Elasticsearch:是一个开源的高扩展的分布式全文搜索引擎,它可以近乎实时的存储,然后检索数据,延迟很小。
Logstash: 实现将mysql或其他数据库的数据定时采集到Elasticsearch里。
ElasticHD:Elasticsearch的可视化工具,可以在界面条件查询查询Elasticsearch里的数据。
注意:因为ES是java开发的,所以需要安装jdk,安装完之后要配置环境变量,这个就不再赘述了,不会的可以从网上搜索怎么配置
1. 下载elasticsearch安装包(也可以自己去es官网下载): elasticsearch-7.16.2-windows-x86-64-Java文档类资源-CSDN下载
2. 解压安装包到指定目录,我的目录是:D:\tool\elasticsearch-7.16.2
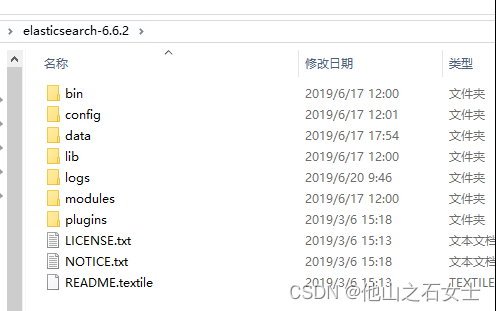
3. 进入bin目录,打开命令行(ps:在地址栏直接输入cmd,敲回车,就会在当前目录打开一个命令行窗口)
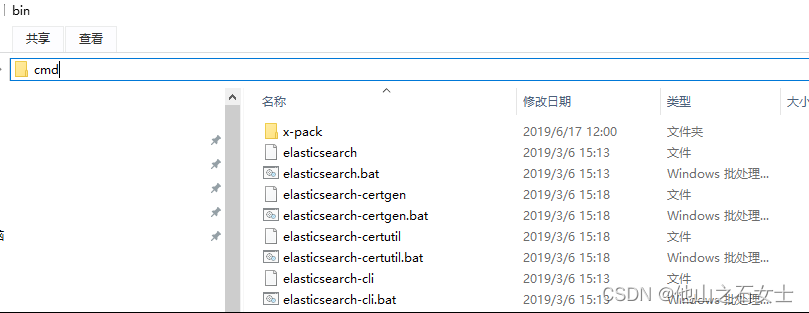
4. 在命令行输入:elasticsearch-service.bat install 把ES安装为服务

5. 启动 elasticsearch
方法一:进入bin目录,双击 elasticsearch.bat 启动该应用
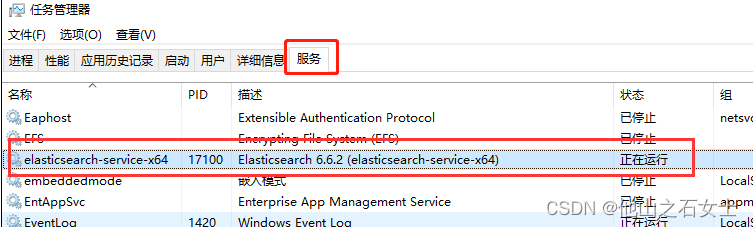
方法二: 打开任务管理器,在服务栏里查看ES是否启动,没有启动,就启动
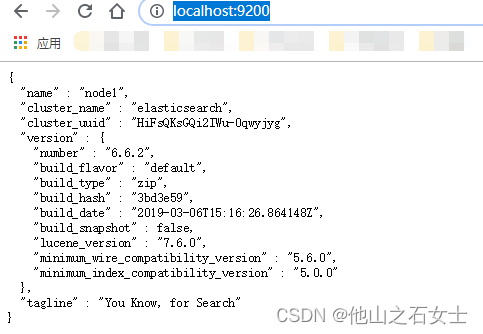
6. 直接访问 http://localhost:9200/ ,浏览器出现如下所示,表明成功
补充: 如果启动后报jdk相关的错(原因:es默认先使用本地jdk, 当本地jdk与其需要的版本不匹配则会报错;解决思路就是 让es使用自己自带的jdk,这样就需要修改配置文件,让其指向自己自带的jdk),则按如下方式解决:
步骤一:在系统环境变量里添加:
ES_HOME: D:\tool\elasticsearch-7.16.2\
ES_PATH_CONF: D:\tool\elasticsearch-7.16.2\config
JAVA_HOME: D:\tool\elasticsearch-7.16.2\jdk
步骤二:按照如上配置后,bin目录下的elasticsearch-env.bat配置文件就会按照设置的目录去调用自带的jdk, 此时重新启动 elasticsearch即可。
1. 下载Logstash安装包(也可以自己去es官网下载): logstash-7.16.2-windows-x86-64版-Java文档类资源-CSDN下载
2. 将安装包解压到指定目录下,我的在:D:\tool\logstash-7.16.2
3. 进入到bin目录下,将 连接mysql数据库的驱动包(mysql-connector-java-5.1.39.jar) 放到该目录下
下载链接:
https://download.csdn.net/download/m0_37951794/87207721
4. 编写采集数据的sql, 并保存到 test.sql文件里,将test.sql文件放到新建的sqldir里,即 bin/sqldir/ test.sql
我test.sql里的内容是: select * from user
5. 修改bin目录下,logstash.conf 配置文件内容:
input{
stdin {}
jdbc{
type => "jdbc"
# mysql 数据库的连接信息
jdbc_connection_string => "jdbc:mysql://127.0.0.1:3306/elasticsearch_view? characterEncoding=UTF-8&autoReconnect=true&useTimezone=true&serverTimezone=UTC"
jdbc_user => "root"
jdbc_password => "ABCabc123"
jdbc_driver_library => "./mysql-connector-java-5.1.39.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
