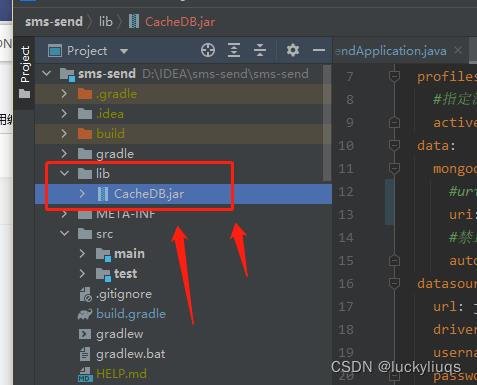
如下图所示,引入CacheDB本地jar包:
dependencies {
// 依赖lib目录下的某个jar文件
implementation files('lib/xxx.jar')
// 依赖lib目录下的所有以.jar结尾的文件
implementation fileTree(dir: 'lib', includes: ['*.jar'])
// 依赖lib目录下的除了xxx.jar以外的所有以.jar结尾的文件
implementation fileTree(dir: 'lib', excludes: ['xxx.jar'], includes: ['*.jar'])
}
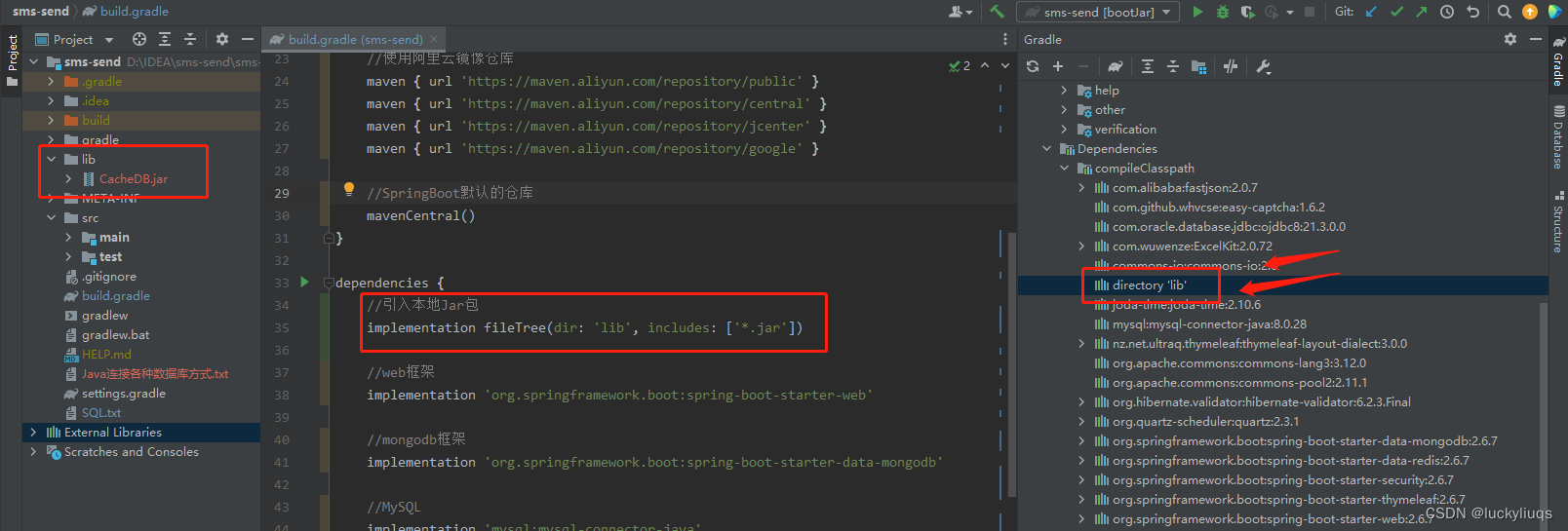
如下图所示,在Gradle的compileClassPath里面可以看到directory 'lib'
使用此方法引入的本地jar包,不会在External Libraries中显示,但可以使用
repositories {
flatDir(dirs: "lib")
mavenCentral()
}
我正在编写一个包含C扩展的gem。通常当我写一个gem时,我会遵循TDD的过程,我会写一个失败的规范,然后处理代码直到它通过,等等......在“ext/mygem/mygem.c”中我的C扩展和在gemspec的“扩展”中配置的有效extconf.rb,如何运行我的规范并仍然加载我的C扩展?当我更改C代码时,我需要采取哪些步骤来重新编译代码?这可能是个愚蠢的问题,但是从我的gem的开发源代码树中输入“bundleinstall”不会构建任何native扩展。当我手动运行rubyext/mygem/extconf.rb时,我确实得到了一个Makefile(在整个项目的根目录中),然后当
我们的git存储库中目前有一个Gemfile。但是,有一个gem我只在我的环境中本地使用(我的团队不使用它)。为了使用它,我必须将它添加到我们的Gemfile中,但每次我checkout到我们的master/dev主分支时,由于与跟踪的gemfile冲突,我必须删除它。我想要的是类似Gemfile.local的东西,它将继承从Gemfile导入的gems,但也允许在那里导入新的gems以供使用只有我的机器。此文件将在.gitignore中被忽略。这可能吗? 最佳答案 设置BUNDLE_GEMFILE环境变量:BUNDLE_GEMFI
我想让一个yaml对象引用另一个,如下所示:intro:"Hello,dearuser."registration:$introThanksforregistering!new_message:$introYouhaveanewmessage!上面的语法只是它如何工作的一个例子(这也是它在thiscpanmodule中的工作方式。)我正在使用标准的rubyyaml解析器。这可能吗? 最佳答案 一些yaml对象确实引用了其他对象:irb>require'yaml'#=>trueirb>str="hello"#=>"hello"ir
我的Rails站点使用了一个确实不是很好的gem。每次我需要做一些新的事情时,我最终不得不花费与向实际Rails项目添加代码一样多的时间来为gem添加功能。但我不介意,我将我的Gemfile设置为指向我的gem的GitHub分支(我尝试提交PR,但维护者似乎已经下台)。问题是我真的没有找到一种合理的方法来测试我添加到gem的新东西。在railsc中测试它会特别好,但我能想到的唯一方法是a)更改~/.rvm/gems/.../foo。rb,这看起来不对或者b)升级版本,推送到Github,然后运行bundleup,这除了耗时之外显然是一场灾难,因为我不确定我所做的promise是否正
