文章目录
本文使用的YOLOv5版本为v6.1,对YOLOv5-6.x网络结构还不熟悉的同学们,可以移步至:【YOLOv5-6.x】网络模型&源码解析
另外,本文所使用的实验环境为1个GTX 1080 GPU,数据集为VOC2007,超参数为hyp.scratch-low.yaml,训练200个epoch,其他参数均为源码中默认设置的数值。
YOLOv5中修改网络结构的一般步骤:
models/common.py:在common.py文件中,加入要修改的模块代码models/yolo.py:在yolo.py文件内的parse_model函数里添加新模块的名称models/new_model.yaml:在models文件夹下新建模块对应的.yaml文件
[Cite]Ma, Ningning, et al. “Shufflenet v2: Practical guidelines for efficient cnn architecture design.” Proceedings of the European conference on computer vision (ECCV). 2018.
旷视轻量化卷积神经网络Shufflenetv2,通过大量实验提出四条轻量化网络设计准则,对输入输出通道、分组卷积组数、网络碎片化程度、逐元素操作对不同硬件上的速度和内存访问量MAC(Memory Access Cost)的影响进行了详细分析:
针对以上四条准则,作者提出了Shufflenetv2模型,通过Channel Split替代分组卷积,满足四条设计准则,达到了速度和精度的最优权衡。

Shufflenetv2有两个结构:basic unit和unit from spatial down sampling(2×)
Shufflenetv2整体哲学要紧紧向论文中提出的轻量化四大准则靠拢,基本除了准则四之外,都有效的避免了。
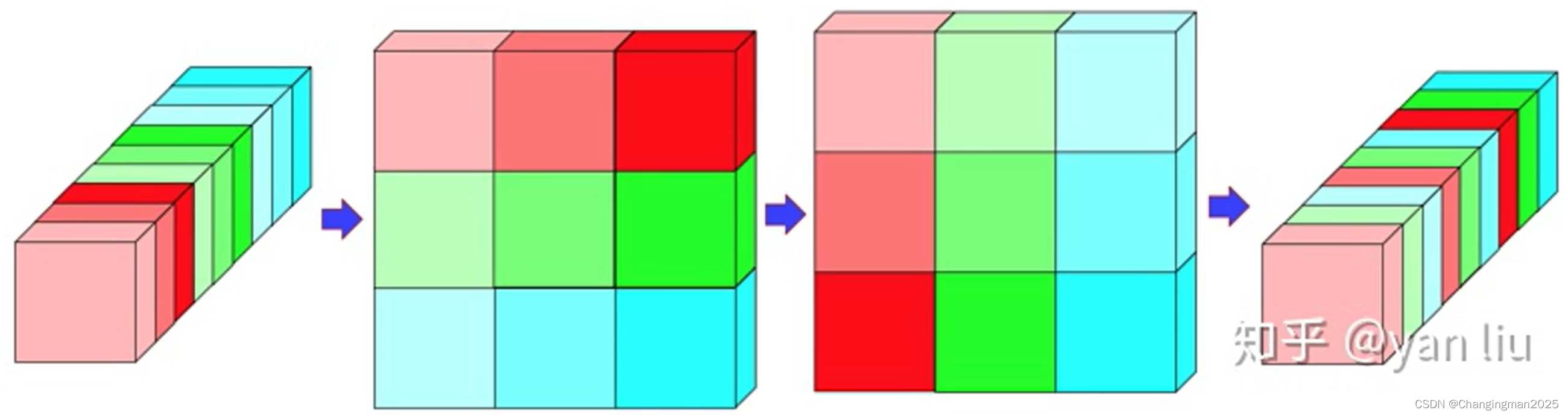
为了解决GConv(Group Convolution)导致的不同group之间没有信息交流,只在同一个group内进行特征提取的问题,Shufflenetv2设计了Channel Shuffle操作进行通道重排,跨group信息交流
class ShuffleBlock(nn.Module):
def __init__(self, groups=2):
super(ShuffleBlock, self).__init__()
self.groups = groups
def forward(self, x):
'''Channel shuffle: [N,C,H,W] -> [N,g,C/g,H,W] -> [N,C/g,g,H,W] -> [N,C,H,W]'''
N, C, H, W = x.size()
g = self.groups
return x.view(N, g, C//g, H, W).permute(0, 2, 1, 3, 4).reshape(N, C, H, W)
# ---------------------------- ShuffleBlock start -------------------------------
# 通道重排,跨group信息交流
def channel_shuffle(x, groups):
batchsize, num_channels, height, width = x.data.size()
channels_per_group = num_channels // groups
# reshape
x = x.view(batchsize, groups,
channels_per_group, height, width)
x = torch.transpose(x, 1, 2).contiguous()
# flatten
x = x.view(batchsize, -1, height, width)
return x
class conv_bn_relu_maxpool(nn.Module):
def __init__(self, c1, c2): # ch_in, ch_out
