一、实验题目
MapReduce编程
二、实验内容
本实验利用 Hadoop 提供的 Java API 进行编程进行 MapReduce 编程。
三、实验目标
掌握MapReduce编程。
理解MapReduce原理
【实验作业】简单流量统计
有如下这样的日志文件:
13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 2481 24681 200
13726230513 00-FD-07-A4-72-B8:CMCC 120.196.40.8 i02.c.aliimg.com 248 0 200
13826230523 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 2481 24681 200
13726230533 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 2481 24681 200
13726230543 00-FD-07-A4-72-B8:CMCC 120.196.100.82 Video website 1527 2106 200
13926230553 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 2481 24681 200
13826230563 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 2481 24681 200
13926230573 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 2481 24681 200
18912688533 00-FD-07-A4-72-B8:CMCC 220.196.100.82 Integrated portal 1938 2910 200
18912688533 00-FD-07-A4-72-B8:CMCC 220.196.100.82 i02.c.aliimg.com 3333 21321 200
13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 Search Engines 9531 9531 200
13826230523 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 2481 24681 200
13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 2481 24681 200
该日志文件记录了每个手机用户在一段时间内的网络流量信息,具体字段含义为:
手机号码 MAC地址 IP地址 域名 上行流量(字节数) 下行流量(字节数) 套餐类型
根据以上日志,统计出每个手机用户在该时间段内的总流量(上行流量+下行流量),统计结果的格式为:
手机号码 字节数量
实验结果
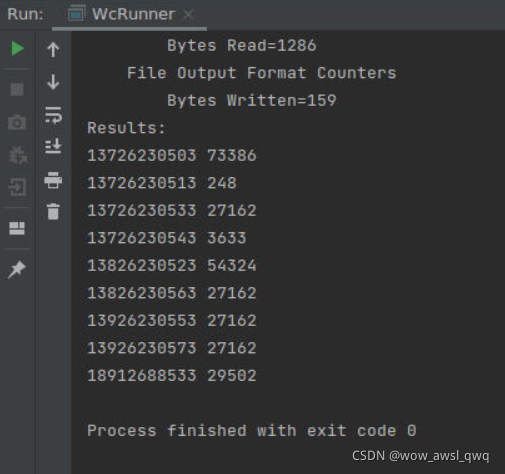
实验代码
WcMap.java
import java.io.IOException;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WcMap extends Mapper<LongWritable, Text, Text, LongWritable>{
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String str = value.toString();
String[] words = StringUtils.split(str," ",10);
int i=0;
for(String word : words){
if(i==words.length-2||i==words.length-3)
context.write(new Text(words[0]), new LongWritable(Integer.parseInt(word)));
i++;
}
}
}
WcReduce.java
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WcReduce extends Reducer<Text, LongWritable, Text, LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> values,Context context)
throws IOException, InterruptedException {
long count = 0;
for(LongWritable value : values){
count += value.get();
}
context.write(key, new LongWritable(count));
}
}
WcRunner.java
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.util.Scanner;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import java.net.URI;
public class WcRunner{
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(WcRunner.class);
job.setMapperClass(WcMap.class);
job.setReducerClass(WcReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
Scanner sc = new Scanner(System.in);
System.out.print("inputPath:");
String inputPath = sc.next();
System.out.print("outputPath:");
String outputPath = sc.next();
try {
FileSystem fs0 = FileSystem.get(new URI("hdfs://master:9000"), new Configuration());
Path hdfsPath = new Path(outputPath);
fs0.copyFromLocalFile(new Path("/headless/Desktop/workspace/mapreduce/WordCount/data/1.txt"),new Path("/mapreduce/WordCount/input/1.txt"));