我正在尝试将一个资源属性的默认值设置为另一个属性的值。我正在为我正在构建的tomcat说明书定义一个资源,其中包含以下定义。我想要可以独立设置的“名称”和“服务名称”属性。当未设置服务名称时,我希望它默认为为“名称”提供的任何内容。以下不符合我的预期:attribute:name,:kind_of=>String,:required=>true,:name_attribute=>trueattribute:service_name,:kind_of=>String,:default=>:name注意第二行末尾的“:default=>:name”。当我在Recipe的新block中引用我
如thisanswer中所述,Array.new(size,object)创建一个数组,其中size引用相同的object。hash=Hash.newa=Array.new(2,hash)a[0]['cat']='feline'a#=>[{"cat"=>"feline"},{"cat"=>"feline"}]a[1]['cat']='Felix'a#=>[{"cat"=>"Felix"},{"cat"=>"Felix"}]为什么Ruby会这样做,而不是对object进行dup或clone? 最佳答案 因为那是thedocumenta
假设我有一个可枚举对象enum,现在我想获取第三个项目。我知道一种通用方法是转换成数组,然后使用索引访问,如:enum.to_a[2]但这种方式会创建一个临时数组,效率可能很低。现在我使用:enum.each_with_index{|v,i|breakvifi==2}但这非常丑陋和多余。执行此操作最有效的方法是什么? 最佳答案 你可以使用take剥离前三个元素,然后剥离last从take给你的数组中获取第三个元素:third=enum.take(3).last如果您根本不想生成任何数组,那么也许:#Ifenumisn'tanEnum
我希望访问我机器上的所有HTTP流量(我的Windows机器-不是服务器)。据我了解,拥有一个本地代理是所有流量路线的必经之路。我一直在谷歌搜索但未能找到任何资源(关于Ruby)来帮助我。非常感谢任何提示或链接。 最佳答案 WEBrick中有一个HTTP代理(Rubystdlib的一部分)和here's一个实现示例。如果你喜欢生活在边缘,还有em-proxy伊利亚·格里戈里克。这postIlya暗示它似乎确实需要一些调整来解决您的问题。 关于ruby-如何捕获所有HTTP流量(本地代理)
我正在尝试找出一种方法来显示来自不在RAILS_ROOT下(在RedHat或Ubuntu环境中)的已安装文件系统的图像。我不想使用符号链接(symboliclink),因为这个应用程序实际上是通过Tomcat部署的,而当我关闭Tomcat时,Tomcat会尝试跟随符号链接(symboliclink)并删除挂载中的所有图像。由于这些文件的数量和大小,将图像放在public/images下也不是一种选择。我查看了send_file,但它只会显示一张图片。我需要在一个格式良好的页面中显示6个请求的图像。由于膨胀,我宁愿不使用Base64编码,但我不知道如何将图像数据与呈现的页面一起传递下去。
我刚刚在我的Ubuntu9.10服务器上安装了TeamBox。我使用提供的服务器脚本在端口3000上启动并运行它。它的运行速度非常慢,从另一台计算机连接时每个HTTP请求最多需要30秒。我使用链接从shell加载TeamBox,一点也不花时间。然后我设置了一个SSH隧道,它再次运行得非常快。我通过此服务器上的apache以及SAMBA等运行了大约30个虚拟主机,没有任何问题。我该如何解决这个问题? 最佳答案 我的redmine(ruby,webrick)太慢了。现在我解决了这个问题:apt-getinstallmongrelruby