super(conv_bn_relu_maxpool, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(c1, c2, kernel_size=3, stride=2, padding=1, bias=False),
nn.BatchNorm2d(c2),
nn.ReLU(inplace=True),
)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
def forward(self, x):
return self.maxpool(self.conv(x))
class Shuffle_Block(nn.Module):
def __init__(self, inp, oup, stride):
super(Shuffle_Block, self).__init__()
if not (1 <= stride <= 3):
raise ValueError('illegal stride value')
self.stride = stride
branch_features = oup // 2
assert (self.stride != 1) or (inp == branch_features << 1)
if self.stride > 1:
self.branch1 = nn.Sequential(
self.depthwise_conv(inp, inp, kernel_size=3, stride=self.stride, padding=1),
nn.BatchNorm2d(inp),
nn.Conv2d(inp, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
)
self.branch2 = nn.Sequential(
nn.Conv2d(inp if (self.stride > 1) else branch_features,
branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
self.depthwise_conv(branch_features, branch_features, kernel_size=3, stride=self.stride, padding=1),
nn.BatchNorm2d(branch_features),
nn.Conv2d(branch_features, branch_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
)
@staticmethod
def depthwise_conv(i, o, kernel_size, stride=1, padding=0, bias=False):
return nn.Conv2d(i, o, kernel_size, stride, padding, bias=bias, groups=i)
def forward(self, x):
if self.stride == 1:
x1, x2 = x.chunk(2, dim=1) # 按照维度1进行split
out = torch.cat((x1, self.branch2(x2)), dim=1)
else:
out = torch.cat((self.branch1(x), self.branch2(x)), dim=1)
out = channel_shuffle(out, 2)
return out
# ---------------------------- ShuffleBlock end --------------------------------
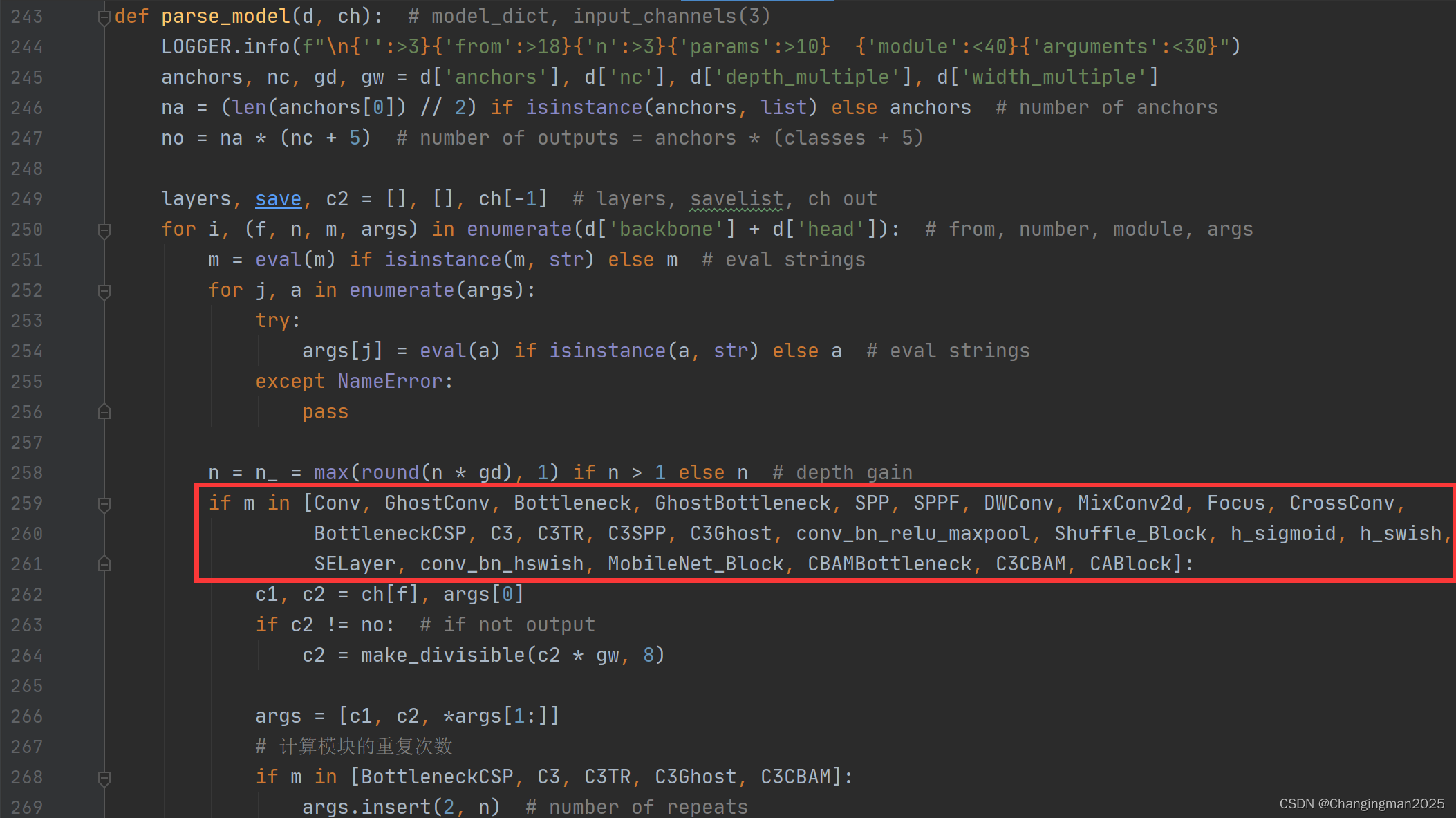
yolo.py文件修改:在yolo.py的parse_model函数中,加入conv_bn_relu_maxpool, Shuffle_Block两个模块(如下图红框所示)
新建yaml文件:在model文件下新建yolov5-shufflenetv2.yaml文件,复制以下代码即可
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 20 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
