作者🕵️♂️:让机器理解语言か
专栏🎇:NLP(自然语言处理)
描述🎨:让机器理解语言,让世界更加美好!
寄语💓:🐾没有白走的路,每一步都算数!🐾
(本文是chatGPT原理介绍,但没有任何数学公式,可以放心食用)
这几个月,chatGPT模型真可谓称得上是狂拽酷炫D炸天的存在了。一度登上了知乎热搜,这对科技类话题是非常难的存在。不光是做人工智能、机器学习的人关注,而是大量的各行各业从业人员都来关注这个模型,真可谓空前盛世。
我赶紧把 openai 以往的 GPT-n 系列论文又翻出来,重新学习一下,认真领会大规模预训练语言模型(Large Language Model)的强大之处。
可能很多深度学习相关从业人员的感受和我一样,大家之前对 LLM 的感受依然是,预训练+finetune,处理下游任务,依然需要大量的标注数据和人工干预,怎么突然间,chatGPT 就智能到如此地步?
注:FineTune: 基于预训练模型(Pre-trained mode)进行的微调(Fine Tune )。
Q:finetune 就是微调的意思,那为什么要微调呢,为什么不能自己重新训练一个网络呢?
A:因为我们没那么多样本,没那么高超的技术使神经网络合理且有用,因此我在训练好的模型的基础上只训练其中一个或几个层,而把其他层的参数都冻结起来。相对于你从头开始训练(Training a model from scatch),微调为你省去大量计算资源和计算时间,提高了计算效率,甚至提高准确率。
接下来,我简要梳理一下 openai 的 GPT 大模型的发展历程。
2018年,自然语言处理 NLP 领域也步入了 LLM (大型语言模型)时代,谷歌出品的 Bert 模型横空出世,碾压了以往的所有模型,直接在各种NLP的建模任务中取得了最佳的成绩。
Bert做了什么,主要用以下例子做解释。
请各位做一个完形填空:___________和阿里、腾讯一起并成为中国互联网 BAT 三巨头。
请问上述空格应该填什么?有的人回答“百度”,有的人可能觉得,“字节”也没错。但总不再可能是别的字了。
不论填什么,这里都表明,空格处填什么字,是受到上下文决定和影响的。
Bert 所作的事就是从大规模的上亿的文本预料中,随机地扣掉一部分字,形成上面例子的完形填空题型,不断地学习空格处到底该填写什么。所谓语言模型,就是从大量的数据中学习复杂的上下文联系。
与此同时,openai 早于 Bert 出品了一个初代 GPT 模型。
他们大致思想是一样的。都基于 Transformer 这种编码器,获取了文本内部的相互联系。
编解码的概念广泛应用于各个领域,在 NLP 领域,人们使用语言一般包括三个步骤:
接受听到或读到的语言 -> 大脑理解 -> 输出要说的语言。
