
目录
特点:
不可变集合:
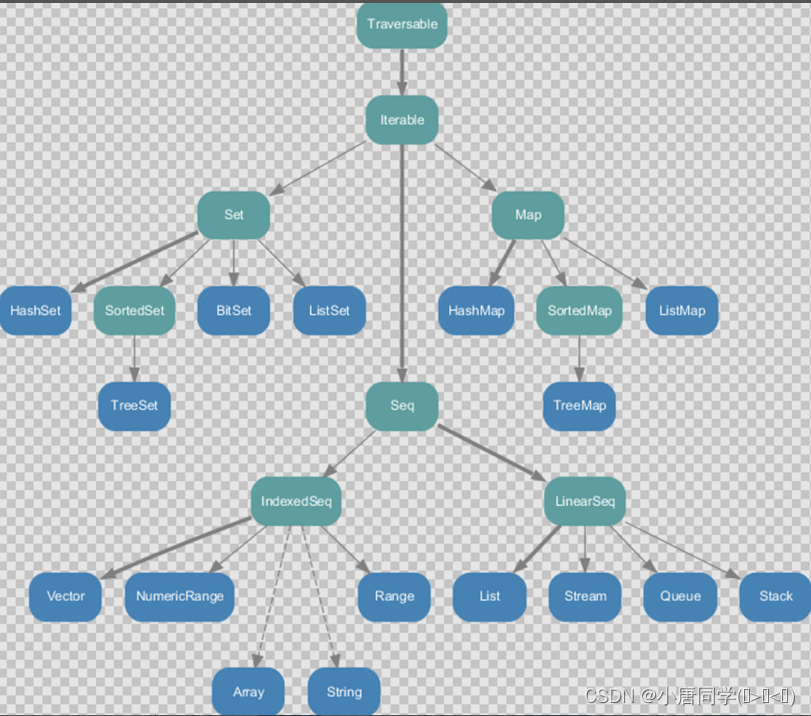
set集合特点:无序,不重复
对set集合无序的理解:set集合的无序是指在使用append等方法给集合添加元素的时候所添加的元素的顺序是不可预测的,并且不能按照添加顺序进行遍历(存储位置是不一定的)
Set集合的无序性是由它的实现方式所决定的。通常,Set集合的实现方式采用了哈希表这种数据结构,其中元素被散列到桶中,不同的元素可能被散列到同一个桶中,因此添加的顺序不能保证元素的顺序。
set集合提供了SortedSet集合是有序的(放入2,3,1,4会按照1,2,3,4进行存储)SortedSet写了一个TreeSet集合是树状存储
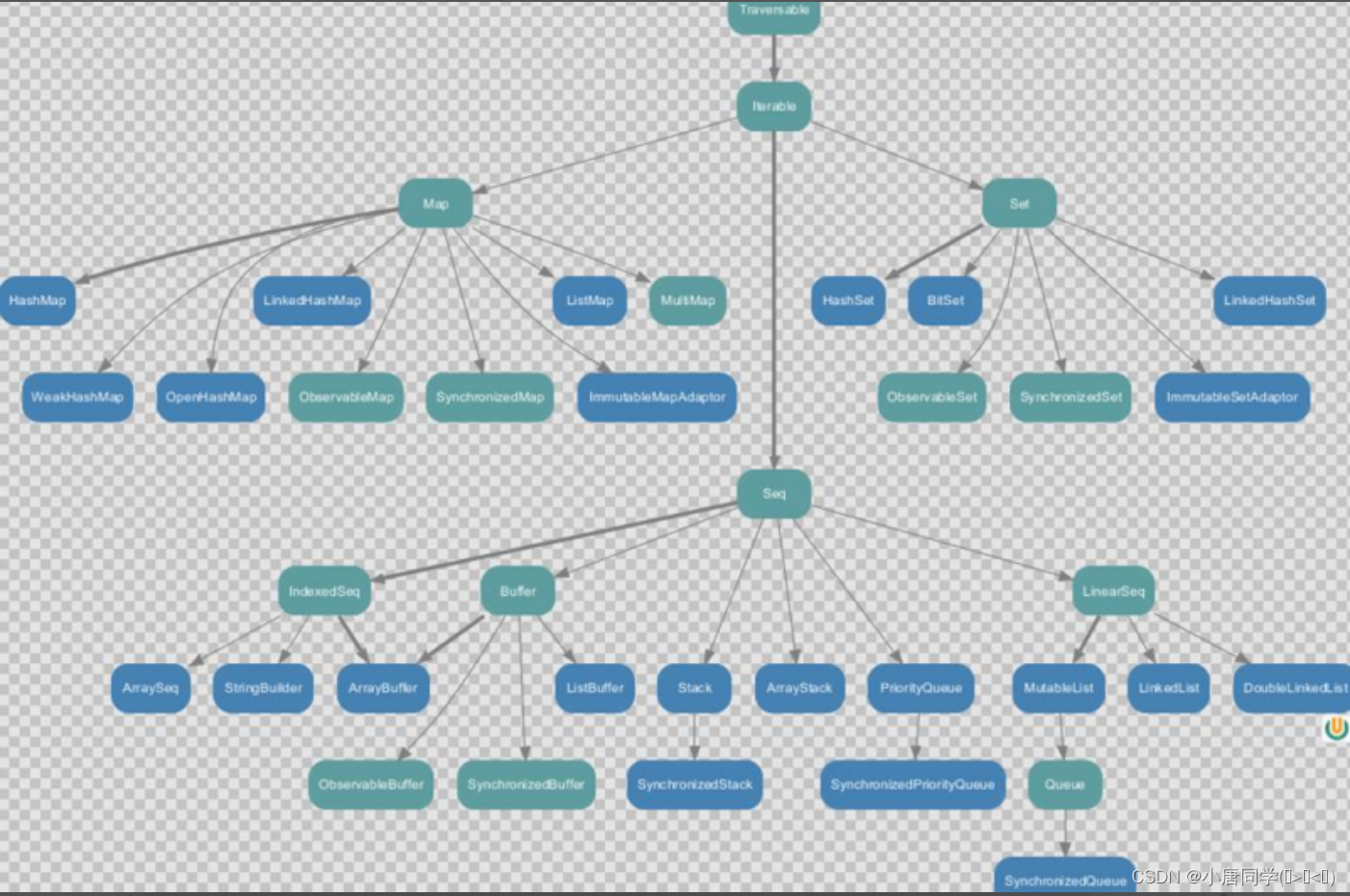
不可变集合是长度不可变
Scala中的array 是与 Java中的[]对应
package chapter05
object Test01_Array {
def main(args: Array[String]): Unit = {
val array = new Array[Int](4)
array(3)=100
//遍历
for (elem <- array) {
println(elem)
}
}
}在Scala中没有写方法名的都是调用了apply方法
上边样例代码已经使用
迭代器相当于是指针的跳转(指针在内存中的跳转)
样例代码:
package chapter05
object Test01_Array {
def main(args: Array[String]): Unit = {
val array = new Array[Int](4)
array(3)=100
val iterator: Iterator[Int] = array.iterator
while (iterator.hasNext)
{
val i: Int = iterator.next()
println(i)
}
}
}array集合可以通过to方法转换成List列表
在Scala中给所有的集合都提供了一个foreach()方法 进行函数式打印
foreach()源码:
def foreach[U](f: A => U): Unit = {
var i = 0
val len = length
while (i < len) { f(this(i)); i += 1 }
}源码分析:
foreach()传入的参数实际是传入的函数
A:是代表你传入集合的类型
U:是泛型,代表你的输出类型
这个函数的返回值是Unit类型
让后通过while进行向下运行
对foreach()函数的调用使用匿名函数进行调用
array.foreach(i=>println(i*2))
数组是默认的不可变的,如果需要可变是需要自己导包的
填入的初始化大小(数组的大小) 只决定了创建底层结构的长度(不填的话默认是16)
ArrayBuffer是可以进行添加元素的append()
可以进行增删改查
可变数组与不可变数组元素的增加区别:
可变的用方法不可变的用符号
代码样例:
可变数组的增删改查:
package chapter05
import scala.collection.mutable.ArrayBuffer
object Test_02_ArrayBuffer {
def main(args: Array[String]): Unit = {
//可变---导包
val arrayBuffer = new ArrayBuffer[Int](4)
arrayBuffer.append(1,2,3)
arrayBuffer.remove(1)
arrayBuffer.update(0,100)
println(arrayBuffer(0))
println(arrayBuffer)
}
}