# Shuffle_Block: [out, stride]
[[ -1, 1, conv_bn_relu_maxpool, [ 32 ] ], # 0-P2/4
[ -1, 1, Shuffle_Block, [ 128, 2 ] ], # 1-P3/8
[ -1, 3, Shuffle_Block, [ 128, 1 ] ], # 2
[ -1, 1, Shuffle_Block, [ 256, 2 ] ], # 3-P4/16
[ -1, 7, Shuffle_Block, [ 256, 1 ] ], # 4
[ -1, 1, Shuffle_Block, [ 512, 2 ] ], # 5-P5/32
[ -1, 3, Shuffle_Block, [ 512, 1 ] ], # 6
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P4
[-1, 1, C3, [256, False]], # 10
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 2], 1, Concat, [1]], # cat backbone P3
[-1, 1, C3, [128, False]], # 14 (P3/8-small)
[-1, 1, Conv, [128, 3, 2]],
[[-1, 11], 1, Concat, [1]], # cat head P4
[-1, 1, C3, [256, False]], # 17 (P4/16-medium)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 7], 1, Concat, [1]], # cat head P5
[-1, 1, C3, [512, False]], # 20 (P5/32-large)
[[14, 17, 20], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
[Cite]Howard, Andrew, et al. “Searching for mobilenetv3.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019.
MobileNetV3,是谷歌在2019年3月21日提出的轻量化网络架构,在前两个版本的基础上,加入神经网络架构搜索(NAS)和h-swish激活函数,并引入SE通道注意力机制,性能和速度都表现优异,受到学术界和工业界的追捧。
主要特点:
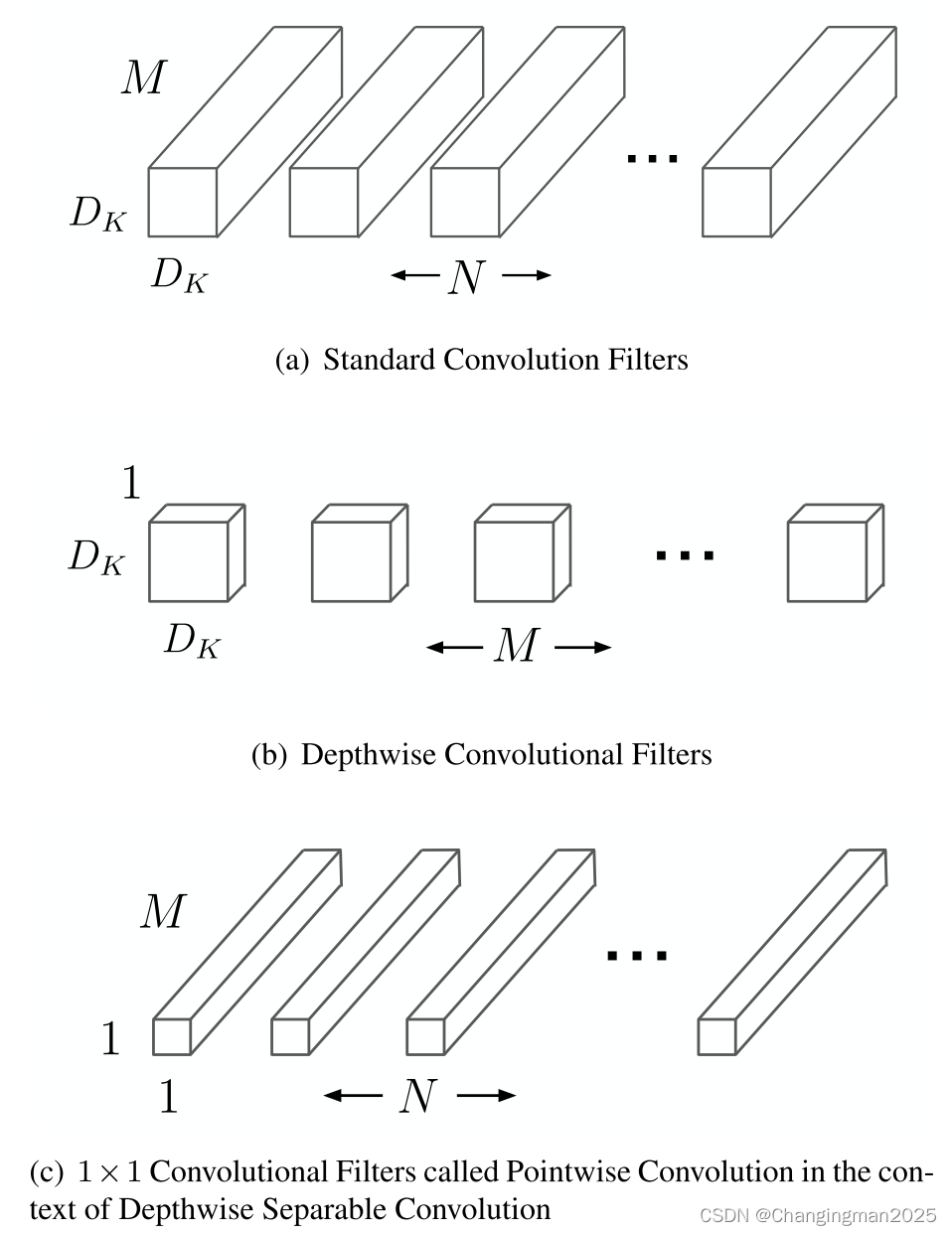
Mobilenetv1提出了深度可分离卷积,就是将普通卷积拆分成为一个深度卷积(Depthwise Convolutional Filters)和一个逐点卷积(Pointwise Convolution):

深度卷积本身没有改变通道的能力,来的是多少通道输出就是多少通道,如果来的通道很少的话,DW深度卷积只能在低维度上工作,这样效果并不会很好,所以我们要“扩张”通道。
既然我们已经知道PW逐点卷积也就是1×1卷积可以用来升维和降维,那就可以在DW深度卷积之前使用PW卷积进行升维(升维倍数为t,t=6),再在一个更高维的空间中进行卷积操作来提取特征,这样不管输入通道数是多少,经过第一个PW逐点卷积升维之后,深度卷积都是在相对的更高6倍维度上进行工作。
Inverted residuals:为了像Resnet一样复用特征,引入了shortcut结构,采用了 1×1 -> 3 ×3 -> 1 × 1 的模式,但是不同点是:
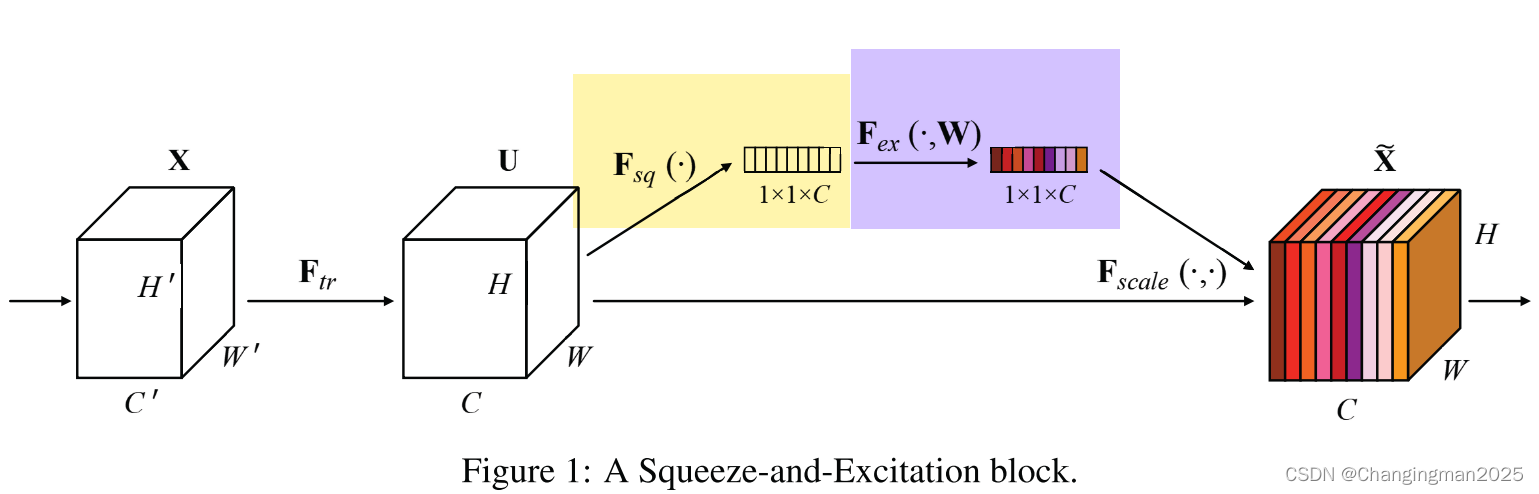
SE通道注意力出自论文:《Squeeze-and-excitation networks.》,主要是探讨了卷积神经网络中信息特征的构造问题,而作者提出了一种称为“Squeeze-Excitation(SE)”的组件:
class SELayer(nn.Module):
def __init__(self, channel, reduction=4):
