由于本人只使用Edge浏览器,所以在得知Selenium对PantomJS的支持取消后,在网上找了各种关于Edge浏览器的资料。配置Selenium Edge有多种方法,但这里只介绍一种方法。
此处需要注意将浏览器更新到最新版本,以及选择正确的下载通道
解压下载的压缩包后会得到名为 msedgedriver.exe 的可执行程序,将这个程序放在任意一个地方,并将该文件所在的路径加入到系统的环境变量中
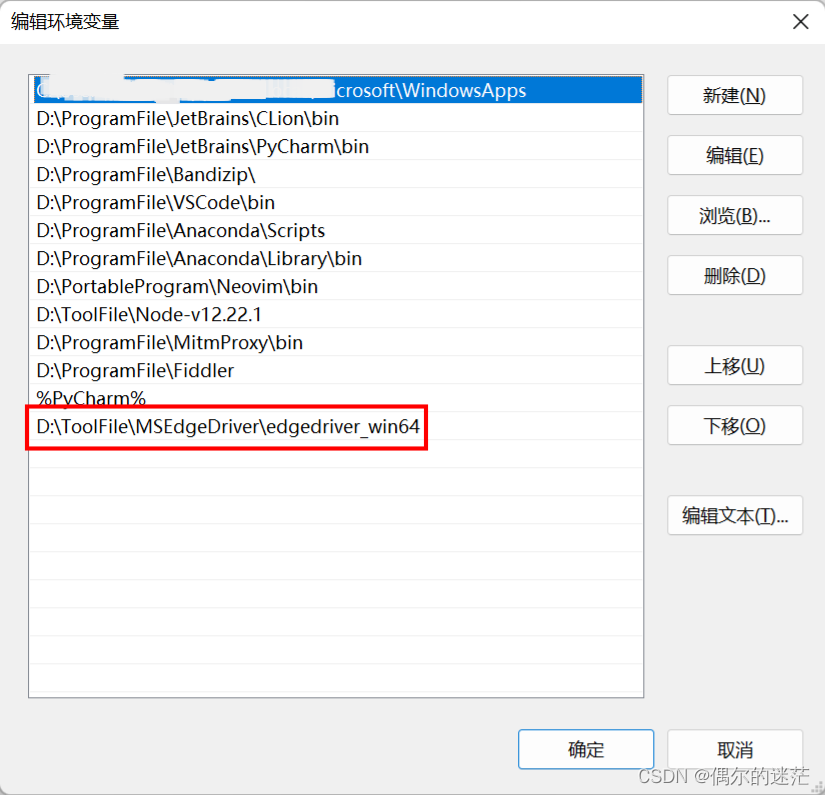
这个是我的 msedgedriver.exe 存放地址
环境变量设置好之后重启电脑,如果没有出错,在cmd中输入msedgedriver将不会报错
pip install selenium>=4.3.0
# 也可以是下面的
pip install selenium
需要注意的是selenium的版本要在4.0以上(其实3.0~4.0也可以,但是需要安装额外的库,为了简单,直接安装selenium4
from selenium import webdriver
browser = webdriver.Edge()
url = "https://baidu.com"
browser.get(url)
出现上面的界面就说明selenium正常工作
如果不设置无头浏览器模式,在Selenium控制浏览器工作时浏览器的一举一动都会显示出来,会占用电脑的gpu。在调试代码时,浏览器的GUI界面能够提供帮助,但是在爬虫工作时,浏览器的GUI就显得多余了,关闭GUI可以节省一部分计算资源。
导入selenium库
from selenium import webdriver
# 在这里导入浏览器设置相关的类
from selenium.webdriver.edge.options import Options
# 无可视化界面设置 #
edge_options = Options()
# 使用无头模式
edge_options.add_argument('--headless')
# 禁用GPU,防止无头模式出现莫名的BUG
edge_options.add_argument('--disable-gpu')
# 将参数传给浏览器
browser = webdriver.Edge(options=edge_options)
# 启动浏览器
url = "https://baidu.com"
browser.get(url)
print(browser.title)
# 关闭浏览器
browser.quit()正常情况下会输出 “百度一下,你就知道”
有时候,我们利用 Selenium 自动化爬取某些网站时,极有可能会遭遇反爬。
实际上,我们使用默认的方式初始化 WebDriver 打开一个网站,下面这段 JS 代码永远为 True,而手动打开目标网站的话,则为:False。
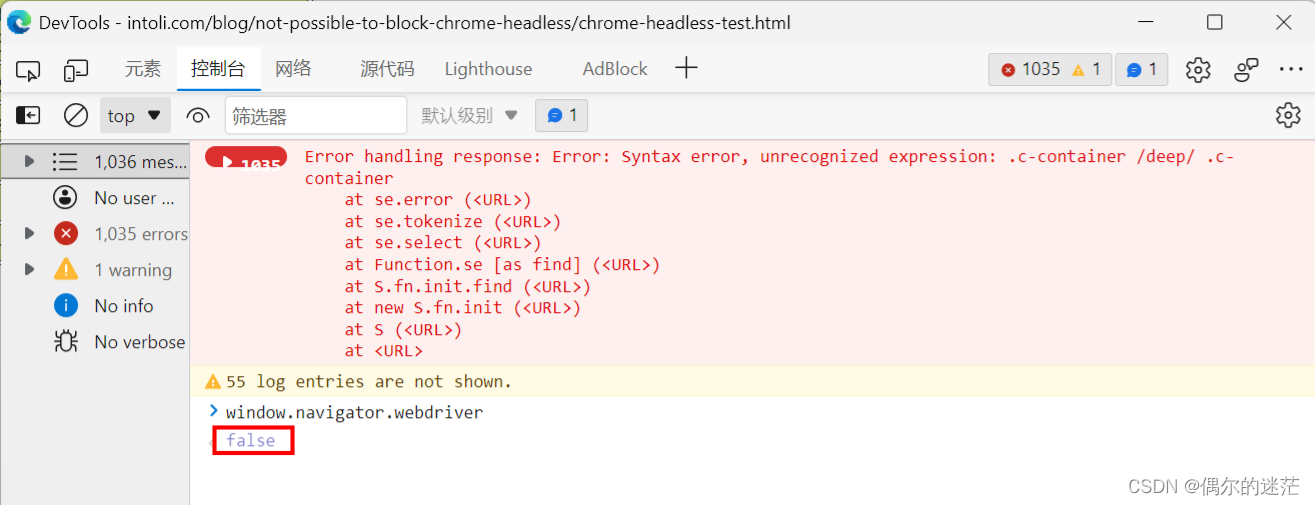
上图是手动打开浏览器
下图是通过selenium打开浏览器

稍微有一点反爬经验的工程师利用上面的差别,很容易判断访问对象是否为一个爬虫,然后对其做反爬处理,返回一堆脏数据或各种验证码。
反检测代码如下
导入selenium库
from selenium import webdriver
# 在这里导入浏览器设置相关的类
from selenium.webdriver.edge.options import Options