语言是一个显式存在的东西,但大脑是如何将语言进行理解、转化和存储的,则是一个目前仍未探明的东西。因此,大脑理解语言这个过程,就是大脑将语言编码成一种可理解、可存储形式的过程,这个过程就叫做语言的编码。相应的,把大脑中想要表达的内容,使用语言表达出来,就叫做语言的解码。
在语言模型中,编码器和解码器都是由一个个的 Transformer 组件拼接在一起形成的。
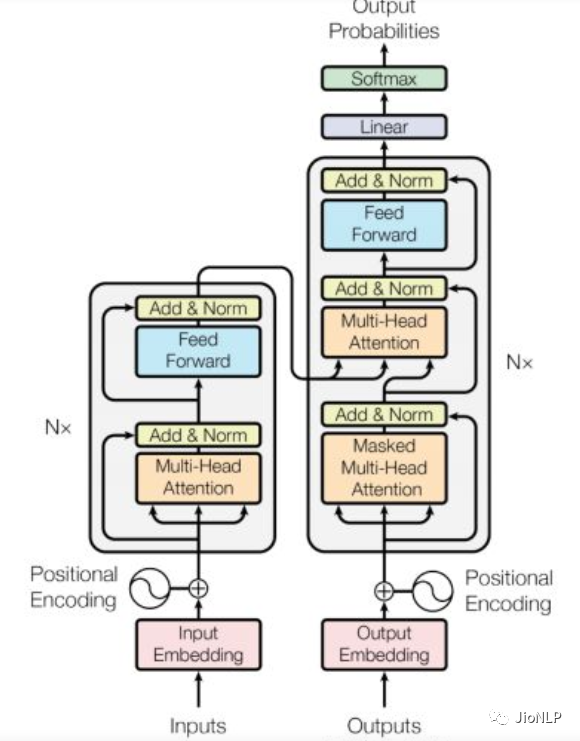
这里不展开讲 Transformer 里的内部结构,仅仅讲一下 Bert 和 GPT 的区别。
两者最主要的区别在于,Bert 仅仅使用了 encoder 也就是编码器部分进行模型训练,GPT 仅仅使用了 decoder 部分。两者各自走上了各自的道路,根据我粗浅的理解,GPT 的decoder 模型更加适应于文本生成领域。
GPT 初代其实个人认为(当然普遍也都这么认为)略逊色于 Bert,再加上宣传地不够好,影响力也就小于 Bert。
我相信很多的 NLP 从业者对 LLM 的理解也大都停留在此。即,本质上讲,LLM 是一个非常复杂的编码器,将文本表示成一个向量表示,这个向量表示有助于解决 NLP 的任务。
自从 Bert 炸街后,跟风效仿的改进模型也就越来越多了,比如 albert、roberta、ERNIE,BART、XLNET、T5 等等五花八门。
最初的时候,仅仅是一个完形填空任务就可以让语言模型有了极大进步,那么,给 LLM 模型出其它的语言题型,应该也会对模型训练有极大的帮助。
想要出语言题型不是很简单么,什么句子打乱顺序再排序、选择题、判断题、改错题、把预测单字改成预测实体词汇等等,纷纷都可以制定数据集添加在模型的预训练里。很多模型也都是这么干的。
既然出题也可以,把各种NLP任务的数据集添加到预训练阶段当然也可以。
这个过程也和人脑很像,人脑是非常稳定和泛化的,既可以读诗歌,也可以学数学,还可以学外语,看新闻,听音乐等等,简而言之,就是一脑多用。
我们一般的 NLP 任务,文本分类模型就只能分类,分词模型就只能分词,机器翻译也就只能完成翻译这一件事,非常不灵活。
GPT-2 主要就是在 GPT 的基础上,又添加了多个任务,扩增了数据集和模型参数,又训练了一番。
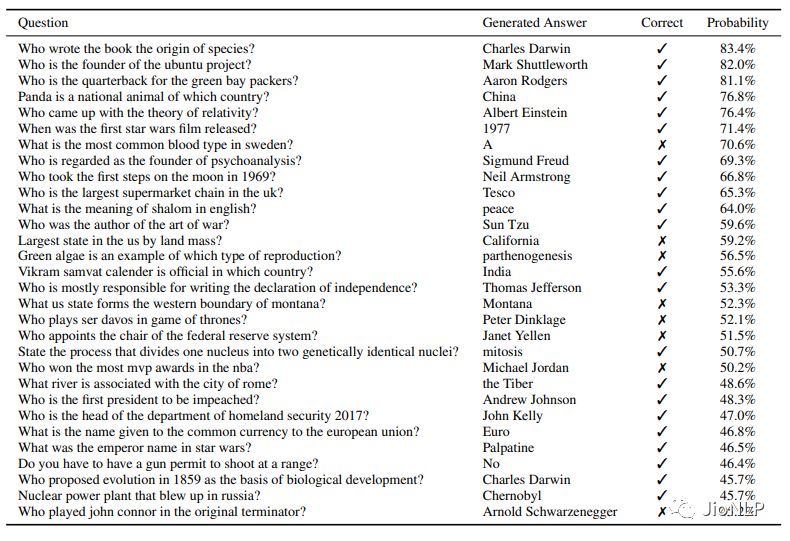
既然多个任务都在同一个模型上进行学习,还存在一个问题,这一个模型能承载的并不仅仅是任务本身,“汪小菲的妈是张兰”,这条文字包含的信息量是通用的,它既可以用于翻译,也可以用于分类,判断错误等等。也就是说,信息是脱离具体 NLP 任务存在的,举一反三,能够利用这条信息,在每一个 NLP 任务上都表现好,这个是 元学习(meta-learning),实际上就是语言模型的一脑多用。
大模型中的大模型