super(SELayer, self).__init__()
# Squeeze操作
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# Excitation操作(FC+ReLU+FC+Sigmoid)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel),
h_sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x)
y = y.view(b, c)
y = self.fc(y).view(b, c, 1, 1) # 学习到的每一channel的权重
return x * y
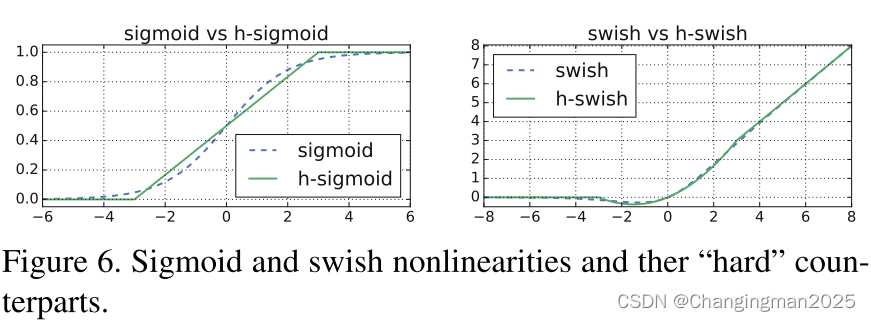
近似操作模拟swish和relu,公式如下:
h _ s w i s h ( x ) = x ∗ R e L U 6 ( x + 3 ) 6 h\_swish(x)=x*\frac{ReLU6(x+3)}{6} h_swish(x)=x∗6ReLU6(x+3)、 h _ s i g m o i d ( x ) = R e L U 6 ( x + 3 ) 6 h\_sigmoid(x)=\frac{ReLU6(x+3)}{6} h_sigmoid(x)=6ReLU6(x+3)
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
# ---------------------------- MobileBlock start -------------------------------
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class SELayer(nn.Module):
def __init__(self, channel, reduction=4):
super(SELayer, self).__init__()
# Squeeze操作
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# Excitation操作(FC+ReLU+FC+Sigmoid)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel),
h_sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x)
y = y.view(b, c)
y = self.fc(y).view(b, c, 1, 1) # 学习到的每一channel的权重
return x * y
class conv_bn_hswish(nn.Module):
"""
This equals to
def conv_3x3_bn(inp, oup, stride):
return nn.Sequential(
nn.Conv2d(inp, oup, 3, stride, 1, bias=False),
nn.BatchNorm2d(oup),
h_swish()
)
"""
def __init__(self, c1, c2, stride):
super(conv_bn_hswish, self).__init__()
self.conv = nn.Conv2d(c1, c2, 3, stride, 1, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = h_swish()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
class MobileNet_Block(nn.Module):
def __init__(self, inp, oup, hidden_dim, kernel_size, stride, use_se, use_hs):
super(MobileNet_Block, self).__init__()
assert stride in [1, 2]
self.identity = stride == 1 and inp == oup