if(fs0.delete(hdfsPath,true)){
System.out.println("Directory "+ outputPath +" has been deleted successfully!");
}
}catch(Exception e) {
e.printStackTrace();
}
FileInputFormat.setInputPaths(job, new Path("hdfs://master:9000"+inputPath));
FileOutputFormat.setOutputPath(job, new Path("hdfs://master:9000"+outputPath));
job.waitForCompletion(true);
try {
FileSystem fs = FileSystem.get(new URI("hdfs://master:9000"), new Configuration());
Path srcPath = new Path(outputPath+"/part-r-00000");
FSDataInputStream is = fs.open(srcPath);
System.out.println("Results:");
while(true) {
String line = is.readLine();
if(line == null) {
break;
}
System.out.println(line);
}
is.close();
}catch(Exception e) {
e.printStackTrace();
}
}
}
what’s up,这个云计算实验也太多了吧,不写了
我又写了一题
(二)【实验作业】索引倒排输出行号
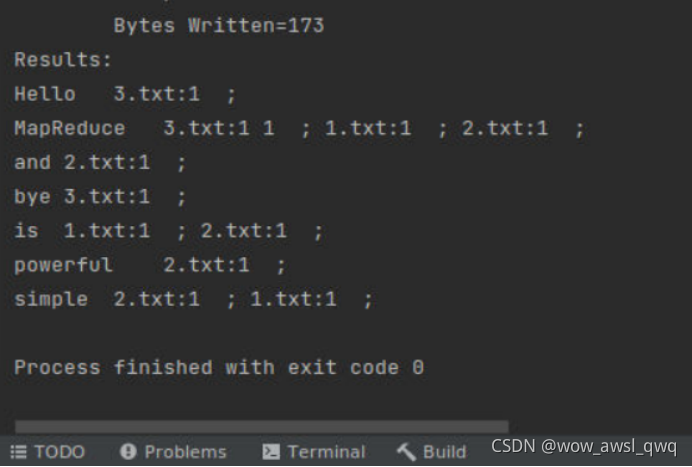
在索引倒排实验中,我们可以得到每个单词分布在哪些文件中,以及在每个文件中出现的次数,修改以上实现,在输出的倒排索引结果中可以得到每个单词在每个文件中的具体行号信息。输出结果的格式如下:
单词 文件名:行号,文件名:行号,文件名:行号
实验结果:
MapReduce在3.txt的第一行出现了两次所以有两个1
import java.io.*;
import java.util.StringTokenizer;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
public class MyMapper extends Mapper<Object,Text,Text,Text>{
private Text keyInfo = new Text();
private Text valueInfo = new Text();
private FileSplit split;
int num=0;
public void map(Object key,Text value,Context context)
throws IOException,InterruptedException{
num++;
split = (FileSplit)context.getInputSplit();
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()){
keyInfo.set(itr.nextToken()+" "+split.getPath().getName().toString());
valueInfo.set(num+"");
context.write(keyInfo,valueInfo);
}
}
}
import java.io.*;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Reducer;
public class MyCombiner extends Reducer<Text,Text,Text,Text>{
private Text info = new Text();
public void reduce(Text key,Iterable<Text>values,Context context)
throws IOException, InterruptedException{
String sum = "";
for(Text value:values){
sum += value.toString()+" ";
}
String record = key.toString();
String[] str = record.split(" ");
key.set(str[0]);
info.set(str[1]+":"+sum);
context.write(key,info);
}
}
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class MyReducer extends Reducer<Text,Text,Text,Text>{
private Text result = new Text();
public void reduce(Text key,Iterable<Text>values,Context context) throws
IOException, InterruptedException{
String value =new String();
for(Text value1:values){
value += value1.toString()+" ; ";
}
result.set(value);
context.write(key,result);
}
}
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.util.Scanner;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import java.net.URI;
public class MyRunner {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(MyRunner.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setCombinerClass(MyCombiner.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
Scanner sc = new Scanner(System.in);
System.out.print("inputPath:");
String inputPath = sc.next();
System.out.print("outputPath:");
