import os
系统模块用于对系统进行操作。
os模块的常用方法有数十种之多,本文中只选出最常用的几种,其余的还有权限操作、文件的删除创建等详细资料可以参考官方文档。
参数的数据类型是字符串格式,内容是系统指令。执行时,直接返回系统输出。
import os
os.system('ifconfig') # Linux系统shell命令
os.system('ipconfig') # Windows系统dos命令
在使用system执行系统命令的时候,发现在windows系统下执行命令时,中文字符发生了乱码!这是因为windows为减少占用,对中文系统使用GB格式编码,而python中默认使用的UTF-8编码,编码不兼容导致了乱码问题。
popen也可以执行系统指令,但是和system的工作方式不一样。
popen执行系统指令之后返回对象,通过内置方法read读出字符串,这个过程中read方法自动的将其它编码转换成为了UTF-8格式,所以popen相比system有更高的可读性和兼容性。
而在实际的使用过程中,发现popen不存在阻塞,即在执行一些长时间系统任务的时候,不会等待系统任务结束,python代码就会继续执行,在某些场景下会导致问题的出现。比如在我的一个场景中,要将一个文件夹中的文件删除,之后在重写一份文件,使用popen导致文件还没有删除,而代码继续执行使新文件已经写好,而这个时候popen又将我新写的文件删除,导致我的程序在后续出现bug。所以,如果没有可读性的要求,我建议优先使用system方法。
import os
obj = os.popen('ipconfig')
res = obj.read()
print(res)
获取指定文件夹中的所有文件(包括文件和文件夹),返回文件的名称,以列表的形式返回,默认情况为当前路径。
import os
# 默认为当前路径
files = os.listdir()
print(files)
# 相对和绝对路径都可以使用
files = os.listdir('C:')
print(files)
递归遍历指定目录,包括其所有的子目录,返回一个迭代器对象。迭代器每次返回一个元组,元组为三个元素:
| 主要参数 | 含义 |
|---|---|
| top | 指定目录; |
| topdown | 正序遍历还是倒序遍历,默认为True(正序); |
请看下例,目录结构如下:
C:\USERS\MSR\DESKTOP\TEST
│root.txt
├─1
│ ├─1.txt
│ └─111
│ └─11.txt
└─2
└─2.txt
import os
path = r'C:\Users\MSR\Desktop\test'
# 正序遍历
res = os.walk(path) # 返回迭代器
for i in res:
print(i)
r"""
('C:\\Users\\MSR\\Desktop\\test', ['1', '2'], ['root.txt'])
('C:\\Users\\MSR\\Desktop\\test\\1', ['111'], ['1.txt'])
('C:\\Users\\MSR\\Desktop\\test\\1\\111', [], ['11.txt'])
('C:\\Users\\MSR\\Desktop\\test\\2', [], ['2.txt'])
"""
# 倒序遍历(优先展示最深子目录)
res = os.walk(path, topdown=False)
for i in res:
print(i)
r"""
('C:\\Users\\MSR\\Desktop\\test\\1\\111', [], ['11.txt'])
('C:\\Users\\MSR\\Desktop\\test\\1', ['111'], ['1.txt'])
('C:\\Users\\MSR\\Desktop\\test\\2', [], ['2.txt'])
('C:\\Users\\MSR\\Desktop\\test', ['1', '2'], ['root.txt'])
"""
import os
# 获取当前的工作路径
dir_path = os.getcwd()
print(dir_path) # E:\0-project\python\test
# 获取当前文件的路径
file_path = __file__ # 使用内置属性__file__获取
print(file_path) # E:/0-project/python/test/test3.py
注意:getcwd()获取的使用当前工作路径,__file__是获取当前文件的路径。
对于这个注意事项,大家一定要铭记于心,因为我被人欺骗了,当然这应该算是pycharm的坑吧!
