRORS数量真正指出了共享池内存无法分配空间的情况。对该内存结构的监控可以比较准确地反映出共享池碎片产生的后果。不过这个数据结构的访问也需要通过相关闩锁,并且这个结构的访问频率要比前面所提的那些结构要频繁。因此对该数据结构的采集依然不建议过于频繁,一个小时采集一次已经足够了。
特别是kghlunfu/ kghlunfs这两个字段,显示了每个子池出现的ORA-4031错误的次数以及最后一次分配错误所需分配的空间的大小。一般来说如果在某个子池中分配共享池空间失败只是一个miss,此时会从另外一个池中分配,直到所有的子池中都无法分配空间,才会真正的出现FAILURE。因此ERRORS数量真正指出了共享池内存无法分配空间的情况。对该内存结构的监控可以比较准确地反映出共享池碎片产生的后果。不过这个数据结构的访问也需要通过相关闩锁,并且这个结构的访问频率要比前面所提的那些结构要频繁。因此对该数据结构的采集依然不建议过于频繁,一个小时采集一次已经足够了。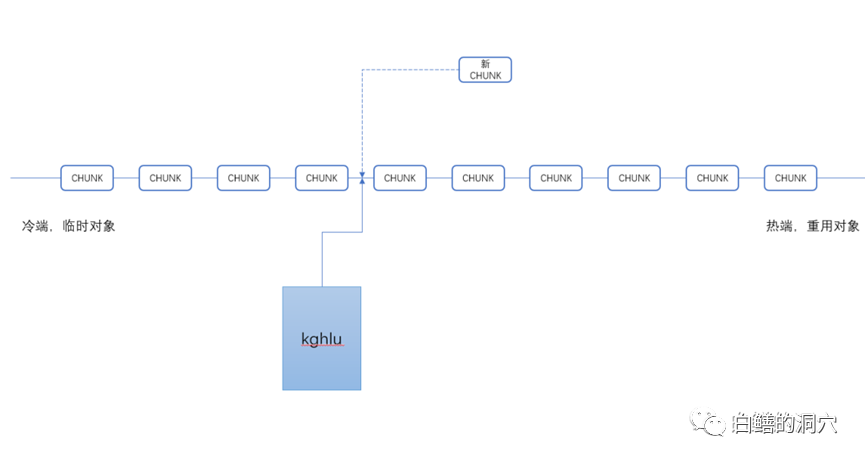 为什么这样说呢?kghlu中的kghlusep指针是一个十分重要的指针,它指向了共享池LRU链上的一个关键位置,那个位置分割了共享池LRU链的冷热区。当新的CHUNK要加入LRU链的时候,是添加在该指针左侧的冷区尾部。而冷区中的CHUNK被多次访问时会迁移到LRU链的热端,以便于被重用。因此这个指针是访问十分频繁的,采集该结构的数据要格外谨慎。x$kghlu经常被某些数据库监控软件用来监控共享池问题,不过频繁的访问这个数据结构还是会对数据库产生影响的,特别是数据库并发比较大,共享池存在性能问题的时候,如果过于频繁的监控这个数据结构,可能会产生一些相当严重的问题。如果知道了这一点,我想大家应该理解为什么我会对共享池的监控数据采集如此谨慎了。col "avg size" format a30 truncate;col siz format 999999999999SELECT KSMCHCLS CLASS, COUNT(KSMCHCLS) NUM, SUM(KSMCHSIZ) SIZ,To_char( ((SUM(KSMCHSIZ) /COUNT(KSMCHCLS) /1024)), '999,999.00')||'k' "AVG SIZE" FROM X$KSMSP GROUP BY KSMCHCLS;
为什么这样说呢?kghlu中的kghlusep指针是一个十分重要的指针,它指向了共享池LRU链上的一个关键位置,那个位置分割了共享池LRU链的冷热区。当新的CHUNK要加入LRU链的时候,是添加在该指针左侧的冷区尾部。而冷区中的CHUNK被多次访问时会迁移到LRU链的热端,以便于被重用。因此这个指针是访问十分频繁的,采集该结构的数据要格外谨慎。x$kghlu经常被某些数据库监控软件用来监控共享池问题,不过频繁的访问这个数据结构还是会对数据库产生影响的,特别是数据库并发比较大,共享池存在性能问题的时候,如果过于频繁的监控这个数据结构,可能会产生一些相当严重的问题。