首先, GPT-3 的模型所采用的数据量之大,高达上万亿,模型参数量也十分巨大,学习之复杂,计算之繁复不说了,看图吧。
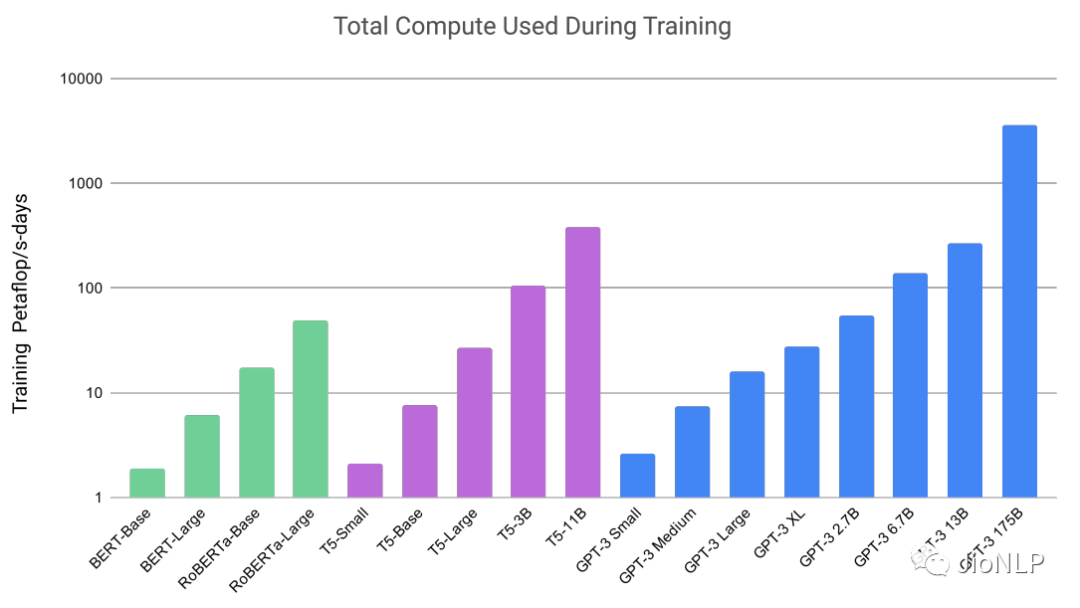
GPT-3 里的大模型计算量是 Bert-base 的上千倍。统统这些都是在燃烧的金钱,真就是 all you need is money。如此巨大的模型造就了 GPT-3 在许多十分困难的 NLP 任务,诸如撰写人类难以判别的文章,甚至编写SQL查询语句,React或者JavaScript代码上优异的表现。
首先 GPT-n 系列模型都是采用 decoder 进行训练的,也就是更加适合文本生成的形式。也就是,输入一句话,输出也是一句话。也就是对话模式。
对话
我们是如何学会中文的?通过从0岁开始,听,说,也就是对话。
我们是如何学外语的?看教材,听广播,背单词。唯独缺少了对话!正是因为缺少了对话这个高效的语言学习方式,所以我们的英语水平才如此难以提高。
对于语言模型,同理。
对话是涵盖一切NLP 任务的终极任务。从此 NLP不再需要模型建模这个过程。比如,传统 NLP 里还有序列标注这个任务,需要用到 CRF 这种解码过程。在对话的世界里,这些统统都是冗余的。
其实 CRF 这项技术还是蛮经典的,在深度学习这块,CRF这也才过去没几年。
注:条件随机场(Conditional Random Field,CRF)是自然语言处理的基础模型,广泛应用于中文分词、命名实体识别、词性标注等标注场景
in-context learning(上下文学习)
以往的预训练都是两段式的,即,首先用大规模的数据集对模型进行预训练,然后再利用下游任务的标注数据集进行 finetune(微调),时至今日这也是绝大多数 NLP 模型任务的基本工作流程。
GPT-3 就开始颠覆这种认知了。它提出了一种 in-context 学习方式。这个词没法翻译成中文,下面举一个例子进行解释。
用户输入到 GPT-3:你觉得 chatNLP 是个好用的工具吗?
GPT-3输出1:我觉得很好啊。
GPT-3输出2:chatNLP是什么东西?
GPT-3输出3:你饿不饿,我给你做碗面吃……
GPT-3输出4:Do you think chatNlp is a good tool?
按理来讲,针对机器翻译任务,我们当然希望模型输出最后一句,针对对话任务,我们希望模型输出前两句中的任何一句。显然做碗面这个输出句子显得前言不搭后语。
这时就有了 in-context 学习,也就是,我们对模型进行引导,教会它应当输出什么内容。如果我们希望它输出翻译内容,那么,应该给模型如下输入:
用户输入到 GPT-3:请把以下中文翻译成中文:你觉得 JioNLP 是个好用的工具吗?
如果想让模型回答问题:
用户输入到 GPT-3:模型模型你说说,你觉得 JioNLP 是个好用的工具吗?
