众所周知,Redis = Remote Dictionary Server,即远程字典服务。
是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
redis 会将 key:myLove value:Mia
包装成一个 dictEntry 对象、一个 redisObject 对象,如下图所示:
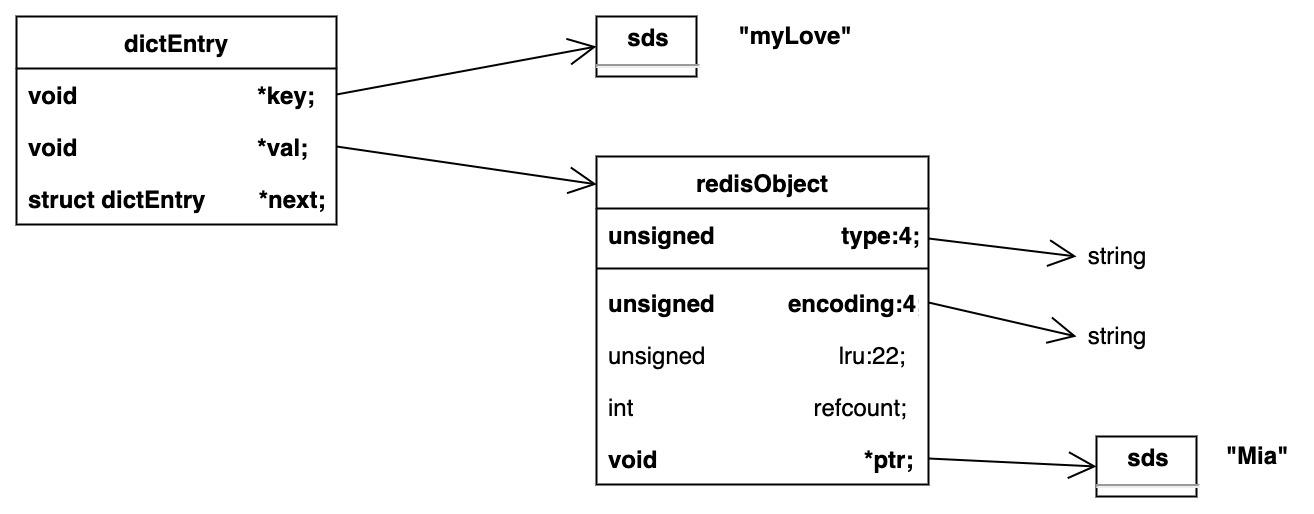
•dictEntry:众所周知,Redis是Key-Value数据库,因此对每个键值对都会有一个dictEntry,里面存储了指向Key和Value的指针;next指向下一个dictEntry,与本Key-Value无关。
•Key:图中右上角可见,Key("myLove")并不是直接以字符串存储,而是存储在SDS结构中。
•redisObject:Value("Mia")既不是直接以字符串存储,也不是像Key一样直接存储在SDS中,而是存储在redisObject中。实际上,不论Value是5种类型的哪一种,都是通过redisObject来存储的;而redisObject中的type字段指明了Value对象的类型,ptr字段则指向对象所在的地址。不过可以看出,字符串对象虽然经过了redisObject的包装,但仍然需要通过SDS存储。
redis内部整体的存储结构是一个大的hashmap,内部是数组实现的hash,key冲突通过挂链表去实现,每个dictEntry为一个key/value对象,value为定义的redisObject。
