环境版本:
hadoop-3.1.0
hive-3.1.2
flink-1.13.2
Maven引入依赖项:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-hive_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>${flink.version}</version>
<!--<scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>${hive.version}</version>
</dependency>
<!--用于向hdfs写paruqet-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-parquet_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-avro</artifactId>
<version>${flink.version}</version>
</dependency>java代码示例:
package teld;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.SqlDialect;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.catalog.hive.HiveCatalog;
import java.time.Duration;
/**
* @Auther: lixz
* @Date: 2022/10/13/9:38
* @Description: 有hive依赖冲突问题暂停
*/
public class Kafka2Hive {
public static void main( String[] args ) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().build();
StreamTableEnvironment tEnv = StreamTableEnvironment.create(env,settings);
/**
* hive环境
*/
// System.setProperty("HADOOP_USER_NAME","hdfs");
String name = "myhive";
String defaultDatabase = "test";
//这里版本号一定要与hive-exec包版本一致,否则报错:NoSuchMethodException: org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(org.apache.hadoop.hive.conf.HiveConf)
String hive_version = "3.1.2";
String hiveConfDir = "/opt/hive-3.1.2/conf";
HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir,hive_version);
tEnv.registerCatalog("myhive", hive);
tEnv.useCatalog("myhive");
tEnv.getConfig().setSqlDialect(SqlDialect.HIVE);
//接入kafka
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers("192.168.78.1:9092")
.setTopics("test4")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.latest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
//接入kafka流
DataStreamSource<String> stream = env.fromSource(source,
WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(5)), "Kafka Source");
DataStream<MyUser> dataStream = stream.map(new MapFunction<String, MyUser>() {
@Override
public MyUser map(String s) throws Exception {
String[] arr = s.split(",");
return new MyUser(arr[0], arr[1], Integer.valueOf(arr[2]));
}
}).returns(MyUser.class);
//创建动态表
tEnv.createTemporaryView("MyUser",dataStream);
//创建hive表(如果hive中该表不存在会自动在hive上创建,也可以提前在hive中建好该表,flinksql中就无需再执行建表SQL,因为用了hive的catalog,flinksql运行时会找到表)
tEnv.executeSql("CREATE TABLE IF NOT EXISTS `myhive`.`test`.`useroplog` \n" +
"(\n" +
"`ID` STRING,\n" +
"`NAME` STRING,\n" +
"`AGE` INT\n" +
") \n" +
"partitioned by(`DAY` STRING)\n" +
"STORED AS parquet TBLPROPERTIES(\n" +
//小文件自动合并,1.12版的新特性,解决了实时写hive产生的小文件问题
"'auto-compaction'='true',\n" +
//合并后的最大文件大小
"'compaction.file-size'='128MB',\n"+
"'format' = 'parquet',\n"+
//压缩方式
"'parquet.compression'='GZIP',\n"+
