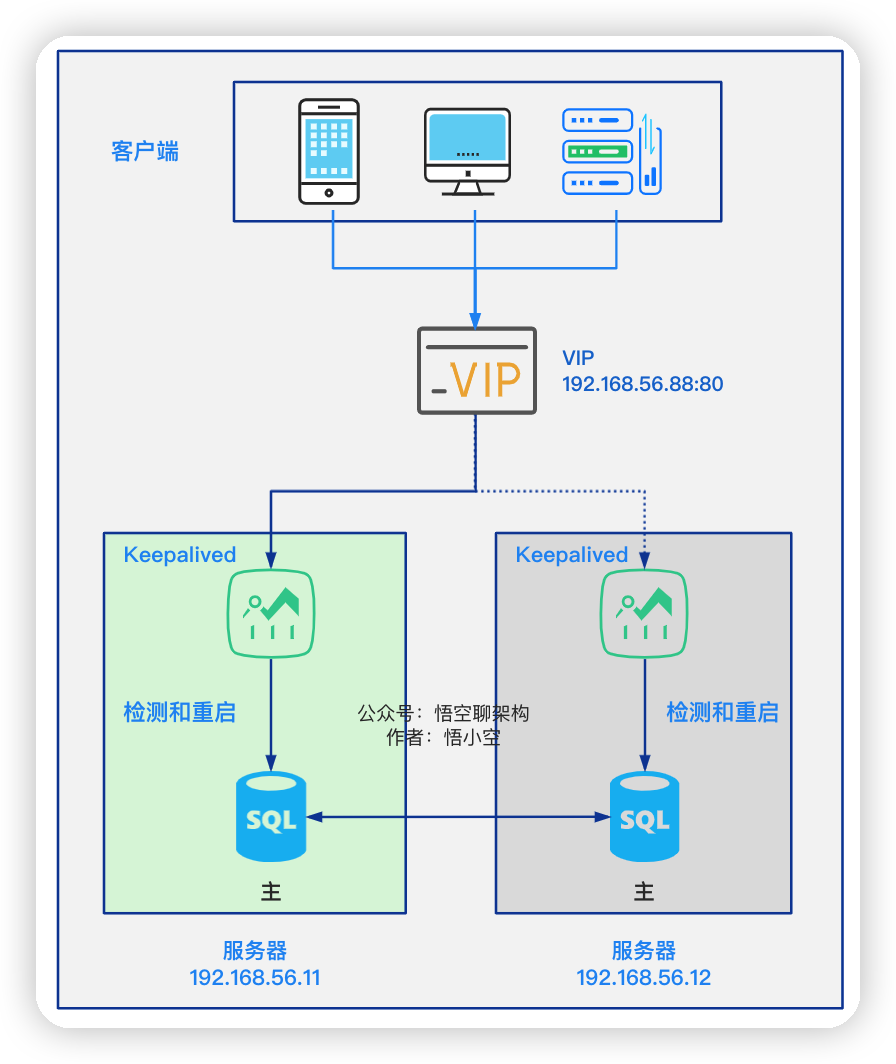
 但是经常出现数据冲突的问题,于是我们又把
但是经常出现数据冲突的问题,于是我们又把双主模式改为了主从读写分离模式。主库作为读写库,再加上一个从库用来做 I/O 密集型的任务(如大量的数据统计操作)。如下图所示: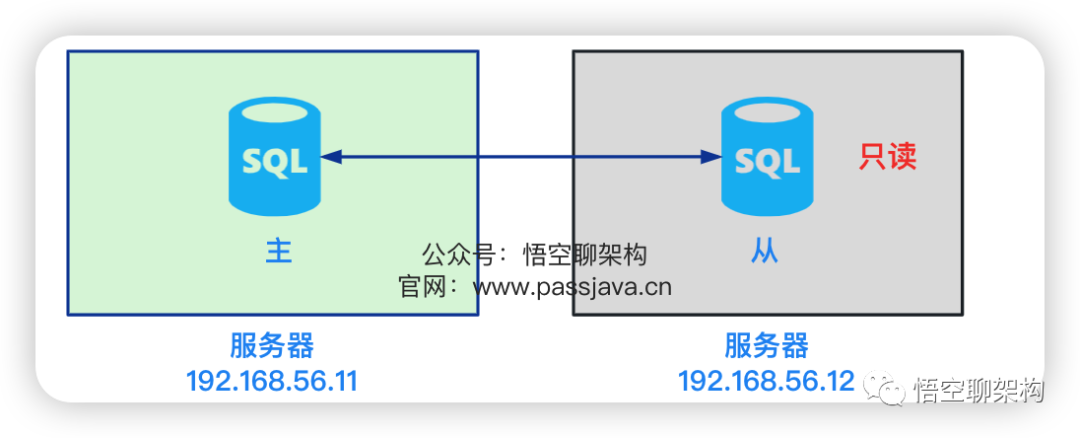 另外从库复制的模式采用
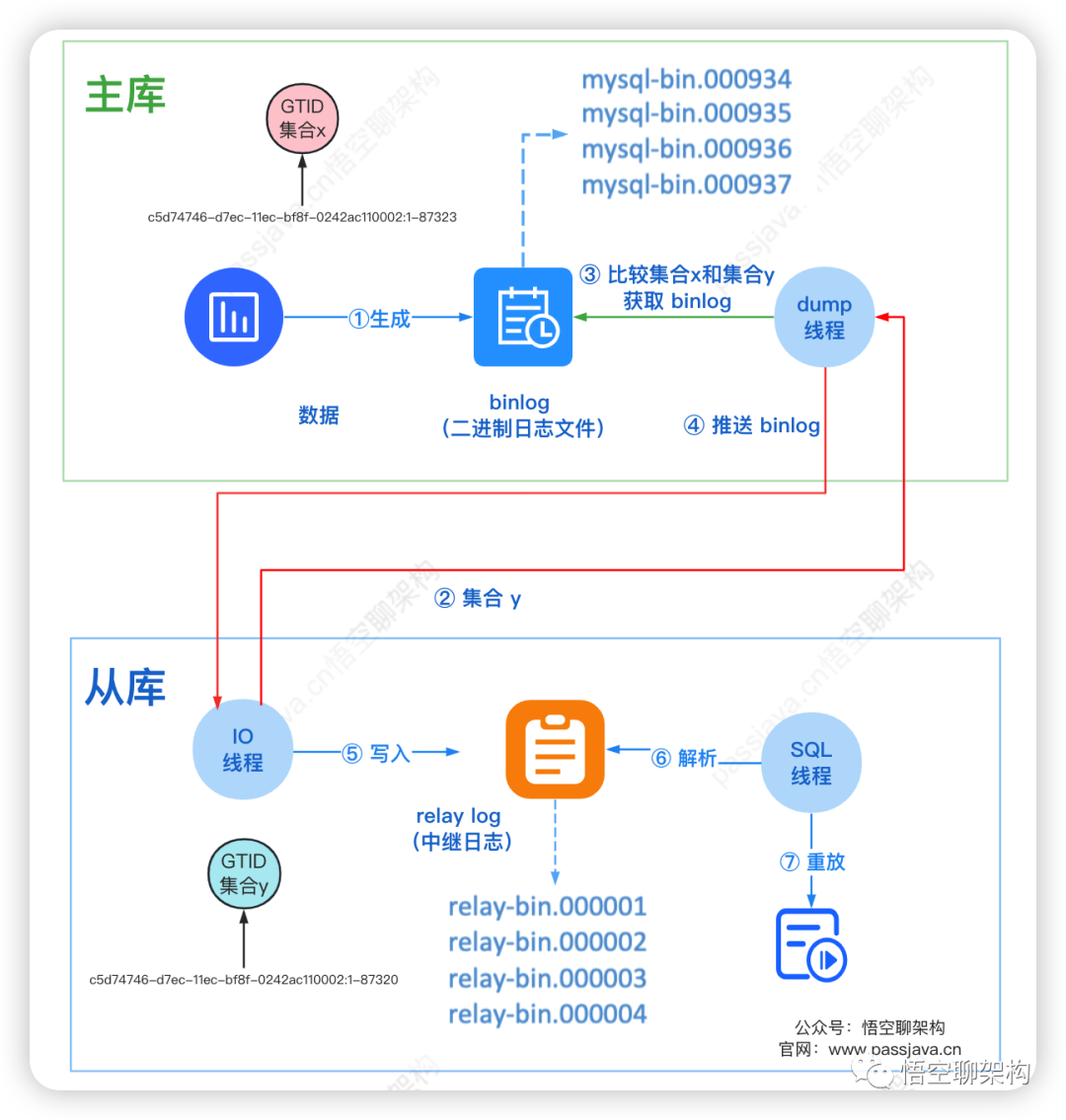
另外从库复制的模式采用位点的方式:指定 binlog 文件和 binlog 位置,这样从库就知道了复制的起始位置。(下文会讲解这种方式)虽然改为了主从模式,但依旧遇到了些问题:mixed,从库同步时出现不一致的情况。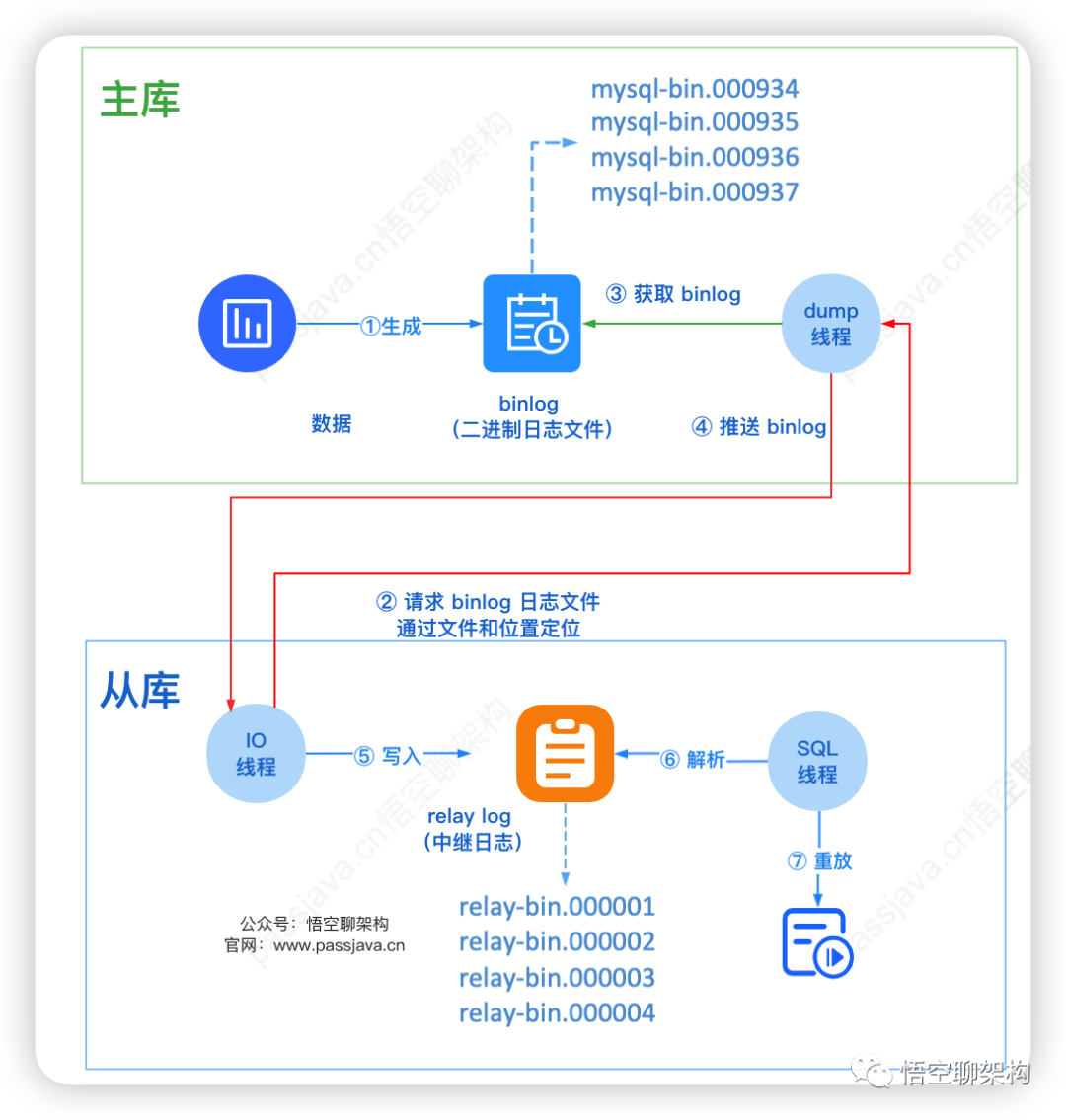 1、主库会生成多个 binlog 日志文件。2、从库的I/O 线程请求指定文件和指定位置的 binlog 日志文件(位点)。3、主库 dump 线程获取指定位点的 binlog 日志。4、主库按照从库发送给来的位点信息读取 binlog,然后推送 binlog 给从库。5、从库将得到的 binlog 写到本地的 relay log (中继日志) 文件中。6、从库的 SQL 线程读取和解析 relay log 文件。7、从库的 SQL 线程重放 relay log 中的命令。当我们使用位点同步的方式时,两种场景下的操作步骤比较复杂。
1、主库会生成多个 binlog 日志文件。2、从库的I/O 线程请求指定文件和指定位置的 binlog 日志文件(位点)。3、主库 dump 线程获取指定位点的 binlog 日志。4、主库按照从库发送给来的位点信息读取 binlog,然后推送 binlog 给从库。