OK,这样模型就可以根据用户提示的情境,进行针对性的回答了。
这里,只是告知了模型如何做,最好能够给模型做个示范:
用户输入到 GPT-3:请把以下中文翻译成英文:苹果 => apple; 你觉得 chatNLP 是个好用的工具吗?=>
其中 苹果翻译成 apple,是一个示范样例,用于让模型感知该输出什么。只给提示叫做 zero-shot,给一个范例叫做 one-shot,给多个范例叫做 few-shot。
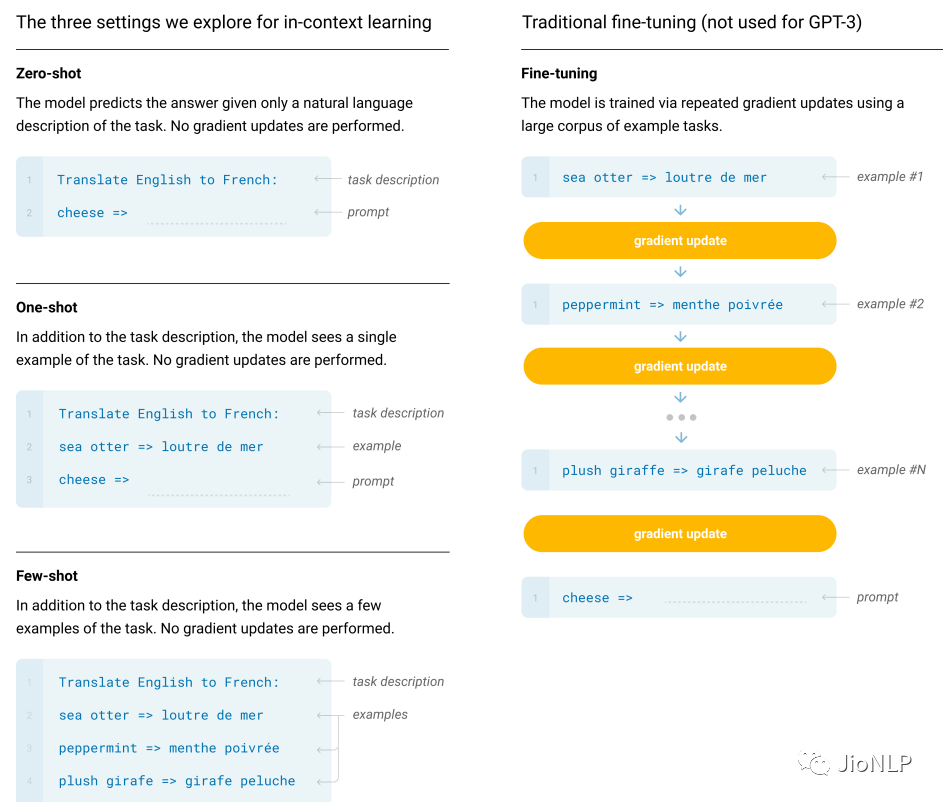
范例给几个就行了,不能再给多了!一个是,咱们没那么多标注数据,另一个是,给多了不就又成了 finetune 模式了么?
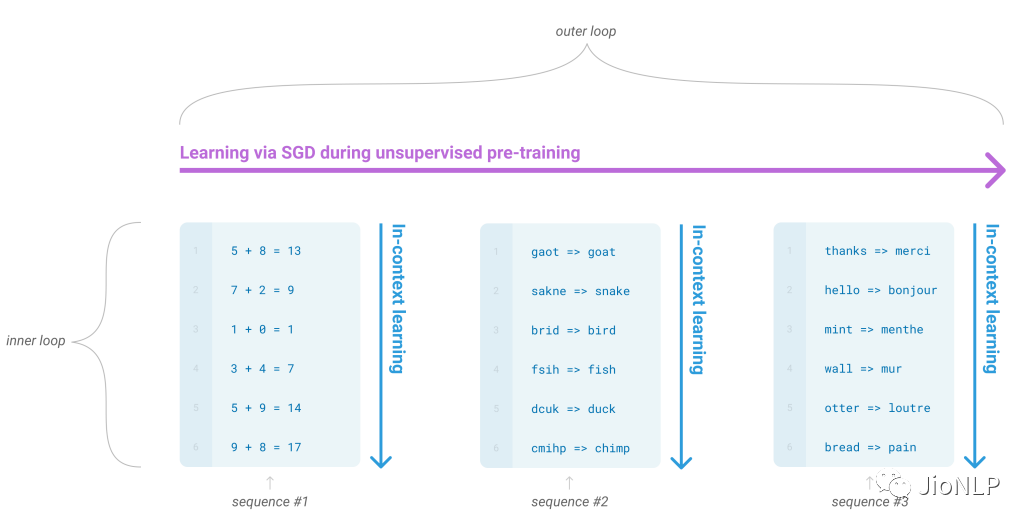
在 GPT-3 的预训练阶段,也是按照这样多个任务同时学习的。比如“ 做数学加法,改错,翻译”同时进行。这其实就类似前段时间比较火的 prompt。
这种引导学习的方式,在超大模型上展示了惊人的效果:只需要给出一个或者几个示范样例,模型就能照猫画虎地给出正确答案。注意啊,是超大模型才可以,一般几亿参数的大模型是不行的。(我们这里没有小模型,只有大模型、超大模型、巨大模型)
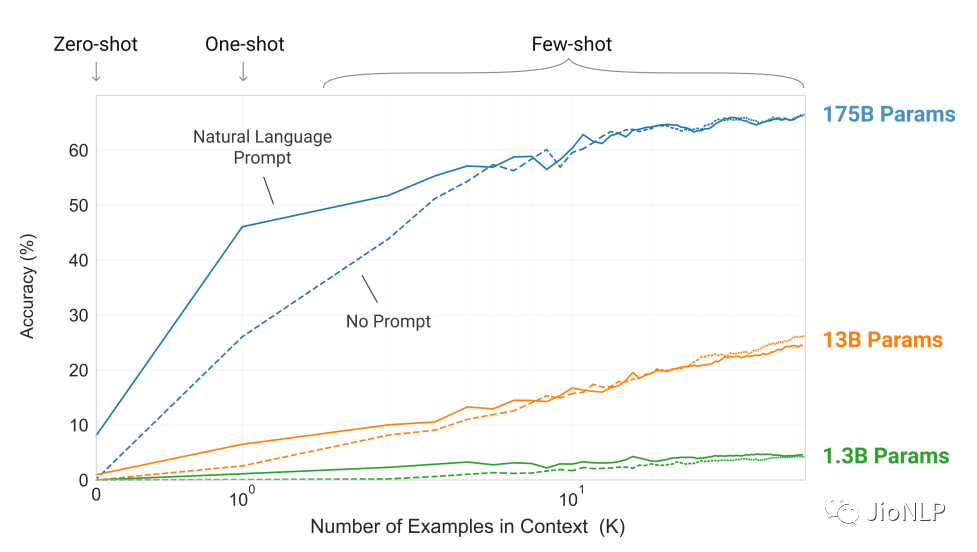
这个表格彷佛在嘲讽我:哎,你没钱,你就看不着这种优质的效果,你气不气?