# 数据库重连尝试次数
connection_retry_attempts => "3"
# 判断数据库连接是否可用,默认false不开启
jdbc_validate_connection => "true"
# 数据库连接可用校验超时时间,默认3600S
jdbc_validation_timeout => "3600"
# 开启分页查询(默认false不开启);
jdbc_paging_enabled => "true"
# 单次分页查询条数(默认100000,若字段较多且更新频率较高,建议调低此值);
jdbc_page_size => "2"
# 执行的sql 文件路径,如果sql较简单则用statement属性直接写sql语句即可
statement_filepath => "./sqldir/test.sql"
#statement=>"select * from user"
# 是否将字段名转换为小写,默认true(如果有数据序列化、反序列化需求,建议改为false);
lowercase_column_names => false
# 是否记录上次执行结果,true表示会将上次执行结果的tracking_column字段的值保存到last_run_metadata_path指定的文件中;
record_last_run => true
# 需要记录查询结果某字段的值时,此 字段为true,否则默认tracking_column为timestamp的值;:sql_last_value如果input里面use_column_value=>true,即如果设置为true的话,可以是我们设定的字段的上一次的值
#默认 use_column_value=>false,这样: sql_last_value为上一次更新的最后时刻值,也就是说对于新增的值,才会更新,这样就实现了增量更新的目的
use_column_value=>true
# 需要记录的字段,用于增量同步,需要是数据库里的字段
tracking_column =>"id"
#查询结果某字段的数据类型,仅包括numeric和timestamp,默认为numeric
tracking_column_type=>"numeric"
#记录上次执行结果数据的存放位置
last_run_metadata_path=>"./iweb_file_view.log"
#是否清除last_run_metadata_path的记录,需要增量同步时此字段必须为false
clean_run=>false
#同步频率(分 时 天 月 年),默认每分钟同步一次
schedule=>"* * * * * *"
}
}
filter{
mutate{
remove_field=>["@timestamp","@version"]
}
}
output {
if [type] == "jdbc" {
elasticsearch {
hosts => "127.0.0.1:9200"
# 配置ES集群地址
# hosts => ["192.168.1.1:9200", "192.168.1.2:9200", "192.168.1.3:9200"]
# 索引名字,必须小写,一个索引下只能有一个类型
index => "iweb_file"
# 数据唯一索引(建议使用数据库KeyID)
document_id => "%{id}"
document_type=>"file_type"
}
}
stdout {
codec => json_lines
}
}
6. 用记事本编写logstash的启动脚本,并存为: my_run.bat 文件
我 my_run.bat里的内容是: logstash -f logstash.conf
7. 在确保elasticsearch已经启动成功的前提下,启动 logstash(否则无法将数据写入elasticsearch): 双击 my_run.bat 即可,如下图则说明logstash启动成功,并成功连接上了elasticsearch

1. 下载 ElasticHD 安装包:https://download.csdn.net/download/m0_37951794/87214728
2. 解压 安装包到 D:\tool\ElasticHD
3. 在elasticsearch已经启动的前提下,双击ElasticHD/run.bat,启动该可视化工具
