1.抠图技术应用很广泛,比如证件照,美体,人体区域特殊处理,还有B站的字幕穿人效果等等。这些的关键技术都在于高精度高性能的分割算法。RobustVideoMatting是来自字节跳动视频人像抠图算法(RVM),专为稳定人物视频抠像设计。 不同于现有神经网络将每一帧作为单独图片处理,RVM 使用循环神经网络,在处理视频流时有时间记忆。RVM 可在任意视频上做实时高清人像抠图。
2.关于RobustVideoMatting算法和模型训练步骤可以直接转到官方的git:https://github.com/PeterL1n/RobustVideoMatting。这里只实现模型的C++推理与部署。
3.使用的开发环境是win10,显卡RTX3080,cuda11.2,cudnn8.1,OpenCV4.5,onnxruntime,IDE 是Vs2019。
1.官方公布了很多种格式的模型,有mnn,ncnn,onnx等等,这里使用的是onnx这个模型,直接从这官方公布的地址(gym7)下载就可以了。
2.onnxruntime直接下载 官方编译好的release版本就可以使用了。
3.如果想用GPU进行推理,则要下载安装cuda,cudnn,具体安装方法网上有很多种,可以参考。
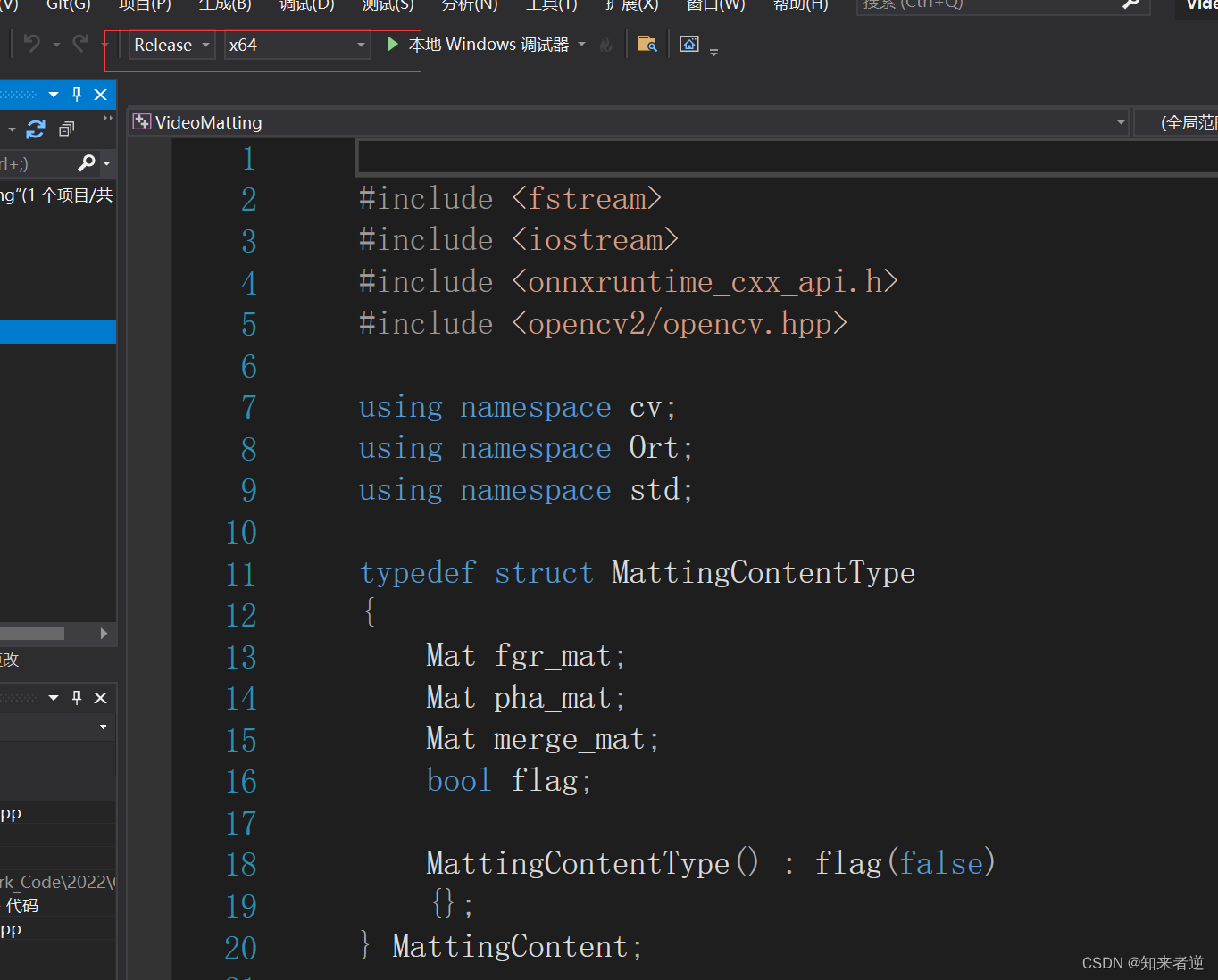
1.推理代码
typedef struct MattingContentType
{
Mat fgr_mat;
Mat pha_mat;
Mat merge_mat;
bool flag;
MattingContentType() : flag(false)
{};
} MattingContent;
class RobustVideoMatting
{
public:
RobustVideoMatting(string model_path);
void detect(const Mat& mat, MattingContent& content, float downsample_ratio);
private:
Session* session_;
Env env = Env(ORT_LOGGING_LEVEL_ERROR, "robustvideomatting");
SessionOptions sessionOptions = SessionOptions();
unsigned int num_inputs = 6;
vector<const char*> input_node_names = {
"src",
"r1i",
"r2i",
"r3i",
"r4i",
"downsample_ratio"
};
vector<vector<int64_t>> dynamic_input_node_dims = {
{1, 3, 1280, 720},
{1, 1, 1, 1},
{1, 1, 1, 1},
{1, 1, 1, 1},
{1, 1, 1, 1},
{1}
};
unsigned int num_outputs = 6;
vector<const char*> output_node_names = {
"fgr",
"pha",
"r1o",
"r2o",
"r3o",
"r4o"
};
vector<float> dynamic_src_value_handler;
vector<float> dynamic_r1i_value_handler = { 0.0f };
vector<float> dynamic_r2i_value_handler = { 0.0f };
vector<float> dynamic_r3i_value_handler = { 0.0f };
vector<float> dynamic_r4i_value_handler = { 0.0f };
vector<float> dynamic_dsr_value_handler = { 0.25f };
int64_t value_size_of(const std::vector<int64_t>& dims);
bool context_is_update = false;
void normalize_(Mat img, vector<float>& output);
vector<Ort::Value> transform(const Mat& mat);
