下载地址: Downloads | Apache SkyWalking
分别下载 apm 和 agent
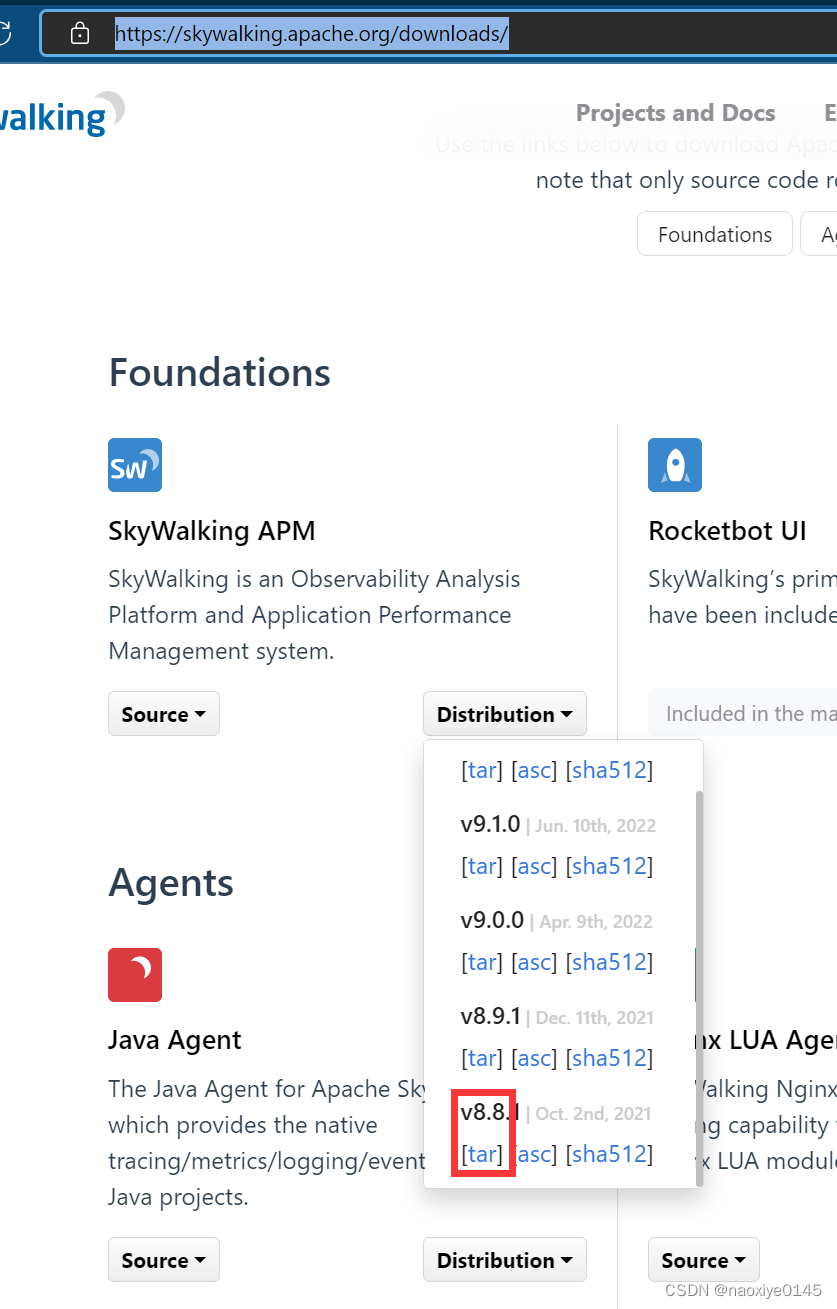
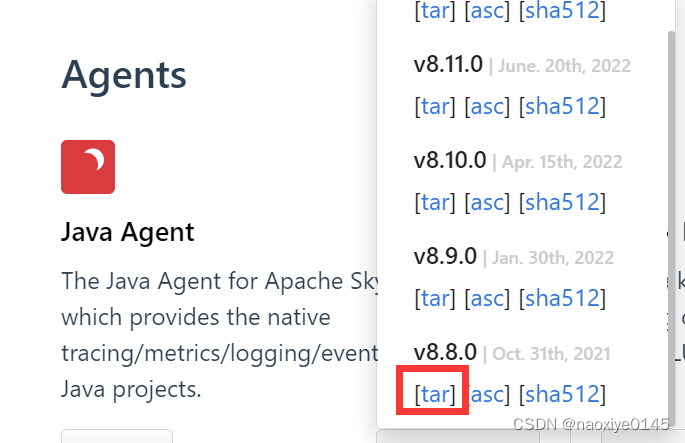
wegt 下载连接如下;
wget https://archive.apache.org/dist/skywalking/java-agent/8.8.0/apache-skywalking-java-agent-8.8.0.tgz
wget https://archive.apache.org/dist/skywalking/8.8.1/apache-skywalking-apm-8.8.1.tar.gz
wegt https://www.elastic.co/cn/downloads/past-releases/elasticsearch-7-17-0
在打开安装目录的config下elasticsearch.yml 并添加以下配置
#http.port: 9200
cluster.name: CollectorDBCluster
path.data: /opt/elasticsearch-7.17.0/data
path.logs: /opt/elasticsearch-7.17.0/logs
network.host: 0.0.0.0
http.port: 9200
node.name: node-1
cluster.initial_master_nodes: ["node-1"]
# /opt/elasticsearch-7.17.0/bin/elasticsearch
storage:
selector: ${SW_STORAGE:elasticsearch}
elasticsearch:
namespace: ${SW_NAMESPACE:"CollectorDBCluster"}
clusterNodes: ${SW_STORAGE_ES_CLUSTER_NODES:服务器ip:9200}
protocol: ${SW_STORAGE_ES_HTTP_PROTOCOL:"http"}
connectTimeout: ${SW_STORAGE_ES_CONNECT_TIMEOUT:500}
socketTimeout: ${SW_STORAGE_ES_SOCKET_TIMEOUT:30000}
numHttpClientThread: ${SW_STORAGE_ES_NUM_HTTP_CLIENT_THREAD:0}
# user: ${SW_ES_USER:""}
# password: ${SW_ES_PASSWORD:""}
# trustStorePath: ${SW_STORAGE_ES_SSL_JKS_PATH:""}
# trustStorePass: ${SW_STORAGE_ES_SSL_JKS_PASS:""}
secretsManagementFile: ${SW_ES_SECRETS_MANAGEMENT_FILE:""} # Secrets management file in the properties format includes the username, password, which are managed by 3rd party tool.
dayStep: ${SW_STORAGE_DAY_STEP:1} # Represent the number of days in the one minute/hour/day index.
indexShardsNumber: ${SW_STORAGE_ES_INDEX_SHARDS_NUMBER:1} # Shard number of new indexes
indexReplicasNumber: ${SW_STORAGE_ES_INDEX_REPLICAS_NUMBER:1} # Replicas number of new indexes