如果知道了这一点,我想大家应该理解为什么我会对共享池的监控数据采集如此谨慎了。col "avg size" format a30 truncate;col siz format 999999999999SELECT KSMCHCLS CLASS, COUNT(KSMCHCLS) NUM, SUM(KSMCHSIZ) SIZ,To_char( ((SUM(KSMCHSIZ) /COUNT(KSMCHCLS) /1024)), '999,999.00')||'k' "AVG SIZE" FROM X$KSMSP GROUP BY KSMCHCLS;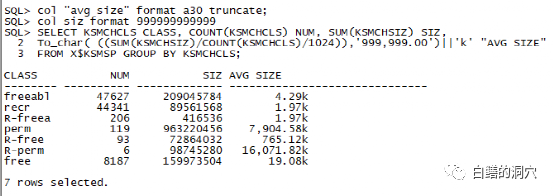 实际上要分析shared pool的风险,上面的语句具有更好的效果,如果发现perm内存不断增长,free的平均大小不断下降,甚至低于4KB,那么说明共享池出现了较大的碎片化风险。而下面的语句可以作更细致的分析。col sga_heap format a15col size format a10select KSMCHIDX "SubPool", 'sga heap('||KSMCHIDX||',0)'sga_heap,ksmchcom ChunkComment,decode(round(ksmchsiz/1000),0,'0-1K', 1,'1-2K', 2,'2-3K',3,'3-4K',4,'4-5K',5,'5-6k',6,'6-7k',7,'7-8k',8,'8-9k', 9,'9-10k','> 10K') "size" ,count(*),ksmchcls Status, sum(ksmchsiz) Bytes from x$ksmsp where KSMCHCOM = 'free memory' group by ksmchidx, ksmchcls,'sga heap('|| KSMCHIDX||',0)',ksmchcom, ksmchcls,decode(round(ksmchsiz/1000),0,'0-1K',1,'1-2K', 2,'2-3K', 3,'3-4K',4,'4-5K',5,'5-6k',6,'6-7k',7,'7-8k',8,'8-9k', 9,'9-10k','> 10K');
实际上要分析shared pool的风险,上面的语句具有更好的效果,如果发现perm内存不断增长,free的平均大小不断下降,甚至低于4KB,那么说明共享池出现了较大的碎片化风险。而下面的语句可以作更细致的分析。col sga_heap format a15col size format a10select KSMCHIDX "SubPool", 'sga heap('||KSMCHIDX||',0)'sga_heap,ksmchcom ChunkComment,decode(round(ksmchsiz/1000),0,'0-1K', 1,'1-2K', 2,'2-3K',3,'3-4K',4,'4-5K',5,'5-6k',6,'6-7k',7,'7-8k',8,'8-9k', 9,'9-10k','> 