# 输入通道数=扩张通道数 则不进行通道扩张
if inp == hidden_dim:
self.conv = nn.Sequential(
# dw
nn.Conv2d(hidden_dim, hidden_dim, kernel_size, stride, (kernel_size - 1) // 2, groups=hidden_dim,
bias=False),
nn.BatchNorm2d(hidden_dim),
h_swish() if use_hs else nn.ReLU(inplace=True),
# Squeeze-and-Excite
SELayer(hidden_dim) if use_se else nn.Sequential(),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
else:
# 否则 先进行通道扩张
self.conv = nn.Sequential(
# pw
nn.Conv2d(inp, hidden_dim, 1, 1, 0, bias=False),
nn.BatchNorm2d(hidden_dim),
h_swish() if use_hs else nn.ReLU(inplace=True),
# dw
nn.Conv2d(hidden_dim, hidden_dim, kernel_size, stride, (kernel_size - 1) // 2, groups=hidden_dim,
bias=False),
nn.BatchNorm2d(hidden_dim),
# Squeeze-and-Excite
SELayer(hidden_dim) if use_se else nn.Sequential(),
h_swish() if use_hs else nn.ReLU(inplace=True),
# pw-linear
nn.Conv2d(hidden_dim, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
def forward(self, x):
y = self.conv(x)
if self.identity:
return x + y
else:
return y
# ---------------------------- MobileBlock end ---------------------------------
yolo.py文件修改:在yolo.py的parse_model函数中,加入h_sigmoid, h_swish, SELayer, conv_bn_hswish, MobileNet_Block五个模块
新建yaml文件:在model文件下新建yolov5-mobilenetv3-small.yaml文件,复制以下代码即可
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# Parameters
nc: 20 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# MobileNetV3-small 11层
# [from, number, module, args]
# MobileNet_Block: [out_ch, hidden_ch, kernel_size, stride, use_se, use_hs]
# hidden_ch表示在Inverted residuals中的扩张通道数
# use_se 表示是否使用 SELayer, use_hs 表示使用 h_swish 还是 ReLU
[[-1, 1, conv_bn_hswish, [16, 2]], # 0-p1/2
[-1, 1, MobileNet_Block, [16, 16, 3, 2, 1, 0]], # 1-p2/4
[-1, 1, MobileNet_Block, [24, 72, 3, 2, 0, 0]], # 2-p3/8
[-1, 1, MobileNet_Block, [24, 88, 3, 1, 0, 0]], # 3-p3/8
[-1, 1, MobileNet_Block, [40, 96, 5, 2, 1, 1]], # 4-p4/16
