
目录
Prompt Managing of Sysytem Principles M(P)
Prompt Managing of Foundation Models M(F)
Prompt Managing of User Querie M(Qi)
Prompt Managing of Foundation Model Out-puts M(F(A(j)i ))
Visual ChatGPT的作用:
1、不仅可以发送和接收语言,也可以发送和接收图像;
2、提供了复杂的视觉问题或视觉编辑指令,这需要多个AI模型多步骤的协作;
3、提供反馈并且要求纠正结果。
考虑到多输入/输出模型和需要视觉反馈的模型,将一系列提示将可视化模型信息注入到ChatGPT中。
ChatGPT是在InstructGPT的基础上,专门训练它用真正对话的方式与用户交互,从而允许它保持当前对话的上下文,处理后续问题,从而产生正确的答案。
BLIP模型是理解和提供图像描述的专家。Stable Diffusion是基于文本提示合成图像的专家。
本文通过提出一个Visual ChatGPT系统。 我们不是从零开始训练一个新的多模态Chatgpt,而是直接基于Chatgpt构建可视化Chatgpt并集成多种VFMS。 为了弥补ChatGPT与这些VFM之间的差距,我们提出了一个支持以下功能的提示管理器:1)显式地告诉ChatGPT每个VFM的CAPA特性,并指定输入输出格式; 2)将不同的视觉信息,如PNG图像、深度图像和掩模矩阵转换成语言格式,以帮助ChatGPT理解; 3)处理不同Visual Foundation模型的历史、优先级和冲突。 在提示管理器的帮助下,ChatGPT可以利用这些VFMs,并以迭代的方式接收它们的反馈,直到满足用户的要求或达到结束条件。
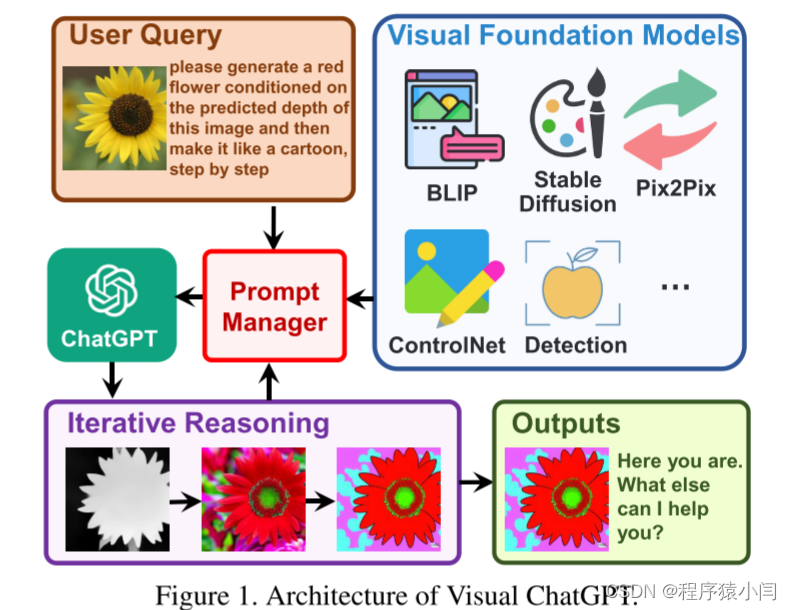
如图所示 1、用户上传一个黄花的图像,并输入一个复杂的语言指令“请根据该图像的预测深度生成一朵红花,然后使其像卡通一样,一步一步地进行”。 在提示管理器的帮助下,Visual ChatGPT启动了相关Visual Foundation模型的执行链。 在这种情况下,首先应用深度估计模型检测深度信息,然后利用深度-图像模型生成具有深度信息的红花图形,最后利用基于稳定扩散模型的风格转移VFM将该图像的风格转换为卡通。 在上述流程中,prompt Manager通过提供可视化格式类型和记录信息转换过程来充当ChatGPT的调度程序。 最后,当Visual ChatGPT从提示管理器中获得“卡通”提示时,将结束执行流水线并显示最终结果。
需要关注的几篇论文:
1、LiT:《Lit: Zero-shot transfer with locked-image text tuning.》
2、CLIP:《Learning transferable visual models from natural language supervision.》
3、ViT:《Scaling vision transformers.》
4、frozen pre-trained LLMs。
5、Chain-of-Thought(CoT):激发大规模语言模型的多步推理能力,也就是说CoT要求LLMs为最终结果生成中间答案。现有的技术分为Few-Shot-CoT和Zero-Shot-CoT。这两种用于单一的模态。MultimodalCoT将语言和视觉两个模态结合到一个两阶段框架中,将理论生成和答案推理分开。本文的工作将CoT潜力扩展到大规模任务,包括但不限于文本到图像的生成[27]、图像到图像的翻译[18]、图像到文本的生成[40]等。
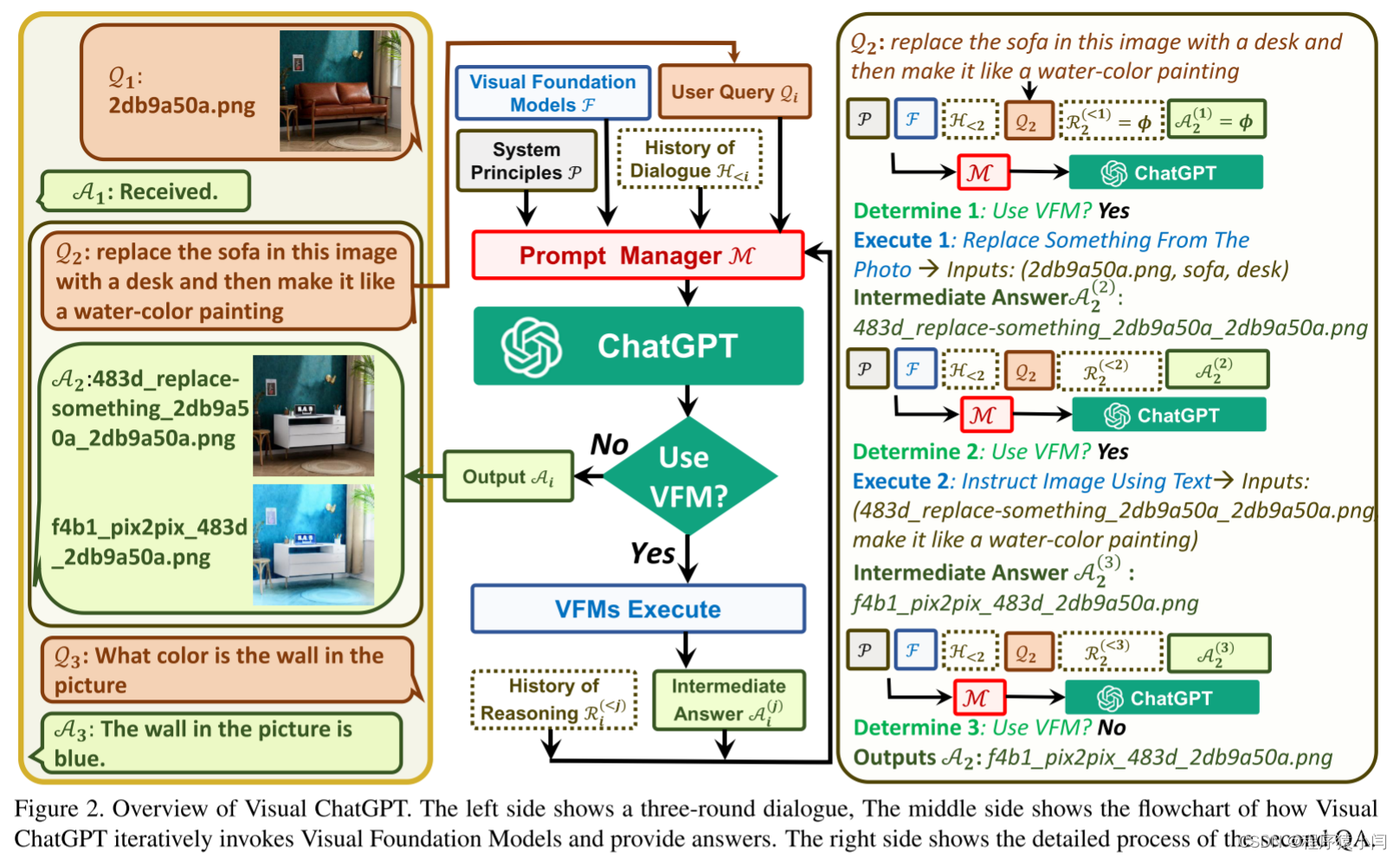
Visual ChatGPT是一个集成了不同的VFM来理解视觉信息并生成相应答案的系统。为此,需要定制一些系统原理,然后将其转化为ChatGPT可以理解的提示。这些提示有多种用途,包括:
visual chatgpt的角色:visual chatgpt旨在帮助一系列与文本和视觉相关的任务,如VQA、图像生成和编辑。
VFMS可访问性:Visual ChatGPT可以访问一个VFMS列表,以解决各种VL任务。 使用哪种基础模型的决定完全由ChatGPT模型本身做出,因此很容易支持新的VFMS和VL任务。
文件名敏感性:Visual ChatGPT根据文件名访问图像文件,使用精确的文件名以避免歧义是至关重要的,因为一轮对话可能包含多个图像及其不同的更新版本,误用文件名将导致混淆当前讨论的是哪一个图像。 因此,Visual ChatGPT被设计为严格使用文件名,以确保检索和操作正确的图像文件。
链式思维:处理一个看似简单的命令可能需要多个VFMs,例如“根据图像的深度预测生成一朵红花,然后使其像卡通一样”的查询需要深度估计、深度到图像和样式转移VFMs。 为了通过将查询分解为子问题来解决更具挑战性的查询,在Visual ChatGPT中引入了COT来帮助决策、利用和调度多个VFMS。
推理格式严格性:Visual ChatGPT必须遵循严格的推理格式。 因此,我们采用详细的Regex匹配算法对中间推理结果进行解析,并为ChatGPT模型构造合理的输入格式,以帮助其确定下一次执行,如触发新的VFM或返回最终响应。
