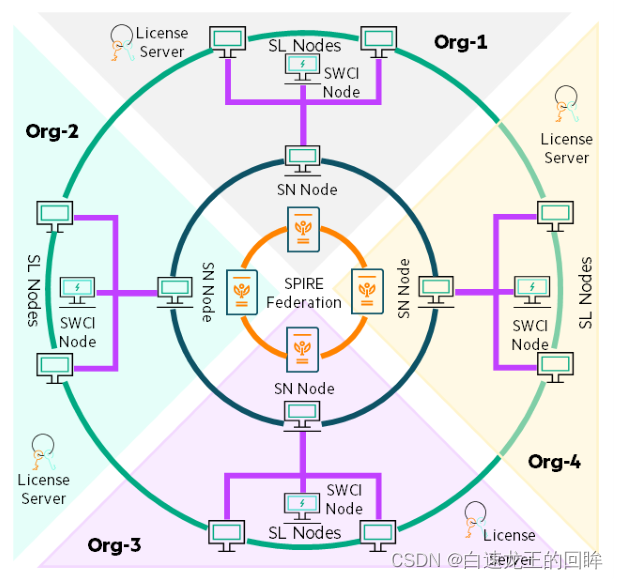
先上一幅Swarm Learning 的架构图镇楼
我们希望实现激励的可协调,也就是让每个节点可以可信地分享reputation的信息
我们引进可转移支付方案,让节点可信地共享reputation信息
我们还通过密码学的方法整合reputation信息
1.如果节点报告reputation信息,别人就会掌握有利的信息,从而对自己不利
2.如果反馈真实的正反馈reputation,节点会由于其余节点的average降低自己的reputation,同时也造成了对稀缺资源的更多需求(我的理解是:reputation比较高的话,别人会认为这个节点可靠,从而向其进行交易需求等)
3.如果反馈虚假的负反馈,节点可以增加自己的reputation,同时减少对稀有资源的需求,所以大家倾向提供虚假信息
我们希望设计一个博弈论模型来让一个理性的节点愿意去分享真实的reputation信息
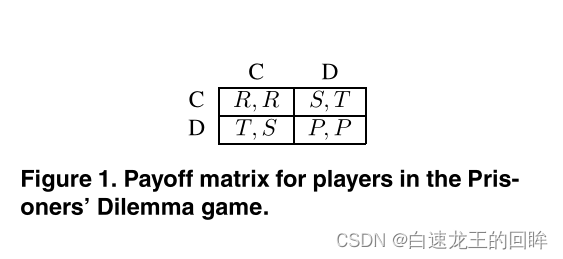
祭上一个囚徒困境的图
我们希望让每一个节点觉得报告真实的信息是有利益的
在我们的机制中,我们引入一个R-agents,负责购买和销售reputation 信息
在博弈游戏中,两个节点要么选择合作要么选择欺骗
游戏双方开始游戏前可以协商合同,但合同不具备强制性
1.先验类型(固定的概率) =》 innate
2.这个节点的前k次动作 =》 mood
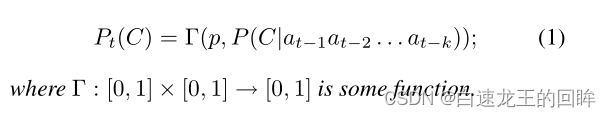
这里的意思是在时间t某个节点何合作的可能性公式
每个节点可以从R-agent处以F的价格买reputation信息,也可以以F‘的价格卖reputation信息
节点只能够卖出一些它们买入的其他节点的reputation信息
当两个节点要开始游戏前,它们需要支付给R-agent钱来询问对方的reputation
注意,买reputation的钱和游戏中获得的钱不通用
如果一个node用完了它买reputation的钱,就不能再买
1.两个节点随机组合
2.通过R-agent询问reputation
3.决定是否玩游戏
4.若同意玩,进入协商合约阶段
5.若同意合约,开始玩游戏
6.游戏中,可以记录对方的信用,从而生成报告给R-agent
因为我们的支付函数可以诱使节点公布诚实的reputation信息
由于我们不能保证从R-agent那里获取的reputation的正确性,我们的支付函数依赖于未来的情况

小s是A对B的report
大S是后续其他节点的B的reports
他可以证明,如果A说真话(真实的s)可以使得它的收益最大化
若节点的gamma函数不依赖于之前的actions,那么没有支付函数可以有效诱使诚实的行为
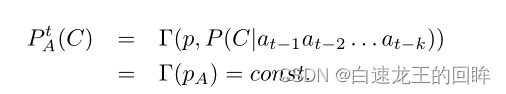
由于A的诚实概率(reputation)不受之前行为的影响,所以是恒定的
所以它的大S(未来的reports)可以认为和目前是完全一致的S = Sc = Sd