注意了,文件的所在路径和工作路径是不相同的,文件的所在路径就是在系统中的这个脚本文件实实在在的地址,如果这个文件在C:\下,那么在任何的情况下这个文件的所在路径都是C:\;而工作路径不同,如果我们在C:\下执行这个python文件,那么我们的工作路径就是C:\,如果我们是在D:\下执行,那么我们的工作路径就是D:\,这就是文件所在地址和工作地址的区别,但是在一般情况下,我们执行文件都是在文件的所在地址执行的,所以大部分的时候文件所在路径和当前工作路径都是相同的。
可我在最开始学习这个方法的时候,我的老师教我说getcwd()的作用是获取文件的所在路径,那么是什么让我一直以为getcwd()的作用是获取文件的所在路径呢?是老师教给我的……感觉这个老师很不靠谱?那么老师怎么没有发现其中的含义呢?我怎么又一直深信不疑呢?我觉得这个一定是要pycharm来背锅了!我们在学习的时候一般都是相信自己的实际操作的结果的,我们执行的结果是什么,反复那么几次,我们的印象就会加深!
然后今天2021年12月7日20:58:09我在给公司的项目写一个启动脚本,目的是为了避免使用繁琐的命令去启动关闭项目,那么我在写的时候为了能够在系统的任何一个地方都是可以使用这个脚本,所以将命令中的各种路径全部写为绝对路径,我们系统工程师对绝对路径是非常熟练的!但是在我写好使用的时候就发现程序根本就启动不起来,已启动就死掉了,我就开始找原因,后来我发现在程序的目录下启动就没有问题,在其它的地址启动就有问题,我就意识到这是路径的错误。当然我们是有日志的,我看日志说是配置文件相关的地方出现了错误,我一看,就很好奇,配置文件是在程序的目录中的,读取的时候使用相对路径来获取,但是却没有读到文件,但是我检查之后文件是存在的!那么这个问题就很明显了,工作路径出了问题。
但是我还疑惑,为什么会影响到相对路径吗?然后我就测试了getcwd,发现果然如此,getcwd返回的不是文件的所在地址而是当前所在的工作地址,这个时候我还不死心,因为当时老师说的不是这样,所以我以为是linux和windows的差异,所以我就咋爱windows中又测试了一遍,发现还是一样的。那么我就又疑惑了,怎么在pycharm中,工作路径始终都是文件的所在路径呢?然后我就发现原来pycharm中可以指定文件的工作路径,而且默认将当前的文件路径作为工作路径使用。
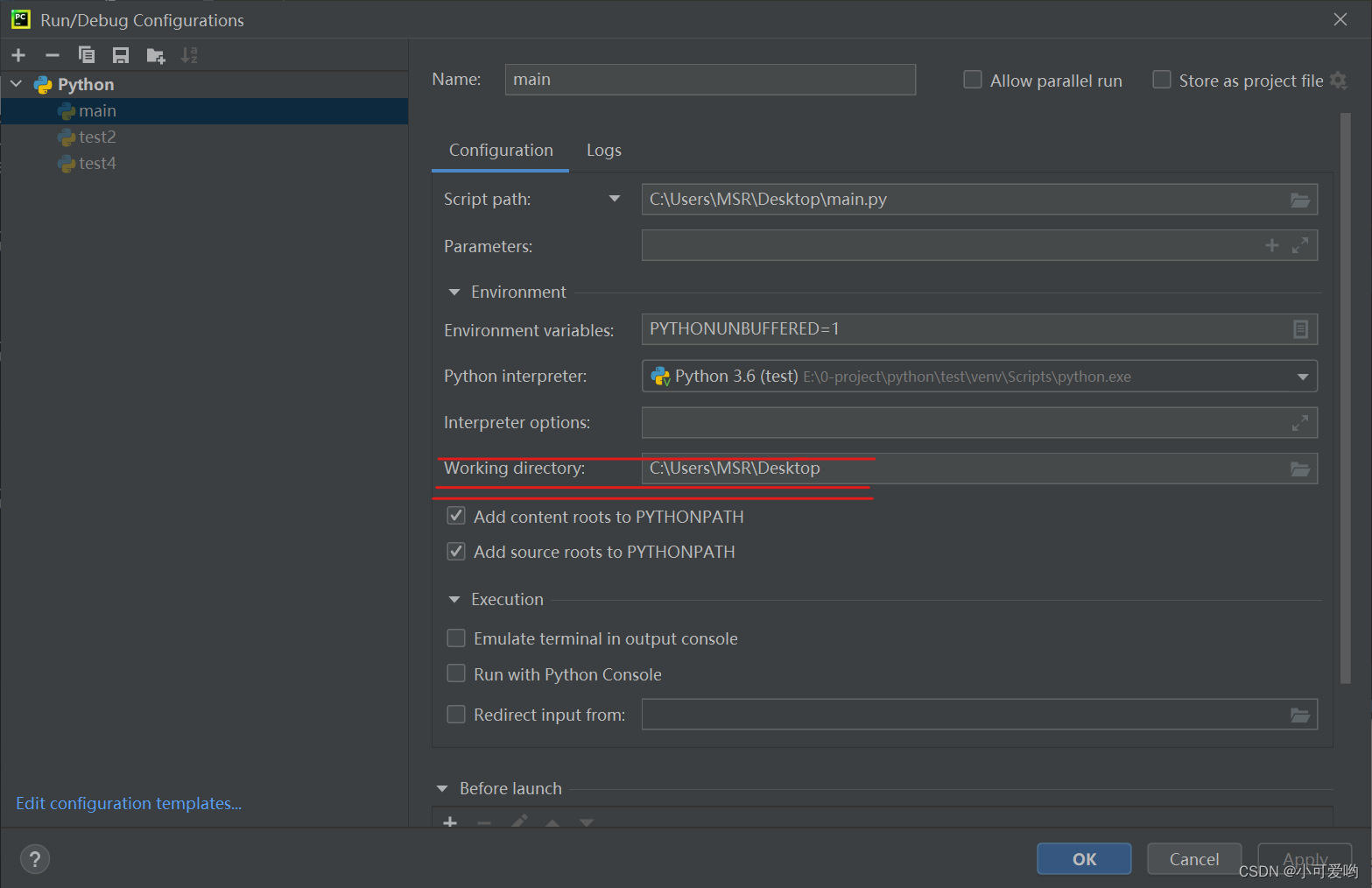
然后我看文档介绍:Return a unicode string representing the current working directory. ,emmm估计当时老师也是被pycharm坑了吧。所以大家以后如果想要在程序中固定工作路径,可以在启动文件中使用__file__获取,或者使用os.chdir方法。
然后最后还是在强调一下:工作路径会影响到相对路径的使用,但是不会影响到sys.pathpython的环境变量。