# Super data set has been defined in the codes, such as trace segments.The following 3 config would be improve es performance when storage super size data in es.
superDatasetDayStep: ${SW_SUPERDATASET_STORAGE_DAY_STEP:-1} # Represent the number of days in the super size dataset record index, the default value is the same as dayStep when the value is less than 0
superDatasetIndexShardsFactor: ${SW_STORAGE_ES_SUPER_DATASET_INDEX_SHARDS_FACTOR:5} # This factor provides more shards for the super data set, shards number = indexShardsNumber * superDatasetIndexShardsFactor. Also, this factor effects Zipkin and Jaeger traces.
superDatasetIndexReplicasNumber: ${SW_STORAGE_ES_SUPER_DATASET_INDEX_REPLICAS_NUMBER:0} # Represent the replicas number in the super size dataset record index, the default value is 0.
indexTemplateOrder: ${SW_STORAGE_ES_INDEX_TEMPLATE_ORDER:0} # the order of index template
bulkActions: ${SW_STORAGE_ES_BULK_ACTIONS:5000} # Execute the async bulk record data every ${SW_STORAGE_ES_BULK_ACTIONS} requests
# flush the bulk every 10 seconds whatever the number of requests
# INT(flushInterval * 2/3) would be used for index refresh period.
flushInterval: ${SW_STORAGE_ES_FLUSH_INTERVAL:15}
concurrentRequests: ${SW_STORAGE_ES_CONCURRENT_REQUESTS:2} # the number of concurrent requests
resultWindowMaxSize: ${SW_STORAGE_ES_QUERY_MAX_WINDOW_SIZE:10000}
metadataQueryMaxSize: ${SW_STORAGE_ES_QUERY_MAX_SIZE:5000}
segmentQueryMaxSize: ${SW_STORAGE_ES_QUERY_SEGMENT_SIZE:200}
profileTaskQueryMaxSize: ${SW_STORAGE_ES_QUERY_PROFILE_TASK_SIZE:200}
oapAnalyzer: ${SW_STORAGE_ES_OAP_ANALYZER:"{\"analyzer\":{\"oap_analyzer\":{\"type\":\"stop\"}}}"} # the oap analyzer.
