原文:ColossalChat: An Open-Source Solution for Cloning ChatGPT With a Complete RLHF Pipeline
作者:Yang You,新加坡国立大学青年教授。他在加州大学伯克利分校获得计算机科学博士学位。


ColossalChat:一个用完整RLHF管道克隆ChatGPT的开源解决方案
像ChatGPT和GPT-4这样的大型AI模型和应用程序在全球范围内非常流行,为技术工业革命和AGI(人工通用智能)的发展奠定了基础。不仅科技巨头竞相发布新产品,学术界和工业界的许多人工智能专家也加入了相关的创业浪潮。生成式AI每天都在快速迭代,不断改进!
然而,OpenAI并没有将其模型开源,这让许多人对模型背后的技术细节感到好奇。
- 我们怎样才能紧跟潮流,参与到技术发展的浪潮中来呢?
- 我们如何降低构建和应用大型AI模型的高昂成本?
- 我们如何保护核心数据和IP不被第三方大模型api泄露?
作为当今领先的开源大型AI模型解决方案,Colossal-AI是第一个开源完整的RLHF管道,包括监督数据收集、监督微调、奖励模型训练和强化学习微调,基于LLaMA预训练模型,并共享最实用的开源项目ColossalChat,与原始的ChatGPT技术解决方案非常相似!
开源地址:https://github.com/hpcaitech/ColossalAI
它包括以下内容:
- 演示:交互式演示,在线试用,无需注册或等待列表。
- 训练代码:开源完整的RLHF训练代码,包括7B和13B模型。
- 数据集:开源的104K中英文双语数据集。
- 推理:对70亿个参数模型进行4位量化推理,只需要4GB GPU内存。
- 模型权重:在单个服务器上仅使用少量计算能力即可实现快速复制。
- 其他更大的模型、数据集和其他优化将迅速更新和添加。
价格实惠,功能强大