结构图如下:
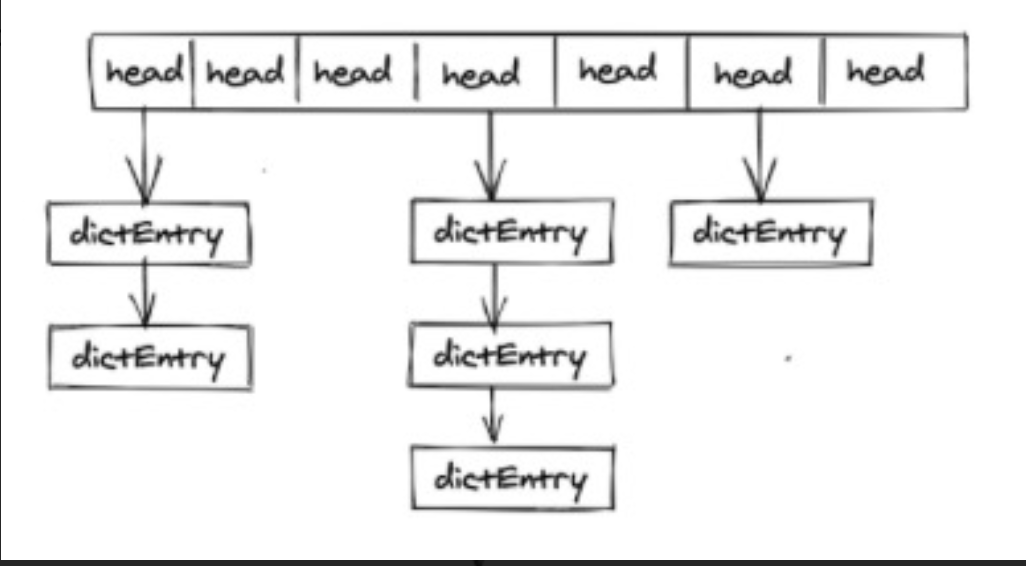
dictEntry是存储key->value的地方,再让我们看一下dictEntry结构体
/*
* 字典
*/
typedef struct dictEntry {
// 键
void *key;
// 值
union {
// 指向具体redisObject
void *val;
//
uint64_t u64;
int64_t s64;
} v;
// 指向下个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;我们接着再往下看redisObject究竟是什么结构的
/*
* Redis 对象
*/
typedef struct redisObject {
// 类型 4bits
unsigned type:4;
// 编码方式 4bits
unsigned encoding:4;
// LRU 时间(相对于 server.lruclock) 24bits
unsigned lru:22;
// 引用计数 Redis里面的数据可以通过引用计数进行共享 32bits
int refcount;
// 指向对象的值 64-bit
void *ptr;
} robj;
*ptr指向具体的数据结构的地址;type表示该对象的类型,即String,List,Hash,Set,Zset中的一个,但为了提高存储效率与程序执行效率,每种对象的底层数据结构实现都可能不止一种,encoding 表示对象底层所使用的编码。