void generate_matting(vector<Ort::Value>& output_tensors, MattingContent& content);
void update_context(vector<Ort::Value>& output_tensors);
};
RobustVideoMatting::RobustVideoMatting(string model_path)
{
wstring widestr = wstring(model_path.begin(), model_path.end());
sessionOptions.SetGraphOptimizationLevel(ORT_ENABLE_EXTENDED);
session_ = new Session(env, widestr.c_str(), sessionOptions);
}
void RobustVideoMatting::normalize_(Mat img, vector<float>& output)
{
int row = img.rows;
int col = img.cols;
for (int c = 0; c < 3; c++)
{
for (int i = 0; i < row; i++)
{
for (int j = 0; j < col; j++)
{
float pix = img.ptr<uchar>(i)[j * 3 + 2 - c];
output[c * row * col + i * col + j] = pix / 255.0;
}
}
}
}
int64_t RobustVideoMatting::value_size_of(const std::vector<int64_t>& dims)
{
if (dims.empty()) return 0;
int64_t value_size = 1;
for (const auto& size : dims) value_size *= size;
return value_size;
}
vector<Ort::Value> RobustVideoMatting::transform(const Mat& mat)
{
Mat src = mat.clone();
const unsigned int img_height = mat.rows;
const unsigned int img_width = mat.cols;
vector<int64_t>& src_dims = dynamic_input_node_dims.at(0);
src_dims.at(2) = img_height;
src_dims.at(3) = img_width;
std::vector<int64_t>& r1i_dims = dynamic_input_node_dims.at(1);
std::vector<int64_t>& r2i_dims = dynamic_input_node_dims.at(2);
std::vector<int64_t>& r3i_dims = dynamic_input_node_dims.at(3);
std::vector<int64_t>& r4i_dims = dynamic_input_node_dims.at(4);
std::vector<int64_t>& dsr_dims = dynamic_input_node_dims.at(5);
int64_t src_value_size = this->value_size_of(src_dims);
int64_t r1i_value_size = this->value_size_of(r1i_dims);
int64_t r2i_value_size = this->value_size_of(r2i_dims);
int64_t r3i_value_size = this->value_size_of(r3i_dims);
int64_t r4i_value_size = this->value_size_of(r4i_dims);
int64_t dsr_value_size = this->value_size_of(dsr_dims);
dynamic_src_value_handler.resize(src_value_size);
this->normalize_(src, dynamic_src_value_handler);
