
文章目录
命名实体识别(Named Entity Recognition,NER)就是从一段自然语言文本中找出相关实体,并标注出其位置以及类型。是信息提取, 问答系统, 句法分析, 机器翻译等应用领域的重要基础工具, 在自然语言处理技术走向实用化的过程中占有重要地位. 包含行业, 领域专有名词, 如人名, 地名, 公司名, 机构名, 日期, 时间, 疾病名, 症状名, 手术名称, 软件名称等。具体可参看如下示例图:

识别专有名词, 为文本结构化提供支持.
主体识别, 辅助句法分析.
实体关系抽取, 有利于知识推理.
缺点: 适用性差, 维护成本高后期甚至不能维护.
优点: 简单, 快速.
序列标注问题涵盖了自然语言处理中的很多任务, 包括语音识别, 中文分词, 机器翻译, 命名实体识别等, 而常见的序列标注模型包括HMM, CRF, RNN, LSTM, GRU等模型.
其中在命名实体识别技术上, 目前主流的技术是通过BiLSTM+CRF模型进行序列标注, 也是项目中要用到的模型.

简短精炼
形容词相对较少
泛化性相对较小
医学名词错字率比较高
同义词、简称比较多
了解BiLSTM网络结构.
掌握BiLSTM模型实现.
所谓的BiLSTM,就是(Bidirectional LSTM)双向LSTM. 单向的LSTM模型只能捕捉到从前向后传递的信息, 而双向的网络可以同时捕捉正向信息和反向信息, 使得对文本信息的利用更全面, 效果也更好.
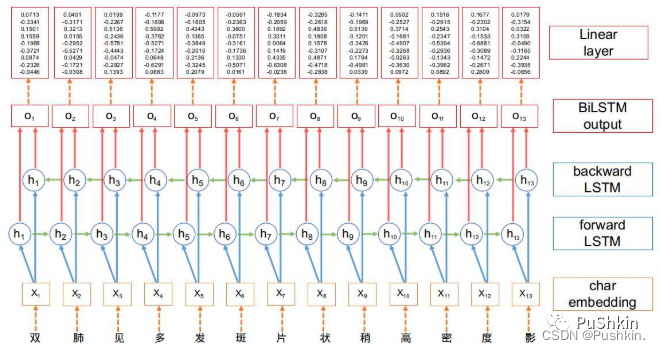
在BiLSTM网络最终的输出层后面增加了一个线性层, 用来将BiLSTM产生的隐藏层输出结果投射到具有某种表达标签特征意义的区间, 具体如下图所示:
第一步: 实现类的初始化和网络结构的搭建.
第二步: 实现文本向量化的函数.
第三步: 实现网络的前向计算.
# 本段代码构建类BiLSTM, 完成初始化和网络结构的搭建
# 总共3层: 词嵌入层, 双向LSTM层, 全连接线性层
import torch
import torch.nn as nn
class BiLSTM(nn.Module):
"""
description: BiLSTM 模型定义
"""
def __init__(self, vocab_size, tag_to_id, input_feature_size, hidden_size,
batch_size, sentence_length, num_layers=1, batch_first=True):
"""
description: 模型初始化
:param vocab_size: 所有句子包含字符大小
:param tag_to_id: 标签与 id 对照
:param input_feature_size: 字嵌入维度( 即LSTM输入层维度 input_size )
:param hidden_size: 隐藏层向量维度
:param batch_size: 批训练大小
:param sentence_length 句子长度
:param num_layers: 堆叠 LSTM 层数
:param batch_first: 是否将batch_size放置到矩阵的第一维度
"""
# 类继承初始化函数
super(BiLSTM, self).__init__()
# 设置标签与id对照
self.tag_to_id = tag_to_id
# 设置标签大小, 对应BiLSTM最终输出分数矩阵宽度
self.tag_size = len(tag_to_id)
# 设定LSTM输入特征大小, 对应词嵌入的维度大小
self.embedding_size = input_feature_size
# 设置隐藏层维度, 若为双向时想要得到同样大小的向量, 需要除以2
self.hidden_size = hidden_size // 2
# 设置批次大小, 对应每个批次的样本条数, 可以理解为输入张量的第一个维度
self.batch_size = batch_size
# 设定句子长度
self.sentence_length = sentence_length
# 设定是否将batch_size放置到矩阵的第一维度, 取值True, 或False
self.batch_first = batch_first
# 设置网络的LSTM层数
self.num_layers = num_layers
# 构建词嵌入层: 字向量, 维度为总单词数量与词嵌入维度
# 参数: 总体字库的单词数量, 每个字被嵌入的维度
self.embedding = nn.Embedding(vocab_size, self.embedding_size)
# 构建双向LSTM层: BiLSTM (参数: input_size 字向量维度(即输入层大小),
# hidden_size 隐藏层维度,
# num_layers 层数,
# bidirectional 是否为双向,
# batch_first 是否批次大小在第一位)
self.bilstm = nn.LSTM(input_size=input_feature_size,
hidden_size=self.hidden_size,
num_layers=num_layers,
bidirectional=True,
batch_first=batch_first)
# 构建全连接线性层: 将BiLSTM的输出层进行线性变换
self.linear = nn.Linear(hidden_size, self.tag_size)
输入参数:
# 参数1:码表与id对照
char_to_id = {"双": 0, "肺": 1, "见": 2, "多": 3, "发": 4, "斑": 5, "片": 6,