redis对象底层的八种数据结构:
REDIS_ENCODING_INT(long 类型的整数)
REDIS_ENCODING_EMBSTR embstr (编码的简单动态字符串)
REDIS_ENCODING_RAW (简单动态字符串)
REDIS_ENCODING_HT (字典)
REDIS_ENCODING_LINKEDLIST (双端链表)
REDIS_ENCODING_ZIPLIST (压缩列表)
REDIS_ENCODING_INTSET (整数集合)
REDIS_ENCODING_SKIPLIST (跳跃表和字典)
查看 redisObject 详细信息 :
# 查看 key对应value的 redisObject 类型
type key
type myLove
# 查看 key对应value的redisObject 详细信息
debug object key
debug object myLove
value 为 string 、int 类型是 redisObject 中的 type、encoding 不同表现形式
Value 为 string 类型时:

Value 为 int类型时:

以上两种不同 value 类型,type 相同,encoding 不同
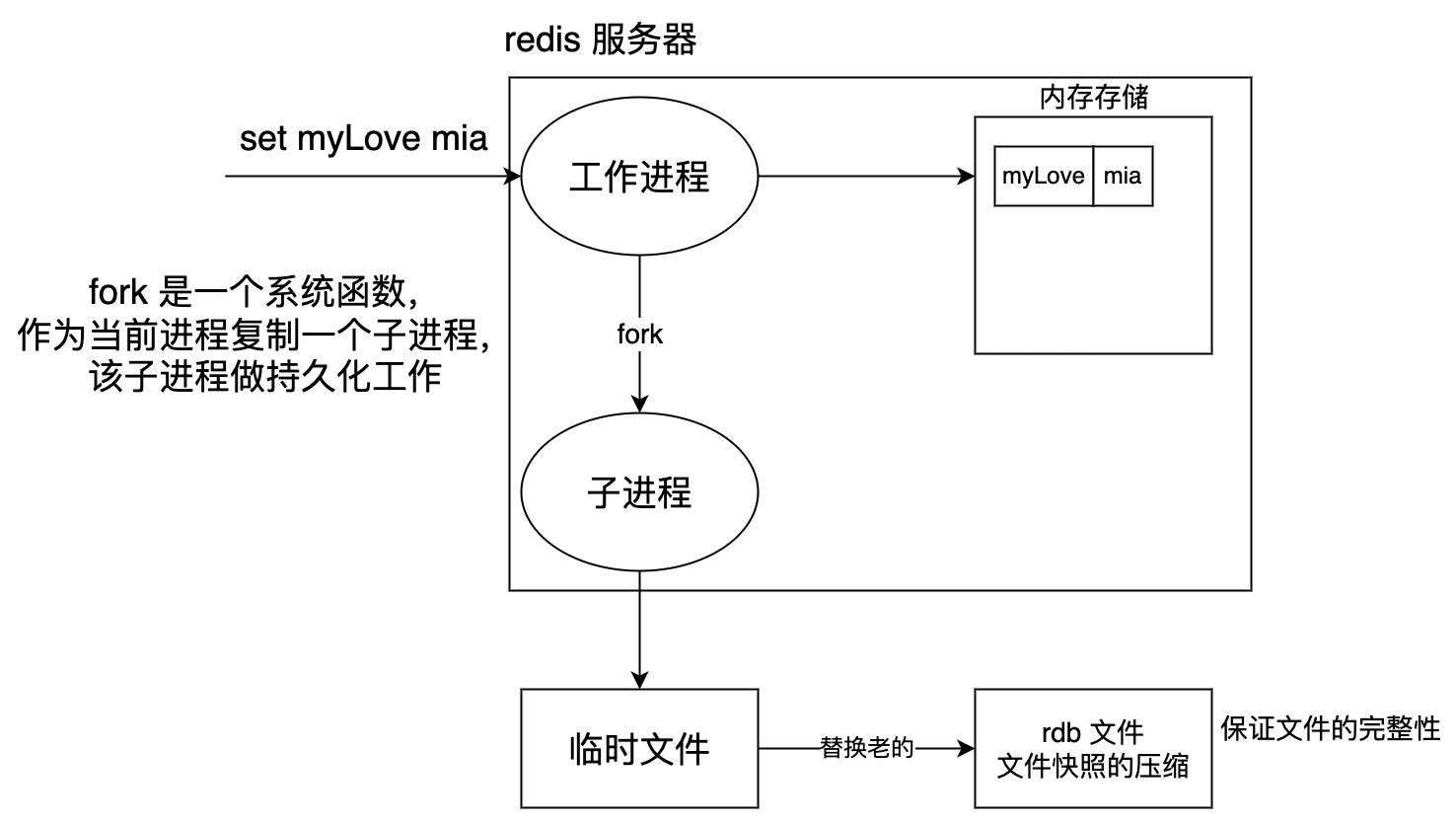
默认情况下 没有开启 AOF ( append only file)