String outputPath = sc.next();
try {
FileSystem fs0 = FileSystem.get(new URI("hdfs://master:9000"), new Configuration());
Path hdfsPath = new Path(outputPath);
if(fs0.delete(hdfsPath,true)){
System.out.println("Directory "+ outputPath +" has been deleted successfully!");
}
}catch(Exception e) {
e.printStackTrace();
}
FileInputFormat.setInputPaths(job, new Path("hdfs://master:9000"+inputPath));
FileOutputFormat.setOutputPath(job, new Path("hdfs://master:9000"+outputPath));
job.waitForCompletion(true);
try {
FileSystem fs = FileSystem.get(new URI("hdfs://master:9000"), new Configuration());
Path srcPath = new Path(outputPath+"/part-r-00000");
FSDataInputStream is = fs.open(srcPath);
System.out.println("Results:");
while(true) {
String line = is.readLine();
if(line == null) {
break;
}
System.out.println(line);
}
is.close();
}catch(Exception e) {
e.printStackTrace();
}
}
}
后面的没写了
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
网络编程套接字网络编程基础知识理解源`IP`地址和目的`IP`地址理解源MAC地址和目的MAC地址认识端口号理解端口号和进程ID理解源端口号和目的端口号认识`TCP`协议认识`UDP`协议网络字节序socket编程接口`sockaddr``UDP`网络程序服务器端代码逻辑:需要用到的接口服务器端代码`udp`客户端代码逻辑`udp`客户端代码`TCP`网络程序服务器代码逻辑多个版本服务器单进程版本多进程版本多线程版本线程池版本服务器端代码客户端代码逻辑客户端代码TCP协议通讯流程TCP协议的客户端/服务器程序流程三次握手(建立连接)数据传输四次挥手(断开连接)TCP和UDP对比网络编程基础知识
项目介绍随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱小学生兴趣延时班预约小程序的设计与开发被用户普遍使用,为方便用户能够可以随时进行小学生兴趣延时班预约小程序的设计与开发的数据信息管理,特开发了小程序的设计与开发的管理系统。小学生兴趣延时班预约小程序的设计与开发的开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与小学生兴趣延时班预约小程序的设计与开发的实际需求相结合,讨论了小学生兴趣延时班预约小程序的设计与开发的使用。开发环境开发说明:前端使用微信微信小程序开发工具:后端使用ssm:VU
我对如何计算通过{%assignvar=0%}赋值的变量加一完全感到困惑。这应该是最简单的任务。到目前为止,这是我尝试过的:{%assignamount=0%}{%forvariantinproduct.variants%}{%assignamount=amount+1%}{%endfor%}Amount:{{amount}}结果总是0。也许我忽略了一些明显的东西。也许有更好的方法。我想要存档的只是获取运行的迭代次数。 最佳答案 因为{{incrementamount}}将输出您的变量值并且不会影响{%assign%}定义的变量,我
给定一个nxmbool数组:[[true,true,false],[false,true,true],[false,true,true]]有什么简单的方法可以返回“该列中有多少个true?”结果应该是[1,3,2] 最佳答案 使用转置得到一个数组,其中每个子数组代表一列,然后将每一列映射到其中的true数:arr.transpose.map{|subarr|subarr.count(true)}这是一个带有inject的版本,应该在1.8.6上运行,没有任何依赖:arr.transpose.map{|subarr|subarr.in
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
我创建了一个由于“在运行时执行的单例元类定义”而无法编码的对象(这段代码的描述是否正确?)。这是通过以下代码执行的:#defineclassXthatmyusesingletonclassmetaprogrammingfeatures#throughcallofmethod:break_marshalling!classXdefbreak_marshalling!meta_class=class我该怎么做才能使对象编码正确?是否可以从对象instance_of_x的classX中“移除”单例组件?我真的需要一个建议,因为我们的一些对象需要通过Marshal.dump序列化机制进行缓存。
给定两个大小相等的数组,如何找到不考虑位置的匹配元素的数量?例如:[0,0,5]和[0,5,5]将返回2的匹配项,因为有一个0和一个5共同;[1,0,0,3]和[0,0,1,4]将返回3的匹配项,因为0有两场,1有一场;[1,2,2,3]和[1,2,3,4]将返回3的匹配项。我尝试了很多想法,但它们都变得相当粗糙和令人费解。我猜想有一些不错的Ruby习惯用法,或者可能是一个正则表达式,可以很好地回答这个解决方案。 最佳答案 您可以使用count完成它:a.count{|e|index=b.index(e)andb.delete_at
我正在查看Ruby日志记录库Logging.logger方法并从sourceatgithub提出问题与这段代码有关:logger=::Logging::Logger.new(name)logger.add_appendersappenderlogger.additive=falseclass我知道类 最佳答案 这实际上删除了方法(当它实际被执行时)。这是确保close不会被调用两次的保障措施。看起来好像有嵌套的“class 关于Ruby元编程问题,我们在StackOverflow上找到一