在我们的hadoop集群运行一段过程中,由于多种原因,数据在DataNade的磁盘之间的分布可能是不均匀。比如: 我们刚刚给某个DataNode新增加了一块磁盘或者集群上存在大批量的write & deltete操作等灯。那么有没有一种工具,能够使单个DataNode中的多个磁盘的数据均衡呢?借助Hadoop提供的Diskbalancer命令行工具可以实现。
hdfs balancer:是为了集群中DataNode的数据均衡,即针对多个DataNode的。
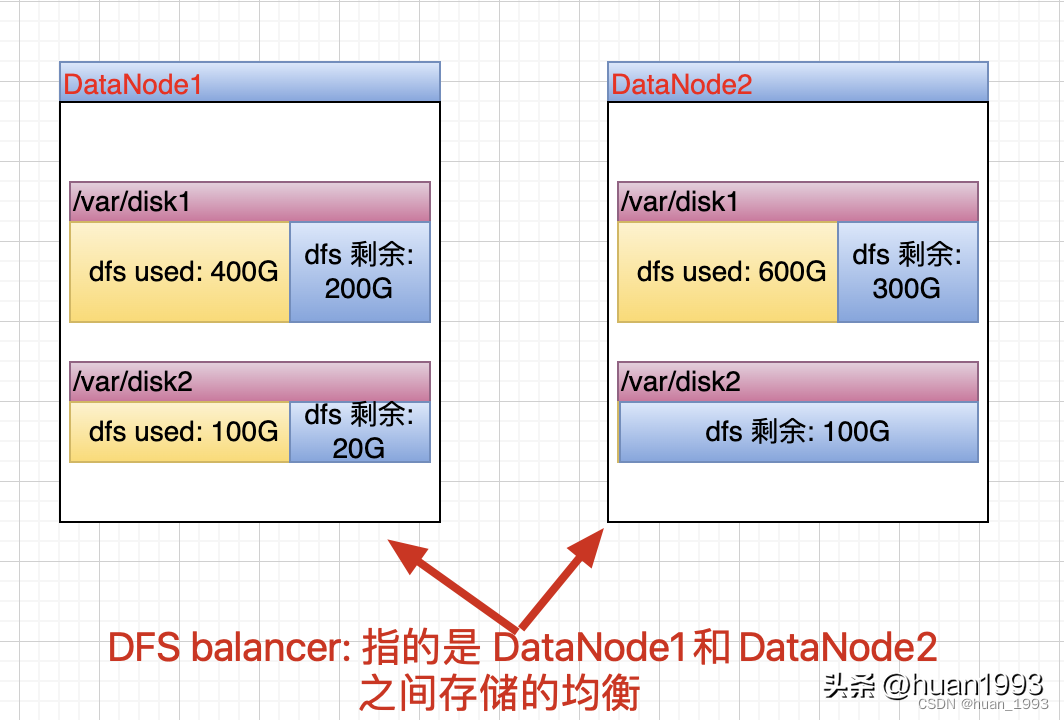
hdfs balancer
hdfs disk balancer:是为了使单台DataNode中的多个磁盘中的数据均衡。
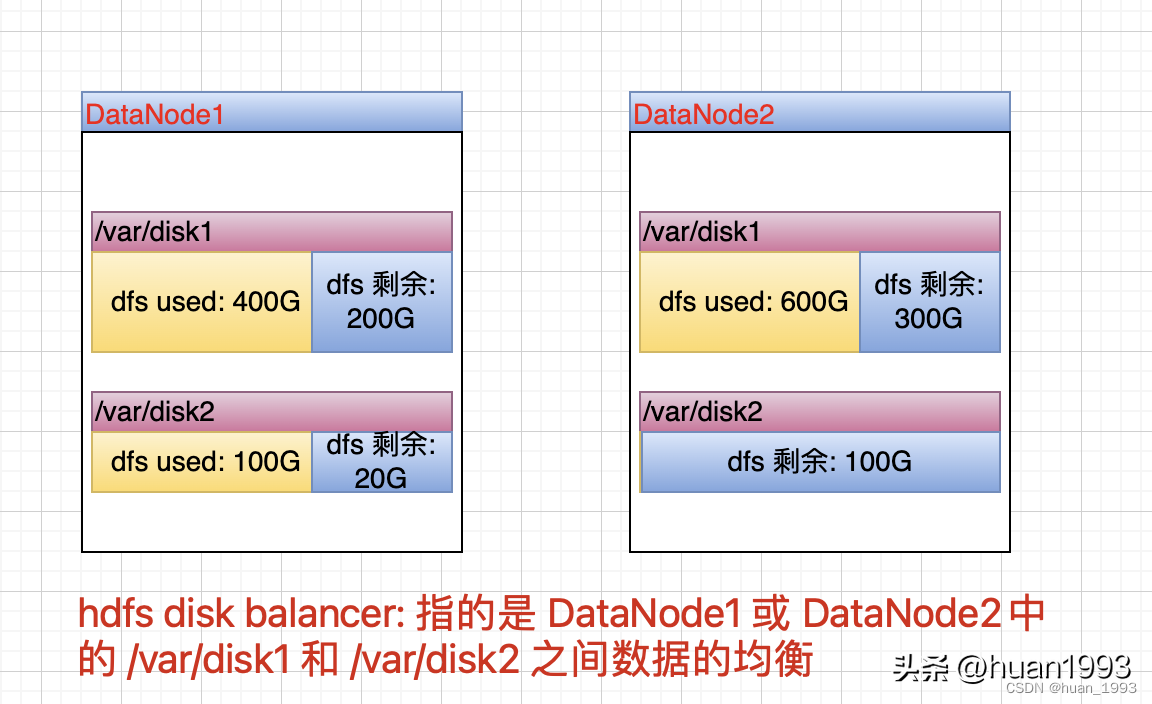
hdfs disk balancer
注意: 目前DiskBalancer不支持跨存储介质(SSD、DISK等)的数据转移,所以磁盘的均衡都是要求在一个storageType下的。因为hdfs中存在异构存储。
[hadoopdeploy@hadoop01 ~]$ hdfs diskbalancer -plan hadoop01 -out hadoop01-plan.json-plan:后面接的是主机名。-out:指定计划文件的输出位置。

生成计划
[hadoopdeploy@hadoop01 ~]$ hdfs diskbalancer -execute hadoop01-plan.json
执行计划
[hadoopdeploy@hadoop01 ~]$ hdfs diskbalancer -query hadoop01-query 后面跟的是 主机名

查询计划
[hadoopdeploy@hadoop01 ~]$ hdfs diskbalancer -cancel hadoop01-plan.json
取消计划
配置 | 描述 |
dfs.disk.balancer.enabled | 此参数控制是否为集群启用diskbalancer。如果未启用,任何执行命令都将被DataNode拒绝。默认值为true。 |
dfs.disk.balancer.max.disk.throughputInMBperSec | 这控制了diskbalancer在复制数据时消耗的最大磁盘带宽。如果指定了10MB之类的值,则diskbalancer平均只会复制10MB/S。默认值为10MB/S。 |
dfs.disk.balancer.max.disk.errors | 设置能够容忍的在指定的移动过程中出现的最大错误次数,超过此阈值则失败。例如,如果一个计划有3对磁盘要在其中复制,并且第一个磁盘集遇到超过5个错误,那么我们放弃第一个副本并启动计划中的第二个副本。最大错误的默认值设置为5。 |
dfs.disk.balancer.block.tolerance.percent | 设置磁盘之间进行数据均衡操作时,各个磁盘的数据存储量与理想状态之间的差异阈值。取值范围[1-100],默认为10。例如,各个磁盘的理想数据存储量为100 GB,此参数设置为10。那么,当目标磁盘的数据存储量达到90 GB时,则认为该磁盘的存储状态就已经达到预期。 |
dfs.disk.balancer.plan.threshold.percent | 设置在磁盘数据均衡中可容忍的两磁盘之间的数据密度域值差,取值范围[1-100],默认为10。如果任意两个磁盘数据密度差值的绝对值超过了阈值,则说明需要对该的磁盘进行数据均衡。例如,如果一个2盘节点上的总数据为100 GB,那么磁盘均衡器计算每个磁盘上的期望值为50 GB。如果容差为10%,则单个磁盘上的数据需要大于60 GB(50 GB + 10%容差值),DiskBalancer才能开始工作。 |