charGPT 模型上基本上和之前都没有太大变化,主要变化的是训练策略变了。
强化学习(Reinforcement Learning)
几年前,alpha GO 击败了柯洁,几乎可以说明,强化学习如果在适合的条件下,完全可以打败人类,逼近完美的极限。
强化学习非常像生物进化,模型在给定的环境中,不断地根据环境的惩罚和奖励(reward),拟合到一个最适应环境的状态。
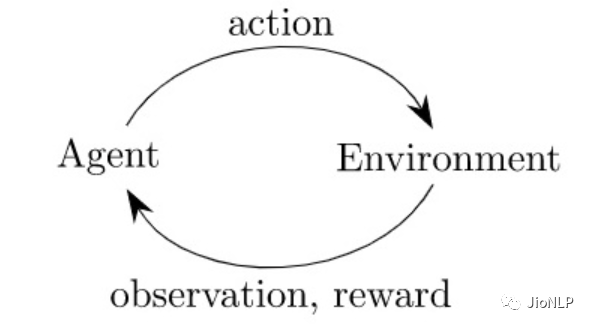
强化学习之所以能比较容易地应用在围棋以及其它各种棋牌游戏里,原因就是因为对于 alpha Go 而言,环境就是围棋,围棋棋盘就是它的整个世界。
而几年前知乎上就有提问,NLP + 强化学习,可以做吗?怎么做呢?
底下回答一片唱衰,原因就是因为,NLP 所依赖的环境,是整个现实世界,整个世界的复杂度,远远不是一个19乘19的棋盘可以比拟的。无法设计反馈惩罚和奖励函数,即 reward 函数。除非人们一点点地人工反馈。
哎,open-ai 的 chatGPT 就把这事给干了。
不是需要人工标反馈和奖励吗?那就撒钱,找40个外包,标起来!

这种带人工操作的 reward,被称之为 RLHF(Reinforcement Learning from Human Feedback)。
具体操作过程就是下图的样子,采用强化学习的方式来对模型进行训练。已经抛弃了传统的 LM 方式。
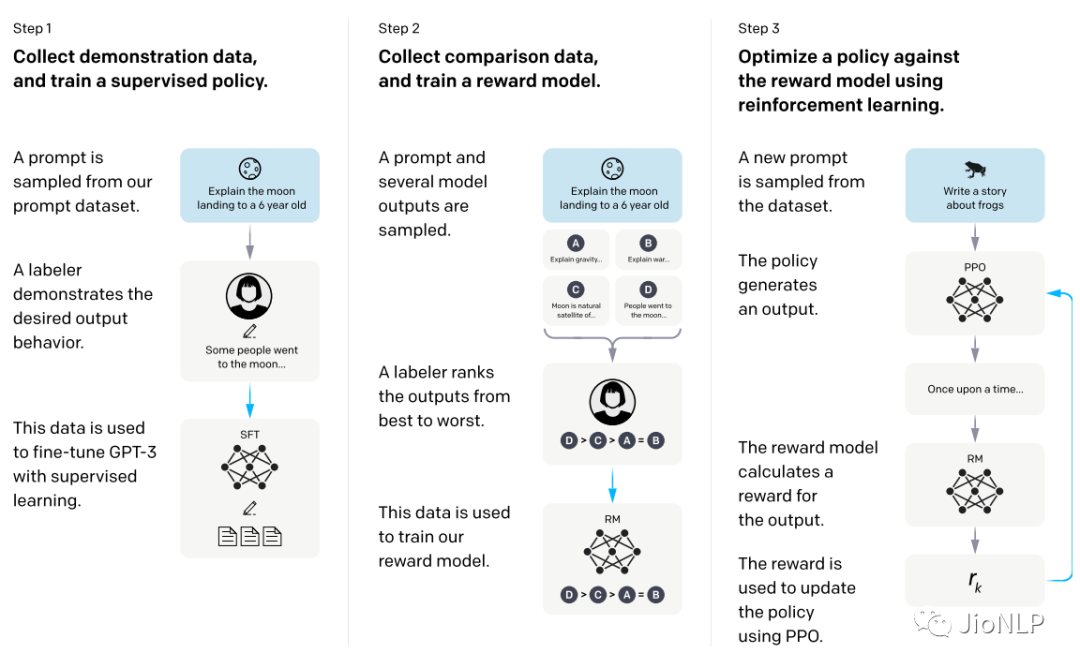
这里重点是第二部中,如何构建一个 reward 函数,具体就是让那40名外包人员不断地从模型的输出结果中筛选,哪些是好的,哪些是低质量的,这样就可以训练得到一个 reward 模型。
通过reward 模型来评价模型的输出结果好坏。
讲真,这个 reward 模型,《黑客帝国》的母体 matrix 既视感有木有??!!