[-1, 1, MobileNet_Block, [40, 240, 5, 1, 1, 1]], # 5-p4/16
[-1, 1, MobileNet_Block, [40, 240, 5, 1, 1, 1]], # 6-p4/16
[-1, 1, MobileNet_Block, [48, 120, 5, 1, 1, 1]], # 7-p4/16
[-1, 1, MobileNet_Block, [48, 144, 5, 1, 1, 1]], # 8-p4/16
[-1, 1, MobileNet_Block, [96, 288, 5, 2, 1, 1]], # 9-p5/32
[-1, 1, MobileNet_Block, [96, 576, 5, 1, 1, 1]], # 10-p5/32
[-1, 1, MobileNet_Block, [96, 576, 5, 1, 1, 1]], # 11-p5/32
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 8], 1, Concat, [1]], # cat backbone P4
[-1, 1, C3, [256, False]], # 15
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 3], 1, Concat, [1]], # cat backbone P3
[-1, 1, C3, [128, False]], # 19 (P3/8-small)
[-1, 1, Conv, [128, 3, 2]],
[[-1, 16], 1, Concat, [1]], # cat head P4
[-1, 1, C3, [256, False]], # 22 (P4/16-medium)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 12], 1, Concat, [1]], # cat head P5
[-1, 1, C3, [512, False]], # 25 (P5/32-large)
[[19, 22, 25], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
Han, Kai, et al. “Ghostnet: More features from cheap operations.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.
Ghostnet出自华为诺亚方舟实验室,作者发现在传统的深度学习网络中存在着大量冗余,但是对模型的精度至关重要的特征图。这些特征图是由卷积操作得到,又输入到下一个卷积层进行运算,这个过程包含大量的网络参数,消耗了大量的计算资源。
作者考虑到这些feature map层中的冗余信息可能是一个成功模型的重要组成部分,正是因为这些冗余信息才能保证输入数据的全面理解,所以作者在设计轻量化模型的时候并没有试图去除这些冗余feature map,而是尝试使用更低成本的计算量来获取这些冗余feature map。
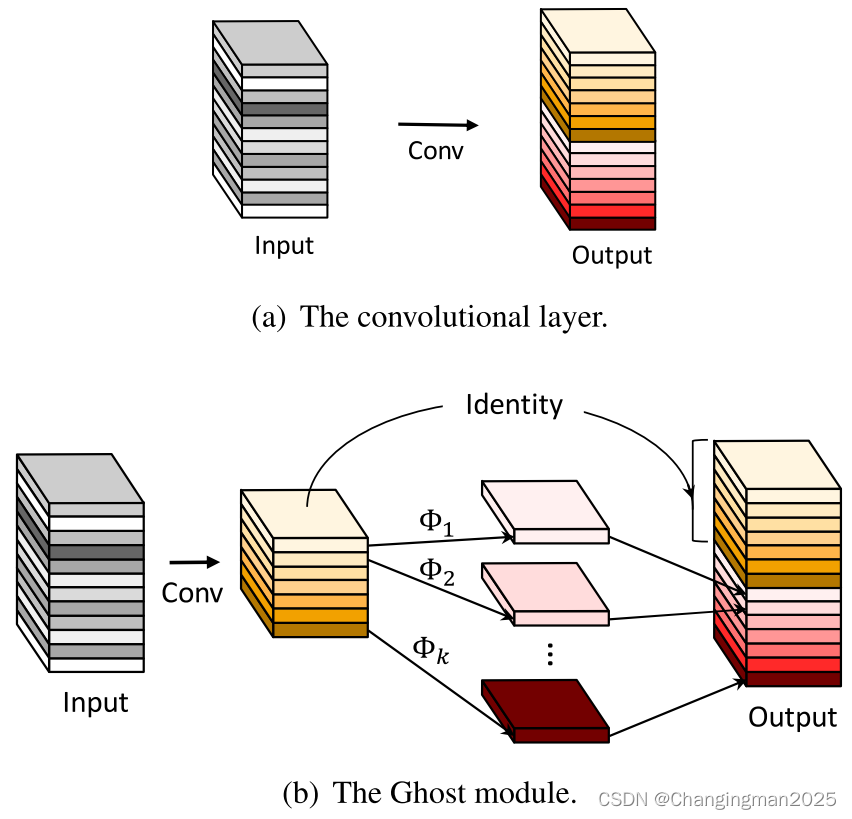
Ghost卷积部分将传统卷积操作分为两部分:
最终将第一部分作为一份恒等映射(Identity),与第二步的结果进行Concat操作
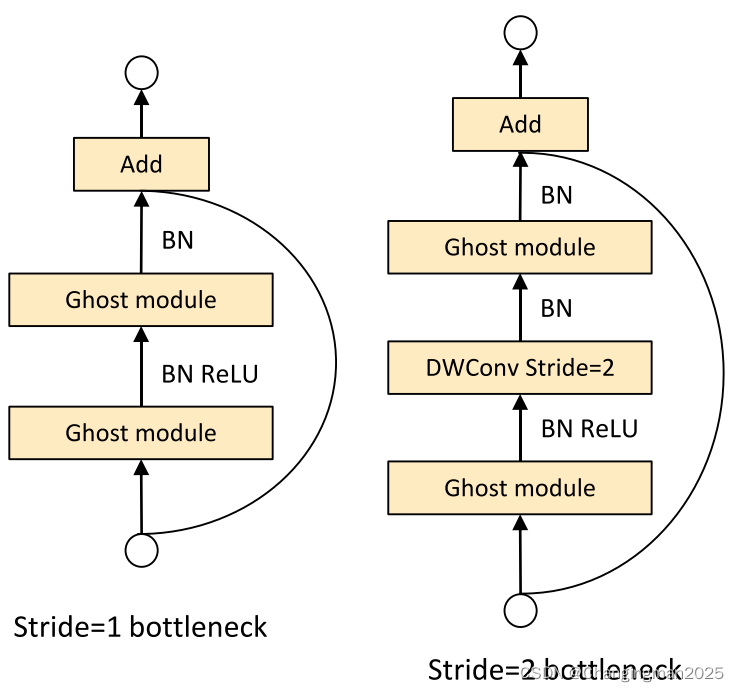
GhostBottleneck部分有两种结构:
在最新版本的YOLOv5-6.1源码中,作者已经加入了Ghost模块,并在models/hub/文件夹下,给出了yolov5s-ghost.yaml文件,因此直接使用即可。
class GhostConv(nn.Module):
# Ghost Convolution https://github.com/huawei-noah/ghostnet
def __init__(self, c1, c2, k=1, s=1, g=1, act=True): # ch_in, ch_out, kernel, stride, groups
super().__init__()