//如果每小时一个分区,这个参数可设置为1 h,这样意思就是说数据延后一小时写入hdfs,能够达到数据的真确性,如果分区是天,这个参数也没必要设置了,今天的数据明天才能写入,时效性太差
"'sink.partition-commit.delay'='30 s',\n" +
//metastore值是专门用于写入hive的,也需要指定success-file
//这样检查点触发完数据写入磁盘后会创建_SUCCESS文件以及hive metastore上创建元数据,这样hive才能够对这些写入的数据可查
"'sink.partition-commit.policy.kind'='metastore,success-file'\n" +
")");
//写hive表
tEnv.getConfig().setSqlDialect(SqlDialect.DEFAULT);
tEnv.executeSql("insert into useroplog select *,'2022-10-13' as `DAY` from MyUser");
//打印
// tEnv.executeSql("select * from MyUser").print();
env.execute();
}
}
如果要输出的hive没有创建,执行任务后会自动创建,我们到hive下看看自定创建出来的表格式是什么样:
CREATE TABLE `useroplog`(
`id` string,
`name` string,
`age` int)
PARTITIONED BY (
`day` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
'hdfs://dss0:8020/user/hive/warehouse/test.db/useroplog'
TBLPROPERTIES (
'auto-compaction'='true',
'bucketing_version'='2',
'format'='parquet',
'parquet.compression'='GZIP',
'sink.partition-commit.delay'='1min',
'sink.partition-commit.policy.kind'='success-file',
'transient_lastDdlTime'='1665629249')
打包代码,注意不要包含依赖避免依赖重读,我们用到的依赖都放到集群上
提交作业:
flink run-application \
-t yarn-application \
-c teld.Kafka2Hive \
-Dyarn.provided.lib.dirs="hdfs://dss0:8020/user/flink/flink-dependency-1.13.2;hdfs://dss0:8020/user/flink/flink-dependency-1.13.2/lib;hdfs://dss0:8020/user/flink/flink-dependency-1.13.2/plugin
s" \-Dyarn.application.name=flink2hivetest \
flink2hivetest-1.0-SNAPSHOT.jar \
提交成功截图:
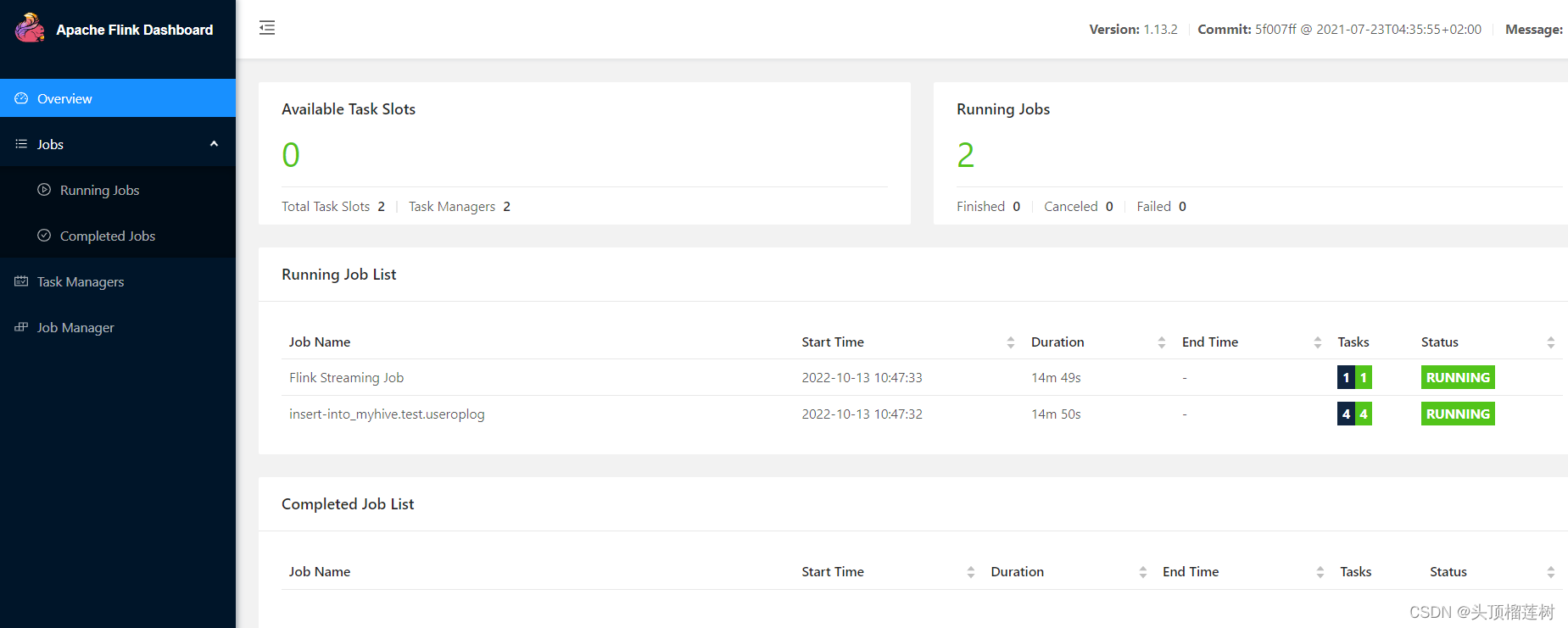
当我们向kafka发送数据后就会写入到hive中,我们看下hive表生成的文件结构

实时写入时,分区会自动创建;我们来查询下

二、注意事项
1、代码中创建的HiveCatalog中要指定hive版本,并且该版本一定要与依赖hive-exec的版本一致
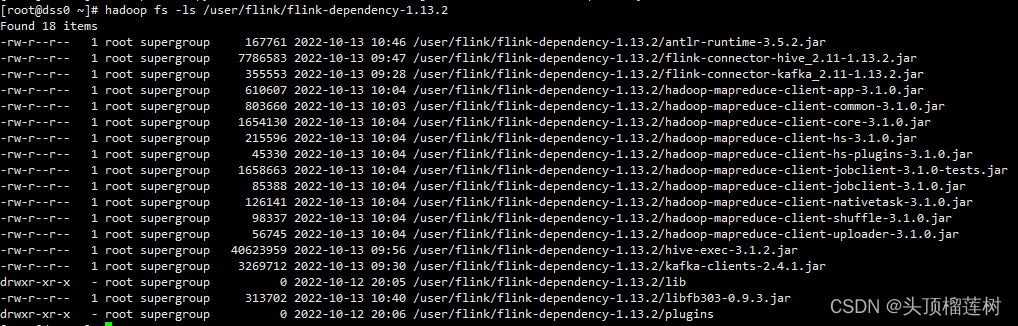
2、集群HDFS上的依赖如下:
3、hive要开启metastore
bin/hive --service metastore >/dev/null 2>&1 &
开启后可以看9083端口是否存在
4、hive-site.xml配置
需要指定metastore uri
<property>
<name>hive.metastore.uris</name>
<value>thrift://192.168.78.12:9083</value>
</property>
好的,所以我的目标是轻松地将一些数据保存到磁盘以备后用。您如何简单地写入然后读取一个对象?所以如果我有一个简单的类classCattr_accessor:a,:bdefinitialize(a,b)@a,@b=a,bendend所以如果我从中非常快地制作一个objobj=C.new("foo","bar")#justgaveitsomerandomvalues然后我可以把它变成一个kindaidstring=obj.to_s#whichreturns""我终于可以将此字符串打印到文件或其他内容中。我的问题是,我该如何再次将这个id变回一个对象?我知道我可以自己挑选信息并制作一个接受该信
目录第1题连续问题分析:解法:第2题分组问题分析:解法:第3题间隔连续问题分析:解法:第4题打折日期交叉问题分析:解法:第5题同时在线问题分析:解法:第1题连续问题如下数据为蚂蚁森林中用户领取的减少碳排放量iddtlowcarbon10012021-12-1212310022021-12-124510012021-12-134310012021-12-134510012021-12-132310022021-12-144510012021-12-1423010022021-12-154510012021-12-1523.......找出连续3天及以上减少碳排放量在100以上的用户分析:遇到这类
我想知道Ruby用来在命令行打印这些东西的输出流:irb(main):001:0>a="test"=>"test"irb(main):002:0>putsatest=>nilirb(main):003:0>a=>"test"$stdout是否用于irb(main):002:0>和irb(main):003:0>?而且,在这两次调用之间,$stdout的值是否有任何变化?另外,有人能告诉我打印/写入这些内容的Ruby源代码吗? 最佳答案 是的。而且很容易向自己测试/证明。在命令行试试这个:ruby-e'puts"foo"'>test.