ColossalChat只需要不到100亿个参数就可以达到中英文双语熟练程度,在大型语言模型的基础上通过RLHF微调,达到与ChatGPT和GPT-3.5相当的效果。
例如,一个常识测验
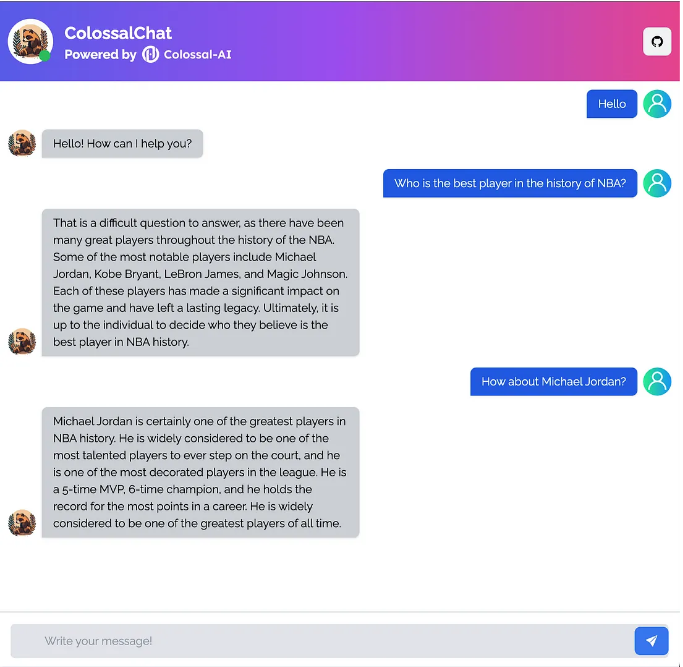
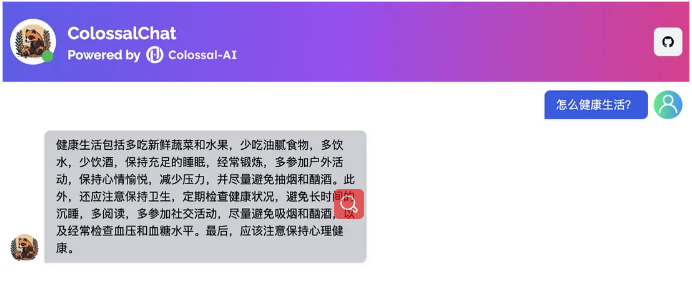
用中文回答
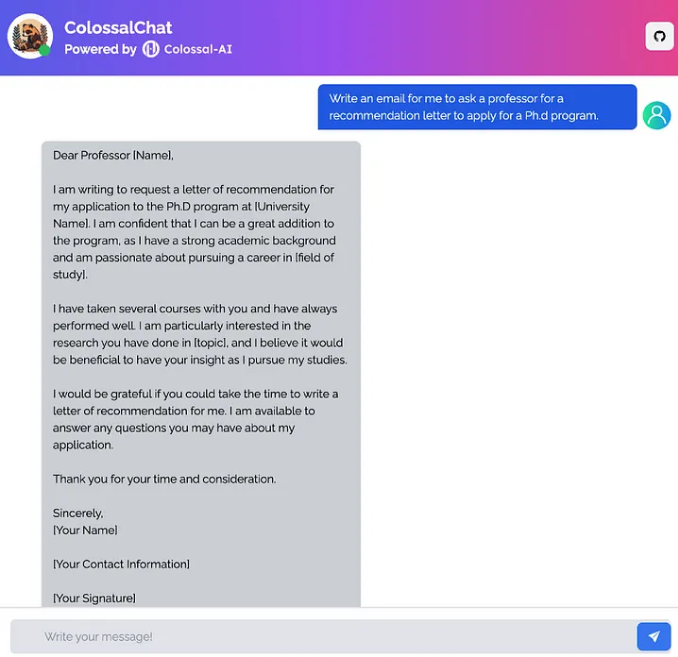
写一封电子邮件
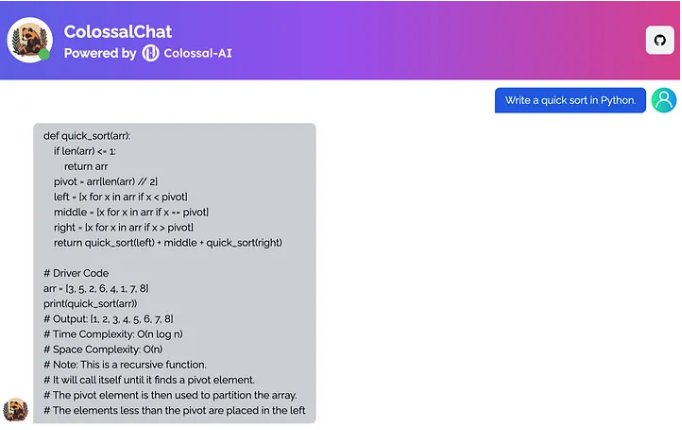
写一个算法
完整的ChatGPT克隆方案
尽管GPT系列中的模型(如ChatGPT和GPT-4)非常强大,但它们不太可能是完全开源的。幸运的是,开源社区一直在努力解决这个问题。
例如,Meta已经开源了LLaMA模型,它提供的参数大小从70亿到650亿不等。在大多数基准测试中,130亿个参数模型可以超过1750亿个GPT-3模型。但由于没有指令调优阶段,实际生成的结果并不理想。
斯坦福大学的羊驼通过调用OpenAI的API以自我指导的方式生成训练数据。这个轻量级模型只有70亿个参数,可以以很小的成本对其进行微调,从而实现与GPT-3.5这样有1750亿个参数的大型语言模型类似的会话性能。
然而,现有的开源解决方案只能被视为RLHF(从人类反馈中强化学习)第一阶段的监督微调模型,后续的校准和微调阶段没有执行。此外,Alpaca的训练数据集仅限于英语,这在一定程度上限制了模型的性能。
然而,ChatGPT和GPT-4令人印象深刻的效果是由于在训练过程中引入了RLHF,这增加了生成内容与人类价值观的一致性。
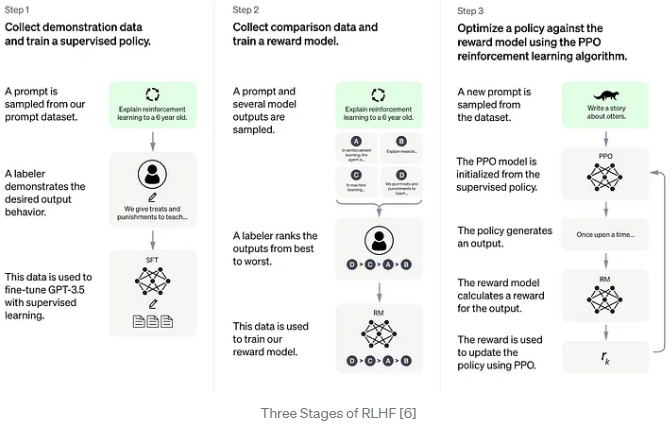
基于LLaMA模型,ColossalChat是第一个实用的开源项目,它包含了一个完整的RLHF过程,用于复制类似ChatGPT的模型,并且是最接近ChatGPT原始技术路线的项目!