"状": 7, "稍": 8, "高": 9, "密": 10, "度": 11, "影": 12, "。": 13}
# 参数2:标签码表对照
tag_to_id = {"O": 0, "B-dis": 1, "I-dis": 2, "B-sym": 3, "I-sym": 4}
# 参数3:字向量维度
EMBEDDING_DIM = 200
# 参数4:隐层维度
HIDDEN_DIM = 100
# 参数5:批次大小
BATCH_SIZE = 8
# 参数6:句子长度
SENTENCE_LENGTH = 20
# 参数7:堆叠 LSTM 层数
NUM_LAYERS = 1
调用:
# 初始化模型
model = BiLSTM(vocab_size=len(char_to_id),
tag_to_id=tag_to_id,
input_feature_size=EMBEDDING_DIM,
hidden_size=HIDDEN_DIM,
batch_size=BATCH_SIZE,
sentence_length=SENTENCE_LENGTH,
num_layers=NUM_LAYERS)
print(model)
输出效果:
BiLSTM(
(embedding): Embedding(14, 200)
(bilstm): LSTM(200, 50, batch_first=True, bidirectional=True)
(linear): Linear(in_features=100, out_features=5, bias=True)
)
# 本函数实现将中文文本映射为数字化的张量
def sentence_map(sentence_list, char_to_id, max_length):
"""
description: 将句子中的每一个字符映射到码表中
:param sentence: 待映射句子, 类型为字符串或列表
:param char_to_id: 码表, 类型为字典, 格式为{"字1": 1, "字2": 2}
:return: 每一个字对应的编码, 类型为tensor
"""
# 字符串按照逆序进行排序, 不是必须操作
sentence_list.sort(key=lambda c:len(c), reverse=True)
# 定义句子映射列表
sentence_map_list = []
for sentence in sentence_list:
# 生成句子中每个字对应的 id 列表
sentence_id_list = [char_to_id[c] for c in sentence]
# 计算所要填充 0 的长度
padding_list = [0] * (max_length-len(sentence))
# 组合
sentence_id_list.extend(padding_list)
# 将填充后的列表加入句子映射总表中
sentence_map_list.append(sentence_id_list)
# 返回句子映射集合, 转为标量
return torch.tensor(sentence_map_list, dtype=torch.long)
输入参数:
# 参数1:句子集合
sentence_list = [
"确诊弥漫大b细胞淋巴瘤1年",
"反复咳嗽、咳痰40年,再发伴气促5天。",
"生长发育迟缓9年。",
"右侧小细胞肺癌第三次化疗入院",
"反复气促、心悸10年,加重伴胸痛3天。",
"反复胸闷、心悸、气促2多月,加重3天",
"咳嗽、胸闷1月余, 加重1周",
"右上肢无力3年, 加重伴肌肉萎缩半年"]
# 参数2:码表与id对照
char_to_id = {"<PAD>":0}
# 参数3:句子长度
SENTENCE_LENGTH = 20
调用:
if __name__ == '__main__':
for sentence in sentence_list:
# 获取句子中的每一个字
for _char in sentence:
# 判断是否在码表 id 对照字典中存在
if _char not in char_to_id:
# 加入字符id对照字典
char_to_id[_char] = len(char_to_id)
# 将句子转为 id 并用 tensor 包装
sentences_sequence = sentence_map(sentence_list, char_to_id, SENTENCE_LENGTH)
print("sentences_sequence:\n", sentences_sequence)
输出效果:
sentences_sequence:
tensor([[14, 15, 16, 17, 18, 16, 19, 20, 21, 13, 22, 23, 24, 25, 26, 27, 28, 29, 30, 0],
[14, 15, 26, 27, 18, 49, 50, 12, 21, 13, 22, 51, 52, 25, 53, 54, 55, 29, 30, 0],
[14, 15, 53, 56, 18, 49, 50, 18, 26, 27, 57, 58, 59, 22, 51, 52, 55, 29, 0, 0],
[37, 63, 64, 65, 66, 55, 13, 22, 61, 51, 52, 25, 67, 68, 69, 70, 71, 13, 0, 0],
[37, 38, 39, 7, 8, 40, 41, 42, 43, 44, 45, 46, 47, 48, 0, 0, 0, 0, 0, 0],
[16, 17, 18, 53, 56, 12, 59, 60, 22, 61, 51, 52, 12, 62, 0, 0, 0, 0, 0, 0],
[ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 0, 0, 0, 0, 0, 0, 0],
[31, 32, 24, 33, 34, 35, 36, 13, 30, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]])
# 本函数实现类BiLSTM中的前向计算函数forward()
def forward(self, sentences_sequence):
"""
description: 将句子利用BiLSTM进行特征计算,分别经过Embedding->BiLSTM->Linear,
获得发射矩阵(emission scores)
:param sentences_sequence: 句子序列对应的编码,
若设定 batch_first 为 True,
则批量输入的 sequence 的 shape 为(batch_size, sequence_length)
:return: 返回当前句子特征,转化为 tag_size 的维度的特征
"""
# 初始化隐藏状态值
h0 = torch.randn(self.num_layers * 2, self.batch_size, self.hidden_size)
# 初始化单元状态值
c0 = torch.randn(self.num_layers * 2, self.batch_size, self.hidden_size)
# 生成字向量, shape 为(batch, sequence_length, input_feature_size)
# 注:embedding cuda 优化仅支持 SGD 、 SparseAdam
input_features = self.embedding(sentences_sequence)
# 将字向量与初始值(隐藏状态 h0 , 单元状态 c0 )传入 LSTM 结构中
# 输出包含如下内容:
# 1, 计算的输出特征,shape 为(batch, sentence_length, hidden_size)
# 顺序为设定 batch_first 为 True 情况, 若未设定则 batch 在第二位
# 2, 最后得到的隐藏状态 hn , shape 为(num_layers * num_directions, batch, hidden_size)
# 3, 最后得到的单元状态 cn , shape 为(num_layers * num_directions, batch, hidden_size)
output, (hn, cn) = self.bilstm(input_features, (h0, c0))
# 将输出特征进行线性变换,转为 shape 为 (batch, sequence_length, tag_size) 大小的特征
sequence_features = self.linear(output)
# 输出线性变换为 tag 映射长度的特征
return sequence_features
输入参数:
# 参数1:标签码表对照
tag_to_id = {"O": 0, "B-dis": 1, "I-dis": 2, "B-sym": 3, "I-sym": 4}
# 参数2:字向量维度
EMBEDDING_DIM = 200
# 参数3:隐层维度
HIDDEN_DIM = 100
# 参数4:批次大小
BATCH_SIZE = 8
# 参数5:句子长度
SENTENCE_LENGTH = 20
# 参数6:堆叠 LSTM 层数
NUM_LAYERS = 1
char_to_id = {"<PAD>":0}
SENTENCE_LENGTH = 20
调用:
if __name__ == '__main__':
for sentence in sentence_list:
for _char in sentence:
if _char not in char_to_id:
char_to_id[_char] = len(char_to_id)
sentence_sequence = sentence_map(sentence_list, char_to_id, SENTENCE_LENGTH)
model = BiLSTM(vocab_size=len(char_to_id), tag_to_id=tag_to_id, input_feature_size=EMBEDDING_DIM, \
hidden_size=HIDDEN_DIM, batch_size=BATCH_SIZE, sentence_length=SENTENCE_LENGTH, num_layers=NUM_LAYERS)
sentence_features = model(sentence_sequence)
print("sequence_features:\n", sentence_features)
输出效果:
sequence_features:
tensor([[[ 4.0880e-02, -5.8926e-02, -9.3971e-02, 8.4794e-03, -2.9872e-01],
[ 2.9434e-02, -2.5901e-01, -2.0811e-01, 1.3794e-02, -1.8743e-01],
[-2.7899e-02, -3.4636e-01, 1.3382e-02, 2.2684e-02, -1.2067e-01],
[-1.9069e-01, -2.6668e-01, -5.7182e-02, 2.1566e-01, 1.1443e-01],
...