可靠性:作为一种语言模型,Visual ChatGPT可能会编造虚假的图像文件名或事实,从而使系统不可靠。 为了处理这些问题,我们设计提示,要求Visual ChatGPT忠于Vision Foundation模型的输出,而不是捏造图像内容或文件名。 此外,多个VFMS的协作可以提高系统的可靠性,因此我们构造的提示将指导ChatGPT优先利用VFMS而不是基于会话历史生成结果。
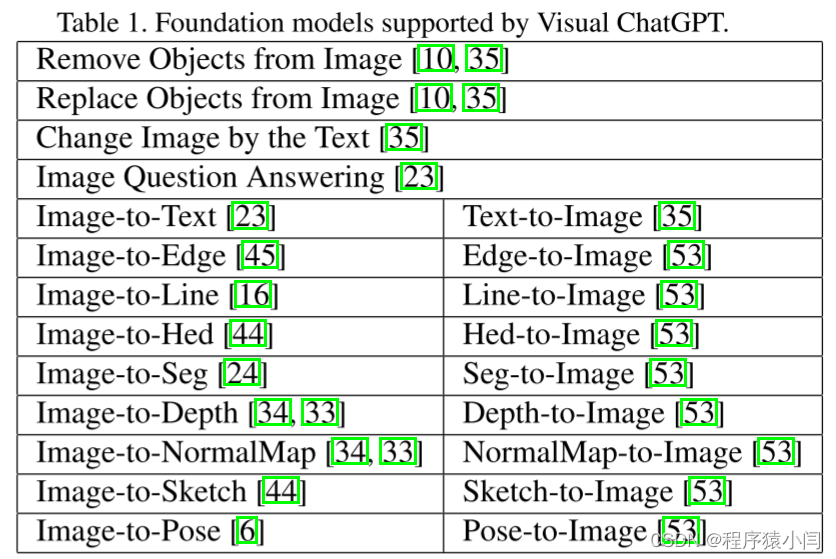
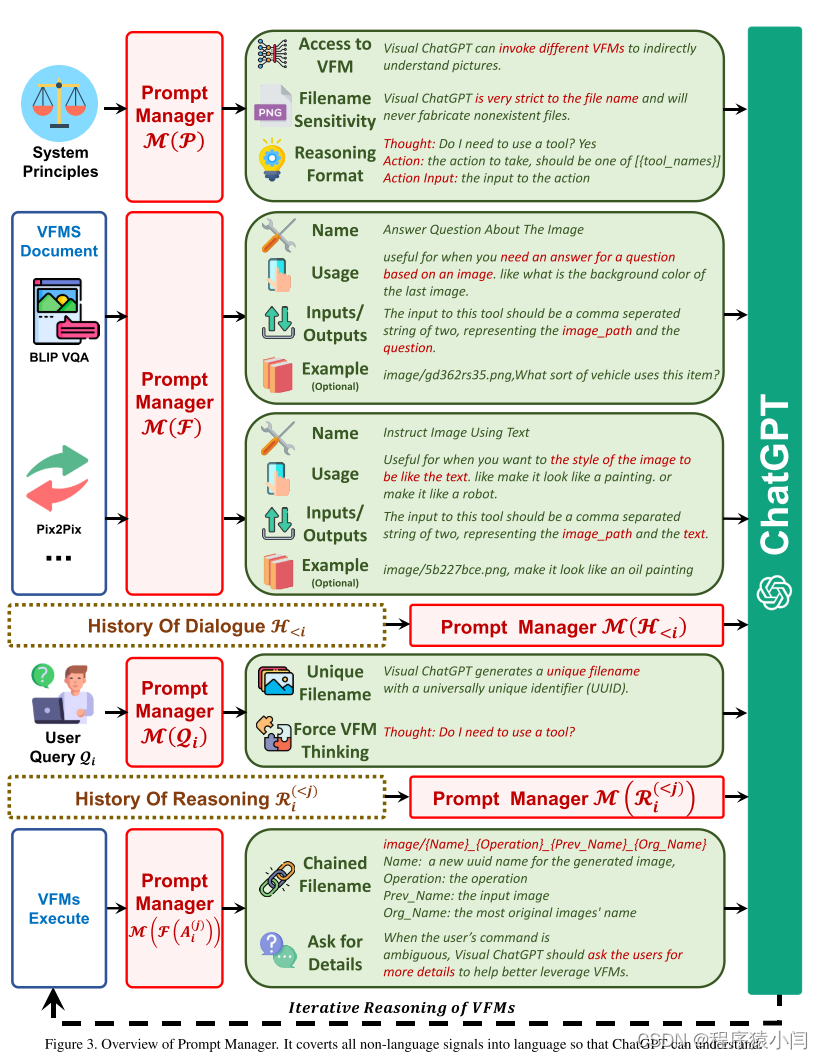
Visual ChatGPT配备了多个VFMS来处理各种VL任务。 由于这些不同的VFMS可能有一些相似之处,例如,图像中对象的替换可以被视为生成新的图像,图像到文本(I2T)任务和图像问答(VQA)任务都可以被理解为根据所提供的图像给出响应,因此区分它们至关重要。 如图所示 3、提示管理器具体定义了以下几个方面,以帮助Visual ChatGPT准确理解和处理VL任务:
名称:名称提示符为每个VFM提供了总体功能的摘要,例如回答有关图像的问题,它不仅帮助Visual ChatGPT简明地理解VFM的目的,而且作为VFM的入口提供了帮助。
用法:用法提示描述了应该使用 VFM 的具体场景。例如,Pix2Pix 模型适用于改变图像的风格。提供此信息有助于 Visual ChatGPT 做出有关将哪个 VFM 用于特定任务的明智决策。
输入/输出:输入和输出提示概述了每个 VFM 所需的输入和输出格式,因为格式可能会有很大差异,并且为 Visual ChatGPT 正确执行 VFM 提供明确的指导至关重要。
示例(可选):示例提示符是可选的,但它有助于Visual ChatGPT更好地理解如何在特定的输入模板下使用特定的VFM,并处理更复杂的查询。
Visual ChatGPT 支持多种用户查询,包括语言或图像,简单或复杂的查询,以及多张图片的引用。 Prompt Manager 从以下两个方面处理用户查询:
生成唯一文件名:Visual ChatGPT 可以处理两种类型的图像相关查询:涉及新上传图像的查询和涉及引用现有图像的查询。对于新上传的图像,Visual ChatGPT 会生成一个具有通用唯一标识符 (UUID) 的唯一文件名,并添加一个前缀字符串“image”来表示相对目录,例如“image/{uuid}.png”。虽然新上传的图像不会被输入 ChatGPT,但会生成一个虚假的对话历史记录,其中包含一个说明图像文件名的问题和一个表明图像已收到的答案。这个虚假的对话历史有助于以下对话。对于涉及引用现有图像的查询,Visual ChatGPT 会忽略文件名检查。这种方法已被证明是有益的,因为 ChatGPT 能够理解用户查询的模糊匹配,前提是它不会导致歧义,例如 UUID 名称。