只要把预训练模型接一根管子在 reward 模型上,预训练模型就会开始像感知真实世界那样,感知reward。
由此,我们就可以得到这个把全世界都震碎的高音!(误,模型)
能回答知乎上的问题
你别想耍它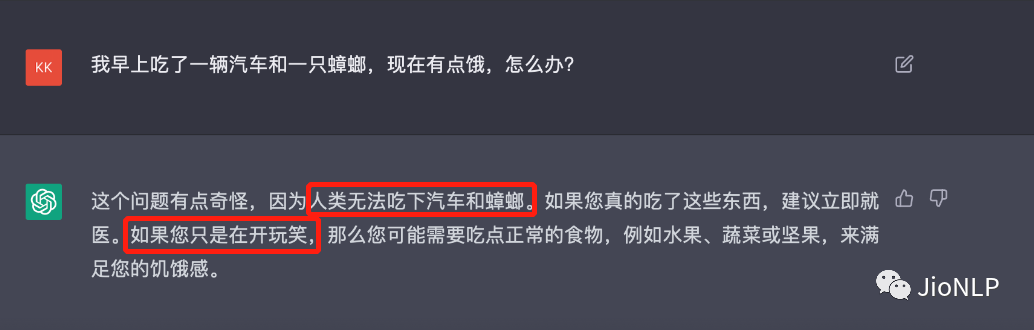
能回答困难的问题
能理解乱序文本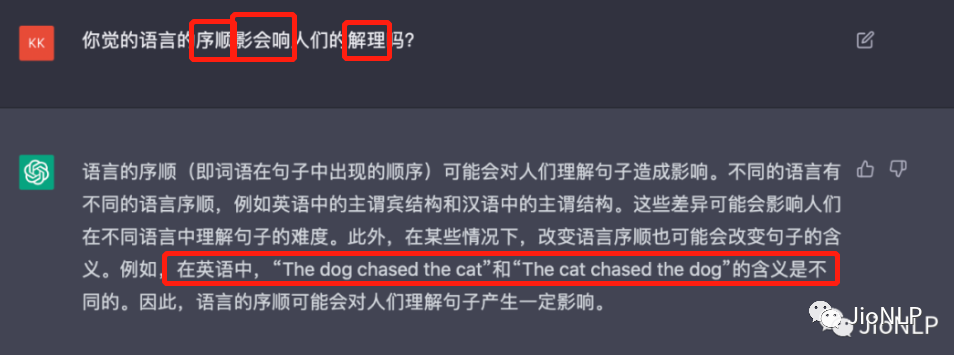
会做高数
知道自己是程序,不会做你女票
还能处理程序 bug
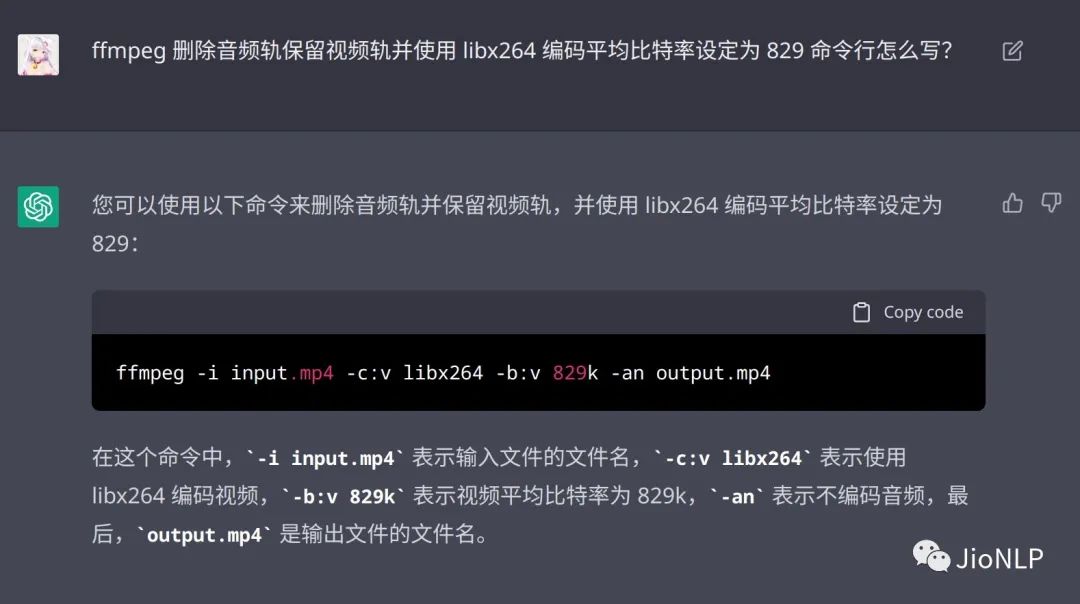
个人认为,NLP 领域的一些里程碑性的技术重要性排序如下:
chatGPT > word2vec > Bert (纯个人看法)
chatGPT 的关注度已经很大程度让人们感觉到,什么天猫精灵、小爱同学等等人工智障的时代似乎过去了。只要模型足够大,数据足够丰富,reward 模型经过了更多的人迭代和优化,完全可以创造一个无限逼近真实世界的超级 openai 大脑。
当然,chat GPT 依然是存在回答不好的情况的,比如会重复一些词句,无法分清楚事实等等。
而且,chatGPT 目前看,它是没有在推理阶段连接外部信息的。
模型知道自己的回答边界,知道自己只是一个没有情感的回答工具。那么,试想 openai 把外部信息也导入到 chatGPT 里。
另一些影响
我看到 chatGPT 居然可以写代码,还能帮我改代码,debug,作为程序员,我不禁深深陷入了沉思。
据说,debug 程序员网站 stackoverflow,已经下场封杀 chatGPT 了。

当然,完全不仅仅是程序界。据说 GPT-4 正在做图文理解,那么,对于教师、医生、咨询师、等等等等,各行各业,是不是都是一个巨大的冲击?所谓专业领域的知识门槛,也将被模型一步踏平。到时候,可能人类真的要靠边站了,除了某些高精尖的行业精英。
英文版英文链接关注公众号在“亚特兰蒂斯的回声”中踏上一段难忘的冒险之旅,深入未知的海洋深处。足智多谋的考古学家AriaSeaborne偶然发现了一件古代神器,揭示了一张通往失落之城亚特兰蒂斯的隐藏地图。在她神秘的导师内森·兰登教授的指导和勇敢的冒险家亚历克斯·默瑟的帮助下,阿丽亚开始了一段危险的旅程,以揭开这座传说中城市的真相。他们的冒险之旅带领他们穿越险恶的大海、神秘的岛屿和充满陷阱和谜语的致命迷宫。随着Aria潜在的魔法能力的觉醒,她被睿智勇敢的QueenNeria的幻象所指引,她让她为即将到来的挑战做好准备。三人组揭开亚特兰蒂斯令人惊叹的隐藏文明,并了解到邪恶的巫师马拉卡勋爵试图利用其古