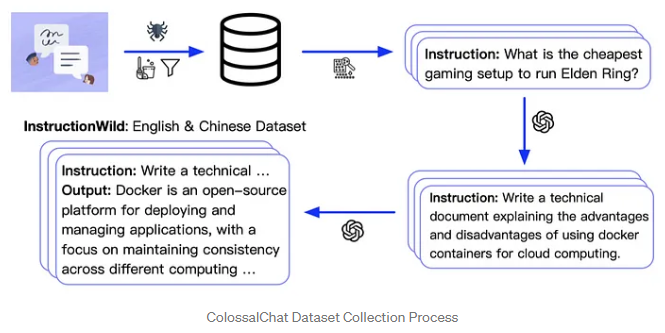
训练数据集开源
ColossalChat发布了一个由大约10万对中英文问答组成的双语数据集。数据集是从社交媒体平台上的现实问题场景中收集和清理的,作为种子数据集,并使用自我指导技术进行扩展,注释成本约为900美元。与其他自学方法生成的数据集相比,该数据集包含更真实和多样化的种子数据,并包含更广泛的主题。该数据集既适用于微调,也适用于RLHF训练。通过提供高质量的数据,ColossalChat可以实现更好的对话交互,并支持中文。
RLHF算法复制
RLHF算法复制包括三个阶段:
在RLHF- stage1中,使用前面提到的数据集执行监督指示微调来微调模型。
在RLHF-Stage2中,通过对同一提示的不同输出进行手动排序,训练奖励模型分配相应的分数,然后监督奖励模型的训练。
在RLHF-Stage3中,使用了强化学习算法,这是训练过程中最复杂的部分:
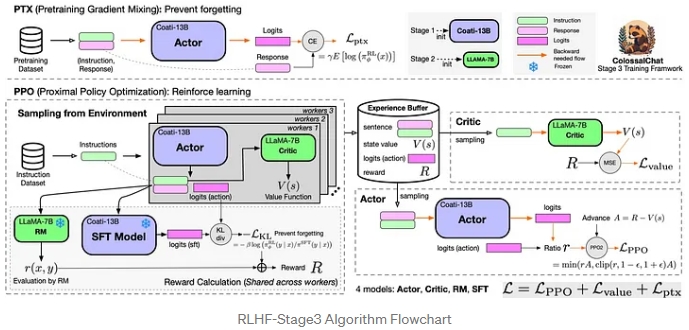
在PPO部分,ColossalChat遵循两个阶段的过程:首先,制造经验阶段,它使用SFT(有监督的微调)、参与者、RM(奖励模型)和批评模型来计算生成的经验并将其存储在缓冲区中。然后是参数更新阶段,使用经验计算策略损失和价值损失。
在PTX部分,ColossalChat计算Actor的输出响应和输入语料库的响应部分之间的交叉熵损失。这种损失被用来在PPO梯度中添加预训练梯度,以保持语言模型的原始性能并防止遗忘。最后,总结了策略损耗、值损耗和PTX损耗,用于反向传播和参数更新。
快速入门
ColossalChat已经以低成本开源了基于LLaMA模型的三个阶段复制ChatGPT的完整代码。
在阶段1中,训练SFT模型:
# Training with a 4-GPU servers
colossalai run — nproc_per_node=4 train_sft.py \
— pretrain “/path/to/LLaMa-7B/” \
— model ‘llama’ \
— strategy colossalai_zero2 \
— log_interval 10 \
— save_path /path/to/Coati-7B \
— dataset /path/to/data.json \
— batch_size 4 \
— accimulation_steps 8 \
— lr 2e-5
在阶段2中,RM训练:
# Training with a 4-GPU servers
colossalai run — nproc_per_node=4 train_reward_model.py \
— pretrain “/path/to/LLaMa-7B/” \
— model ‘llama’ \
— strategy colossalai_zero2 \
— dataset /path/to/datasets
第三阶段,RL算法训练:
# Training with a 8-GPU servers
colossalai run — nproc_per_node=8 train_prompts.py prompts.csv \
— strategy colossalai_zero2 \
— pretrain “/path/to/Coati-7B” \
— model ‘llama’ \
— pretrain_dataset /path/to/dataset
一旦获得了微调后的模型权重,就可以通过量化降低推理的硬件成本,启动在线推理服务,只需要一个大约4GB内存的GPU就可以部署70亿个参数的模型推理服务。