5、从库将得到的 binlog 写到本地的 relay log (中继日志) 文件中。6、从库的 SQL 线程读取和解析 relay log 文件。7、从库的 SQL 线程重放 relay log 中的命令。当我们使用位点同步的方式时,两种场景下的操作步骤比较复杂。不论是首次开启同步时需要找位点和设置位点,还是恢复主从复制时,设置位点和忽略错误,这些步骤都显得过于复杂,而且容易出错。所以 MySQL 5.6 版本引入了 GTID,彻底解决了这个困难。
c5d74746-d7ec-11ec-bf8f-0242ac110002:1GTID=server_uuid:gno#GTID:
gtid_mode=on
enforce_gtid_cnotallow=onCHANGE MASTER TO
MASTER_HOST=$host_name
MASTER_PORT=$port
MASTER_USER=$user_name
MASTER_PASSWORD=$password
master_auto_positinotallow=1 GTID 方案:主库计算主库 GTID 集合和从库 GTID 的集合的差集,主库推送差集 binlog 给从库。当从库设置完同步参数后,主库 A 的GTID 集合记为集合 x,从库 B 的 GTID 集合记为 y。从库同步的逻辑如下:
seconds_behind_master 参数的值,如下图所示,Seconds_Behind_Master 等于 0 Seconds_Behind_Master 的单位是秒,所以精度不准确。所以为了保证查询的数据是和主库一致的,就需要先判断 seconds_behind_master 是否已经等于 0,如果不等于 0,就必须等到这个参数变为 0 才能执行查询请求。