2022年底,OpenAI的预训练模型ChatGPT给人工智能领域的爱好者和研究人员留下了深刻的印象和启发,他展现的惊人能力将人工智能的研究和应用热度推向高潮,网上也充斥着和ChatGPT的各种聊天,他可以作诗、写小说、写代码、讨论疫情问题等。下面就是一些他的神回复:人命关天的坑: 写歌,留给词作者的机会不多了。。。 回答人类怎么样面对人工智能: 什么是ChatGPT?借用网上的一段介绍,ChatGPT是由人工智能研究实验室OpenAI在2022年11月30日发布的全新聊天机器人模型,一款人工智能技术驱动的自然语言处理工具。它能够通过学习和理解人类的语言来进行对话,还能根据聊天的上下文进行互动
目录ChatGPT简介技术原理应用未来发展ChatGPT的10 种用法ChatGPT简介ChatGPT是一种基于深度学习的大型语言模型,由OpenAI公司开发。技术原理GPT是GenerativePre-trainedTransformer的缩写,意为生成式预训练变压器。它的技术原理是使用了一个基于注意力机制的变压器(Trans
♥️作者:白日参商🤵♂️个人主页:白日参商主页♥️坚持分析平时学习到的项目以及学习到的软件开发知识,和大家一起努力呀!!!🎈🎈加油!加油!加油!加油🎈欢迎评论💬点赞👍🏻收藏📂加关注+!「想体验ChatGPT中文聊天?」那快进来,你用不上算我输项目场景:项目条件一、那就开始吧1、安装ChatGPT-Desktop2、OpenAPI设置二、使用实例恭喜你!!!配置成功了!!!API和URL都是博主免费提供给大家的!!!恭喜你!!!配置成功了!!!API和URL都是博主免费提供给大家的!!!🎈🎈加油!加油!加油!加油🎈欢迎评论💬点赞👍🏻收藏📂加关注+!项目场景:近几个月可以说ChatGPT是火得一
ChatGPT掀起了AI股历史上最疯狂的一轮市值狂飙。自春节后至今,ChatGPT概念股开始了暴走模式,短短半月时间,海天瑞声、开普云等ChatGPT概念股市值累计增加了近1400亿。如此的爆炸效应,得益于ChatGPT所展现出商业化落地的巨大潜力。要知道,在此之前,无论是十年AI投入超千亿的百度,还是困在硬件化里的AI四小龙,都在重复着AI商业化难落地的故事。ChatGPT的出现,让AI从生产力的赋能者直接成为一种创造生产力的工具。随着订阅模式的推出,ChatGPT已经成为第一个以AI技术为核心直接变现的消费者应用。本文持有以下核心观点:1、ChatGPT是AI技术迭代的受益者。过去受限技术
文章目录前言1.AI的发展历程2.我是如何接触到人工智能的概念和产品的3.对于ChatGPT的一点看法4.AI对大学毕业生的职业发展的利与弊5.对于AI的思考和问题前言随着ChatGPT的爆火,生成式AI,大模型的人工智能被越来越多的人注意到,同时他也带来了许多问题。本文将对几方面进行探讨。1.AI的发展历程远古时期在公元前第一个千禧年,中国,印度和希腊哲学家都提出了一些推理的研究理论,比如亚里士多德(Aristotle)进行了演绎推理三段论的完整分析,欧几里得(Euclid)所著Elements是一种形式推理的模型,MuḥammadibnMūsāal-Khwārizmī,发明了代数学,即我们
