Spark于2009年诞生于美国加州大学伯克利分校的AMP实验室,它是一个可应用于大规模数据处理的统一分析引擎。Spark不仅计算速度快,而且内置了丰富的API,使得我们能够更加容易编写程序。
Spark在2013年加入Apache孵化器项目,之后获得迅猛的发展,并于2014年正式成为Apache软件基金会的顶级项目。Spark生态系统已经发展成为一个可应用于大规模数据处理的统一分析引擎,它是基于内存计算的大数据并行计算框架,适用于各种各样的分布式平台的系统。在Spark生态圈中包含了Spark SQL、Spark Streaming、GraphX、MLlib等组件。

图1-1

图1-2
图1-3

图1-4
Spark计算框架在处理数据时,所有的中间数据都保存在内存中,从而减少磁盘读写操作,提高框架计算效率。同时Spark还兼容HDFS、Hive,可以很好地与Hadoop系统融合,从而弥补MapReduce高延迟的性能缺点。所以说,Spark是一个更加快速、高效的大数据计算平台。
根据官方数据统计,与Hadoop相比,Spark基于内存的运算效率要快100倍以上,基于硬盘的运算效率也要快10倍以上。Spark实现了高效的DAG执行引擎,能够通过内存计算高效地处理数据流。
Spark编程支持Java、Python、Scala及R语言,并且还拥有超过80种高级算法,除此之外,Spark还支持交互式的Shell操作,开发人员可以方便地在Shell客户端中使用Spark集群解决问题。
Spark提供了统一的解决方案,适用于批处理、交互式查询(Spark SQL)、实时流处理(Spark Streaming)、机器学习(Spark MLIib)和图计算(GraphX),它们可以在同一个应用程序中无缝地结合使用,大大减少大数据开发和维护的人力成本和部署平台的物力成本。
Spark可以运行在Hadoop模式、Mesos模式、Standalone独立模式或Cloud中,并且还可以访问各种数据源,包括本地文件系统、HDFS、Cassandra、HBase和Hive等。
如下图1-5、1-6.

图1-5

图1-6
Hadoop的MapReduce计算数据时,要转化为Map和Reduce两个过程,从而难以描述复杂的数据处理过程;而Spark的计算模型不局限于Map和Reduce操作,还提供了多种数据集的操作类型,编程模型比MapReduce更加灵活。
Hadoop的MapReduce进行计算时,每次产生的中间结果都存储在本地磁盘中;而Spark在计算时产生的中间结果存储在内存中。
Hadoop在每次执行数据处理时,都要从磁盘中加载数据,导致磁盘IO开销较大;而Spark在执行数据处理时,要将数据加载到内存中,直接在内存中加载中间结果数据集,减少了磁盘的IO开销。
MapReduce计算的中间结果数据,保存在磁盘中,Hadoop底层实现了备份机制,从而保证了数据容错;Spark RDD实现了基于Lineage的容错机制和设置检查点方式的容错机制,弥补数据在内存处理时,因断电导致数据丢失的问题。
由于Spark仅仅是一种计算框架,不负责数据的存储和管理,因此,通常都会将Spark和Hadoop进行统一部署,由Hadoop中的HDFS、HBase等组件负责数据的存储管理,Spark负责数据计算。
注:安装Spark集群之前,需要安装Hadoop环境,采用如下配置环境:
○ Linux系统:CentOS_6.7版本;
○ Hadoop:2.7.4版本;
○ JDK:1.8版本;
○ Spark:2.3.2版本。
(1)Standalone模式:
·Standalone模式被称为集群单机模式。
·该模式下,Spark集群架构为主从模式,即一台Master节点与多台Slave节点,Slave节点启动的进程名称为Worker,存在单点故障的问题。
(2)Mesos模式:
·Mesos模式被称为Spark on Mesos模式。
·Mesos是一款资源调度管理系统,为Spark提供服务,由于Spark与Mesos存在密切的关系,因此在设计Spark框架时充分考虑到对Mesos的集成。
(3)Yarn模式:
·Yarn模式被称为Spark on Yarn模式,即把Spark作为一个客户端,将作业提交给Yarn服务。
·由于在生产环境中,很多时候都要与Hadoop使用同一个集群,因此采用Yarn来管理资源调度,可以提高资源利用率。
(1)安装Scala.
①下载Scala安装包.
进入下载网站(All Available Versions | The Scala Programming Language (scala-lang.org))并选择版本下载(图1-7),进入选择版本下滑找到(图1-8)下载对应的版本。
(1)Standalone模式:
·Standalone模式被称为集群单机模式。
·该模式下,Spark集群架构为主从模式,即一台Master节点与多台Slave节点,Slave节点启动的进程名称为Worker,存在单点故障的问题。
(2)Mesos模式:
·Mesos模式被称为Spark on Mesos模式。
·Mesos是一款资源调度管理系统,为Spark提供服务,由于Spark与Mesos存在密切的关系,因此在设计Spark框架时充分考虑到对Mesos的集成。
(3)Yarn模式:
·Yarn模式被称为Spark on Yarn模式,即把Spark作为一个客户端,将作业提交给Yarn服务。
·由于在生产环境中,很多时候都要与Hadoop使用同一个集群,因此采用Yarn来管理资源调度,可以提高资源利用率。
(1)安装Scala.
①下载Scala安装包.
进入下载网站(All Available Versions | The Scala Programming Language (scala-lang.org))并选择版本下载(图1-7),进入选择版本下滑找到(图1-8)下载对应的版本。