开启 AOF 持久化后,每执行一条会更改 redis 数据的命令,redis就会将写入、修改、删除命令写入到硬盘中的 AOF 文件(当然并不是立即写入文件,而是立即写入aof缓存中,再根据aof配置的数据持久化条件进行写入),这一过程显然会降低 redis 的性能,但大部分情况下这个影响是能够接受的,
另外使用快的硬盘可以提高 AOF 的性能。
配置 redis.conf
# 可以通过修改redis.conf配置文件中的appendonly参数开启
appendonly yes
# AOF文件的保存位置和RDB文件的位置相同,都是通过dir参数设置的。 dir ./
# 默认的文件名是appendonly.aof,可以通过appendfilename参数修改 appendfilename appendonly.aof
Redis 将所有对数据库进行过写入的命令(及其参数)记录到 AOF 文件, 以此达到记录数据库状态的 目的, 为了方便起见, 我们称呼这种记录过程为同步。
命令传播:Redis 将执行完的命令、命令的参数、命令的参数个数等信息发送到 AOF 程序中。 缓存追 加:AOF 程序根据接收到的命令数据,将命令转换为网络通讯协议 RESP 的格式,然后将协议内容追加到服务器的 AOF 缓存中。 文件写入和保存: AOF 缓存中的内容被写入到 AOF 文件末尾,如果设定的 AOF 保存条件被满足的话, fsync 函数或者 fdatasync 函数会被调用,将写入的内容真正地保存到磁盘中。