oapLogAnalyzer: ${SW_STORAGE_ES_OAP_LOG_ANALYZER:"{\"analyzer\":{\"oap_log_analyzer\":{\"type\":\"standard\"}}}"} # the oap log analyzer. It could be customized by the ES analyzer configuration to support more language log formats, such as Chinese log, Japanese log and etc.
advanced: ${SW_STORAGE_ES_ADVANCED:""}
主要需要修改
storage:
selector: ${SW_STORAGE:elasticsearch}
我的版本是8.8 如果你是低版本 且Elasticsearch7 ,就配置
storage:
selector: ${SW_STORAGE:elasticsearch7}
然后修改elasticsarch的服务ip和端口就可以了
# /opt/apache-skywalking-apm-bin/bin/startup.sh
每个jar单独一个文件夹
分别 orderservice、gatway、userservice

version: "3.2"
services:
# nacos:
# image: nacos/nacos-server
# environment:
# MODE: standalone
# ports:
# - "9010:8848"
userservice:
env_file: .env
environment:
- USER_NAME=${COMNAME}
build: ./user-service
orderservice:
build: ./order-service
gateway:
build: ./gateway
ports:
- "9013:9013"
.env 可以指定运行参数
## docker-compose环境变量
## 测试docker绑定参数
COMNAME=abcdefg129001
每个服务文件夹里面包含以下几个文件
其中dockerfile 如下;
# 将下面的代码放入Dockerfile文件中,复制三份分别放入三个文件夹
FROM java:8
COPY ./app.jar /tmp/app.jar
COPY ./agent /tmp/agent
ENTRYPOINT java -javaagent:/tmp/agent/skywalking-agent.jar -Dskywalking.agent.service_name=gatway -Dskywalking.collector.backend_service=sky服务器ip:11800 -jar /tmp/app.jar
其他几个服务相同配置
每个springboot小项目单独添加依赖:
<!--打印skywalking的TraceId到日志-->
<dependency>
<groupId>org.apache.skywalking</groupId>
<artifactId>apm-toolkit-logback-1.x</artifactId>
<version>8.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.skywalking</groupId>
<artifactId>apm-toolkit-trace</artifactId>
<version>8.8.0</version>
</dependency>
其中版本号要与skywalking一致
日志可以使用logback (其他日志框架可以自行google)
<?xml version="1.0" encoding="utf-8" ?>
<configuration>
<!-- logback-spring加载早于application.yml,如果直接通过${参数key}的形式是无法获取到对应的参数值-->
<!-- source指定的是application.yml配置文件中key,其它地方直接用${log.path}引用这个值 -->