图1-7

图1-8
②解压Scala安装包.
使用CRT连接虚拟机linux,将安装包拉入目录,并使用指令解压Scala安装包。(图1-9)
指令:tar -zxvf /opt/software/scala-2.11.8.tgz -C /opt/module/

图1-9
③重命名Scala.
在解压目录,将解压的scala-2.11.8.tgz重命名为scala。(图2-1)
指令:mv scala-2.11.8/ scala
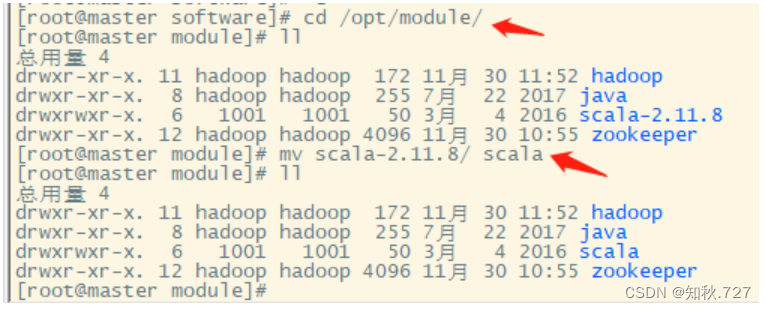
图2-1
④配置Scala环境变量.
进入(/etc/profile)配置scala的环境变量,保存并生效。(图2-2)
配置内容:
export SCALA_HOME=/opt/module/scala
export PATH=$PATH:$SCALA_HOME/bin
生效指令:source /etc/profile

图2-2
⑤修改hadoop权限并分发文件到各个节点.
修改scala目录的权限为Hadoop(图2-3),并分发文件给slave1,slave2,再到各个节点修改scala目录的权限为Hadoop,配置环境变量并使环境变量生效。(图2-4)
修改权限指令:
chown -R hadoop:hadoop /opt/
分发文件scala指令:
scp -r /opt/module/scala/ slave1:/opt/module/
scp -r /opt/module/scala/ slave2:/opt/module/
配置内容:
export SCALA_HOME=/opt/module/scala
export PATH=$PATH:$SCALA_HOME/bin
生效指令:source /etc/profile