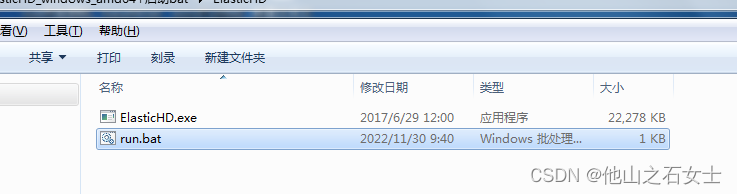
4. 启动后直接浏览器访问: http://127.0.0.1:9800,即可看到可视化界面,在连接里配置已启动的elasticsearch的访问地址即可查看里面的存储的数据
我的完整demo:java如何调用Elasticsearch(连接、查询、分页、排序、统计、模糊匹配、精准匹配、文字高亮)源码-Java文档类资源-CSDN下载
我需要在客户计算机上运行Ruby应用程序。通常需要几天才能完成(复制大备份文件)。问题是如果启用sleep,它会中断应用程序。否则,计算机将持续运行数周,直到我下次访问为止。有什么方法可以防止执行期间休眠并让Windows在执行后休眠吗?欢迎任何疯狂的想法;-) 最佳答案 Here建议使用SetThreadExecutionStateWinAPI函数,使应用程序能够通知系统它正在使用中,从而防止系统在应用程序运行时进入休眠状态或关闭显示。像这样的东西:require'Win32API'ES_AWAYMODE_REQUIRED=0x0
我真的很习惯使用Ruby编写以下代码:my_hash={}my_hash['test']=1Java中对应的数据结构是什么? 最佳答案 HashMapmap=newHashMap();map.put("test",1);我假设? 关于java-等价于Java中的RubyHash,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/22737685/
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
这似乎非常适得其反,因为太多的gem会在window上破裂。我一直在处理很多mysql和ruby-mysqlgem问题(gem本身发生段错误,一个名为UnixSocket的类显然在Windows机器上不能正常工作,等等)。我只是在浪费时间吗?我应该转向不同的脚本语言吗? 最佳答案 我在Windows上使用Ruby的经验很少,但是当我开始使用Ruby时,我是在Windows上,我的总体印象是它不是Windows原生系统。因此,在主要使用Windows多年之后,开始使用Ruby促使我切换回原来的系统Unix,这次是Linux。Rub
我需要一个表,其中行实际上是2行表,一个嵌套表是..我怎样才能在Prawn中做到这一点?也许我需要延期..但哪一个? 最佳答案 现在支持子表:Prawn::Document.generate("subtable.pdf")do|pdf|subtable=pdf.make_table([["sub"],["table"]])pdf.table([[subtable,"original"]])end 关于ruby-on-rails-PrawnPDF:Ineedtogeneratenested
我正在尝试使用boilerpipe来自JRuby。我看过guide从JRuby调用Java,并成功地将它与另一个Java包一起使用,但无法弄清楚为什么同样的东西不能用于boilerpipe。我正在尝试基本上从JRuby中执行与此Java等效的操作:URLurl=newURL("http://www.example.com/some-location/index.html");Stringtext=ArticleExtractor.INSTANCE.getText(url);在JRuby中试过这个:require'java'url=java.net.URL.new("http://www
我只想对我一直在思考的这个问题有其他意见,例如我有classuser_controller和classuserclassUserattr_accessor:name,:usernameendclassUserController//dosomethingaboutanythingaboutusersend问题是我的User类中是否应该有逻辑user=User.newuser.do_something(user1)oritshouldbeuser_controller=UserController.newuser_controller.do_something(user1,user2)我
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m