之前我们有学过很多的函数,他们在涉及到路径的时候,一般默认情况都是当前脚本文件所在的目录(比如刚才的listdir、getcwd),如果将文件的默认工作路径修改,就会影响到其它的一些功能,比如说我们导入文件使用相对路径等,所以,谨慎使用。
import os
# 在修改默认工作路径前使用
print(os.getcwd()) # E:\0-project\python\test
# chdir 修改当前文件工作的默认路径
os.chdir('C:')
# 在修改工作路径后使用
print(os.getcwd()) # C:\
用于测试一个指定路径或者文件的权限,返回True或者False。
语法:os.access(path, mode)
必要参数为path和mode,分别表示路径和测试的权限类型。
| mode | 说明 |
|---|---|
| os.F_OK | 是否存在; |
| os.R_OK | 是否可读; |
| os.W_OK | 是否可写; |
| os.X_OK | 是否可执行; |
返回包含适合加密使用的随机字节的bytes对象。
import os
# 参数为字节长度
key = os.urandom(1)
print(key, len(key))
# b'\x92' 1
key = os.urandom(5)
print(key, len(key))
# b'\xde\x05/lh' 5
getpid用于返回当前程序(脚本文件)的进程ID,getppid用于返回当前程序(脚本文件)的父进程ID。
# 获取进程唯一ID(PID)
import os
# getpid 返回当前进程的ID
print(os.getpid()) # 10784
# getppid 返回父进程的ID
# 如果父进程已退出,Windows计算机仍将运行返回其id;其他系统将返回“init”进程的id;
print(os.getppid()) # 16468
import os
print(os.cpu_count())
"""
结果:
8
"""
import os
# 获取系统的所有环境变量
ev_var = os.environ
print(ev_var)
# 获取系统指定的环境变量
path_ev_var = os.environ['PATH']
print(path_ev_var)
# 添加环境变量
os.environ['PATH'] += r':/home/msr' # Linux使用冒号分隔
os.environ['PATH'] += r';C:\Users\MSR' # Windows使用分号分隔
# 其实可以看到,环境变量其实就是一个特殊的字典,修改环境变量就是在操作一个字典数据而已
import os
# name 获取系统标识(Linux ->posix windows -> nt)
print(os.name) # nt
# sep 获取路径分隔符号
print(os.sep) # \
# linesep 获取系统的换行符号
print(repr(os.linesep)) # '\r\n'
windows系统不支持此方法。
import os