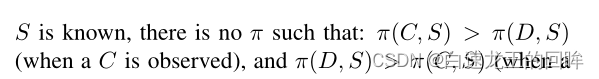
因此说真话肯定不可能总是有好处
这个要看pi(C,S) and pi(D,S)的大小决定~
这个结果令人震惊,因为很多reputation系统都是只关注先验类型对行为的影响
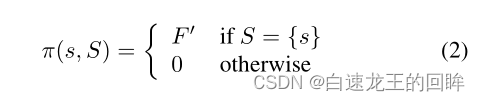
R-agent只有当下一次关于B的report:S和之前A的report:s相同的时候,才会支付给A报酬F’
如果满足Def1和Eq2,那么报告真实的reputation信息就是一个纳什均衡
which means, 如果下一个节点讲真话, ‘我’也最好讲真话
概率证明:B在连续两次动作中采用相同的概率大于等于0.5
这个Eq2只能保证系统前期交互的安全的
还有一些问题:Eq2中的支付函数需要引入一些节点行为参数才可以保证长期稳定~~
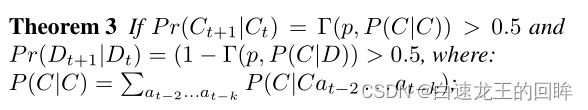
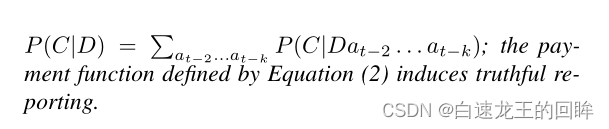
两个概率指的是假设连续在t时间干了X行为的条件下t+1时间还是保持X行为的概率是大于5成的话
Eq2总会诱使它们交出真实的reputation报告

条件:A观察到B是正常的合作
如果它诚实报告1的收益期望就是E[pi(1,S)]
然后根据B下一次可能的行为展开条件概率求和就可以得到一头一尾
注意:我们假设下一个汇报B者是诚实的
我们这里采用两阶段假设和证明,表明了在模型的前期和后期都会让各个节点倾向于说真话
R-agent变成blockchain node可行吗?(负责买卖?不能以明文记录reputation)
分开game 的money 和reputation的money有什么好处?
1.worker selection based on reputation可防止不可靠的模型更新
2.使用多权重主观逻辑模型计算reputation然后用联盟链存reputation
3.基于契约理论的激励机制促进高reputation的worker拥有高quality数据来参与训练防止攻击
4.实验表明这个方案很好很精确。。。
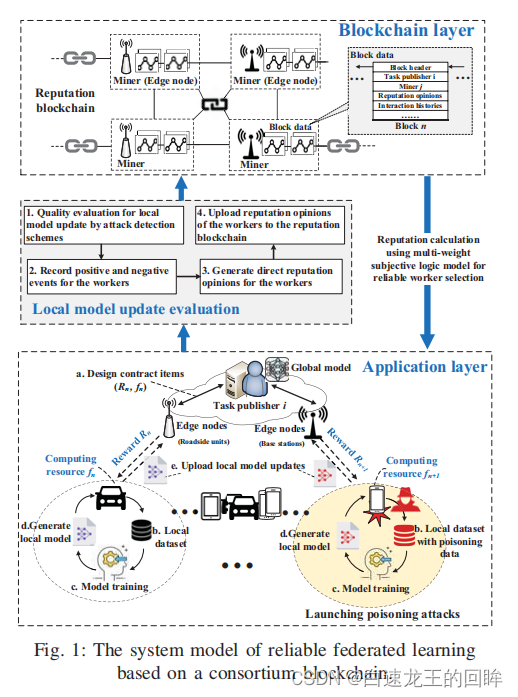
worker:本地数据集、本地模型训练、生成本地模型、计算资源Fn
task publisher:分配task、计算每个worker提供的模型质量、生成reputation、reputation上链
reputation是评估worker可靠性的重要因素:综合direct reputation和在链上记录的最近几次的indirect reputation计算
step1: task publishers发布FL的任务和合约条款,有相关的数据类型、大小和精确度、时间和CPUT的要求。如果workers觉得可以满足就加入任务,然后给予回应给task publisher
step2:基于direct的reputation和存在链上的indirect的reputation得到综合的reputation;reputation的计算是某种加权平均(交互的效果、交互的新鲜度 =》 direct)(跟其他recommender的worker相似度 =》 indirect)