std::vector<Ort::Value> input_tensors;
auto allocator_info = MemoryInfo::CreateCpu(OrtDeviceAllocator, OrtMemTypeCPU);
input_tensors.push_back(Value::CreateTensor<float>(allocator_info,
dynamic_src_value_handler.data(), dynamic_src_value_handler.size(), src_dims.data(), src_dims.size()));
input_tensors.push_back(Value::CreateTensor<float>(allocator_info,
dynamic_r1i_value_handler.data(), r1i_value_size, r1i_dims.data(), r1i_dims.size()));
input_tensors.push_back(Value::CreateTensor<float>(allocator_info,
dynamic_r2i_value_handler.data(), r2i_value_size, r2i_dims.data(), r2i_dims.size()));
input_tensors.push_back(Value::CreateTensor<float>(allocator_info,
dynamic_r3i_value_handler.data(), r3i_value_size, r3i_dims.data(), r3i_dims.size()));
input_tensors.push_back(Value::CreateTensor<float>(allocator_info,
dynamic_r4i_value_handler.data(), r4i_value_size, r4i_dims.data(), r4i_dims.size()));
input_tensors.push_back(Value::CreateTensor<float>(allocator_info,
dynamic_dsr_value_handler.data(), dsr_value_size, dsr_dims.data(), dsr_dims.size()));
return input_tensors;
}
void RobustVideoMatting::generate_matting(std::vector<Ort::Value>& output_tensors, MattingContent& content)
{
Ort::Value& fgr = output_tensors.at(0);
Ort::Value& pha = output_tensors.at(1);
auto fgr_dims = fgr.GetTypeInfo().GetTensorTypeAndShapeInfo().GetShape();
auto pha_dims = pha.GetTypeInfo().GetTensorTypeAndShapeInfo().GetShape();
const unsigned int height = fgr_dims.at(2);
const unsigned int width = fgr_dims.at(3);
const unsigned int channel_step = height * width;
float* fgr_ptr = fgr.GetTensorMutableData<float>();
float* pha_ptr = pha.GetTensorMutableData<float>();
Mat rmat(height, width, CV_32FC1, fgr_ptr);
Mat gmat(height, width, CV_32FC1, fgr_ptr + channel_step);
Mat bmat(height, width, CV_32FC1, fgr_ptr + 2 * channel_step);
Mat pmat(height, width, CV_32FC1, pha_ptr);
rmat *= 255.;
bmat *= 255.;