python server.py /path/to/pretrained — quant 4bit — gptq_checkpoint /path/to/coati-7b-4bit-128g.pt — gptq_group_size 128
系统性能优化与开发加速
ColossalChat能够快速跟踪ChatGPT复制的完整RLHF过程,这在很大程度上归功于colossalai基础设施和相关优化技术的底层支持。在相同条件下,与Alpaca使用的FSDP (Fully Sharded Data Parallel)相比,ColossalChat的训练速度可以提高两倍以上。
系统基础建设 Colossal-AI
AI大模型开发系统Colossal-AI为该项目提供了基础支撑。它可以高效、快速地部署基于PyTorch的AI大模型训练和推理,降低大型AI模型应用的成本。colossa - ai是基于加州大学伯克利分校特聘教授James Demmel教授和新加坡国立大学青年教授Yang You教授的专业知识开发的。自开源发布以来,Colossol-AI多次在GitHub Trending上排名第一,GitHub上约有2万颗星,并已成功被SC、AAAI、PPoPP、CVPR和ISC等国际AI和HPC顶级会议接受为官方教程。
Zero+Gemini 减少内存冗余
Colosal - Ai支持ZeRO(零冗余优化器)来提高内存使用效率,使更大的模型能够以更低的成本容纳,而不影响计算粒度和通信效率。自动块机制可以通过提高内存使用效率、降低通信频率和避免内存碎片来进一步提高ZeRO的性能。异构内存空间管理器Gemini支持将优化器状态从GPU内存卸载到CPU内存或硬盘空间,以克服GPU内存容量的限制,扩大可训练模型的规模,降低大型AI模型应用的成本。
LoRA的低成本微调
Colossa - AI包括低秩自适应(LoRA)方法,用于大型模型的低成本微调。LoRA方法假设大型语言模型是过度参数化的,并且在微调过程中参数的变化是一个低秩矩阵。因此,这个矩阵可以分解成两个更小的矩阵的乘积。在微调过程中,固定大模型的参数,只调整低秩矩阵的参数,大大减少了训练所需的参数数量,降低了成本。
低成本量化推理
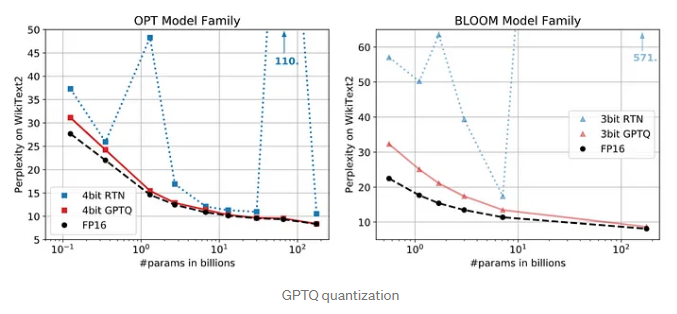
为了降低推理部署的成本,Colostal - AI使用了GPTQ 4位量化推理。在GPT/OPT/BLOOM模型上,它可以获得比传统RTN(四舍五入到最接近)量化技术更好的Perplexity结果。与普通的FP16推理相比,它可以减少75%的内存消耗,同时只牺牲了少量的吞吐量速度和Perplexity性能。
例如,对于使用4位量化推理的ColossalChat-7B, 70亿个参数模型只需要大约4GB的GPU内存来完成短序列(128个长度的生成)推断,这可以在RTX 3060等普通消费级GPU上完成,只需一行代码。
if args.quant == ‘4bit’:
model = load_quant(args.pretrained, args.gptq_checkpoint, 4, args.gptq_group_size)
如果使用高效的异步卸载技术,则可以进一步降低内存需求,从而可以在成本较低的硬件上推断出更大的模型。
限制
虽然RLHF被进一步引入,但由于计算能力和数据集有限,在某些场景下,实际性能仍有提升空间。
协作
幸运的是,与之前的大型AI模型和尖端技术被少数科技巨头垄断不同,PyTorch、hug Face和OpenAI等开源社区和创业公司也在这一波浪潮中发挥了关键作用。巨量ai借鉴开源社区的成功经验,欢迎各方共同参与建设,拥抱大模型时代!