<!-- 解决在相对路径下生成log.path_IS_UNDEFINED的问题,增加defaultValue -->
<springProperty scope="context" name="base.path" source="logging.file.path" defaultValue="${user.home}/kenlogs"/>
<!-- app.name根据你的应用名称修改 -->
<springProperty scope="context" name="app.name" source="spring.application.name" defaultValue="applog"/>
<property name="log.path" value="${base.path}/${app.name}"/>
<!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度,%msg:日志消息,%n是换行符-->
<property name="log.pattern" value="%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - [%tid] - %msg%n"/>
<!-- 控制台日志输出配置 -->
<appender name="stdout" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder">
<layout class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.TraceIdPatternLogbackLayout">
<pattern>${log.pattern}</pattern>
</layout>
</encoder>
</appender>
<appender name="SKYWALKING" class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.log.GRPCLogClientAppender">
<!-- 日志输出编码 -->
<encoder>
<!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度%msg:日志消息,%n是换行符-->
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n
</pattern>
<charset>UTF-8</charset> <!-- 设置字符集 -->
</encoder>
</appender>
<!-- 文件输出日志配置,按照每天生成日志文件 -->
<appender name="file" class="ch.qos.logback.core.rolling.RollingFileAppender">
<rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<!-- 日志文件输出的文件名称 -->
<FileNamePattern>${log.path}-%d{yyyy-MM-dd}.%i.log</FileNamePattern>
<!-- 日志保留天数 -->
<MaxHistory>30</MaxHistory>
<MaxFileSize>3KB</MaxFileSize>
</rollingPolicy>
<encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder">
<layout class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.TraceIdPatternLogbackLayout">
<!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度%msg:日志消息,%n是换行符-->
<pattern>${log.pattern}</pattern>