不可变数组是不可变的,如果使用符号做出改变会生成一个新的对象
val array = new Array[Int](10)
val array1: Array[Int]= array :+ 8
println(array1.toList)使用to方法可以让可变与不可变数组进行相互转换
二维数组的定义与遍历:
val array2: Array[ Array[Int]] = Array(Array(1, 2, 3),Array(1, 2, 3),Array(1, 2, 3))
for (array3 <- array2) {
for (elem <- array3) {
print(elem+ "\t")
}
println()
}在Scala中创建多维数组的方法:
val array3: Array[Array[Int]] = Array.ofDim[Int](3, 4)
List是一个抽象类 在不继承的情况下是无法new的,所以需要使用伴生对象的apply方法
直接使用即可
val list = List(1, 2, 3, 4)
list.foreach(println)
val ints: List[Int] = list :+ 10
ints.foreach(println) val list1: List[Int] = 10 :: list
list1.foreach(println) val list2 = List(5, 6, 7, 8)
val ints1: List[Int] = list ::: list2
println(ints1)
println(ints1(5))
val ints2: List[Int] = 1 :: 2 :: 4 :: 5 :: Nil
val ints3: List[Int] = 3 :: 6 :: 7 :: 9 :: List()上述两行代码代表的是一个意思
val value: Any = Set(1, 1, 2,2,3, 4, 5, 6, 7, 8, 9)
println(value)运行结果:
判断set的类型:
val bool: Boolean = value.isInstanceOf[HashSet[Int]]
println(bool) val ints: mutable.Set[Int] = mutable.Set(1, 2, 2, 3, 1, 4, 5, 6, 8, 7, 9)
可变Set的增加是add方法,不是append方法
可变Set的集合也是符合不可重复,不可修改的特点
只可增删查
map集合也是一个特质,可以通过apply方法创建对象
map是一个(k,v)集合
(1)这是一种采用元组的方式创建的
val map = Map(("hello", 10), ("world", 20))
(2)这是采用的箭头的方式创建的
val map1 = Map("hello" -> 10, "world" -> 12)
常用第一种方式创建
(采用第一种方式创建的)
for循环得到的对象是元组
for (elem <- map) {
//elem是元组
val key: String = elem._1
val value: Int = elem._2
println(s"${key}:${value}")
}在Scala中value的类型为Int类型 在Java中是Int的包装类(防止在get方法找value不存在的时候为Null的情况)
上述情况也会在Scala中出现,Scala是对get方法使用Option(是一个抽象类,被两个子类实现(None,Some))封装
如果get的key存在 就调用上述的some类 再对结果进行调用get 转换成int类型 (方法很长,而且在没有值的情况下是会报错的)
因为太长引入了新的写法:
对map集合直接调用getOrElse(1)方法 设置1 有值输出值 无值输出1
val i: Int = map.getOrElse("hello", 1)