- 您可以发布一个问题或提交一个拉请求(PR)。
- 加入colossa - ai微信或Slack群,与团队和其他用户交流。
- 请将正式提案发送至邮箱youy@comp.nus.edu.sg
致谢
ColossalChat非常感谢许多现有的作品和杰出的组织。不可思议的斯坦福羊驼项目一直是灵感的源泉。自我指导研究论文为小数据集的强大功能提供了基础。准确的训练后量化来自于GPTQ。感谢Meta AI Research发布了LLaMA模型,Meta的PyTorch和OpenAI为最强大的AI铺平了道路。
免责声明
与斯坦福羊驼相似,我们强调ColossalChat是对开源社区的贡献,仅用于学术研究目的,禁止任何商业用途:
- ColossalChat构建于LLaMA之上,授权仅用于非商业用途。
- 来自OpenAI的模型API的指令数据,以及这些数据的使用条款禁止开发竞争模型。
- 像其他大型语言模型一样,ColossalChat可能会表现出一些常见的缺陷,包括幻觉、毒性和偏见。
参考
[1] Wang, Yizhong, et al. “Self-Instruct: Aligning Language Model with Self Generated Instructions.” arXiv preprint arXiv:2212.10560 (2022).
[2] Touvron, Hugo, et al. “LLaMA: Open and efficient foundation language models.” arXiv preprint arXiv:2302.13971 (2023).
[3] Rohan, Taori, et al. “Stanford Alpaca: An Instruction-following LLaMA model.” arXiv preprint arXiv:2302.13971 (2023).
[4] Hu, Edward J., et al. “Lora: Low-rank adaptation of large language models.” arXiv preprint arXiv:2106.09685 (2021).
[5] Frantar, Elias, et al. “GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers.” arXiv preprint arXiv:2210.17323 (2022).
[6] OpenAI. 2022. ChatGPT. https://openai.com/blog/chatgpt
[7] Rajbhandari, Samyam, et al. “Zero: Memory optimizations toward training trillion parameter models.” SC20: International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 2020.
在MRIRuby中我可以这样做:deftransferinternal_server=self.init_serverpid=forkdointernal_server.runend#Maketheserverprocessrunindependently.Process.detach(pid)internal_client=self.init_client#Dootherstuffwithconnectingtointernal_server...internal_client.post('somedata')ensure#KillserverProcess.kill('KILL',
英文版英文链接关注公众号在“亚特兰蒂斯的回声”中踏上一段难忘的冒险之旅,深入未知的海洋深处。足智多谋的考古学家AriaSeaborne偶然发现了一件古代神器,揭示了一张通往失落之城亚特兰蒂斯的隐藏地图。在她神秘的导师内森·兰登教授的指导和勇敢的冒险家亚历克斯·默瑟的帮助下,阿丽亚开始了一段危险的旅程,以揭开这座传说中城市的真相。他们的冒险之旅带领他们穿越险恶的大海、神秘的岛屿和充满陷阱和谜语的致命迷宫。随着Aria潜在的魔法能力的觉醒,她被睿智勇敢的QueenNeria的幻象所指引,她让她为即将到来的挑战做好准备。三人组揭开亚特兰蒂斯令人惊叹的隐藏文明,并了解到邪恶的巫师马拉卡勋爵试图利用其古