当一个 Redis 客户端需要执行命令时, 它通过网络连接, 将协议文本发送给 Redis 服务器。服务器在 接到客户端的请求之后, 它会根据协议文本的内容, 选择适当的命令函数, 并将各个参数从字符串文 本转换为 Redis 字符串对象( StringObject )。每当命令函数成功执行之后, 命令参数都会被传播到 AOF 程序。
当命令被传播到 AOF 程序之后, 程序会根据命令以及命令的参数, 将命令从字符串对象转换回原来的 协议文本。协议文本生成之后, 它会被追加到 redis.h/redisServer 结构的 aof_buf 末尾。
redisServer 结构维持着 Redis 服务器的状态, aof_buf 域则保存着所有等待写入到 AOF 文件的协 议文本。
Redis客户端使用RESP(Redis的序列化协议)协议与Redis的服务器端进行通信。 虽然该协议是专门为 Redis设计的,但是该协议也可以用于其他 客户端-服务器 (Client-Server)软件项目。
可以通过特殊符号来区分出数据的类型:
单行回复:以+号开头。
错误回复:以-号开头。
整数回复:以:号开头。
批量回复:以$号开头。
多条批量回复:以*号开头。
1)间隔符号,在Linux下是\r\n,在Windows下是\n
2)简单字符串 Simple Strings, 以 "+"加号 开头
3)错误 Errors, 以"-"减号 开头
4)整数型 Integer, 以 ":" 冒号开头