[-1.6844e-01, -4.0699e-02, 2.6328e-02, 1.3513e-01, -2.4445e-01],
[-7.3070e-02, 1.2032e-01, 2.2346e-01, 1.8993e-01, 8.3171e-02],
[-1.6808e-01, 2.1454e-02, 3.2424e-01, 8.0905e-03, -1.5961e-01],
[-1.9504e-01, -4.9296e-02, 1.7219e-01, 8.9345e-02, -1.4214e-01]],
...
[[-3.4836e-03, 2.6217e-01, 1.9355e-01, 1.8084e-01, -1.6086e-01],
[-9.1231e-02, -8.4838e-04, 1.0575e-01, 2.2864e-01, 1.6104e-02],
[-8.7726e-02, -7.6956e-02, -7.0301e-02, 1.7199e-01, -6.5375e-02],
[-5.9306e-02, -5.4701e-02, -9.3267e-02, 3.2478e-01, -4.0474e-02],
[-1.1326e-01, 4.8365e-02, -1.7994e-01, 8.1722e-02, 1.8604e-01],
...
[-5.8271e-02, -6.5781e-02, 9.9232e-02, 4.8524e-02, -8.2799e-02],
[-6.8400e-02, -9.1515e-02, 1.1352e-01, 1.0674e-02, -8.2739e-02],
[-9.1461e-02, -1.2304e-01, 1.2540e-01, -4.2065e-02, -8.3091e-02],
[-1.5834e-01, -8.7316e-02, 7.0567e-02, -8.8845e-02, -7.0867e-02]],
[[-1.4069e-01, 4.9171e-02, 1.4314e-01, -1.5284e-02, -1.4395e-01],
[ 6.5296e-02, 9.3255e-03, -2.8411e-02, 1.5143e-01, 7.8252e-02],
[ 4.1765e-03, -1.4635e-01, -4.9798e-02, 2.7597e-01, -1.0256e-01],
...
[-3.9810e-02, -7.6746e-03, 1.2418e-01, 4.9897e-02, -8.4538e-02],
[-3.4474e-02, -1.0586e-02, 1.3861e-01, 4.0395e-02, -8.3676e-02],
[-3.4092e-02, -2.3208e-02, 1.6097e-01, 2.3498e-02, -8.3332e-02],
[-4.6900e-02, -5.0335e-02, 1.8982e-01, 3.6287e-03, -7.8078e-02],
[-6.4105e-02, -4.2628e-02, 1.8999e-01, -2.9888e-02, -1.1875e-01]]],
grad_fn=<AddBackward0>)
输出结果说明: 该输出结果为输入批次中句子的特征, 利用线性变换分别对应到每个tag的得分. 例如上述标量第一个值:[ 4.0880e-02, -5.8926e-02, -9.3971e-02, 8.4794e-03, -2.9872e-01]表示的意思为第一个句子第一个字分别被标记为[“O”, “B-dis”, “I-dis”, “B-sym”, “I-sym”]的分数, 由此可以判断, 在这个例子中, 第一个字被标注为"O"的分数最高.