强制VFM思考:为保证Visual ChatGPT的VFM成功触发,我们在(Qi)后面附加了一个后缀提示:“由于Visual ChatGPT是文本语言模型,Visual ChatGPT必须使用工具来观察图像,而不是想象。想法和观察仅对 Visual ChatGPT 可见,Visual ChatGPT 应记住在最终响应中为 Human 重复重要信息。想法:我需要使用工具吗?这个提示有两个目的:1)提示 Visual ChatGPT 使用基础模型,而不是仅仅依靠它的想象; 2) 它鼓励 Visual ChatGPT 提供由基础模型生成的特定输出,而不是诸如“你在这里”之类的通用响应。
对于来自不同VFMs F(A(j)i)的中间输出,Visual ChatGPT将隐式汇总并反馈给ChatGPT进行后续交互,即调用其他VFMS进行进一步操作,直到达到结束条件或反馈给用户。 内部步骤可以总结如下:
生成链式文件名:由于Visual ChatGPT的中间输出将成为下一轮隐式对话的输入,我们应该使这些输出更符合逻辑,以帮助LLMS更好地理解推理过程。 具体地说,从Visual Foundation模型生成的图像保存在“image/”文件夹下,该文件夹提示以下表示图像名称的字符串。 然后将图像命名为“{name}{operation}{prev name}{org name}”,其中{name}为上述UUID名称,以{operation}为操作名称,以{prev name}为输入图像唯一标识符,以{org name}为用户上传或VFMS生成图像的原始名称。 例如,“image/ui3c edge-ofo0ec nji9dcgf.png”是输入“o0ec”的名为“ui3c”的canny边缘图像,该图像的原始名称是“nji9dcgf”。 通过这样的命名规则,可以提示中间结果属性(即图像)的chatgpt,以及它是如何从一系列操作中生成的。
调动更多的VFMs:visual chatgpt的一个核心是可以自动调用更多的vfms来完成用户的命令。 更具体地说,我们通过在每一代的末尾扩展一个后缀“though:”,使ChatGPT不断地问自己是否需要VFMS来解决当前的问题。
询问更多细节:当用户的命令不明确时,Visual ChatGPT应该询问用户更多细节,以帮助更好地利用VFMS。 这种设计是安全和关键的,因为LLMS不允许任意篡改或毫无根据地猜测用户的意图,尤其是在输入信息不足的情况下。
使用LangChain引导LLM,我们从HuggingFace Transformers、Maskformer和ControlNet中收集基础模型。 全面部署所有22个VFMS需要4个NVIDIA V100 GPU,但允许用户部署更少的基础型号,以灵活节省GPU资源。 聊天历史记录的最大长度为2000个,并截断过多的令牌以满足chatgpt的输入长度。