dfs.disk.balancer.plan.valid.interval | 磁盘平衡器计划有效的最大时间。支持以下后缀(不区分大小写):ms(milis)、s(sec)、m(min)、h(h)、d(day)以指定时间(例如2s、2m、1h等)。如果未指定后缀,则假定为毫秒。默认值为1d |
当数据写入新的block时,DataNode会根据策略选择不同的磁盘来存储。
循环策略: 默认策略,将新的块均匀的分布在可用的磁盘上,可能造成数据倾斜。
可用空间策略: 选择更多可用空间(按百分比)的磁盘。可能造成在某段时间内,某个磁盘的IO压力变大。

磁盘数据密度度量标准
上图来自https://www.bilibili.com/video/BV11N411d7Zh/?p=81
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t
如果我使用ruby版本2.5.1和Rails版本2.3.18会怎样?我有基于rails2.3.18和ruby1.9.2p320构建的rails应用程序,我只想升级ruby的版本,而不是rails,这可能吗?我必须面对哪些挑战? 最佳答案 GitHub维护apublicfork它有针对旧Rails版本的分支,有各种变化,它们一直在运行。有一段时间,他们在较新的Ruby版本上运行较旧的Rails版本,而不是最初支持的版本,因此您可能会发现一些关于需要向后移植的有用提示。不过,他们现在已经有几年没有使用2.3了,所以充其量只能让更
我已经找到了几个使用datamapper的示例,并且能够让它们正常工作。不过,所有这些示例都是针对sqlite数据库的。我正在尝试将数据映射器与postgresql一起使用。我将datamapper中的调用从sqlite3更改为postgres,并且我已经安装了dm-postgres-adapter。但它仍然不起作用。我还需要做什么? 最佳答案 与SQLite不同,PostgreSQL不将数据库存储在单个文件中。在你拥有createdyourdatabase之后,尝试这样的事情:DataMapper.setup:default,{:
我经常将预配置的lambda插入可枚举的方法中,例如“map”、“select”等。但是“注入(inject)”的行为似乎有所不同。例如与mult4=lambda{|item|item*4}然后(5..10).map&mult4给我[20,24,28,32,36,40]但是,如果我制作一个2参数lambda用于像这样的注入(inject),multL=lambda{|product,n|product*n}我想说(5..10).inject(2)&multL因为“inject”有一个可选的单个初始值参数,但这给了我......irb(main):027:0>(5..10).inject
我需要使用ActiveMerchant库在我们的一个Rails应用程序中设置支付解决方案。尽管这个问题非常主观,但人们对主要网关(BrainTree、Authorize.net等)的体验如何?它必须:处理定期付款。有能力记入个人帐户。能够取消付款。有办法存储用户的付款详细信息(例如Authotize.netsCIM)。干杯 最佳答案 ActiveMerchant很棒,但在过去一年左右的时间里,我在使用它时发现了一些问题。首先,虽然某些网关可能会得到“支持”——但并非所有功能都包含在内。查看功能矩阵以确保完全支持您选择的网关-http