添加文本向量化的辅助函数, 注意padding填充为相同长度的Tensor
要注意forward函数中不同张量的形状约定
设置隐藏层维度的时候, 需要将hidden_size // 2
总共有3层需要构建, 分别是词嵌入层, 双向LSTM层, 全连接线性层
在代码层面, 双向LSTM就是将nn.LSTM()中的参数bidirectional设置为True

关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
基础版云数据库RDS的产品系列包括基础版、高可用版、集群版、三节点企业版,本文介绍基础版实例的相关信息。RDS基础版实例也称为单机版实例,只有单个数据库节点,计算与存储分离,性价比超高。说明RDS基础版实例只有一个数据库节点,没有备节点作为热备份,因此当该节点意外宕机或者执行重启实例、变更配置、版本升级等任务时,会出现较长时间的不可用。如果业务对数据库的可用性要求较高,不建议使用基础版实例,可选择其他系列(如高可用版),部分基础版实例也支持升级为高可用版。基础版与高可用版的对比拓扑图如下所示。优势 性能由于不提供备节点,主节点不会因为实时的数据库复制而产生额外的性能开销,因此基础版的性能相对于
我使用irb。下面是我写的代码。“斧头”..“bc”我期待"ax""ay""az""ba"bb""bc"但结果只是“斧头”..“bc”我该如何纠正?谢谢。 最佳答案 >puts("ax".."bc").to_aaxayazbabbbc 关于ruby-从结束值创建一系列字符串,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/7617092/
使用RubyonRails,我使用给定的增量(例如每30分钟)用时间填充“选择”。目前我正在YAML文件中写出所有的可能性,但我觉得有一种更巧妙的方法。我想我想提供一个开始时间、一个结束时间、一个增量,并且目前只提供一个名为“关闭”的选项(想想“business_hours”)。所以,我的选择可能会显示:'Closed'5:00am5:30am6:00am...[allthewayto]...11:30pm谁能想出更好的方法,或者只是将它们全部“拼写”出来的最佳方法? 最佳答案 此答案基于@emh的答案。defcreate_hour
最近在工作中,看到一些新手测试同学,对接口测试存在很多疑问,甚至包括一些从事软件测试3,5年的同学,在聊到接口时,也是一知半解;今天借着这个机会,对接口测试做个实战教学,顺便总结一下经验,分享给大家。计划拆分成4个模块跟大家做一个分享,(接口测试、接口基础知识、接口自动化、接口进阶)感兴趣的小伙伴记得关注,希望对你的日常工作和求职面试,带来一些帮助。注:文章较长有5000多字,希望小伙伴们认真看完,当然有些内容对小白同学不是太友好,如果你需要详细了解其中的一些概念或者名词,请在文章之后留言,后续我将针对大家的疑问,整理输出一些大家感兴趣的文章。随着开发模式的迭代更新,前后端分离已不是新的概念,
有道无术,术尚可求,有术无道,止于术。本系列SpringBoot版本3.0.4本系列SpringSecurity版本6.0.2本系列SpringAuthorizationServer版本1.0.2源码地址:https://gitee.com/pearl-organization/study-spring-security-demo文章目录前言1.OAuth2AuthorizationServerMetadataEndpointFilter2.OAuth2AuthorizationEndpointFilter3.OidcProviderConfigurationEndpointFilter4.N
目录FIFO一.自定义同步FIFO1.1代码设计1.2Testbech1.3行为仿真***学习位宽计算函数$clog2()***$clog2()系统函数使用,可以不关注***分布式资源或者BLOCKBRAM二.异步FIFO2.1在FIFO判满的时候有两种方式:2.2异步FIFO为什么要使用格雷码2.2.1介绍格雷码2.2.2格雷码在异步FIFO中的应用2.2.2格雷码判满2.4二进制与格雷码之间的转换2.4.1二进制码转换为格雷码的方法2.4.2格雷码转换为二进制码的方法2.3实现框图2.5实现及仿真代码2.6仿真图验证2.7结论FIFO 这篇更多的是记录FIFO学习,参考了众多优秀的文章,