5)大字符串类型 Bulk Strings, 以 "$"美元符号开头,长度限制512M 6、数组类型 Arrays,以 "*"星号开头 用SET命令来举例说明RESP协议的格式。
实际发送的请求数据:
redis> SET myLove "Mia"
"OK"
*3\r\n$3\r\nSET\r\n$6\r\nmyLove\r\n$3\r\nMia\r\n
*3
$3
SET
$5
mykey
$5
Hello
实际收到的响应数据:
+OK\r\n
文件写入和保存:
每当服务器常规任务函数被执行、 或者事件处理器被执行时, aof.c/flushAppendOnlyFile 函数都会被 调用, 这个函数执行以下两个工作:
WRITE:根据条件,将 aof_buf 中的缓存写入到 AOF 文件。 SAVE:根据条件,调用 fsync 或 fdatasync 函数,将 AOF 文件保存到磁盘中。
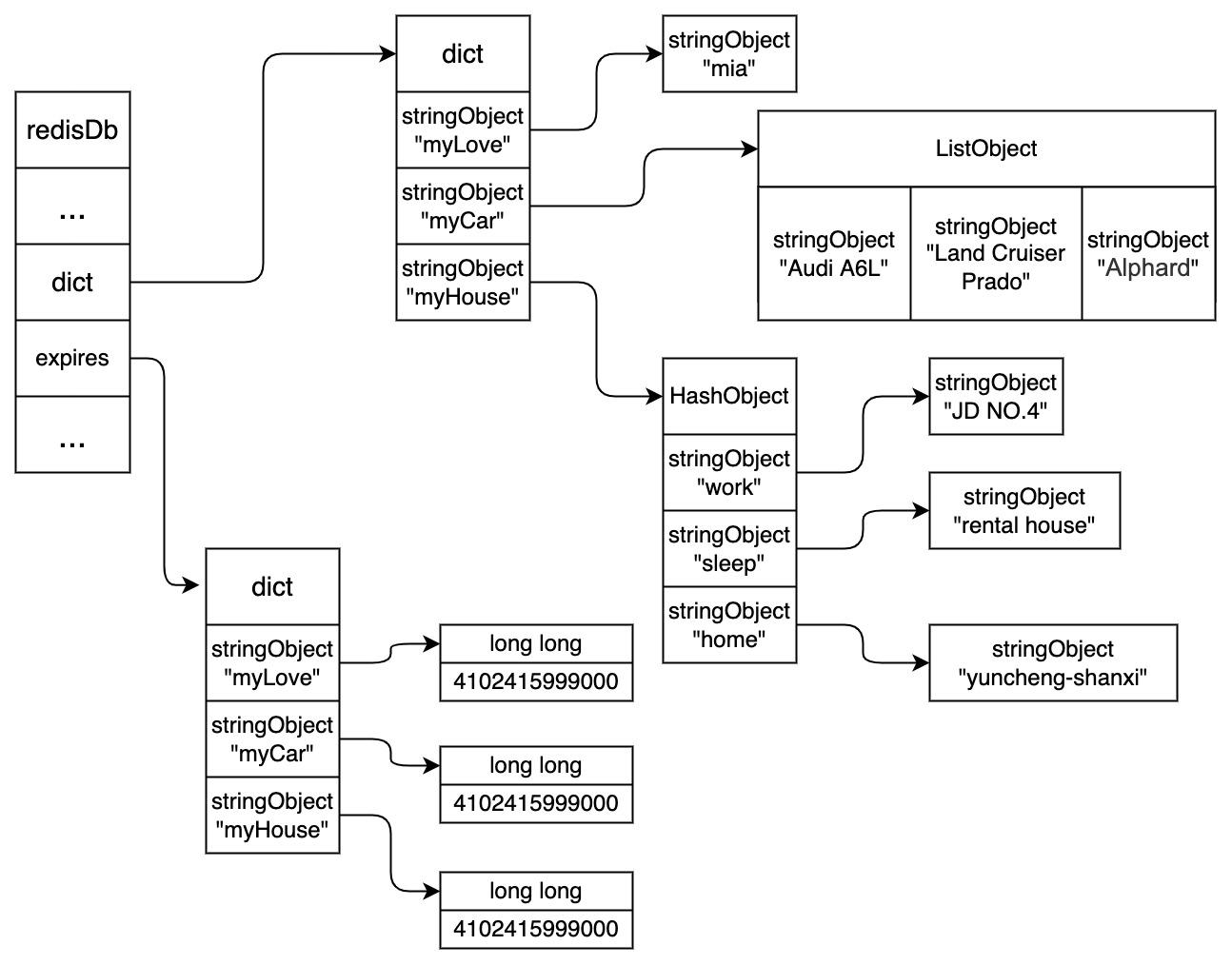
从图可知,在redis的数据库中,redisDb结构中的expires字典中保存了数据库中所有键的过期时间,所以叫过期字典。
过期字典的key是一个指针,指向键空间的某个键对象(就是数据库键)
过期字典的value是一个long类型的整数,这个整数保存了键所指向的数据库键的过期时间,一个毫秒精度的UNIX时间戳
过期键判定
通过过期字典,我们可以得到一个key是否过期:
判断key是否存在于过期字典中
通过过期字典拿到key的过期时间,判断当前UNIX时间戳是否大于key时间