println(i)不存在就会返回None
可变map也是采用mutable.map进行创建
增删改查:
增加:
put方法 这个方法可以增加也可以进行修改 当key值存在的时候 如果value不同会覆盖前值
val maybeInt: Option[Int] = map.put("helloi2", 23)
删除:
val maybeInt1: Option[Int] = map.remove("hello")
查找:
查找与不可变一样使用getOrElse方法进行查找
本身为不可变 ,可以存放不同数据类型的元素
list具有上述的性质 但是使用list存放不同类型的数据 在调用的时候无法得到相应的类型(统一为Any)而tuple(元组可以)
val tuple: (String, Int) = ("hihihi", 23)
map中的(key value )元素被默认当作二元组
这样我们可以实现list集合与map集合的转换
val toList: List[(String, Int)] = map1.toList
println(toList)运行结果:

我有一个涉及多台机器、消息队列和事务的问题。因此,例如用户点击网页,点击将消息发送到另一台机器,该机器将付款添加到用户的帐户。每秒可能有数千次点击。事务的所有方面都应该是容错的。我以前从未遇到过这样的事情,但一些阅读表明这是一个众所周知的问题。所以我的问题。我假设安全的方法是使用两阶段提交,但协议(protocol)是阻塞的,所以我不会获得所需的性能,我是否正确?我通常写Ruby,但似乎Redis之类的数据库和Rescue、RabbitMQ等消息队列系统对我的帮助不大——即使我实现某种两阶段提交,如果Redis崩溃,数据也会丢失,因为它本质上只是内存。所有这些让我开始关注erlang和
//1.验证返回状态码是否是200pm.test("Statuscodeis200",function(){pm.response.to.have.status(200);});//2.验证返回body内是否含有某个值pm.test("Bodymatchesstring",function(){pm.expect(pm.response.text()).to.include("string_you_want_to_search");});//3.验证某个返回值是否是100pm.test("Yourtestname",function(){varjsonData=pm.response.json
我正在构建一个小部件来显示奥运会的奖牌数。我有一个“国家”对象的集合,其中每个对象都有一个“名称”属性,以及奖牌计数的“金”、“银”、“铜”。列表应该排序:1.首先是奖牌总数2.如果奖牌相同,按类型分割(金>银>铜,即2金>1金+1银)3.如果奖牌和类型相同,则按字母顺序子排序我正在用ruby做这件事,但我想语言并不重要。我确实找到了一个解决方案,但如果感觉必须有更优雅的方法来实现它。这是我做的:使用加权奖牌总数创建一个虚拟属性。因此,如果他们有2个金牌和1个银牌,加权总数将为“3.020100”。1金1银1铜为“3.010101”由于我们希望将奖牌数排序为最高的,因此列表按降序排
我有以下python函数来递归查找集合的所有分区:defpartitions(set_):ifnotset_:yield[]returnforiinxrange(2**len(set_)/2):parts=[set(),set()]foriteminset_:parts[i&1].add(item)i>>=1forbinpartitions(parts[1]):yield[parts[0]]+bforpinpartitions(["a","b","c","d"]):print(p)有人可以帮我把它翻译成ruby吗?这是我目前所拥有的:defpartitions(set)ifnots