我正在编写一个ruby程序,它应该执行另一个程序,通过stdin向它传递值,从它的stdout读取响应,然后打印响应。这是我目前所拥有的。#!/usr/bin/envrubyrequire'open3'stdin,stdout,stderr=Open3.popen3('./MyProgram')stdin.puts"helloworld!"output=stdout.readerrors=stderr.readstdin.closestdout.closestderr.closeputs"Output:"puts"-------"putsoutputputs"\nErrors:"p
我正在处理http://prepwork.appacademy.io/mini-curriculum/array/中概述的数组问题我正在尝试创建函数my_transpose,它接受一个矩阵并返回其转置。我对写入二维数组感到很困惑!这是一个代码片段,突出了我的困惑。rows=[[0,1,2],[3,4,5],[6,7,8]]columns=Array.new(3,Array.new(3))putscolumns.to_s#Outputisa3x3arrayfilledwithnilcolumns[0][0]=0putscolumns.to_s#Outputis[[0,nil,nil],[
我在一个ruby文件中有一个函数可以像这样写入一个文件File.open("myfile",'a'){|f|f.puts("#{sometext}")}这个函数在不同的线程中被调用,使得像上面这样的文件写入不是线程安全的。有谁知道如何以最简单的方式使这个文件写入线程安全?更多信息:如果重要的话,我正在使用rspec框架。 最佳答案 您可以通过File#flock给锁File.open("myfile",'a'){|f|f.flock(File::LOCK_EX)f.puts("#{sometext}")}
有人可以花我一些代码,在图像底部添加文本吗?我想使用Rmagick,但我也愿意使用其他工具。 最佳答案 我也发现了这个,它非常适合我。require'RMagick'includeMagick#Dimisionsbasedonanimage3072x2048unlessARGV[0]andFile.exists?(ARGV[0])puts"\n\n\nYouneedtospecifyafilename:watermark.rb\n\n\n"exitendimg=Image.read(ARGV[0]).firstnew_img="wm
假设我有200个昂贵的方法调用(每个都有不同的参数)。出于某种原因,我可以并行执行其中的5个调用,但不能更多。我可以一次执行一个,但一次执行5个要快5倍。我想一直执行五件事。不想排五个,等五个都排完了,再排五个。如果我排队A、B、C、D、E并且C先完成,我想立即用F替换它,即使A和B还没有完成。我一直在研究这个问题,因为我可以想象它会定期发生。解决方案似乎是生产者-消费者模式,Ruby在其标准库中内置了一些用于该模式的结构(Queue和SizedQueue)。我玩过代码示例,阅读了一些文档,我想我对它有一个粗略的了解。但是我有一些问题我对我的解决方案没有信心,而且多线程的整个领域对我来
我目前正在试验ActionController::Live,但我不知道如何正确地测试它。在我的Controller中,我写了这个response.stream.write("event:#{event}\n")response.stream.write("data:#{post.to_json}\n\n")但是当我在rspec测试中检查对象时,我看到了这个(rdb:1)response.stream.instance_variable_get(:@buf)["event:event\n"]当我将“数据”写入流时,我不明白为什么它没有出现在数组中。当我删除第一个response.stre
我想使用rmagick将图像写入文件。下面给出的是我的代码im="base64encodedstring"image=Magick::Image.from_blob(Base64.decode64(im)image[0].format="jpeg"name="something_temp"path="/somepath/"+nameFile.open(path,"wb"){|f|f.write(image[0])}我也尝试过使用f.write(image).但是文件中写入的是#.这是什么原因? 最佳答案 这应该有效:image[0]