过期key如何删除
惰性删除策略
过期键的惰性删除策略由db.c/expireIfNeeded函数实现,所有读写数据库的Redis命令在执行之前都会调用expireIfNeeded函数对输入键进行检查:
如果输入键已经过期,那么expireIfNeeded函数将输入键从数据库中删除。
如果输入键未过期,那么expireIfNeeded函数不做动作。
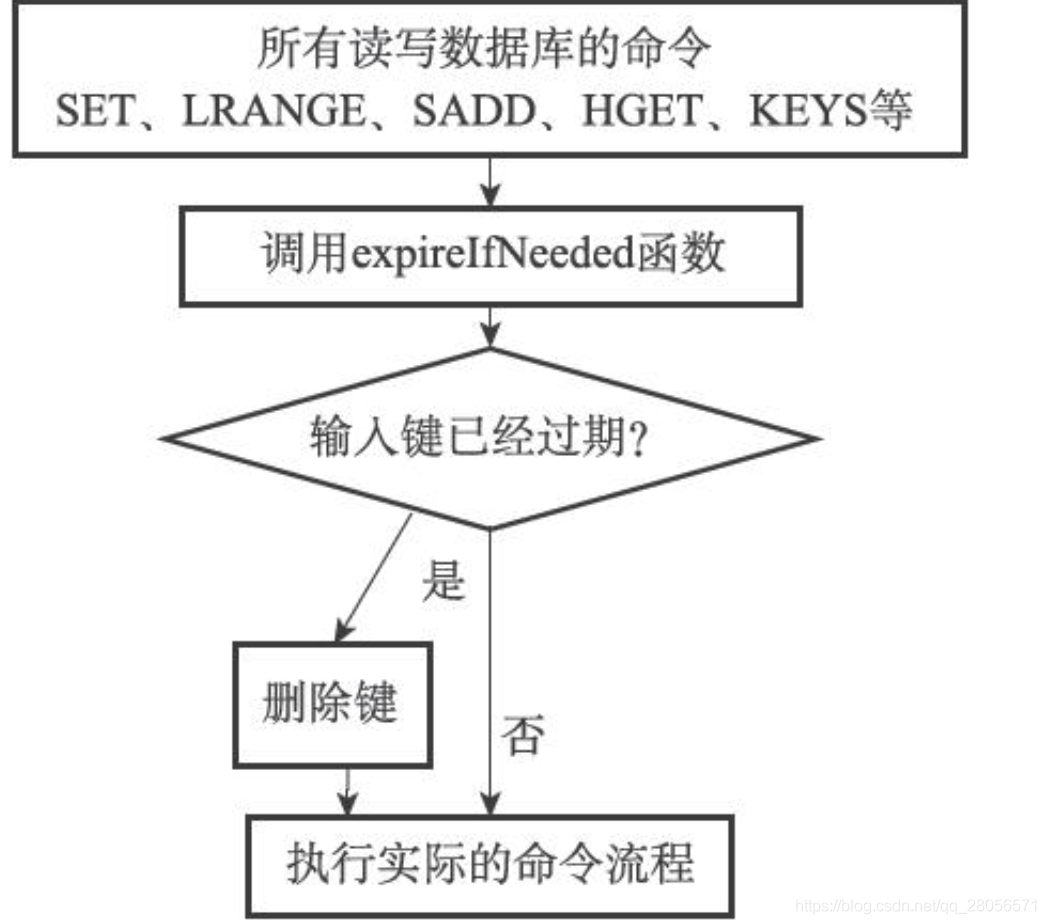
expireIfNeeded函数就像一个过滤器,它可以在命令真正执行之前,过滤掉过期的输入键,从而避免命令接触到过期键。
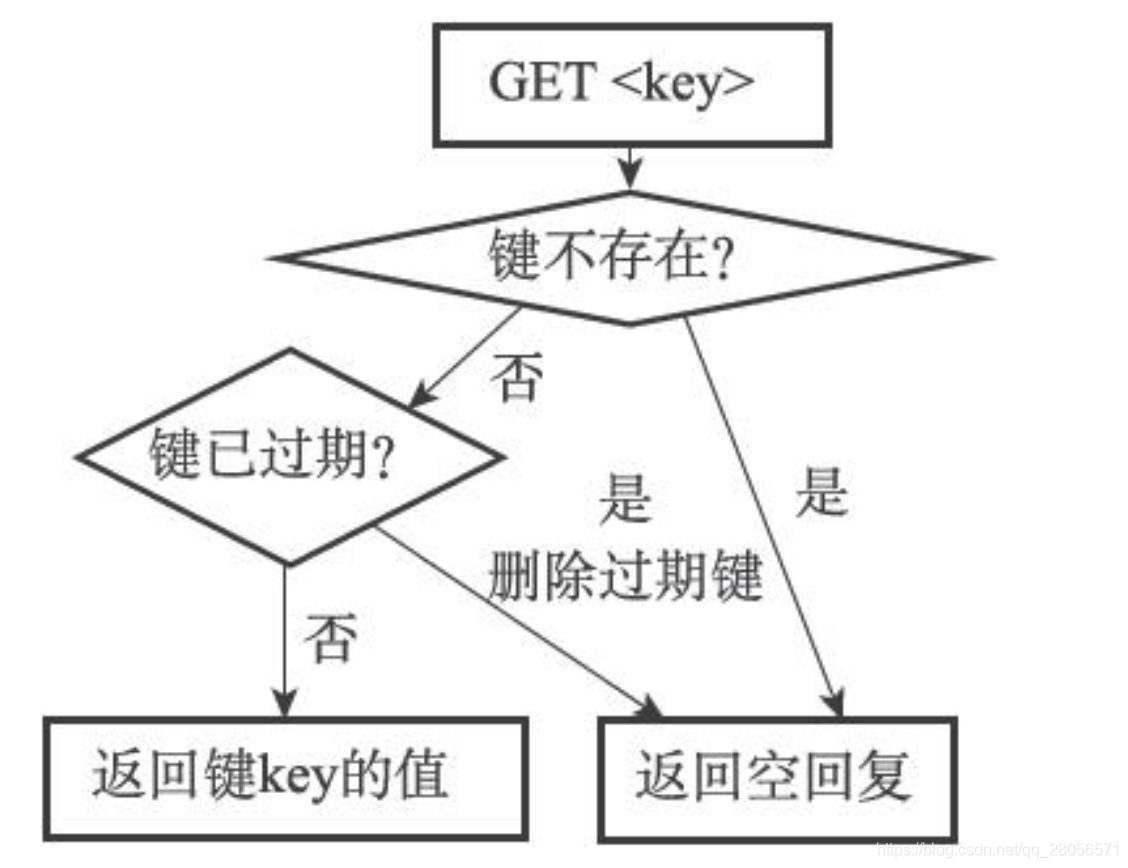
另外,因为每个被访问的键都可能因为过期而被expireIfNeeded函数删除,所以每个命令的实现函数都必须能同时处理键存在以及键不存在这两种情况:
当键存在时,命令按照键存在的情况执行。
当键不存在或者键因为过期而被expireIfNeeded函数删除时,命令按照键不存在的情况执行。
定期删除策略的实现
过期键的定期删除策略由redis.c/activeExpireCycle函数实现,每当Redis的服务器周期性操作redis.c/serverCron函数执行时,activeExpireCycle函数就会被调用,它在规定的时间内,分多次遍历服务器中的各个数据库,从数据库的expires字典中随机检查一部分键的过期时间,并删除其中的过期键。
不好意思,哥们的爱无法删除!