os.mknod('test.txt')
os.remove('test.txt')
import os
os.mkdir('test_dir')
os.rmdir('test_dir')
语法:rename(old_path, new_path)
import os
os.rename('test.txt', 'hahaha.txt')
import os
# 迭代创建文件夹
os.makedirs('a/b/c/d/e')
# 迭代删除文件夹(文件夹中存在文件,则该文件夹不删除)
os.removedirs('a/b/c/d/e')
import os.path
路径模块也是系统模块中的一部分。
import os.path
# 该路径不一定真实存在
file_path = r'..\学习笔记\day1笔记.py'
file_name = os.path.basename(file_path)
print(file_name) # day1笔记.py
import os.path
file_path = r'..\学习笔记\day1笔记.py'
dir_path = os.path.dirname(file_path)
print(dir_path) # ..\学习笔记
import os.path
file_path = r'..\学习笔记\day1笔记.py'
tuple_var = os.path.split(file_path)
print(tuple_var) # ('..\\学习笔记', 'day1笔记.py')
print(type(tuple_var)) # 返回元组: <class 'tuple'>
import os.path
path1 = 'abc'
path2 = '123'
path3 = 'main.py'
# 使用join组合
path = os.path.join(path1, path2, path3)
print(path) # abc\123\main.py
# 也可以使用 os.sep
path = path1 + os.sep + path2 + os.sep + path3
print(path) # abc\123\main.py
import os.path
# 分开文件名
file_name = 'main.py'
res = os.path.splitext(file_name)
print(res) # ('main', '.py')
print(type(res)) # <class 'tuple'>
# 分来完整路径
file_path = r'..\学习笔记\day1笔记.py'
res = os.path.splitext(file_path)
print(res) # ('..\\学习笔记\\day1笔记', '.py')
print(type(res)) # <class 'tuple'>
# 也可以使用字符串内置方法 split 实现
res = file_path.split('.')