Seconds_Behind_Master 的单位是秒,所以精度不准确。所以为了保证查询的数据是和主库一致的,就需要先判断 seconds_behind_master 是否已经等于 0,如果不等于 0,就必须等到这个参数变为 0 才能执行查询请求。show slave status \G命令后的结果: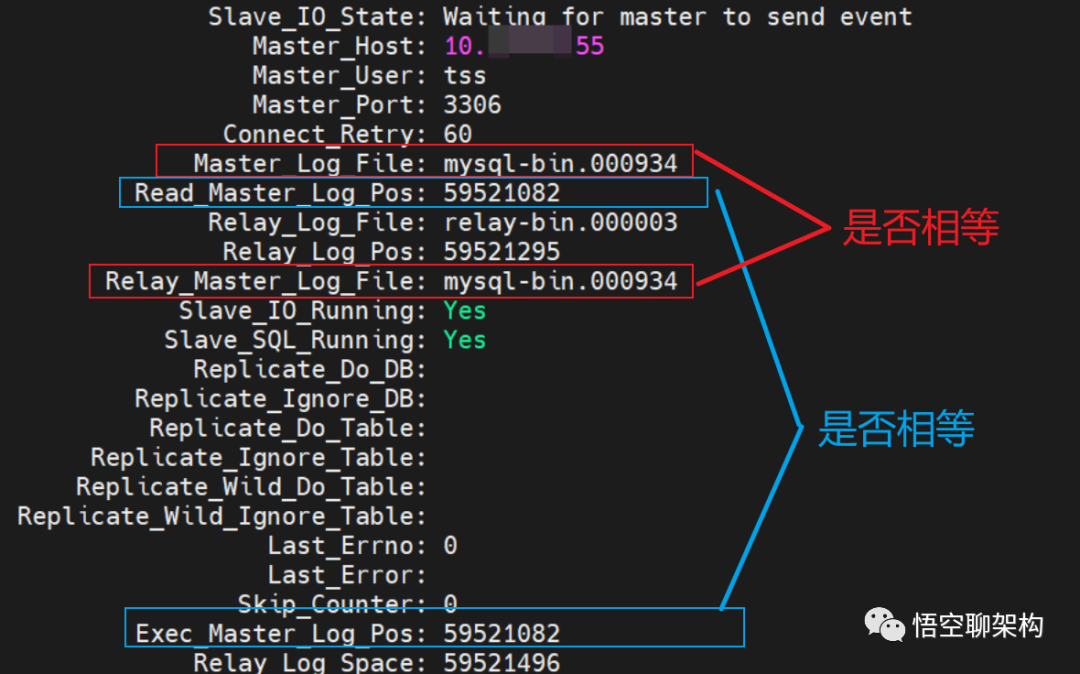 Master_Log_File 和 Read_Master_Log_Pos 这两个参数合起来表示的是读到的主库的最新位点,第一参数是代表读取到了哪个文件,第二个是读取到的文件的位置。Relay_Master_Log_File 和 Exec_Master_Log_Pos,这两个参数合起来表示的是从库执行的最新位点。如果红色框起来的两个参数:Master_Log_File 和 Relay_Master_Log_File 相等,则说明从库读到的最新文件和主库上生成的文件相同,这里都是 mysql-bin.000934。如果蓝色框起来的两个参数 Read_Master_Log_Pos 和 Exec_Master_Log_Pos 相等,则说明从库读到的日志文件的位置和从库上执行日志文件的位置相同,这里都是 59521082。当上面两组参数都相等时,则说明没有延迟。
Master_Log_File 和 Read_Master_Log_Pos 这两个参数合起来表示的是读到的主库的最新位点,第一参数是代表读取到了哪个文件,第二个是读取到的文件的位置。Relay_Master_Log_File 和 Exec_Master_Log_Pos,这两个参数合起来表示的是从库执行的最新位点。如果红色框起来的两个参数:Master_Log_File 和 Relay_Master_Log_File 相等,则说明从库读到的最新文件和主库上生成的文件相同,这里都是 mysql-bin.000934。