虽然Visual ChatGPT是一种很有前途的多模式对话方法,但它有一些局限性,包括:
Visual ChatGPT在很大程度上依赖于ChatGPT来分配任务,并依赖于VFMS来执行任务。 因此,这些模型的准确性和有效性严重影响了可视化ChatGPT的性能。
Visual ChatGPT需要大量的提示工程来将VFMS转换为语言,并使这些模型描述变得可区分。 这个过程可能会占用时间,需要计算机视觉和自然语言处理方面的专业知识。
Visual ChatGPT 被设计为通用的。它试图将一个复杂的任务自动分解成几个子任务。因此,在处理特定任务时,Visual ChatGPT 可能会调用多个 VFM,与专门为特定任务训练的专家模型相比,实时能力有限。
ChatGPT中的最大令牌长度可能会限制可使用的基础模型的数量。 如果有数以千计或数以百万计的基础模型,可能需要一个预滤波模块来限制馈入ChatGPT的VFMS。
轻松插入和拔出基础模型的能力可能会引起安全和隐私问题,特别是对于通过API访问的远程模型。 必须仔细考虑和自动检查,以确保敏感数据不应暴露或泄露。
由于VFMS的故障和提示的不稳定,一些生成结果不能满足。 因此,需要一个自校正模块来检查执行结果与人类意图之间的一致性,并据此进行相应的编辑。 这种自我修正行为会导致对模型的思考更加复杂,显著增加推理时间。
几个月前,我读了一篇关于rubygem的博客文章,它可以通过阅读代码本身来确定编程语言。对于我的生活,我不记得博客或gem的名称。谷歌搜索“ruby编程语言猜测”及其变体也无济于事。有人碰巧知道相关gem的名称吗? 最佳答案 是这个吗:http://github.com/chrislo/sourceclassifier/tree/master 关于ruby-寻找通过阅读代码确定编程语言的rubygem?,我们在StackOverflow上找到一个类似的问题:
一、引擎主循环UE版本:4.27一、引擎主循环的位置:Launch.cpp:GuardedMain函数二、、GuardedMain函数执行逻辑:1、EnginePreInit:加载大多数模块int32ErrorLevel=EnginePreInit(CmdLine);PreInit模块加载顺序:模块加载过程:(1)注册模块中定义的UObject,同时为每个类构造一个类默认对象(CDO,记录类的默认状态,作为模板用于子类实例创建)(2)调用模块的StartUpModule方法2、FEngineLoop::Init()1、检查Engine的配置文件找出使用了哪一个GameEngine类(UGame