</layout>
</encoder>
</appender>
<!-- mybatis日志配置 -->
<!-- <logger name="java.sql.Connection" level="DEBUG"/>-->
<!-- <logger name="java.sql.Statement" level="DEBUG"/>-->
<!-- <logger name="java.sql.PreparedStatement" level="DEBUG"/>-->
<root level="INFO">
<appender-ref ref="SKYWALKING"/>
<appender-ref ref="file"/>
</root>
<!-- 配置开发环境,多个使用逗号隔开(例如:dev,sit) -->
<!-- <springProfile name="dev">
<!–定义日志输出级别–>
<root level="INFO">
<appender-ref ref="stdout"/>
<appender-ref ref="file"/>
</root>
</springProfile>
<!– 配置测试环境,多个使用逗号隔开 –>
<springProfile name="sit">
<!–定义日志输出级别–>
<root level="INFO">
<appender-ref ref="stdout"/>
<appender-ref ref="file"/>
</root>
</springProfile>
<!– 配置生产环境,多个使用逗号隔开 –>
<springProfile name="prod">
<!–定义日志输出级别–>
<root level="INFO">
<appender-ref ref="stdout"/>
<appender-ref ref="file"/>
</root>
</springProfile>-->
</configuration>
其中最重要的是
appender name=“SKYWALKING” class 指定正确
同时要日志生效;必须修改服务 -javaagent的config/agent.config ; 我开始就是没指定这个;日志一直没生成
plugin.toolkit.log.grpc.reporter.server_host=${SW_GRPC_LOG_SERVER_HOST:skywalking服务ip}
plugin.toolkit.log.grpc.reporter.server_port=${SW_GRPC_LOG_SERVER_PORT:11800}
plugin.toolkit.log.grpc.reporter.max_message_size=${SW_GRPC_LOG_MAX_MESSAGE_SIZE:10485760}
plugin.toolkit.log.grpc.reporter.upstream_timeout=${SW_GRPC_LOG_GRPC_UPSTREAM_TIMEOUT:30}
plugin.toolkit.log.transmit_formatted=${SW_PLUGIN_TOOLKIT_LOG_TRANSMIT_FORMATTED:true}
测试使用日志
简单点直接controller使用一个;真实业务应该在service层比较合适
private final Logger log = LoggerFactory.getLogger(*controller.class);
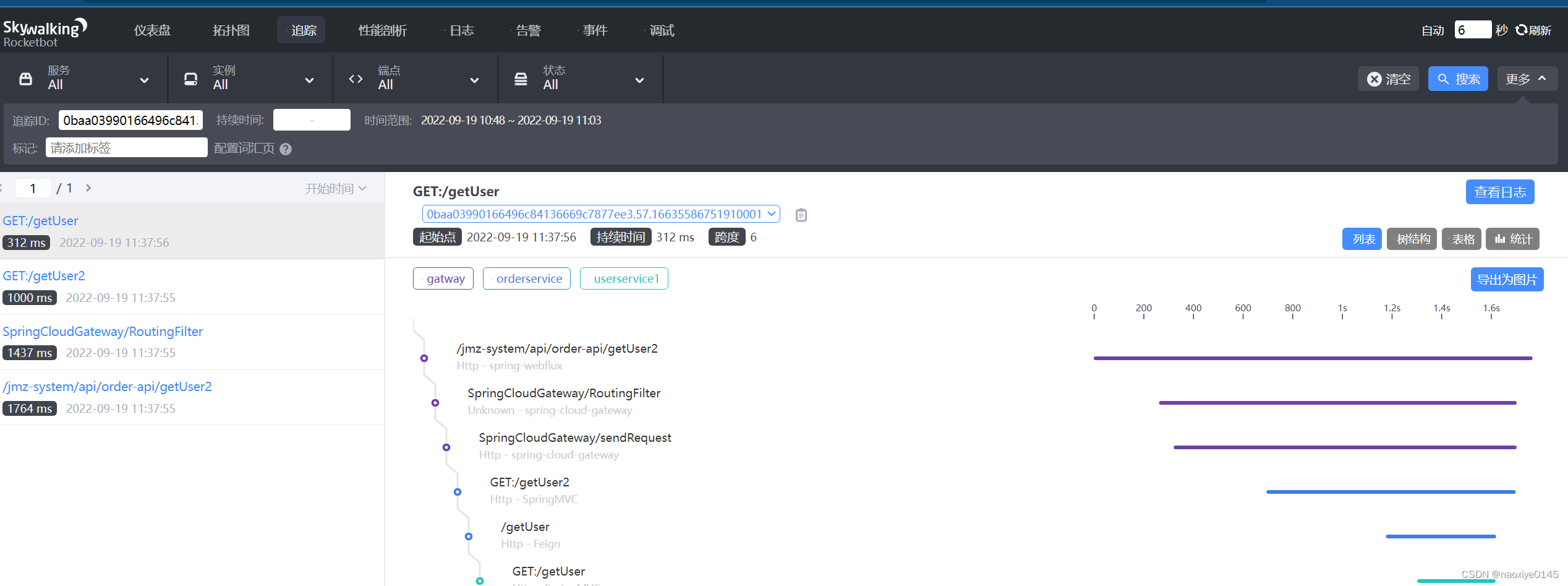

代码里面获取日志的tranceid
String traceId = TraceContext.traceId();
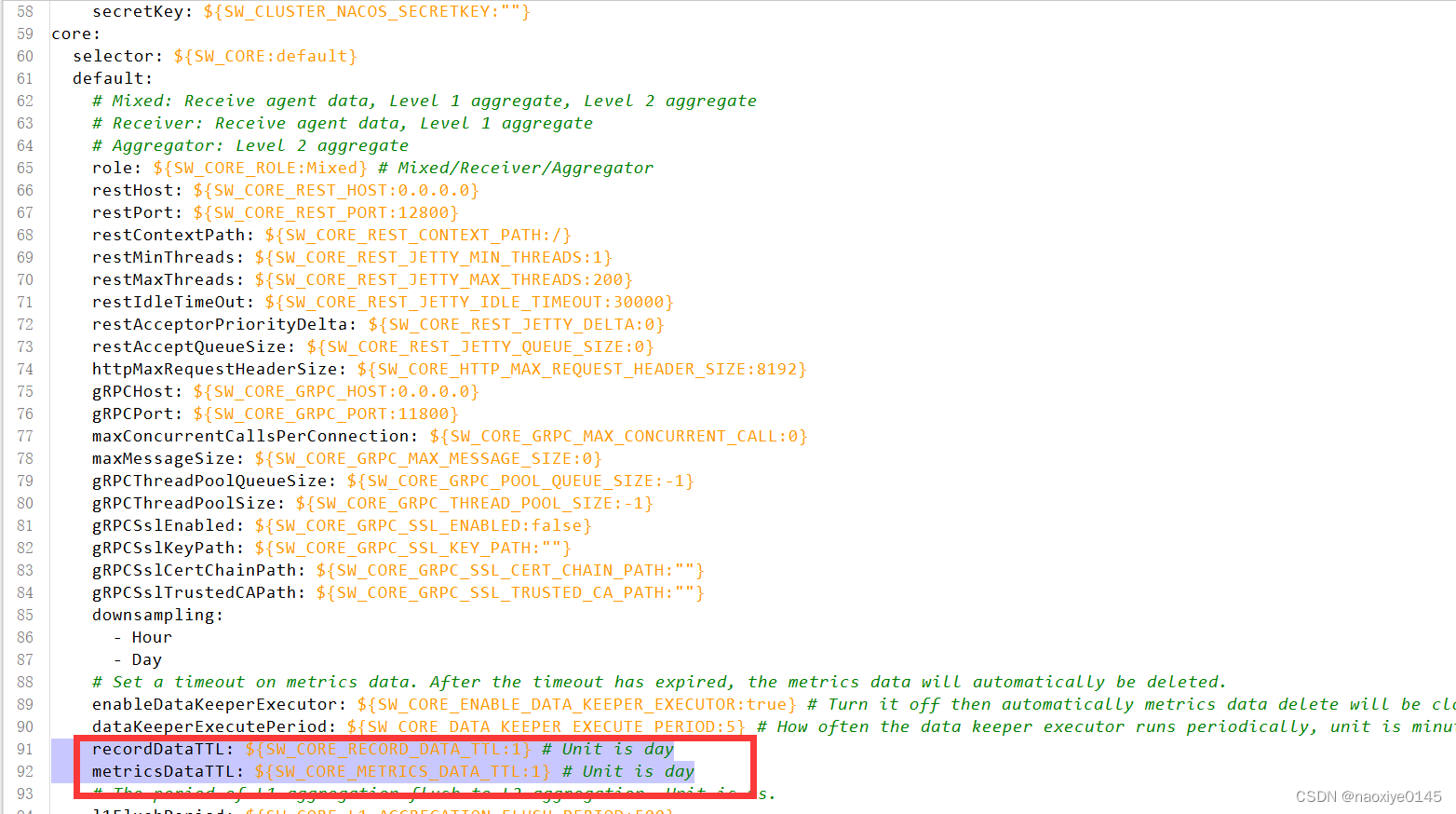
以上配置保留一天;其他详细需求可以自行百度。
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