c_ = c2 // 2 # hidden channels
self.cv1 = Conv(c1, c_, k, s, None, g, act) # 先进行一半卷积 减少计算量
self.cv2 = Conv(c_, c_, 5, 1, None, c_, act) # 再进行逐特征图卷积
def forward(self, x):
y = self.cv1(x)
return torch.cat([y, self.cv2(y)], 1) # 最后将两部分进行concat
class GhostBottleneck(nn.Module):
# Ghost Bottleneck https://github.com/huawei-noah/ghostnet
def __init__(self, c1, c2, k=3, s=1): # ch_in, ch_out, kernel, stride
super().__init__()
c_ = c2 // 2
self.conv = nn.Sequential(GhostConv(c1, c_, 1, 1), # pw
# dw 当stride=2时 才开启
DWConv(c_, c_, k, s, act=False) if s == 2 else nn.Identity(),
GhostConv(c_, c2, 1, 1, act=False)) # pw-linear
self.shortcut = nn.Sequential(DWConv(c1, c1, k, s, act=False),
Conv(c1, c2, 1, 1, act=False)) if s == 2 else nn.Identity()
def forward(self, x):
return self.conv(x) + self.shortcut(x) # Add(Element-Wise操作)
class C3Ghost(C3):
# C3 module with GhostBottleneck()
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e) # 引入C3(父类)的属性
c_ = int(c2 * e) # hidden channels
self.m = nn.Sequential(*(GhostBottleneck(c_, c_) for _ in range(n)))
【精读AI论文】旷视轻量化网络ShuffleNet V2-算法精讲
轻量级神经网络“巡礼”(二)—— MobileNet,从V1到V3
我在开发的Rails3网站的一些搜索功能上遇到了一个小问题。我有一个简单的Post模型,如下所示:classPost我正在使用acts_as_taggable_on来更轻松地向我的帖子添加标签。当我有一个标记为“rails”的帖子并执行以下操作时,一切正常:@posts=Post.tagged_with("rails")问题是,我还想搜索帖子的标题。当我有一篇标题为“Helloworld”并标记为“rails”的帖子时,我希望能够通过搜索“hello”或“rails”来找到这篇帖子。因此,我希望标题列的LIKE语句与acts_as_taggable_on提供的tagged_with方法
我正在使用这个:4.times{|i|assert_not_equal("content#{i+2}".constantize,object.first_content)}我之前声明过局部变量content1content2content3content4content5我得到的错误NameError:wrongconstantnamecontent2这个错误是什么意思?我很确定我想要content2=\ 最佳答案 你必须用一个大字母来调用ruby常量:Content2而不是content2。Aconstantnamestart
很难说出这里要问什么。这个问题模棱两可、含糊不清、不完整、过于宽泛或夸夸其谈,无法以目前的形式得到合理的回答。如需帮助澄清此问题以便重新打开,visitthehelpcenter.关闭9年前。我需要从基于ruby的应用程序使用AmazonSimpleNotificationService,但不知道从哪里开始。您对从哪里开始有什么建议吗?