图2-3
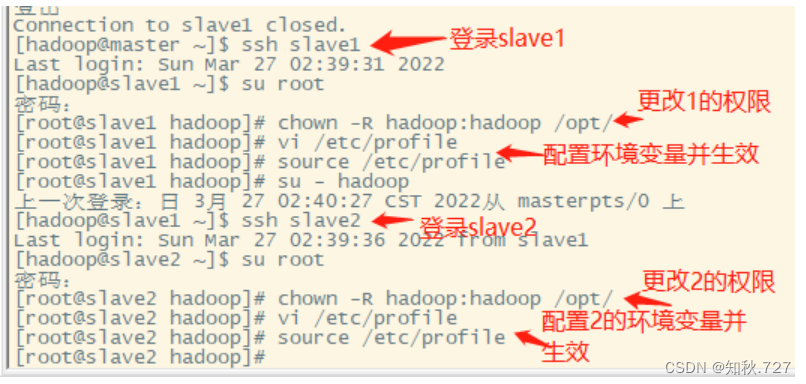
图2-4
⑥启动Scala.
在master节点上启动Scala。
指令:scala -version
(2)安装Spark.
①下载Spark安装包.
进入Spark下载(图2-5)页面(Downloads | Apache Spark),选择基于对应的版本下载。(图2-6)

图2-5

图2-6
②解压Spark安装包.
使用CRT连接虚拟机linux,将安装包拉入目录,并使用指令解压Spark安装包。(图2-7)
指令:tar -zxvf /opt/software/spark-2.0.0-bin-hadoop2.6.tgz -C /opt/module/
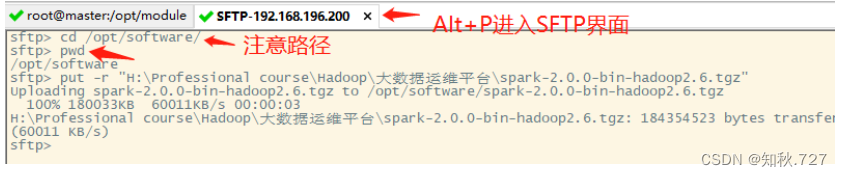
图2-7
③重命名Spark.
在解压目录,将解压的spark-2.0.0-bin-hadoop2.6重命名为spark。
指令:mv spark-2.0.0-bin-hadoop2.6/ spark
④修改Spark配置文件.
进入spark/conf目录修改配置文件,将spark-env.sh.template修改成spark-env.sh并配置.(图2-8)
复制指令:cp spark-env.sh.template spark-env.sh
修改文件添加内容:
export JAVA_HOME=/opt/module/java
export SPARK_MASTER_HOST=master
export SPARK_MASTER_PORT=7077
复制slaves.template文件,命名为slaves,并编辑slaves配置文件配置。
指令:cp slaves.template slaves
配置内容:
slave1
slave2

图2-8
⑤分发文件到各个节点.
修改Spark目录的权限为Hadoop,并分发文件给slave1,slave2,再到各个节点修改Spark目录的权限为Hadoop。(图2-9)
修改权限指令:
chown -R hadoop:hadoop /opt/
分发文件scala指令:
scp -r /opt/module/spark/ slave1:/opt/module/
scp -r /opt/module/spark/ slave2:/opt/module/

图2-9
⑥启动Spark.
在Spark目录下执行或者直接使用Spark/sbin/start-all.sh脚本命令。(图3-1)
指令:sbin/start-all.sh