我想安装一个带有一些身份验证的私有(private)Rubygem服务器。我希望能够使用公共(public)Ubuntu服务器托管内部gem。我读到了http://docs.rubygems.org/read/chapter/18.但是那个没有身份验证-如我所见。然后我读到了https://github.com/cwninja/geminabox.但是当我使用基本身份验证(他们在他们的Wiki中有)时,它会提示从我的服务器获取源。所以。如何制作带有身份验证的私有(private)Rubygem服务器?这是不可能的吗?谢谢。编辑:Geminabox问题。我尝试“捆绑”以安装新的gem..
我尝试使用不同的ssh_options在同一阶段运行capistranov.3任务。我的production.rb说:set:stage,:productionset:user,'deploy'set:ssh_options,{user:'deploy'}通过此配置,capistrano与用户deploy连接,这对于其余的任务是正确的。但是我需要将它连接到服务器中配置良好的an_other_user以完成一项特定任务。然后我的食谱说:...taskswithoriginaluser...task:my_task_with_an_other_userdoset:user,'an_othe
最近,当我启动我的Rails服务器时,我收到了一长串警告。虽然它不影响我的应用程序,但我想知道如何解决这些警告。我的估计是imagemagick以某种方式被调用了两次?当我在警告前后检查我的git日志时。我想知道如何解决这个问题。-bcrypt-ruby(3.1.2)-better_errors(1.0.1)+bcrypt(3.1.7)+bcrypt-ruby(3.1.5)-bcrypt(>=3.1.3)+better_errors(1.1.0)bcrypt和imagemagick有关系吗?/Users/rbchris/.rbenv/versions/2.0.0-p247/lib/ru
在Rails4.0.2中,我使用s3_direct_upload和aws-sdkgems直接为s3存储桶上传文件。在开发环境中它工作正常,但在生产环境中它会抛出如下错误,ActionView::Template::Error(noimplicitconversionofnilintoString)在View中,create_cv_url,:id=>"s3_uploader",:key=>"cv_uploads/{unique_id}/${filename}",:key_starts_with=>"cv_uploads/",:callback_param=>"cv[direct_uplo
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
我想在Ruby中创建一个用于开发目的的极其简单的Web服务器(不,不想使用现成的解决方案)。代码如下:#!/usr/bin/rubyrequire'socket'server=TCPServer.new('127.0.0.1',8080)whileconnection=server.acceptheaders=[]length=0whileline=connection.getsheaders想法是从命令行运行这个脚本,提供另一个脚本,它将在其标准输入上获取请求,并在其标准输出上返回完整的响应。到目前为止一切顺利,但事实证明这真的很脆弱,因为它在第二个请求上中断并出现错误:/usr/b
您如何在Rails中的实时服务器上进行有效调试,无论是在测试版/生产服务器上?我试过直接在服务器上修改文件,然后重启应用,但是修改好像没有生效,或者需要很长时间(缓存?)我也试过在本地做“脚本/服务器生产”,但是那很慢另一种选择是编码和部署,但效率很低。有人对他们如何有效地做到这一点有任何见解吗? 最佳答案 我会回答你的问题,即使我不同意这种热修补服务器代码的方式:)首先,你真的确定你已经重启了服务器吗?您可以通过跟踪日志文件来检查它。您更改的代码显示的View可能会被缓存。缓存页面位于tmp/cache文件夹下。您可以尝试手动删除
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.