我有一个基本的Rails应用程序测试,其中包含一个用回形针处理的照片字段的用户模型。我创建了能够创建/编辑用户的View,并且照片上传工作正常。Editinguseruser_path(@user),:html=>{:method=>"put",:multipart=>true}do|f|%>|然后,我想将SWFUpload集成到我的应用程序中。我试着按照这个tutorial并运行testproject没有任何成功:浏览按钮不会打开文件对话框,并抛出错误#2176,这是关于selectFiles()方法的。首先,问题是Flashv.10与项目中包含的旧版本SWFUpload(2.1.0
我正在尝试使Authlogic和FacebookConnect(使用Facebook)发挥良好的作用,以便您可以通过正常注册方式或使用Facebookconnect创建帐户。我已经能够让连接以一种方式工作,但注销只会在facebook而不是我的网站上注销,我必须删除cookie才能使其正常工作。任何帮助都会很棒,谢谢! 最佳答案 这是我使用FacebookConnect扩展、authlogic和OpenID制作的示例应用程序。它仍然需要一些工作,但它确实起作用了。http://big-glow-mama.heroku.com/htt
关于yolov5训练时参数workers和batch-size的理解yolov5训练命令workers和batch-size参数的理解两个参数的调优总结yolov5训练命令python.\train.py--datamy.yaml--workers8--batch-size32--epochs100yolov5的训练很简单,下载好仓库,装好依赖后,只需自定义一下data目录中的yaml文件就可以了。这里我使用自定义的my.yaml文件,里面就是定义数据集位置和训练种类数和名字。workers和batch-size参数的理解一般训练主要需要调整的参数是这两个:workers指数据装载时cpu所使
我有一个单表继承设置,我有一个Controller(我觉得有多个Controller会重复)。但是,对于某些方法,我想调用模型的子类。我想我可以让浏览器发送一个参数,我会针对该参数编写一个case语句。像这样的东西:case@model[:type]when"A"@results=Subclass1.search(params[:term])when"B"@results=Subclass2.search(params[:term])...end或者,我了解到Ruby的所有技巧都可以用字符串创建模型。像这样的东西:@results=params[:model].constantize.
在我的Rails应用程序中,我收到来自brakeman的以下安全警告。使用模型属性调用的不安全反射方法常量化。这是我的代码正在执行的操作。chart_type=Chart.where(id:chart_id,).pluck(:type).firstbeginChartPresenter.new(chart_type.camelize.constantize.find(chart_id))rescueraise"Unabletofindthechartpresenter"end根据我的研究,我还没有找到任何具体的解决方案。我听说你可以创建一个白名单,但我不确定brakeman在寻找什么。
亚马逊的documentation提供有关如何使用DynamoDBLocal的Java、.NET和PHP示例。你如何用AWSRubySDK做同样的事情??我的猜测是你在初始化时传入了一些参数,但我不知道它们是什么。dynamo_db=AWS::DynamoDB.new(:access_key_id=>'...',:secret_access_key=>'...') 最佳答案 您使用的是SDK的v1还是v2?您需要找出答案;从上面的简短片段来看,它看起来像v2。为了以防万一,我已经包含了这两个答案。v1答案:AWS.config(us
文章目录1.价差套利原理1.1概述1.2以BTC为例2.投研分析3.veighna的价差交易回测引擎4.实盘交易1.价差套利原理1.1概述在数字货币交易市场,我们会发现大多数行情下,相同币种之间的不同交割合约会存在一定的价差,由于它们属于同一品种,本身价值不会有任何差别,而且涨跌趋势一致,相关性高。那么如果在它们价差低的时候买入,价差高的时候卖出,这样我们就可以赚取中间的这部分差价。不过在实际交易过程中,我们还需要考虑到交易滑点、手续费、极端行情下,价差走出趋势特征…1.2以BTC为例图一、不同合约的比特币行情图由上图可以看出比特币远月合约与永续合约之间存在一定的价差。图二、某一时刻比特币价差