我是ruby开发的新手,我目前正在使用rails2.3.11在ruby1.8.7中开发一个项目,我想知道这种语言是否有与C#的linq等效的集合操作,例如where子句。谢谢。 最佳答案 Ruby中Linq的where等价于find_all检查documentationfortheEnumerableModule用于其他功能。 关于C#的LINQ用于在ruby中等效的集合操作,我们在StackOverflow上找到一个类似的问题: https://
我正在使用reform-railsgem为了在我的Rails项目中使用表单对象。我意识到表单对象对于我在下面使用的示例代码来说可能有点矫枉过正,但它仅用于演示目的。在我创建一个用户的表单中,与该用户记录关联的是两个user_emails。#models/user.rbclassUser请注意,我没有在User模型中使用accepts_nested_attributes_for:user_emails。在我看来,表单对象的要点之一是它可以帮助您摆脱使用accepts_nested_attributes_for,所以这就是为什么我试图在没有它的情况下这样做。我从thisvideo得到了这个
问题localhost:3000/users/不会显示我谦虚地进入,因为我是第一次尝试通过Rails教程。我在第10章,我已经花了5个小时解决这个问题。当我尝试访问localhost:3000/users/时出现错误(我相信这与factory_girl有关)解释了@users变量为空并且我忘记了为will_paginate传递一个集合对象。我目前在第10章第10.23节,每次运行时:$bundleexecrakedb:reset$bundleexecrakedb:populate$bundleexecrakedb:test:prepare我在解释时遇到错误rakeaborted!Fac
我正在为Mechanize而苦苦挣扎。我希望“单击”一组只能通过其位置(div#content中的所有链接)或其href来识别的链接。以上两种识别方法我都试过了,都没有成功。从文档中,我无法弄清楚如何根据链接在DOM中的位置而不是直接通过链接上的属性返回一组链接(用于单击)。其次,documentation建议你可以使用:href来匹配部分href,page=agent.get('http://foo.com/').links_with(:href=>"/something")但我让它返回链接的唯一方法是传递一个完全限定的URL,例如page=agent.get('http://foo
我有两个表与一个连接表连接-这只是伪代码:LibraryBookLibraryBooks我需要做的是,如果我有一个图书馆的id,我想获取该图书馆拥有的所有书籍所在的所有图书馆。因此,如果我有图书馆1,而图书馆1中有书A和B,而书A和B在图书馆1、2和3中,是否有优雅的(单行)方式在rails中执行此操作?我在想:l=Library.find(1)allLibraries=l.books.libraries但这似乎行不通。有什么建议吗? 最佳答案 l=Library.find(:all,:include=>:books)l.books
我想了解更多关于Rails路线的信息。成员和收藏#Exampleresourceroutewithoptions:resources:productsdomemberdoget'short'post'toggle'endcollectiondoget'sold'endend命名空间和作用域#Exampleresourceroutewithinanamespace:namespace:admindoresources:productsendscope:admindoresources:productsend约束,Redirect_to#Exampleresourceroutewithop