step3:选出reputation大于某个阈值的作为worker,worker根据他们的条件选择一个最优的合同项进行签署
step4:开始进行FL,然后评估各个worker更新的本地模型
通过两个攻击检测算法评估模型
1.Reject on Negative Influence(RONI)投毒检测方案(IID),通过比较包含和剔除某个本地模型,如果加入这个本地模型后,总体表现下降超过一定阈值,则拒绝这个本地模型
2.FoolsGold方案(non IID)通过某个本地模型的梯度更新差异来识别不可靠的worker,由于non-IID 的梯度变化遵循一定的分布函数,如果worker重复上传相似度高的梯度就会被检测出来
基于上述两个方案,task publishers可以移除不可靠节点,然后用联邦平均更新模型
训练完成后,每个可靠的worker根据之前签订合约中的内容,获取与资源贡献和模型训练行为对等的奖励
恶意节点的交互会被task publishers记录下来
step5:更新联盟链中的reputation,task publishers更新direct的reputation,这些reputation会被workers数字签名从而不可抵赖(应该是合约中签订的),然后这些reputation提供给以后的task publishers作为indirect参考
原则:鼓励high-reputation high-quality data的worker加入模型训练
1.task publisher 由于缺乏先验知识并不知道哪些worker希望加入到训练中
2.对于task publisher而言,worker的reputation和data quality是未知的
3.task publisher也不知道worker的可用计算资源和数据量
1、2、3 =》 task publisher在给worker激励的时候会有太多的消耗
因此,本文设计了基于契约理论的激励机制
A:worker在一次迭代中的CPU消耗
B:worker在一次迭代中的通信消耗
C:worker按照数据质量进行分级
D:task publisher对type-n worker一次迭代花费时间的满意度函数
因此,由于有了契约理论,恶意节点是不会签署比他等级要高的合约的(否则拿不到奖励)
从而也可以激励高质量的节点加入FL中
reward min?max?sum?(worker应该怎么选择合同签署,具体奖励如何分配?)
pre-set reward 放到 smart contract可行吗?(pre-set reward指的是契约中约定的奖励)
合约里面包括digital signature?(让reputation绑定具体的worker)
每个等级的合同的钱怎么设计?(不同数据质量的奖励梯度如何划分?)
一开始的reputation不确定,worker selection都是基于一定的reputation基础的(初始阶段怎么判断?)