gmat *= 255.;
Mat rest = 1. - pmat;
Mat mbmat = bmat.mul(pmat) + rest * 153.;
Mat mgmat = gmat.mul(pmat) + rest * 255.;
Mat mrmat = rmat.mul(pmat) + rest * 120.;
std::vector<Mat> fgr_channel_mats, merge_channel_mats;
fgr_channel_mats.push_back(bmat);
fgr_channel_mats.push_back(gmat);
fgr_channel_mats.push_back(rmat);
merge_channel_mats.push_back(mbmat);
merge_channel_mats.push_back(mgmat);
merge_channel_mats.push_back(mrmat);
content.pha_mat = pmat;
merge(fgr_channel_mats, content.fgr_mat);
merge(merge_channel_mats, content.merge_mat);
content.fgr_mat.convertTo(content.fgr_mat, CV_8UC3);
content.merge_mat.convertTo(content.merge_mat, CV_8UC3);
content.flag = true;
}
void RobustVideoMatting::update_context(std::vector<Ort::Value>& output_tensors)
{
Ort::Value& r1o = output_tensors.at(2);
Ort::Value& r2o = output_tensors.at(3);
Ort::Value& r3o = output_tensors.at(4);
Ort::Value& r4o = output_tensors.at(5);
auto r1o_dims = r1o.GetTypeInfo().GetTensorTypeAndShapeInfo().GetShape();
auto r2o_dims = r2o.GetTypeInfo().GetTensorTypeAndShapeInfo().GetShape();
auto r3o_dims = r3o.GetTypeInfo().GetTensorTypeAndShapeInfo().GetShape();
auto r4o_dims = r4o.GetTypeInfo().GetTensorTypeAndShapeInfo().GetShape();
dynamic_input_node_dims.at(1) = r1o_dims;
dynamic_input_node_dims.at(2) = r2o_dims;
dynamic_input_node_dims.at(3) = r3o_dims;
dynamic_input_node_dims.at(4) = r4o_dims;
int64_t new_r1i_value_size = this->value_size_of(r1o_dims);
int64_t new_r2i_value_size = this->value_size_of(r2o_dims);
int64_t new_r3i_value_size = this->value_size_of(r3o_dims);
int64_t new_r4i_value_size = this->value_size_of(r4o_dims);
dynamic_r1i_value_handler.resize(new_r1i_value_size);
dynamic_r2i_value_handler.resize(new_r2i_value_size);
dynamic_r3i_value_handler.resize(new_r3i_value_size);
dynamic_r4i_value_handler.resize(new_r4i_value_size);
float* new_r1i_value_ptr = r1o.GetTensorMutableData<float>();
