https://dev.mysql.com/doc/refman/8.0/en/innodb-parameters.html
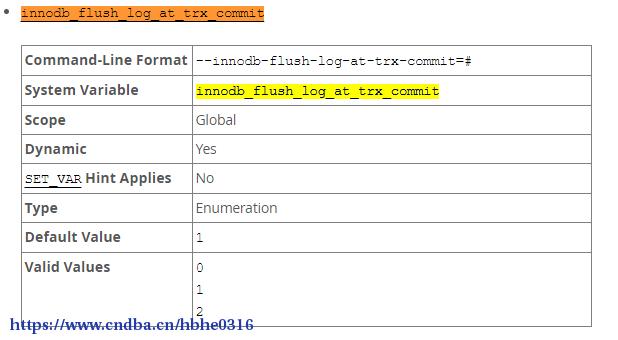
1、innodb_flush_log_at_trx_commit
innodb_flush_log_at_trx_commit:是 InnoDB 引擎特有的,ib_logfile的刷新方式( ib_logfile:记录的是redo log和undo log的信息)https://www.cndba.cn/hbhe0316/article/22631https://www.cndba.cn/hbhe0316/article/22631
取值:0/1/2
innodb_flush_log_at_trx_commit=0,表示每隔一秒把log buffer刷到文件系统中(os buffer)去,并且调用文件系统的“flush”操作将缓存刷新到磁盘上去。也就是说一秒之前的日志都保存在日志缓冲区,也就是内存上,如果机器宕掉,可能丢失1秒的事务数据。https://www.cndba.cn/hbhe0316/article/22631
innodb_flush_log_at_trx_commit=1,表示在每次事务提交的时候,都把log buffer刷到文件系统中(os buffer)去,并且调用文件系统的“flush”操作将缓存刷新到磁盘上去。这样的话,数据库对IO的要求就非常高了,如果底层的硬件提供的IOPS比较差,那么MySQL数据库的并发很快就会由于硬件IO的问题而无法提升。https://www.cndba.cn/hbhe0316/article/22631
innodb_flush_log_at_trx_commit=2,表示在每次事务提交的时候会把log buffer刷到文件系统中去,但并不会立即刷写到磁盘。如果只是MySQL数据库挂掉了,由于文件系统没有问题,那么对应的事务数据并没有丢失。只有在数据库所在的主机操作系统损坏或者突然掉电的情况下,数据库的事务数据可能丢失1秒之类的事务数据。这样的好处,减少了事务数据丢失的概率,而对底层硬件的IO要求也没有那么高(log buffer写到文件系统中,一般只是从log buffer的内存转移的文件系统的内存缓存中,对底层IO没有压力)。https://www.cndba.cn/hbhe0316/article/22631https://www.cndba.cn/hbhe0316/article/22631
控制提交操作的严格ACID遵从性和在重新安排和批量执行与提交相关的I/O操作时可能实现的更高性能之间的平衡。您可以通过更改默认值来获得更好的性能,但这样可能会在崩溃时丢失事务。
为了完全符合ACID,需要将默认设置设置为1。在每次事务提交时将日志写入并刷新到磁盘。
如果设置为0,则每秒将日志写入磁盘并将其刷新一次。未刷新日志的事务可能会在崩溃中丢失。
如果设置为2,则在每次事务提交后写入日志,并每秒将日志刷新到磁盘一次。未刷新日志的事务可能会在崩溃中丢失。
对于设置0和2,不能100%保证每秒刷新一次。刷新可能由于DDL更改和其他InnoDB内部活动而更频繁地发生,这些活动导致日志被独立于innodb_flush_log_at_trx_commit设置而刷新,有时由于调度问题而不那么频繁地刷新。如果每秒钟刷新一次日志,那么在崩溃中可能会丢失一秒以内的事务。如果日志刷新的频率高于或低于每秒一次,那么可能丢失的事务数量也会相应变化。
日志刷新频率由innodb_flush_log_at_timeout控制,它允许您将日志刷新频率设置为N秒(其中N为1…2700,默认值为1)。然而,任何意外的mysqld进程退出都可能删除最多N秒的事务。
DDL变化和其他InnoDB内部活动会独立于innodb_flush_log_at_trx_commit设置刷新日志。
InnoDB崩溃恢复工作与innodb_flush_log_at_trx_commit设置无关。事务要么被完全应用,要么被完全删除。
在使用InnoDB和事务的复制设置中,为了持久性和一致性:
如果启用了二进制日志,设置sync_binlog=1。
总是设置innodb_flush_log_at_trx_comm=1https://www.cndba.cn/hbhe0316/article/22631https://www.cndba.cn/hbhe0316/article/22631
mysql> SHOW VARIABLES LIKE 'innodb_flush_log_at_trx_commit';
+--------------------------------+-------+
| Variable_name | Value |
+--------------------------------+-------+
| innodb_flush_log_at_trx_commit | 1 |
+--------------------------------+-------+
1 row in set (0.00 sec)
[root@mysql57 logs]# cat /etc/my.cnf | grep -i innodb-flush-log-at-trx-commit
innodb-flush-log-at-trx-commit = 1
[root@mysql57 logs]# service mysqld restart
Shutting down MySQL.... SUCCESS!