我最喜欢的Google文档功能之一是它会在我工作时不断自动保存我的文档版本。这意味着即使我在进行关键更改之前忘记在某个点进行保存,也很有可能会自动创建一个保存点。至少,我可以将文档恢复到错误更改之前的状态,并从该点继续工作。对于在MacOS(或UNIX)上运行的Ruby编码器,是否有具有等效功能的工具?例如,一个工具会每隔几分钟自动将Gitcheckin我的本地存储库以获取我正在处理的文件。也许我有点偏执,但这点小保险可以让我在日常工作中安心。 最佳答案 虚拟机有些人可能讨厌我对此的回应,但我在编码时经常使用VIM,它具有自动保存功
我希望用户从一个模型的三个选项中选择一个。即我有一个模型视频,可以被评为正面/负面/未知目前我有三列bool值(pos/neg/unknown)。这是处理这种情况的最佳方式吗?为此,表单应该是什么样的?目前我有类似的东西但显然它允许多项选择,而我试图将它限制为只有一个..怎么办? 最佳答案 如果要使用字符串列,让我们说rating。然后在你的表单中:#...#...它只允许一个选择编辑完全相同但使用radio_button_tag: 关于ruby-on-rails-Rails单选按钮-模
a=[3,4,7,8,3]b=[5,3,6,8,3]假设数组长度相同,是否有办法使用each或其他一些惯用方法从两个数组的每个元素中获取结果?不使用计数器?例如获取每个元素的乘积:[15,12,42,64,9](0..a.count-1).eachdo|i|太丑了...ruby1.9.3 最佳答案 使用Array.zip怎么样?:>>a=[3,4,7,8,3]=>[3,4,7,8,3]>>b=[5,3,6,8,3]=>[5,3,6,8,3]>>c=[]=>[]>>a.zip(b)do|i,j|c[[3,5],[4,3],[7,6],
我写了很多initialize代码,将attrs设置为参数,类似于:classSiteClientattr_reader:login,:password,:domaindefinitialize(login,password,domain='somedefaultsite.com')@login=login@password=password@domain=domainendend有没有更像Ruby的方式来做到这一点?我觉得我在一遍又一遍地编写相同的样板设置代码。 最佳答案 您可以使用rubyStruct:classMyClass或
在使用rails4和https://github.com/globalize/globalize的情况下,我应该如何为我的模型编写表单?用于翻译。我想以一种形式显示所有翻译,如下例所示。我在这里找到了解决方案https://github.com/rilla/batch_translations但我不知道如何实现它。这个“批量翻译”是一个gem还是什么?以及如何安装它。EditingpostEnglish(defaultlocale)SpanishtranslationFrenchtranslation 最佳答案 批处理翻译gem很旧
我使用Ruby编程已经有一段时间了,现在只使用Ruby的标准MRI实现,但我一直对我经常听到的其他实现感到好奇。前几天我在读有关Rubinius的文章,这是一个用Ruby编写的Ruby解释器。我试着在不同的地方查找它,但我很难弄清楚这样的东西到底是如何工作的。我在编译器或语言编写方面从来没有太多经验,但我真的很想弄明白。一门语言究竟如何才能被自己解释?编译中是否有一个我不明白这有意义的基本步骤?有人可以像我是个白痴一样向我解释这个吗(因为无论如何这都不会太离谱) 最佳答案 它比你想象的要简单。Rubinius并非100%用Ruby编
Ruby是完全面向对象的语言。在ruby中,一切都是对象,因此属于某个类。例如5属于Objectclass1.9.3p194:001>5.class=>Fixnum1.9.3p194:002>5.class.superclass=>Integer1.9.3p194:003>5.class.superclass.superclass=>Numeric1.9.3p194:005>5.class.superclass.superclass.superclass=>Object1.9.3p194:006>5.class.superclass.superclass.superclass.su
我有一个正在HerokuCedar堆栈上部署的Rails3.2应用程序。这意味着应用程序本身负责为其静态Assets提供服务。我希望对这些Assets进行gzip压缩,所以我在production.rb的中间件堆栈中插入了Rack::Deflater:middleware.insert_after('Rack::Cache',Rack::Deflater)...curl告诉我这与宣传的一样有效。但是,由于Heroku将全力运行rakeassets:precompile,生成一堆预gzipAssets,我很想使用它们(而不是让Rack::Deflater再次完成所有工作)。我已经看到使用
我经常使用嵌套数据结构,很多时候我必须从控制台手动分析它们。问题是它们全部打印在一行中。是否有一种简单的方法可以根据{,[,],}和逗号重新构造数据结构的显示,使其看起来像Ruby的pretty_print输出? 最佳答案 :%s/\([{,]\)/\1\r/gggVG=:setft=ruby呜呜呜 关于ruby-如何将Vim中的"expand"文本转换成一种易于阅读的方式?,我们在StackOverflow上找到一个类似的问题: https://stacko
我从教练那里接到了任务。我想以一种形式编辑两个模型。例如,我们有两个实体学生和地址。在新学生部分,我想添加学生详细信息和地址。我如何通过rubyonrails中的脚手架实现这一目标? 最佳答案 您可以使用accepts_nested_attributes_for和fields_for建立一个表格来同时创建两个模型,所以你也可以编辑它们。这种形式称为嵌套形式。这里有一个关于Nestedform的引用给你,. 关于ruby-on-rails-如何以一种形式编辑多个模型?,我们在Stack