float* new_r2i_value_ptr = r2o.GetTensorMutableData<float>();
float* new_r3i_value_ptr = r3o.GetTensorMutableData<float>();
float* new_r4i_value_ptr = r4o.GetTensorMutableData<float>();
std::memcpy(dynamic_r1i_value_handler.data(),
new_r1i_value_ptr, new_r1i_value_size * sizeof(float));
std::memcpy(dynamic_r2i_value_handler.data(),
new_r2i_value_ptr, new_r2i_value_size * sizeof(float));
std::memcpy(dynamic_r3i_value_handler.data(),
new_r3i_value_ptr, new_r3i_value_size * sizeof(float));
std::memcpy(dynamic_r4i_value_handler.data(),
new_r4i_value_ptr, new_r4i_value_size * sizeof(float));
context_is_update = true;
}
void RobustVideoMatting::detect(const Mat& mat, MattingContent& content, float downsample_ratio)
{
if (mat.empty()) return;
dynamic_dsr_value_handler.at(0) = downsample_ratio;
std::vector<Ort::Value> input_tensors = this->transform(mat);
auto output_tensors = session_->Run(
Ort::RunOptions{ nullptr }, input_node_names.data(),
input_tensors.data(), num_inputs, output_node_names.data(),
num_outputs
);
this->generate_matting(output_tensors, content);
context_is_update = false;
this->update_context(output_tensors);
}
2.对图像中的人像进行抠图:
void detect_image(const cv::Mat& cv_src, string model_path)
{
const float downsample_ratio = 0.2;
RobustVideoMatting rvm(model_path);
MattingContent content;
rvm.detect(cv_src, content, downsample_ratio);
namedWindow("src", 0);
imshow("src", cv_src);
namedWindow("matting", 0);
imshow("matting", content.pha_mat * 255.);
namedWindow("merge", 0);
imshow("merge", content.merge_mat);
waitKey(0);
}
执行效果:


3.对视频进行人像抠图
void detect_video(const std::string video_path, string model_path)
{
const float downsample_ratio = 0.25;
RobustVideoMatting rvm(model_path);
cv::VideoCapture video_capture(video_path);
const unsigned int width = video_capture.get(cv::CAP_PROP_FRAME_WIDTH);
const unsigned int height = video_capture.get(cv::CAP_PROP_FRAME_HEIGHT);