当前科技领域最有热度的话题,无疑是OpenAI新提出的大规模对话语言模型ChatGPT,一经发布上线,短短五天就吸引了百万用户,仅一个多月的时间月活已然破亿,并且热度一直在持续发酵,各行各业的从业人员、企业机构都开始体验关注甚至自研“类ChatGPT”模型。这里,笔者从一位NLP从业人员的角度谈一谈对ChatGPT的一些看法和思考。1、ChatGPT诞生之路1.1BERT2018年,谷歌提出BERT(BidirectionalEncoderRepresentationfromTransformer)模型,一时之间疯狂屠榜,在各种自然语言处理领域建模任务中取得了最佳的成绩,NLP自此进入了大规模
解开谜团:深入探索ChatGPT的技术奇迹。ChatGpt无处不在,无论是在播客、博客、YouTube还是社交媒体上。当我注意到这项新技术如此受欢迎时,我决定试一试,我被震惊了!有很多关于ChatGpt及其魔力的博客,但在这篇博客中,我将深入探讨其内部技术及其工作原理!ChatGpt简介根据OpenAI,ChatGpt被描述为:“我们训练了一个名为ChatGpt的模型,它以对话方式进行交互。对话格式使ChatGpt可以回答后续问题、承认错误、挑战不正确的前提并拒绝不适当的请求。ChatGPT是InstructGPT的兄弟模型,它经过训练可以按照提示中的说明进行操作并提供详细的响应。”OpenA
以前我们经常打趣说:***,你out了!当然了,玩笑成分居多。但是如果作为一名技术人员,现在还没有听说过ChatGPT,那么你可能真的“out”了。比尔·盖茨说,ChatGPT的重要性堪比互联网的发明,甚至它“将改变我们的世界”。ChatGPT得到科技界大佬的如此推崇,那么,ChatGPT到底是什么?ChatGPT是2022年11月底,美国OpenAI公司推出的一款人工智能聊天机器人。两个月后,ChatGPT的月活用户已经突破1亿,成为有史以来增长速度最快的消费者应用程序。ChatGPT功能极其强大,它能够通过学习和理解人类的语言进行对话,还能根据上下文进行互动,实现像人类一样的聊天交流。除了
近期,AI安全问题闹得沸沸扬扬,多国“禁令”剑指ChatGPT。自然语言大模型采用人类反馈的增强学习机制,也被担心会因人类的偏见“教坏”AI。4月6日,OpenAI官方发声称,从现实世界的使用中学习是创建越来越安全的人工智能系统的“关键组成部分”,该公司也同时承认,这需要社会有足够时间来适应和调整。至于这个时间是多久,OpenAI也没给出答案。大模型背后的“算法黑箱”无法破解,开发它的人也搞不清机器作答的逻辑。十字路口在前,一些自然语言大模型的开发者换了思路,给类似GPT的模型立起规矩,让对话机器人“嘴上能有个把门的”,并“投喂”符合人类利益的训练数据,以便它们输出“更干净”的答案。这些研发