print(res) # ['', '', '\\学习笔记\\day1笔记', 'py']
print(type(res)) # <class 'list'>
import os.path
# 获取指定文件的大小(单位:byte)
file_size_byte = os.path.getsize('test.txt')
获取文件的创建时间,返回时间戳。(windows有明确的创建时间,linux只有最后一次的修改时间。)
import os.path
import time
# 获取文件创建时间
stamp_time = os.path.getctime('./test.py')
print(stamp_time) # 1613989768.3445127
# 配合 时间模块使用 获取时间
print(time.ctime(stamp_time)) # Mon Feb 22 18:29:28 2021
import os.path
import time
# 获取文件最后一次修改时间
stamp_time = os.path.getmtime('./test.py')
print(stamp_time) # 1614037683.1067748
# 配合 时间模块使用 获取时间
print(time.ctime(stamp_time)) # Tue Feb 23 07:48:03 2021
import os.path
import time
# 获取文件最后一次访问时间
stamp_time = os.path.getatime('./test.py')
print(stamp_time) # 1635590737.799415
# 配合 时间模块使用 获取时间
print(time.ctime(stamp_time)) # Sat Oct 30 18:45:37 2021
不检查路径是否真实存在。
import os.path
# 检查路径类型,返回布尔值:
# 不是对应类型或没有相应文件 : False
# 是对应类型:True
# isdir 检查路径是否是文件夹
res = os.path.isdir('test.txt')
# isfile 检查路径是否是文件
res = os.path.isfile('test.txt')
# islink 检查路径是否是链接
res = os.path.islink('test.txt')
不检查路径是否真实存在
import os.path
# 检查windows路径
path = r'E:\小黄片'
res = os.path.isabs(path)
print(res) # True
# windows系统检查Linux路径
path = r'/root/home'
res = os.path.isabs(path)
print(res) # True
先检查一个路径是否是相对路径,是则将其转成绝对路径,反之不变。
转成绝对路径的规则是:以当前的工作路径为基准,根据相对路径中的相对级别,将对应级别的工作路径替换为原路径中的相对路径。
不检查路径是否真实存在。
import os.path
# 绝对路径不改变
path = r'E:\学习资料'
new_path = os.path.abspath(path)
print(new_path) # E:\学习资料
# 相对路径转成绝对路径
path = r'..\学习资料'
new_path = os.path.abspath(path)
print(new_path) # E:\0-project\python\学习资料
# 根据级别自动转换
path = r'..\..\学习资料'
new_path = os.path.abspath(path)
print(new_path) # E:\0-project\学习资料
# 如果相对的级别过多,就以根目录为准(不会报错)
path = r'..\..\..\..\..\..\..\..\..\..\学习资料'
new_path = os.path.abspath(path)
print(new_path) # E:\学习资料
检查路径是否真实存在,返回布尔值。
import os.path
# 检查指定路径是否存在
path = r'E:\小黄片'
res = os.path.exists(path)
print(res) # False
import shutil
用于对文件进行操作。
获取文件信息,获取文件信息,见系统模块。
只复制文件的内容,通过文件IO操作,将一个文件的对象复制到另一个文件对象当中,因为需要在文件IO对象中操作,所以不推荐使用。
语法:copyfileobj(fsrc, fdst, length=16*1024)
copyfileobj(被复制文件对象,新文件对象,一次性读取字符数量。)
import shutil
with open('test.txt', 'r', encoding='UTF-8') as fp1 :
with open('test2.txt', 'w', encoding='UTF-8') as fp2 :
shutil.copyfileobj(fp1, fp2)
底层调用copyfileobj,使用方便快捷,所以推荐使用。
语法:copyfile(被复制文件路径, 新文件路径)
import shutil
shutil.copyfile('test.txt', 'test2.txt')
仅复制文件的权限,不复制文件的内容(被赋值权限的文件必须存在),语法和copyfile相同。
import shutil
shutil.copymode('test.txt', 'test.txt')
复制文件的所有的状态信息,包括各种日期、权限……就是没有内容。
import shutil
shutil.copystat('test.txt', 'test.txt')
import shutil
# 复制文件内容和权限
shutil.copy('test.txt', 'test.txt')
# 完整复制整个文件(包括状态、权限、内容……)
shutil.copy2('test.txt', 'test.txt')
import shutil
shutil.copytree('../学习笔记', '../学习笔记备份')
import shutil
shutil.rmtree('..\小黄片')
import shutil
shutil.move('D:\学习资料', 'C:\我的心血')
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
大约一年前,我决定确保每个包含非唯一文本的Flash通知都将从模块中的方法中获取文本。我这样做的最初原因是为了避免一遍又一遍地输入相同的字符串。如果我想更改措辞,我可以在一个地方轻松完成,而且一遍又一遍地重复同一件事而出现拼写错误的可能性也会降低。我最终得到的是这样的:moduleMessagesdefformat_error_messages(errors)errors.map{|attribute,message|"Error:#{attribute.to_s.titleize}#{message}."}enddeferror_message_could_not_find(obje
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