我怀念ipython的一件事是它有一个?为特定功能挖掘文档的运算符。我知道ruby有一个类似的命令行工具,但是我在irb中调用它非常不方便。ruby/irb有类似的东西吗? 最佳答案 Pry是IPython的Ruby版本,它支持?命令来查找有关方法的文档,但语法略有不同:pry(main)>?File.dirnameFrom:file.cinRubyCore(CMethod):Numberoflines:6visibility:publicsignature:dirname()Returnsallcomponentsofthef
我经常使用嵌套数据结构,很多时候我必须从控制台手动分析它们。问题是它们全部打印在一行中。是否有一种简单的方法可以根据{,[,],}和逗号重新构造数据结构的显示,使其看起来像Ruby的pretty_print输出? 最佳答案 :%s/\([{,]\)/\1\r/gggVG=:setft=ruby呜呜呜 关于ruby-如何将Vim中的"expand"文本转换成一种易于阅读的方式?,我们在StackOverflow上找到一个类似的问题: https://stacko
软件特点部署后能通过浏览器查看线上日志。支持Linux、Windows服务器。采用随机读取的方式,支持大文件的读取。支持实时打印新增的日志(类终端)。支持日志搜索。使用手册基本页面配置路径配置日志所在的目录,配置后按回车键生效,下拉框选择日志名称。选择日志后点击生效,即可加载日志。windows路径E:\java\project\log-view\logslinux路径/usr/local/XX历史模式历史模式下,不会读取新增的日志。针对历史文件可以分页读取,配置分页大小、跳转。历史模式下,支持根据关键词搜索。目前搜索引擎使用的是jdk自带类库,搜索速度相对较低,优点是比较简单。2G日志全文搜
我正在使用Watir进行自动化,它会创建一封我需要检查的电子邮件。有人指出电子邮件gem是执行此操作的最简单方法。我添加了以下代码,并且能够从我的收件箱中收到第一封电子邮件。require'mail'require'openssl'Mail.defaultsdoretriever_method:pop3,:address=>"email.someemail.com",:port=>995,:user_name=>'domain/username',:password=>'pwd',:enable_ssl=>trueendputsMail.first我是这个论坛的新手,有以下问题:如何获