# 反检测设置 #
edge_options = Options()
# 开启开发者模式
edge_options.add_experimental_option('excludeSwitches', ['enable-automation'])
# 禁用启用Blink运行时的功能
edge_options.add_argument('--disable-blink-features=AutomationControlled')
# 将参数传给浏览器
browser = webdriver.Edge(options=edge_options)
# 启动浏览器
url = "https://intoli.com/blog/not-possible-to-block-chrome-headless/chrome-headless-test.html"
browser.get(url)
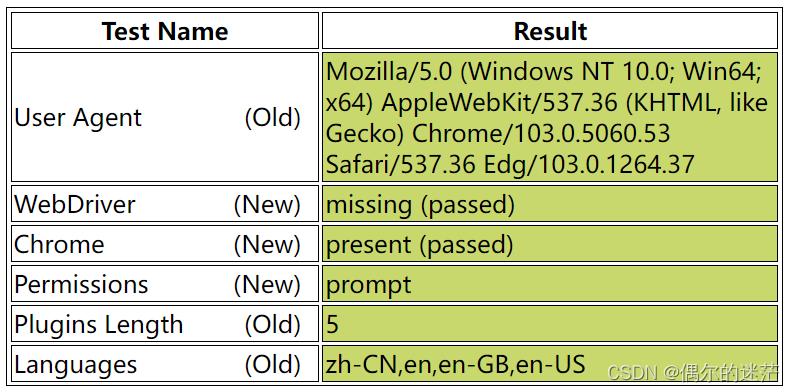
代码中url所指网站可以检测浏览器是否通过selenium控制,如果未检测出selenium控制,则"WebDriver"一栏为绿色。
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我正在使用的第三方API的文档状态:"[O]urAPIonlyacceptspaddedBase64encodedstrings."什么是“填充的Base64编码字符串”以及如何在Ruby中生成它们。下面的代码是我第一次尝试创建转换为Base64的JSON格式数据。xa=Base64.encode64(a.to_json) 最佳答案 他们说的padding其实就是Base64本身的一部分。它是末尾的“=”和“==”。Base64将3个字节的数据包编码为4个编码字符。所以如果你的输入数据有长度n和n%3=1=>"=="末尾用于填充n%
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我正在尝试在Ruby中制作一个cli应用程序,它接受一个给定的数组,然后将其显示为一个列表,我可以使用箭头键浏览它。我觉得我已经在Ruby中看到一个库已经这样做了,但我记不起它的名字了。我正在尝试对soundcloud2000中的代码进行逆向工程做类似的事情,但他的代码与SoundcloudAPI的使用紧密耦合。我知道cursesgem,我正在考虑更抽象的东西。广告有没有人见过可以做到这一点的库或一些概念证明的Ruby代码可以做到这一点? 最佳答案 我不知道这是否是您正在寻找的,但也许您可以使用我的想法。由于我没有关于您要完成的工作
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
作为新的阿里云用户,您可以50免费试用多种优惠,价值高达1,700美元(或8,500美元)。这将让您了解和体验阿里云平台上提供的一系列产品和服务。如果您以个人身份注册免费试用,您将获得价值1,700美元的优惠。但是,如果您是注册公司,您可以选择企业免费试用,提交基本信息通过企业实名注册验证,即可开始价值$8,500的免费试用!本教程介绍了如何设置您的帐户并使用您的免费试用版。关于免费试用在我们开始此试用之前,您还必须遵守以下条款和条件才能访问您的免费试用:只有在一年内创建的账户才有资格获得阿里云免费试用。通过此免费试用优惠,用户可以免费试用免费试用活动页面上列出的每种产品一次。如果您有多个帐