Starting MySQL.. SUCCESS!版权声明:本文为博主原创文章,未经博主允许不得转载。
MYSQL
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
exe应该在我打开页面时运行。异步进程需要运行。有什么方法可以在ruby中使用两个参数异步运行exe吗?我已经尝试过ruby命令-system()、exec()但它正在等待过程完成。我需要用参数启动exe,无需等待进程完成是否有任何rubygems会支持我的问题? 最佳答案 您可以使用Process.spawn和Process.wait2:pid=Process.spawn'your.exe','--option'#Later...pid,status=Process.wait2pid您的程序将作为解释器的子进程执行。除
我有一些Ruby代码,如下所示:Something.createdo|x|x.foo=barend我想编写一个测试,它使用double代替block参数x,这样我就可以调用:x_double.should_receive(:foo).with("whatever").这可能吗? 最佳答案 specify'something'dox=doublex.should_receive(:foo=).with("whatever")Something.should_receive(:create).and_yield(x)#callthere
从给定URL下载文件并立即将其上传到AmazonS3的更直接的方法是什么(+将有关文件的一些信息保存到数据库中,例如名称、大小等)?现在,我既不使用Paperclip,也不使用Carrierwave。谢谢 最佳答案 简单明了:require'open-uri'require's3'amazon=S3::Service.new(access_key_id:'KEY',secret_access_key:'KEY')bucket=amazon.buckets.find('image_storage')url='http://www.ex
我正在为一个项目制作一个简单的shell,我希望像在Bash中一样解析参数字符串。foobar"helloworld"fooz应该变成:["foo","bar","helloworld","fooz"]等等。到目前为止,我一直在使用CSV::parse_line,将列分隔符设置为""和.compact输出。问题是我现在必须选择是要支持单引号还是双引号。CSV不支持超过一个分隔符。Python有一个名为shlex的模块:>>>shlex.split("Test'helloworld'foo")['Test','helloworld','foo']>>>shlex.split('Test"
我不确定传递给方法的对象的类型是否正确。我可能会将一个字符串传递给一个只能处理整数的函数。某种运行时保证怎么样?我看不到比以下更好的选择:defsomeFixNumMangler(input)raise"wrongtype:integerrequired"unlessinput.class==FixNumother_stuffend有更好的选择吗? 最佳答案 使用Kernel#Integer在使用之前转换输入的方法。当无法以任何合理的方式将输入转换为整数时,它将引发ArgumentError。defmy_method(number)
两者都可以defsetup(options={})options.reverse_merge:size=>25,:velocity=>10end和defsetup(options={}){:size=>25,:velocity=>10}.merge(options)end在方法的参数中分配默认值。问题是:哪个更好?您更愿意使用哪一个?在性能、代码可读性或其他方面有什么不同吗?编辑:我无意中添加了bang(!)...并不是要询问nobang方法与bang方法之间的区别 最佳答案 我倾向于使用reverse_merge方法:option
我有一个只接受一个参数的方法:defmy_method(number)end如果使用number调用方法,我该如何引发错误??通常,我如何定义方法参数的条件?比如我想在调用的时候报错:my_method(1) 最佳答案 您可以添加guard在函数的开头,如果参数无效则引发异常。例如:defmy_method(number)failArgumentError,"Inputshouldbegreaterthanorequalto2"ifnumbereputse.messageend#=>Inputshouldbegreaterthano
我没有找到太多关于如何执行此操作的信息,尽管有很多关于如何使用像这样的redirect_to将参数传递给重定向的建议:action=>'something',:controller=>'something'在我的应用程序中,我在路由文件中有以下内容match'profile'=>'User#show'我的表演Action是这样的defshow@user=User.find(params[:user])@title=@user.first_nameend重定向发生在同一个用户Controller中,就像这样defregister@title="Registration"@user=Use
对于作为String#tr参数的单引号字符串文字中反斜杠的转义状态,我觉得有些神秘。你能解释一下下面三个例子之间的对比吗?我特别不明白第二个。为了避免复杂化,我在这里使用了'd',在双引号中转义时不会改变含义("\d"="d")。'\\'.tr('\\','x')#=>"x"'\\'.tr('\\d','x')#=>"\\"'\\'.tr('\\\d','x')#=>"x" 最佳答案 在tr中转义tr的第一个参数非常类似于正则表达式中的括号字符分组。您可以在表达式的开头使用^来否定匹配(替换任何不匹配的内容)并使用例如a-f来匹配一