const unsigned int frame_count = video_capture.get(cv::CAP_PROP_FRAME_COUNT);
if (!video_capture.isOpened())
{
return;
}
cv::Mat cv_src;
while (video_capture.read(cv_src))
{
MattingContent content;
rvm.detect(cv_src, content, downsample_ratio);
namedWindow("src", 0);
imshow("src", cv_src);
namedWindow("matting", WINDOW_NORMAL);
imshow("matting", content.pha_mat);
namedWindow("merge", WINDOW_NORMAL);
imshow("merge", content.merge_mat);
waitKey(10);
}
}
执行效果:




1.源码地址:https://download.csdn.net/download/matt45m/86821062
2.下载源码后解压,使用vs2019打开,images和video是测试的图像和视频,lib里面有使用到的依赖库,include依赖的头文件。

3.配置include和lib路径
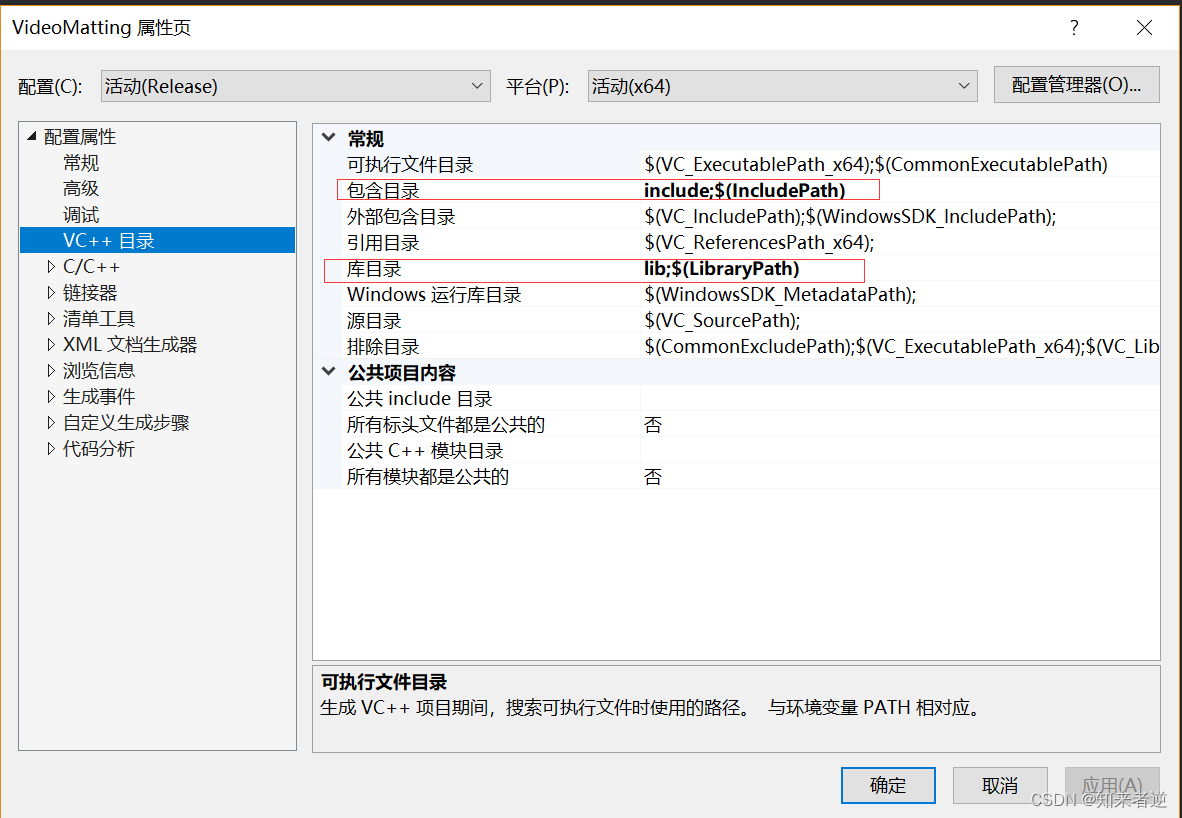
4.添加lib,把lib目录下所有.lib后缀的添加到依赖项。
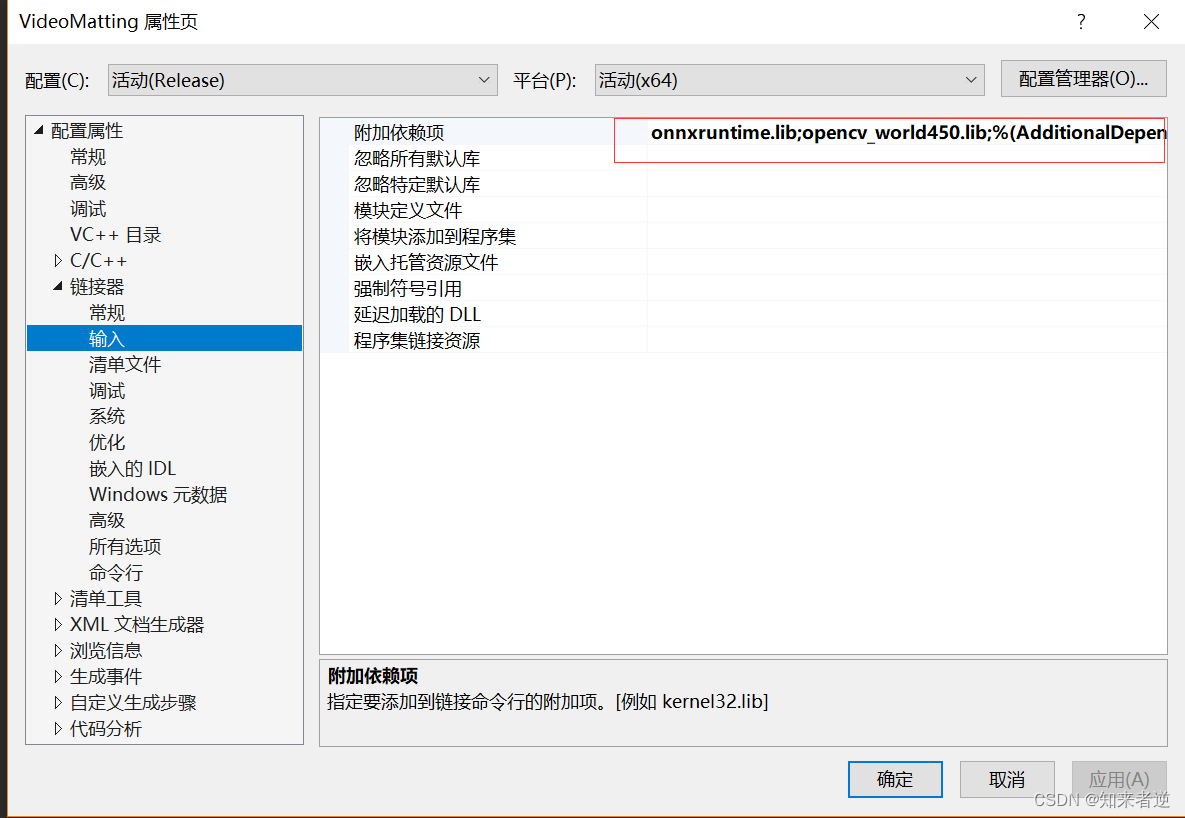
5.运行配置
所以我在关注Railscast,我注意到在html.erb文件中,ruby代码有一个微弱的背景高亮效果,以区别于其他代码HTML文档。我知道Ryan使用TextMate。我正在使用SublimeText3。我怎样才能达到同样的效果?谢谢! 最佳答案 为SublimeText安装ERB包。假设您安装了SublimeText包管理器*,只需点击cmd+shift+P即可获得命令菜单,然后键入installpackage并选择PackageControl:InstallPackage获取包管理器菜单。在该菜单中,键入ERB并在看到包时选择
我有一张背景图片,我想在其中添加一个文本框。我想弄清楚如何将标题放置在其顶部的正确位置。(我使用标题是因为我需要自动换行功能)。现在,我只能让文本显示在左上角,但我需要能够手动定位它的开始位置。require'RMagick'require'Pry'includeMagicktext="Loremipsumdolorsitamet"img=ImageList.new('template001.jpg')img 最佳答案 这是使用convert的ImageMagick命令行的答案。如果你想在Rmagick中使用这个方法,你必须自己移植
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
动漫制作技巧是很多新人想了解的问题,今天小编就来解答与大家分享一下动漫制作流程,为了帮助有兴趣的同学理解,大多数人会选择动漫培训机构,那么今天小编就带大家来看看动漫制作要掌握哪些技巧?一、动漫作品首先完成草图设计和原型制作。设计草图要有目的、有对象、有步骤、要形象、要简单、符合实际。设计图要一致性,以保证制作的顺利进行。二、原型制作是根据设计图纸和制作材料,可以是手绘也可以是3d软件创建。在此步骤中,要注意的问题是色彩和平面布局。三、动漫制作制作完成后,加工成型。完成不同的表现形式后,就要对设计稿进行加工处理,使加工的难易度降低,并得到一些基本准确的概念,以便于后续的大样、准确的尺寸制定。四、
2022/8/4更新支持加入水印水印必须包含透明图像,并且水印图像大小要等于原图像的大小pythonconvert_image_to_video.py-f30-mwatermark.pngim_dirout.mkv2022/6/21更新让命令行参数更加易用新的命令行使用方法pythonconvert_image_to_video.py-f30im_dirout.mkvFFMPEG命令行转换一组JPG图像到视频时,是将这组图像视为MJPG流。我需要转换一组PNG图像到视频,FFMPEG就不认了。pyav内置了ffmpeg库,不需要系统带有ffmpeg工具因此我使用ffmpeg的python包装p