在railstutorial中,作者为什么选择使用这个(代码list10.25):http://ruby.railstutorial.org/chapters/updating-showing-and-deleting-usersnamespace:dbdodesc"Filldatabasewithsampledata"task:populate=>:environmentdoRake::Task['db:reset'].invokeUser.create!(:name=>"ExampleUser",:email=>"example@railstutorial.org",:passwo
我在一段非常简单的代码(如我所想)中得到了一个错误的值:org=4caseorgwhenorg=4val='H'endputsval=>nil请不要生气,我希望我错过了一些非常明显的东西,但我真的想不通。谢谢。 最佳答案 这是典型的Ruby错误。case有两种被调用的方法,一种是你传递一个东西作为分支的基础,另一种是你不传递的东西。如果您确实在case中指定了一个表达式语句然后评估所有其他条件并与===进行比较.在这种情况下org评估为false和org===false显然不是真的。所有其他情况也是如此,它们要么是真的,要么是假的。
我在我的Rails项目中使用rspec_rails和factory_girl_railsgem。所有模型都已创建。是否有我可以运行的生成器来为现有模型创建工厂文件?例如:我已经有了一个Blog模型。RSpec允许我通过简单地运行以下命令在spec/models/blog_spec.rb生成一个模型规范文件:railsgeneraterspec:modelblog是否有我可以在命令行中运行的生成器,它会为这个现有模型生成工厂文件,位于:spec/factories/blogs.rb?我在factory_girl_rails中没有看到任何关于发电机的提及文档。
已修复。Rails中有一个错误。参见https://github.com/rails/rails/issues/2333我对FactoryGirlRails和Rails3.1.0.rc5有疑问当我多次执行user=FactoryGirl.create(:user)时出现错误。Failure/Error:user=FactoryGirl.create(:user)NameError:uninitializedconstantUser::User#./app/models/user.rb:17:in`generate_token'#./app/models/user.rb:4:in`blo
我有一个FactoryGirl工厂,它创建一个Order但before(:create)回调不会创建关联的工厂对象:父类classOrder子类classOrderLine工厂Factory:orderdo...ignoredonumber_or_order_lines1endbefore(:create)do|order,evaluator|FactoryGirl.create_list:order_line,evaluator.number_or_order_lines,order:orderendendFactory:order_linedoassociation:userass
我刚刚进入FactoryGirl,我遇到了一个困难,我相信应该容易得多。我只是无法将文档扭曲成一个工作示例。假设我有以下模型:classLeague我想做的是:team=Factory.build(:team_with_players)并让它为我培养了一批玩家。我试过这个:Factory.define:team_with_players,:class=>:teamdo|t|t.sequence{|n|"team-#{n}"}t.players{|p|25.times{Factory.build(:player,:team=>t)}}end但这在:team=>t部分失败了,因为t并不是真
跟随BenWalker的(惊人的)Let'sBuildInstagramWithRails,特别是BDD版本。教程使用FactoryGirl。我在多次测试中遇到以下错误:精简版Failure/Error:post=create(:post,user_id=user.id)ArgumentError:Traitnotregistered:1我什至无法让Ben用cloneofmyrepo重新创建错误,我在StackOverflow的“特征未注册”问题中找不到任何内容。这是我的第一个SO问题,所以如果我在那个前面做错了什么,请告诉我。在此先感谢您的帮助!代码选择:spec/factories
模型/message.rbclassMessageattr_reader:bundle_id,:order_id,:order_number,:eventdefinitialize(message)hash=message@bundle_id=hash[:payload][:bundle_id]@order_id=hash[:payload][:order_id]@order_number=hash[:payload][:order_number]@event=hash[:concern]endend规范/模型/message_spec.rbrequire'spec_helper'de
或者是否需要外部gem来生成随机且唯一的用户名?这是我现在的工厂:factory:user_4dosequence(:id){|n|n}sequence(:first_name){|n|"Gemini"+n.to_s}sequence(:last_name){|n|"Pollux"+n.to_s}sequence(:profile_name){|n|"GeminiPollux"+n.to_s}sequence(:email){|n|"geminipollus"+n.to_s+"@hotmail.co.uk"}end使用序列方法适用于id、profile_name和电子邮件,但我的REG
当我可以使用before(:each)block时,FactoryGirl在rspec测试中的目的是什么?感觉FactoryGirl和before(:each)之间的唯一区别是工厂在测试之外准备对象创建。这样对吗? 最佳答案 像FactoryGirl这样的gem和Sham允许您为有效和可重用的对象创建模板。它们是为了响应必须将固定记录加载到数据库中的固定装置而创建的。当您实例化对象时,它们允许更多的自定义,它们旨在确保您有一个有效的对象可以使用。它们可以在您的测试中的任何地方以及您的测试前后Hook中使用。before(:each)