CSDN优秀解读:https://blog.csdn.net/jiaoyangwm/article/details/1266387752021https://arxiv.org/pdf/2103.14259.pdf关键解读在目标检测中标签分配的最新进展主要寻求为每个GT对象独立定义正/负训练样本。在本文中,我们创新性地从全局的角度重新审视标签分配,并提出将分配程序制定为一个最优传输(OT)问题——优化理论中一个被充分研究的课题。具体来说,我们将每个需求方(锚框)和供应商(GT标签)的单位传输成本定义为他们的分类和回归损失加权之和。在公式化后,找到最好的分配方案即为最小传播成本解决最优传输方案,
我正在用Ruby编写类似curses的程序,我正在使用stty和ansi转义字符来实现我想要的。当我想获得用户输入时,我的问题就出现了。像许多基于控制台的程序一样,我想从终端底部获取用户输入。因此,我将光标放在屏幕底部并调用Readline.readline(或任何获取用户输入的方法)。像往常一样,它会读取所有内容,直到我按下回车键,并打印一个换行符。由于光标位于终端的最后一行,它会滚动一行,这会弄乱屏幕。我怎样才能避免这种情况?我试图使用stty来停止回显换行符,但我没有成功。也许可以使用stty来阻止终端滚动?当然,我可以编写自己的方法来通过一次读取一个字符(并捕获“返回”)来捕获
Two-StreamConvolutionalNetworksforActionRecognitioninVideos双流网络论文精读论文:Two-StreamConvolutionalNetworksforActionRecognitioninVideos链接:https://arxiv.org/abs/1406.2199本文是深度学习应用在视频分类领域的开山之作,双流网络的意思就是使用了两个卷积神经网络,一个是SpatialstreamConvNet,一个是TemporalstreamConvNet。此前的研究者在将卷积神经网络直接应用在视频分类中时,效果并不好。作者认为可能是因为卷积神经
论文常见数学符号及其含义(科研必备)返回论文和资料目录数学符号在数学领域是非常重要的。在论文中,使用数学符号可以使得论文更加简洁明了,同时也能够准确地描述各种概念和理论。在本篇博客中,我将介绍一些常见的数学符号及其含义(省去特别简单的符号),希望能够帮助读者更好地理解数学论文。高等数学∑i=1nxi\sum_{i=1}^nx_i∑i=1nxi(求和符号):表示将x1,x2,…,xnx_1,x_2,\dots,x_nx1,x2,…,xn中的所有数相加,例如∑i=1nxi\sum_{i=1}^nx_i∑i=1nxi表示将x1,x2,…,xnx_1,x_2,\dots,x_nx1,x