Heapster是容器集群监控和性能分析工具,天然的支持Kubernetes和CoreOS
heapster监控目前官网已经不更新,部署学习使用
heapster: 收集监控数据
influxdb:数据库,存储数据
grafana:web页面展示
1、heapster安装包下载
地址:https://github.com/kubernetes-retired/heapster/releases
把对应的tar包下载
解压包,在路径:heapster-1.5.4\heapster-1.5.4\deploy\kube-config\rbac下找到heapster-rbac.yaml
在路径heapster-1.5.4\heapster-1.5.4\deploy\kube-config\influxdb下找到grafana.yaml,heapster.yaml,influxdb.yaml2、部署influxdb
新版本k8sapi变动,修改Deployment apiVersion为apiVersion: apps/v1
镜像修改为国内镜像源:image: registry.aliyuncs.com/google_containers/heapster-influxdb-amd64:v1.5.2
增加selector选择器
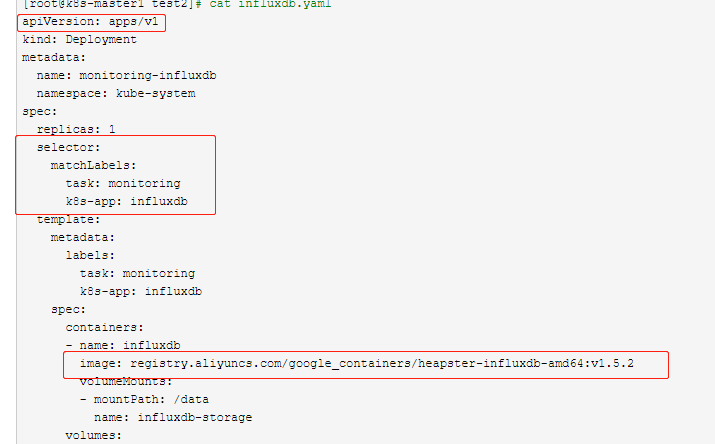
[root@k8s-master1 test2]# cat influxdb.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: monitoring-influxdb
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
task: monitoring
k8s-app: influxdb
template:
metadata:
labels:
task: monitoring
k8s-app: influxdb
spec:
containers:
- name: influxdb
image: registry.aliyuncs.com/google_containers/heapster-influxdb-amd64:v1.5.2
volumeMounts:
- mountPath: /data
name: influxdb-storage
volumes:
- name: influxdb-storage
emptyDir: {}
---
apiVersion: v1
kind: Service
metadata:
labels:
task: monitoring
# For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons)
# If you are NOT using this as an addon, you should comment out this line.
kubernetes.io/cluster-service: 'true'
kubernetes.io/name: monitoring-influxdb
name: monitoring-influxdb
namespace: kube-system
spec:
ports:
- port: 8086
targetPort: 8086
selector:
k8s-app: influxdb
部署influxdb:
# kubectl apply -f influxdb.yaml
3、部署heapster
新版本k8sapi变动,修改Deployment apiVersion为apiVersion: apps/v1
镜像修改为国内镜像源:image: registry.aliyuncs.com/google_containers/heapster-amd64:v1.5.4
增加selector选择器
source参数修改为:- --source=kubernetes:https://kubernetes.default?kubeletHttps=true&kubeletPort=10250&insecure=true
不修改会提示报错,kubectl logs可以查询到对应报错信息

[root@k8s-master1 test2]# cat heapster.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: heapster
namespace: kube-system
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: heapster
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
task: monitoring
k8s-app: heapster
template:
metadata:
labels:
task: monitoring
k8s-app: heapster
spec:
serviceAccountName: heapster
containers:
- name: heapster
image: registry.aliyuncs.com/google_containers/heapster-amd64:v1.5.4
imagePullPolicy: IfNotPresent
command:
- /heapster
- --source=kubernetes:https://kubernetes.default?kubeletHttps=true&kubeletPort=10250&insecure=true
- --sink=influxdb:http://monitoring-influxdb.kube-system.svc:8086
---
apiVersion: v1
kind: Service
metadata:
labels:
task: monitoring
# For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons)
# If you are NOT using this as an addon, you should comment out this line.
kubernetes.io/cluster-service: 'true'
kubernetes.io/name: Heapster
name: heapster
namespace: kube-system
spec:
ports:
- port: 80
targetPort: 8082
selector:
k8s-app: heapster用户权限,默认的没有create权限
# kubectl apply -f heapster-rbac.yaml
重新导出yaml文件,修改rule角色权限
# kubectl get ClusterRole system:heapster -o yaml > heapster_modify.yaml
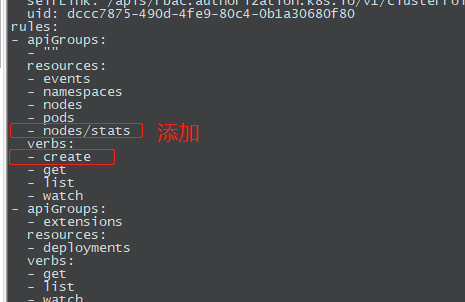
# kubectl apply -f heapster_modify.yaml
部署heapster
#kubectl apply -f heapster.yaml
查询角色权限,verbs中有了create权限
[root@k8s-master1 test2]# kubectl describe ClusterRole system:heapster
Name: system:heapster
Labels: kubernetes.io/bootstrapping=rbac-defaults
Annotations: rbac.authorization.kubernetes.io/autoupdate: true
PolicyRule:
Resources Non-Resource URLs Resource Names Verbs
--------- ----------------- -------------- -----
events [] [] [create get list watch]
namespaces [] [] [create get list watch]
nodes/stats [] [] [create get list watch]
nodes [] [] [create get list watch]
pods [] [] [create get list watch]
deployments.extensions [] [] [get list watch]
4、部署grafana
新版本k8sapi变动,修改Deployment apiVersion为apiVersion: apps/v1
镜像修改为国内镜像源:image: registry.aliyuncs.com/google_containers/heapster-grafana-amd64:v5.0.4
增加selector选择器
[root@k8s-master1 test2]# cat grafana.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: monitoring-grafana
namespace: kube-system
spec:
replicas: 1
selector:
matchLabels:
task: monitoring
k8s-app: grafana
template:
metadata:
labels:
task: monitoring
k8s-app: grafana
spec:
containers:
- name: grafana
image: registry.aliyuncs.com/google_containers/heapster-grafana-amd64:v5.0.4
ports:
- containerPort: 3000
protocol: TCP
volumeMounts:
- mountPath: /etc/ssl/certs
name: ca-certificates
readOnly: true
- mountPath: /var
name: grafana-storage
env:
- name: INFLUXDB_HOST
value: monitoring-influxdb
- name: GF_SERVER_HTTP_PORT
value: "3000"
# The following env variables are required to make Grafana accessible via
# the kubernetes api-server proxy. On production clusters, we recommend
# removing these env variables, setup auth for grafana, and expose the grafana
# service using a LoadBalancer or a public IP.
- name: GF_AUTH_BASIC_ENABLED
value: "false"
- name: GF_AUTH_ANONYMOUS_ENABLED
value: "true"
- name: GF_AUTH_ANONYMOUS_ORG_ROLE
value: Admin
- name: GF_SERVER_ROOT_URL
# If you're only using the API Server proxy, set this value instead:
# value: /api/v1/namespaces/kube-system/services/monitoring-grafana/proxy
value: /
volumes:
- name: ca-certificates
hostPath:
path: /etc/ssl/certs
- name: grafana-storage
emptyDir: {}
---
apiVersion: v1
kind: Service
metadata:
labels:
# For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons)
# If you are NOT using this as an addon, you should comment out this line.
kubernetes.io/cluster-service: 'true'
kubernetes.io/name: monitoring-grafana
name: monitoring-grafana
namespace: kube-system
spec:
# In a production setup, we recommend accessing Grafana through an external Loadbalancer
# or through a public IP.
# type: LoadBalancer
# You could also use NodePort to expose the service at a randomly-generated port
# type: NodePort
ports:
- port: 80
targetPort: 3000
selector:
k8s-app: grafana
type: NodePort
部署grafana
# kubectl apply -f grafana.yaml
5、查询部署资源
[root@k8s-master1 test2]# kubectl get all -n kube-system | egrep 'heapster|monitor'
pod/heapster-7f6787db47-xjtg2 1/1 Running 2 17h
pod/monitoring-grafana-745bf97858-5484w 1/1 Running 2 18h
pod/monitoring-influxdb-77864d8b5-dlwwz 1/1 Running 2 18h
service/heapster ClusterIP 10.103.130.255 <none> 80/TCP 17h
service/monitoring-grafana NodePort 10.102.137.71 <none> 80:31526/TCP 18h
service/monitoring-influxdb ClusterIP 10.102.238.82 <none> 8086/TCP 18h
deployment.apps/heapster 1/1 1 1 17h
deployment.apps/monitoring-grafana 1/1 1 1 18h
deployment.apps/monitoring-influxdb 1/1 1 1 18h
replicaset.apps/heapster-7f6787db47 1 1 1 17h
replicaset.apps/monitoring-grafana-745bf97858 1 1 1 18h
replicaset.apps/monitoring-influxdb-77864d8b5 1 1 1 18h
6、可以使用top命令查询node,pod等资源监控数据。这个需要等一段时间才会有数据
[root@k8s-master1 test2]# kubectl top node
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-master1 125m 6% 1140Mi 29%
k8s-node1 39m 1% 587Mi 15%
k8s-node2 39m 1% 479Mi 12%
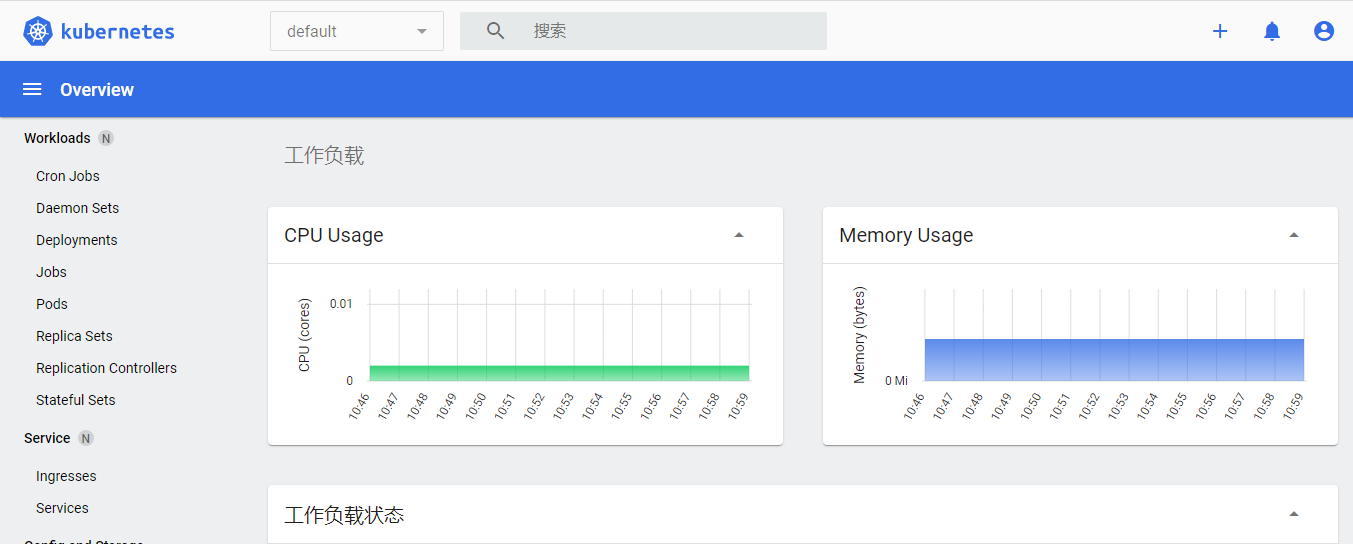
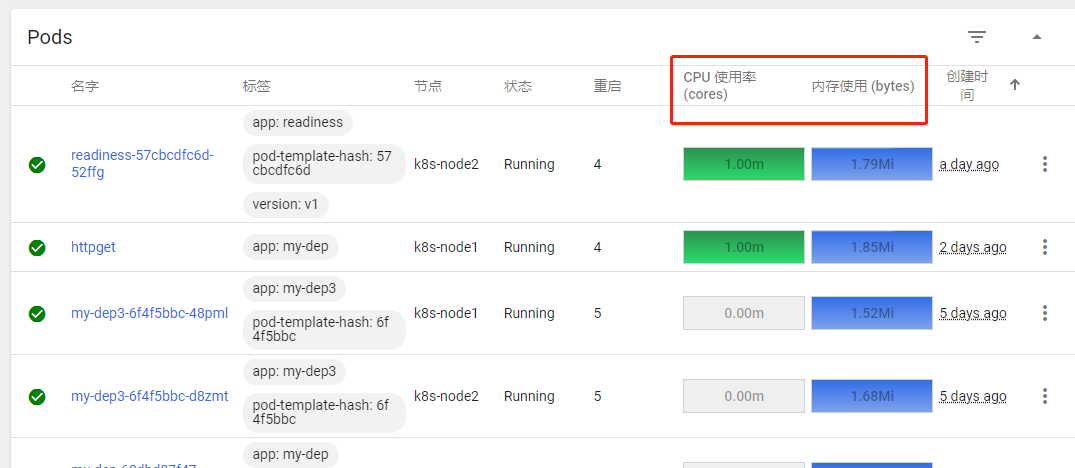
7、 结果展示,在dashboard页面可以看到资源监控数据
我是Google云的新手,我正在尝试对其进行首次部署。我的第一个部署是RubyonRails项目。我基本上是在关注thisguideinthegoogleclouddocumentation.唯一的区别是我使用的是我自己的项目,而不是他们提供的“helloworld”项目。这是我的app.yaml文件runtime:customvm:trueentrypoint:bundleexecrackup-p8080-Eproductionconfig.ruresources:cpu:0.5memory_gb:1.3disk_size_gb:10当我转到我的项目目录并运行gcloudprevie
我可以在Azure网站上部署RubyonRails吗? 最佳答案 还没有。目前仅支持.NET和PHP。 关于ruby-on-rails-RubyonRails可以部署在Azure网站上吗?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/12964010/