图3-1
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
开门见山|拉取镜像dockerpullelasticsearch:7.16.1|配置存放的目录#存放配置文件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/config#存放数据的文件夹mkdir-p/opt/docker/elasticsearch/node-1/data#存放运行日志的文件夹mkdir-p/opt/docker/elasticsearch/node-1/log#存放IK分词插件的文件夹mkdir-p/opt/docker/elasticsearch/node-1/plugins若你使用了moba,直接右键新建即可如上图所示依次类推创建
目录:一、简介二、HQL的执行流程三、索引四、索引案例五、Hive常用DDL操作六、Hive常用DML操作七、查询结果插入到表八、更新和删除操作九、查询结果写出到文件系统十、HiveCLI和Beeline命令行的基本使用十一、Hive配置一、简介Hive是一个构建在Hadoop之上的数据仓库,它可以将结构化的数据文件映射成表,并提供类SQL查询功能,用于查询的SQL语句会被转化为MapReduce作业,然后提交到Hadoop上运行。特点:简单、容易上手(提供了类似sql的查询语言hql),使得精通sql但是不了解Java编程的人也能很好地进行大数据分析;灵活性高,可以自定义用户函数(UDF)和
文章目录查看ES信息查看节点信息查看分片信息实际场景下ES分片及副本数量应该怎么分关于ES的灵活使用查看ES信息查看版本kibana:GET/查看节点信息GET/_cat/nodes?v解释:ip:集群中节点的ip地址;heap.percent:堆内存的占用百分比;ram.percent:总内存的占用百分比,其实这个不是很准确,因为buff/cache和available也被当作使用内存;cpu:cpu占用百分比;load_1m:1分钟内cpu负载;load_5m:5分钟内cpu负载;load_15m:15分钟内cpu负载;node.role:上图的dilmrt代表全部权限master:*代表
elasticsearch查看当前集群中的master节点是哪个需要使用_cat监控命令,具体如下。查看方法es主节点确定命令,以kibana上查看示例如下:GET_cat/nodesv返回结果示例如下:ipheap.percentram.percentcpuload_1mload_5mload_15mnode.rolemastername172.16.16.188529952.591.701.45mdi-elastic3172.16.16.187329950.990.991.19mdi-elastic2172.16.16.231699940.871.001.03mdi-elastic4172
(二十二)-框架主入口main.py设计&log日志调用和生成1测试目的2测试需求3需求分析4详细设计4.1新建存放日志目录log4.1.1配置config.py中写入log的目录4.2`baseInfo.py`中加入日志4.3`test_gedit.py`中加入日志4.4主函数入口main.py中调用日志5调用日志主函数main.py源码6`baseInfo.py`源码7`test_gedit.py`源码8运行效果9目前框架结构1测试目的组织运行所有的测试用例,并调用日志模块,便于问题定位。
(1)为什么写这个话题(Why)读万卷书不如行千里路。这次搭建MQTT服务,遇到了一些误解,特此记录备忘。主要包括:(1)服务(Broker)的账户管理与网页管理平台的账户(2)与web应用的集成(Spring系)(2)ActiveMQ版本选择因为JAVA环境是JDK8,所以按兼容性考虑选择了ActiveMQ5.15的最后版本5.15.15。如果你是JDK11则可考虑ActiveMQ的最新版本5.17或5.18。ActiveMQ支持MQTTv3.1.1andv3.1。(3)ActiveMQ与web应用的集成主要介绍与Spring系的webapp集成(SpringBoot和SpringMVC)。
Kubernetes(K8s)是一个用于管理容器化应用程序的开源平台,可以帮助开发人员更轻松地部署、管理和扩展应用程序。在Kubernetes中,集群划分是一种重要的概念,可以帮助我们更好地组织和管理集群中的节点和资源。本文将介绍如何使用Kubernetes对集群进行划分,并提供详细的操作示例,希望能够帮助读者更好地了解和使用Kubernetes平台。Node划分Node划分是将集群中的节点按照一定的规则进行划分。在Kubernetes中,可以使用NodeSelector和Affinity机制来实现Node划分。NodeSelectorNodeSelector是一种将Pod调度到符合特定节点标
这篇文章,主要介绍如何使用SpringCloud微服务组件从0到1搭建一个微服务工程。目录一、从0到1搭建微服务工程1.1、基础环境说明(1)使用组件(2)微服务依赖1.2、搭建注册中心(1)引入依赖(2)配置文件(3)启动类1.3、搭建配置中心(1)引入依赖(2)配置文件(3)启动类1.4、搭建API网关(1)引入依赖(2)配置文件(3)启动类1.5、搭建服务提供者(1)引入依赖(2)配置文件(3)启动类1.6、搭建服务消费者(1)引入依赖(2)配置文件(3)启动类1.7、运行测试一、从0到1搭建微服务工程1.1、基础环境说明(1)使用组件这里主要是使用的SpringCloudNetflix
一、获取当前时间1、current_date当前日期(年月日)Examples:SELECTcurrent_date;2、current_timestamp/now()当前日期(时间戳)Examples:SELECTcurrent_timestamp;二、从日期字段中提取时间1、year,month,day/dayofmonth,hour,minute,secondExamples:SELECTyear(now());其他的日期函数以此类推month:1day:12(当月的第几天)dayofmonth:12hour,minute,second:分别对应时分秒2、dayofweek、dayofm