如果蓝色框起来的两个参数 Read_Master_Log_Pos 和 Exec_Master_Log_Pos 相等,则说明从库读到的日志文件的位置和从库上执行日志文件的位置相同,这里都是 59521082。当上面两组参数都相等时,则说明没有延迟。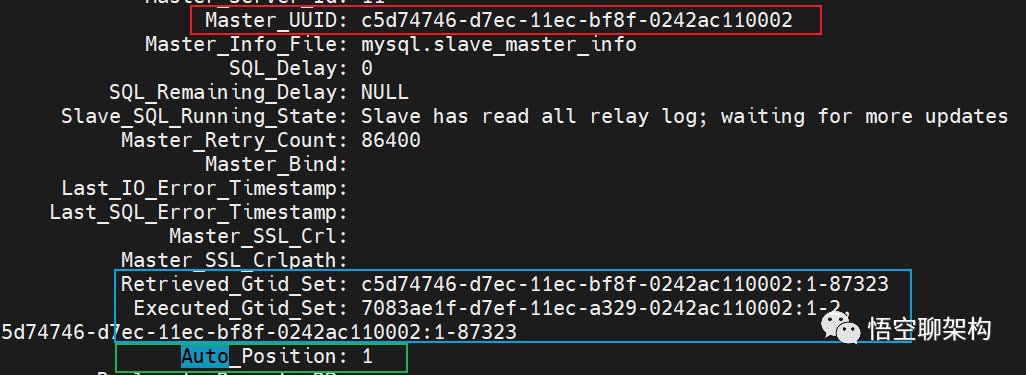 Master_UUID 表示当前连接的主库的 ID。Auto_Position: 1 表示主备使用了 GTID 协议。Retrieved_Gtid_Set 表示从库收到的所有日志的 GTID 集合。Executed_Gtid_Set 表示从库已经执行完成的 GTID 集合。如果 Executed_Gtid_Set 集合是包含 Retrieved_Gtid_Set,则表示从库接收到的日志已经同步完成。比如上图中 Retrieved_Gtid_Set 值为
Master_UUID 表示当前连接的主库的 ID。Auto_Position: 1 表示主备使用了 GTID 协议。Retrieved_Gtid_Set 表示从库收到的所有日志的 GTID 集合。Executed_Gtid_Set 表示从库已经执行完成的 GTID 集合。如果 Executed_Gtid_Set 集合是包含 Retrieved_Gtid_Set,则表示从库接收到的日志已经同步完成。比如上图中 Retrieved_Gtid_Set 值为c5d74746-d7ec-11ec-bf8f-0242ac110002:1-873237083ae1f-d7ef-11ec-a329-0242ac110002:1-2,
c5d74746-d7ec-11ec-bf8f-0242ac110002:1-87323很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