10K') "size" ,count(*),ksmchcls Status, sum(ksmchsiz) Bytes from x$ksmsp where KSMCHCOM = 'free memory' group by ksmchidx, ksmchcls,'sga heap('|| KSMCHIDX||',0)',ksmchcom, ksmchcls,decode(round(ksmchsiz/1000),0,'0-1K',1,'1-2K', 2,'2-3K', 3,'3-4K',4,'4-5K',5,'5-6k',6,'6-7k',7,'7-8k',8,'8-9k', 9,'9-10k','> 10K');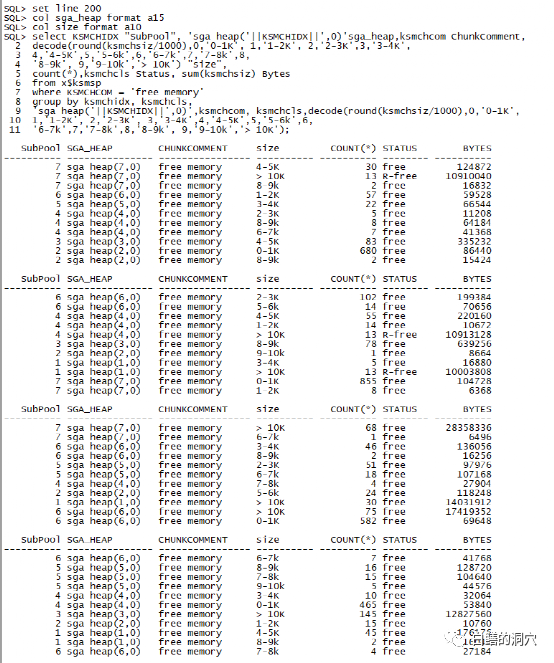 这条SQL可以采集到共享池中free内存的详细情况,如果较大的heap比较少时,共享池的碎片化就很严重了。似乎我们可以直接对x$ksmsp直接做采集,从而获得对共享池分析的更有效的数据。不过真的如此吗?我们如果看一下x$ksmsp的实际结构,就会明白为什么我们不想把这个采集放到自动化采集的脚本中,更好的采集共享池的信息了。
这条SQL可以采集到共享池中free内存的详细情况,如果较大的heap比较少时,共享池的碎片化就很严重了。似乎我们可以直接对x$ksmsp直接做采集,从而获得对共享池分析的更有效的数据。不过真的如此吗?我们如果看一下x$ksmsp的实际结构,就会明白为什么我们不想把这个采集放到自动化采集的脚本中,更好的采集共享池的信息了。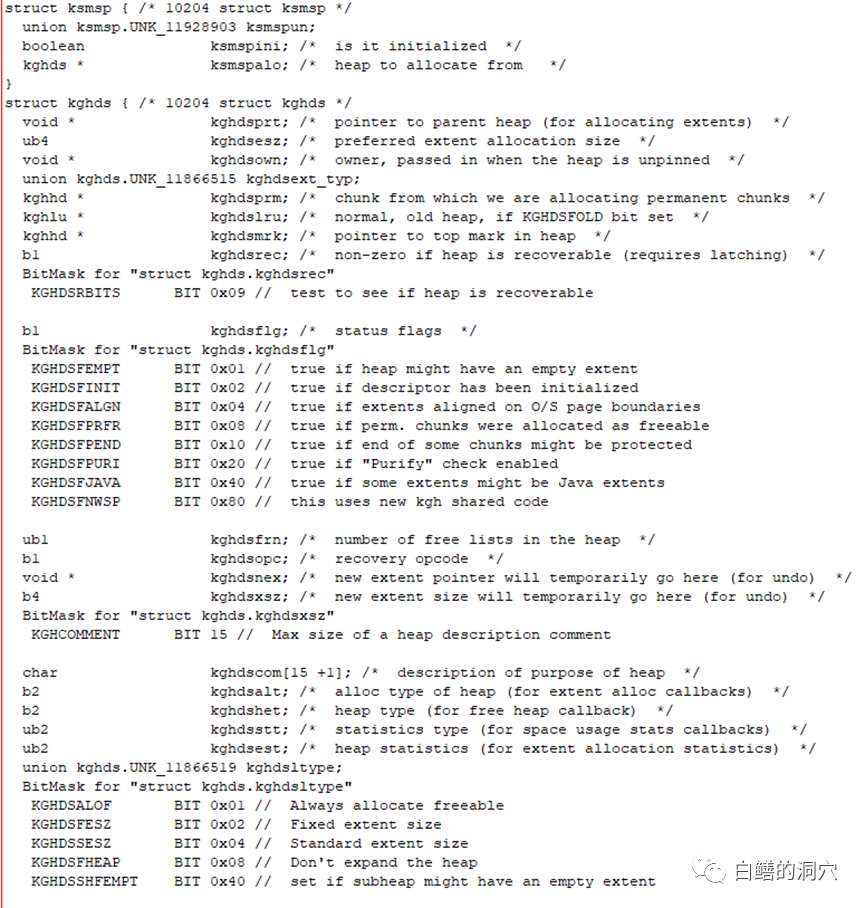 我们可以看到ksmsp实际上指向了一个kghds的链表,而这个链表实际上是指向真实的heap链,对x$ksmsp的统计实际上会遍历heap链表,对于共享池很大,并且共享池并发访问很重,特别是共享池存在性能问题的场景,这种访问无疑会加重共享池的负担,甚至成为压垮骆驼的最后一根稻草。如果这种采集放到不受控的自动化采集中去,那可能会带来不可知的影响。因此这种分析我们只是在手工点击的工具中提供,而不会做成自动化采集的一部分。监控与诊断实际上也是一种运维知识,开发监控与诊断工具,产品经理中应该有资深的运维专家,仅仅依靠高水平的研发人员是开发不出一套真正高水平的运维监控与诊断工具的。而对于一些比较脆弱的数据库模块的监控采集,也需要十分谨慎的做设计,否则监控软件会成为伪装成天使的恶魔。
我们可以看到ksmsp实际上指向了一个kghds的链表,而这个链表实际上是指向真实的heap链,对x$ksmsp的统计实际上会遍历heap链表,对于共享池很大,并且共享池并发访问很重,特别是共享池存在性能问题的场景,这种访问无疑会加重共享池的负担,甚至成为压垮骆驼的最后一根稻草。如果这种采集放到不受控的自动化采集中去,那可能会带来不可知的影响。因此这种分析我们只是在手工点击的工具中提供,而不会做成自动化采集的一部分。监控与诊断实际上也是一种运维知识,开发监控与诊断工具,产品经理中应该有资深的运维专家,仅仅依靠高水平的研发人员是开发不出一套真正高水平的运维监控与诊断工具的。而对于一些比较脆弱的数据库模块的监控采集,也需要十分谨慎的做设计,否则监控软件会成为伪装成天使的恶魔。 我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