这篇文章是继上一篇文章“Observability:从零开始创建Java微服务并监控它(一)”的续篇。在上一篇文章中,我们讲述了如何创建一个Javaweb应用,并使用Filebeat来收集应用所生成的日志。在今天的文章中,我来详述如何收集应用的指标,使用APM来监控应用并监督web服务的在线情况。源码可以在地址 https://github.com/liu-xiao-guo/java_observability 进行下载。摄入指标指标被视为可以随时更改的时间点值。当前请求的数量可以改变任何毫秒。你可能有1000个请求的峰值,然后一切都回到一个请求。这也意味着这些指标可能不准确,你还想提取最小/
前置步骤我们都操作完了,这篇开始介绍jenkins的集成。话不多说,看操作1、登录进入jenkins后会让你选择安装插件,选择第一个默认的就行。安装完成后设置账号密码,重新登录。2、配置JDK和Git都需要执行路径,所以需要先把执行路径找到,先进入服务器的docker容器,2.1JDK的路径root@69eef9ee86cf:/usr/bin#echo$JAVA_HOME/usr/local/openjdk-82.2Git的路径root@69eef9ee86cf:/#whichgit/usr/bin/git3、先配置JDK和Git。点击:ManageJenkins>>GlobalToolCon
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
Ocra无法处理需要“tk”的应用程序require'tk'puts'nope'用奥克拉http://github.com/larsch/ocra不起作用(如链接中的一个问题所述)问题:https://github.com/larsch/ocra/issues/29(Ocra是1.9的"new"rubyscript2exe,本质上它用于将rb脚本部署为可执行文件)唯一的问题似乎是缺少tcl的DLL文件我不认为这是一个问题据我所知,问题是缺少tk的DLL文件如果它们是已知的,则可以在执行ocra时将它们包括在内有没有办法知道tk工作所需的DLL依赖项? 最佳答
我有一个类unzipper.rb,它使用Rubyzip解压文件。在我的本地环境中,我可以成功解压缩文件,而无需使用require'zip'明确包含依赖项但是在Heroku上,我得到一个NameError(uninitializedconstantUnzipper::Zip)我只能通过使用明确的require来解决问题:为什么这在Heroku环境中是必需的,但在本地主机上却不是?我的印象是Rails自动需要所有gem。app/services/unzipper.rbrequire'zip'#OnlyrequiredforHeroku.Workslocallywithout!class
出于某种原因,heroku尝试要求dm-sqlite-adapter,即使它应该在这里使用Postgres。请注意,这发生在我打开任何URL时-而不是在gitpush本身期间。我构建了一个默认的Facebook应用程序。gem文件:source:gemcuttergem"foreman"gem"sinatra"gem"mogli"gem"json"gem"httparty"gem"thin"gem"data_mapper"gem"heroku"group:productiondogem"pg"gem"dm-postgres-adapter"endgroup:development,:t
如何使用Capistrano将Rails应用程序部署到无法访问外部网络或存储库的生产或暂存服务器?我已经设法完成部署的一半,并意识到Capistrano没有在我的本地机器上下载gitrepo,但它首先连接到远程服务器并尝试在那里下载Git存储库。我希望有一个类似Javaee的构建系统,其中创建可交付成果并将该可交付成果发送到服务器。就像您构建.ear文件并将其部署到您想要的任何服务器上一样。显然在RoR中,你被迫(据我所知)在该服务器上构建应用程序,在那里创建一个gem存储库,在那里克隆最新的分支等等。有什么方法可以将准备运行的包发送到远程服务器吗? 最佳答
集成背景我们当前集群使用的是ClouderaCDP,Flink版本为ClouderaVersion1.14,整体Flink安装目录以及配置文件结构与社区版本有较大出入。直接根据Streampark官方文档进行部署,将无法配置FlinkHome,以及后续整体Flink任务提交到集群中,因此需要进行针对化适配集成,在满足使用需求上,尽量提供完整的Streampark使用体验。集成步骤版本匹配问题解决首先解决无法识别Cloudera中的FlinkHome问题,根据报错主要明确到的事情是无法读取到Flink版本、lib下面的jar包名称无法匹配。修改对象:修改源码:(解决无法匹配clouderajar