鉴于我有以下迁移:Sequel.migrationdoupdoalter_table:usersdoadd_column:is_admin,:default=>falseend#SequelrunsaDESCRIBEtablestatement,whenthemodelisloaded.#Atthispoint,itdoesnotknowthatusershaveais_adminflag.#Soitfails.@user=User.find(:email=>"admin@fancy-startup.example")@user.is_admin=true@user.save!ende
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
文章目录一、概述简介原理模块二、配置Mysql使用版本环境要求1.操作系统2.mysql要求三、配置canal-server离线下载在线下载上传解压修改配置单机配置集群配置分库分表配置1.修改全局配置2.实例配置垂直分库水平分库3.修改group-instance.xml4.启动监听四、配置canal-adapter1修改启动配置2配置映射文件3启动ES数据同步查询所有订阅同步数据同步开关启动4.验证五、配置canal-admin一、概述简介canal是Alibaba旗下的一款开源项目,Java开发。基于数据库增量日志解析,提供增量数据订阅&消费。Git地址:https://github.co
了解Rails缓存如何工作的人可以真正帮助我。这是嵌套在Rails::Initializer.runblock中的代码:config.after_initializedoSomeClass.const_set'SOME_CONST','SOME_VAL'end现在,如果我运行script/server并发出请求,一切都很好。然而,在我的Rails应用程序的第二个请求中,一切都因单元化常量错误而变得糟糕。在生产模式下,我可以成功发出第二个请求,这意味着常量仍然存在。我已通过将以上内容更改为以下内容来解决问题:config.after_initializedorequire'some_cl
我认为我的问题最好用一个例子来描述。假设我有一个名为“Thing”的简单模型,它有一些简单数据类型的属性。像...Thing-foo:string-goo:string-bar:int这并不难。数据库表将包含具有这三个属性的三列,我可以使用@thing.foo或@thing.bar之类的东西访问它们。但我要解决的问题是当“foo”或“goo”不再包含在简单数据类型中时会发生什么?假设foo和goo代表相同类型的对象。也就是说,它们都是“Whazit”的实例,只是数据不同。所以现在事情可能看起来像这样......Thing-bar:int但是现在有一个新的模型叫做“Whazit”,看起来
我有一个要在我的Rails3项目中使用的数组扩展方法。它应该住在哪里?我有一个应用程序/类,我最初把它放在(array_extensions.rb)中,在我的config/application.rb中我加载路径:config.autoload_paths+=%W(#{Rails.root}/应用程序/类)。但是,当我转到railsconsole时,未加载扩展。是否有一个预定义的位置可以放置我的Rails3扩展方法?或者,一种预先定义的方式来添加它们?我知道Rails有自己的数组扩展方法。我应该将我的添加到active_support/core_ext/array/conversion