?博客主页:https://xiaoy.blog.csdn.net?本文由呆呆敲代码的小Y原创,首发于CSDN??学习专栏推荐:Unity系统学习专栏?游戏制作专栏推荐:游戏制作?Unity实战100例专栏推荐:Unity实战100例教程?欢迎点赞?收藏⭐留言?如有错误敬请指正!?未来很长,值得我们全力奔赴更美好的生活✨------------------❤️分割线❤️-------------------------
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO
我最近开始从事一个项目,该项目使用git进行存储并使用ruby作为前端。我的脚本的第一个版本使用了ruby-git,虽然非常简单,但还不错。当我需要对我的提交和日志做更具体的工作时,建议我转向砂砾。然而,我在早期遇到了障碍——grit似乎无法克隆远程存储库。我发现使用Repository类的所有示例都创建了一个本地存储库并搜索了我发现Grit的clone方法未定义的源代码。给了什么?这是我的第一个StackOverflow问题,在此先感谢您的帮助。 最佳答案 由于Git结构良好,Grit使用缺少的方法(Grit::Git#m
我有一个应用程序正在从Ruby迁移到JRuby(由于需要通过Java提供更好的Web服务安全支持)。我使用的gem之一是daemons创建后台作业。问题在于它使用fork+exec来创建后台进程,但这对JRuby来说是禁忌。那么-是否有用于创建后台作业的替代gem/wrapper?我目前的想法是只从shell脚本调用rake并让rake任务永远运行......提前致谢,克里斯。更新我们目前正在使用几个与Java线程相关的包装器,即https://github.com/jmettraux/rufus-scheduler和https://github.com/philostler/acts
我刚刚看到whitehouse.gov正在使用drupal作为CMS和门户技术。drupal的优点之一似乎是很容易添加插件,而且编程最少,即重新发明轮子最少。这实际上正是Ruby-on-Rails的DRY理念。所以:drupal的缺点是什么?Rails或其他基于Ruby的技术有哪些不符合whitehouse.org(或其他CMS门户)门户技术的资格? 最佳答案 Whatarethedrawbacksofdrupal?对于Ruby和Rails,这确实是一个相当主观的问题。Drupal是一个可靠的内容管理选项,非常适合面向社区的站点。它
我的Ruby代码中有一个看起来有点像这样的结构Parameter=Struct.new(:name,:id,:default_value,:minimum,:maximum)稍后,我使用创建了这个结构的一个实例freq=Parameter.new('frequency',15,1000.0,20.0,20000.0)在某些时候,我需要这个结构的精确副本,所以我调用newFreq=freq.clone然后,我更改newFreq的名称newFreq.name.sub!('f','newF')奇迹般地,它也改变了freq.name!像newFreq.name='newFrequency'这样
当音乐碰上区块链技术,会擦出怎样的火花?或许周杰伦已经给了我们答案。8月29日下午,B站独家首发周杰伦限定珍藏Demo独家访谈VCR,周杰伦在VCR里分享了《晴天》《青花瓷》《搁浅》《爱在西元前》四首经典歌曲Demo背后的创作故事,并首次公布18年前未发布的神秘作品《纽约地铁》的Demo。在VCR中,方文山和杰威尔音乐提及到“多亏了区块链技术,现在我们可以将这些Demos,变成独一无二具有收藏价值的艺术品,这些Demos可以在薄盒(国内数藏平台)上听到。”如何将音乐与区块链技术相结合,薄盒方面称:“薄盒作为区块链技术服务方,打破传统对于区块链技术只能作为数字收藏的理解。聚焦于区块链技术赋能,在
2022年底,OpenAI的预训练模型ChatGPT给人工智能领域的爱好者和研究人员留下了深刻的印象和启发,他展现的惊人能力将人工智能的研究和应用热度推向高潮,网上也充斥着和ChatGPT的各种聊天,他可以作诗、写小说、写代码、讨论疫情问题等。下面就是一些他的神回复:人命关天的坑: 写歌,留给词作者的机会不多了。。。 回答人类怎么样面对人工智能: 什么是ChatGPT?借用网上的一段介绍,ChatGPT是由人工智能研究实验室OpenAI在2022年11月30日发布的全新聊天机器人模型,一款人工智能技术驱动的自然语言处理工具。它能够通过学习和理解人类的语言来进行对话,还能根据聊天的上下文进行互动