给定这段代码defcreate@upgrades=User.update_all(["role=?","upgraded"],:id=>params[:upgrade])redirect_toadmin_upgrades_path,:notice=>"Successfullyupgradeduser."end我如何在该操作中实际验证它们是否已保存或未重定向到适当的页面和消息? 最佳答案 在Rails3中,update_all不返回任何有意义的信息,除了已更新的记录数(这可能取决于您的DBMS是否返回该信息)。http://ar.ru
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
Rackup通过Rack的默认处理程序成功运行任何Rack应用程序。例如:classRackAppdefcall(environment)['200',{'Content-Type'=>'text/html'},["Helloworld"]]endendrunRackApp.new但是当最后一行更改为使用Rack的内置CGI处理程序时,rackup给出“NoMethodErrorat/undefinedmethod`call'fornil:NilClass”:Rack::Handler::CGI.runRackApp.newRack的其他内置处理程序也提出了同样的反对意见。例如Rack
在选择我想要运行操作的频率时,唯一的选项是“每天”、“每小时”和“每10分钟”。谢谢!我想为我的Rails3.1应用程序运行调度程序。 最佳答案 这不是一个优雅的解决方案,但您可以安排它每天运行,并在实际开始工作之前检查日期是否为当月的第一天。 关于ruby-如何每月在Heroku运行一次Scheduler插件?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/8692687/
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为
我有一大串格式化数据(例如JSON),我想使用Psychinruby同时保留格式转储到YAML。基本上,我希望JSON使用literalstyle出现在YAML中:---json:|{"page":1,"results":["item","another"],"total_pages":0}但是,当我使用YAML.dump时,它不使用文字样式。我得到这样的东西:---json:!"{\n\"page\":1,\n\"results\":[\n\"item\",\"another\"\n],\n\"total_pages\":0\n}\n"我如何告诉Psych以想要的样式转储标量?解