我有一个Rails应用程序,我正在尝试使用acts_as_list插件设置可排序列表。数据库中的位置字段正在更新,但是在呈现页面时,不考虑顺序。我想我是在寻求帮助。这是我的模型...classQuestionMembership:question_membershipsendclassQuestion:question_membershipsacts_as_listend还有给我列表的草率View代码...>true)%>拖放用于重新排序。数据库中QuestionMembership对象的位置值更新,页面实际上正确显示重新排序。问题是在页面重新加载时,它默认返回到它感觉的任何顺序。我认
例如,如果我们defc=(foo)p"hello"endc=3c=(3)并且不会打印“hello”。我知道它可以被self.c=3调用,但为什么呢?可以通过哪些其他方式调用它? 最佳答案 c=3(和c=(3),完全等同于它)总是被解释为局部变量赋值。你可能会说只有当方法c=没有在self上定义时,它才应该被解释为局部变量赋值,但是这有很多问题:至少MRI需要在解析时知道在给定范围内定义了哪些局部变量。但是,在解析时并不知道给定的方法是否已定义。所以ruby直到运行时才知道c=3是否定义了变量c或者调用了方法c=,这意味着它不会知
文章目录一基础定义二创建逻辑卷2-1准备物理设备2-2创建物理卷2-3创建卷组2-4创建逻辑卷2-5创建文件系统并挂载文件三扩展卷组和缩减卷组3-1准备物理设备3-2创建物理卷3-3扩展卷组3-4查看卷组的详细信息以验证3-5缩减卷组四扩展逻辑卷4-1检查卷组是否有可用的空间4-2扩展逻辑卷4-3扩展文件系统五删除逻辑卷5-1备份数据5-2卸载文件系统5-3删除逻辑卷5-4删除卷组5-5删除物理卷六LVM逻辑卷缩容6-1缩容注意事项6-2标准缩容步骤一基础定义LVM,LogicalVolumeManger,逻辑卷管理,Linux磁盘分区管理的一种机制,建立在硬盘和分区上的一个逻辑层,提高磁盘分
我想获取一个数组并将其作为订单列表。目前我正在尝试以这种方式进行:r=["a","b","c"]r.each_with_index{|w,index|puts"#{index+1}.#{w}"}.map.to_a#1.a#2.b#3.c#=>["a","b","c"]输出应该是["1.a","2.b","3.c"]。如何让正确的输出成为r数组的新值? 最佳答案 a.to_enum.with_index(1).map{|element,index|"#{index}.#{element}"}或a.map.with_index(1){|
我试图定义一个带有方法的类,以及一个缺少这些方法的类,然后允许后一个类的对象从前一个类的实例“学习”这些方法。这是我的尝试(Ruby1.9.2)-当我尝试更改lambda绑定(bind)中“self”的值时,它中断了(在注释为“BREAKS!”的行处)。如果您能想出如何解决这个问题-我很想知道。classSkillattr_accessor:nameattr_accessor:techniquedefinitialize(name,&technique_proc)@name=name@technique=lambda(&proc)endendclassPersonattr_access