

基于CNN的超分辨方法虽然取得了最好的结果,但此类方法关注更宽或更深的结构设计,忽略了中间层特征之间的关系。基于此,本文提出了二阶注意力机制(SOCA)更好的学习特征之间的联系,此模块通过利用二阶特征的分布自适应的学习特征的内部依赖关系,SOCA的机制是网络能够专注于更有益的信息且能够提高判别学习的能力。此外,本文提出了一种非局部加强残差组结构能进一步结合非局部操作来提取长程的空间上下文信息。通过堆叠非局部残差组,本文的方法能够利用LR图像的信息且能够忽略低频信息。总体上该论文贡献主要有以下三点:
1.提出了用于图像超分辨的深度二阶注意力网络,
2.提出了二阶注意力机制通过利用高阶的特征自适应的调整特征,另外利用了协方差归一化的方法来加速网络的训练。
3.提出了非局部加强残差组NLRG结构构建网络,进一步结合非局部操作来提取空间上的上下文信息,并共享残差结构来学习深度特征,另外通过跳跃链接来过滤低频信息且简化了深层网络的训练。
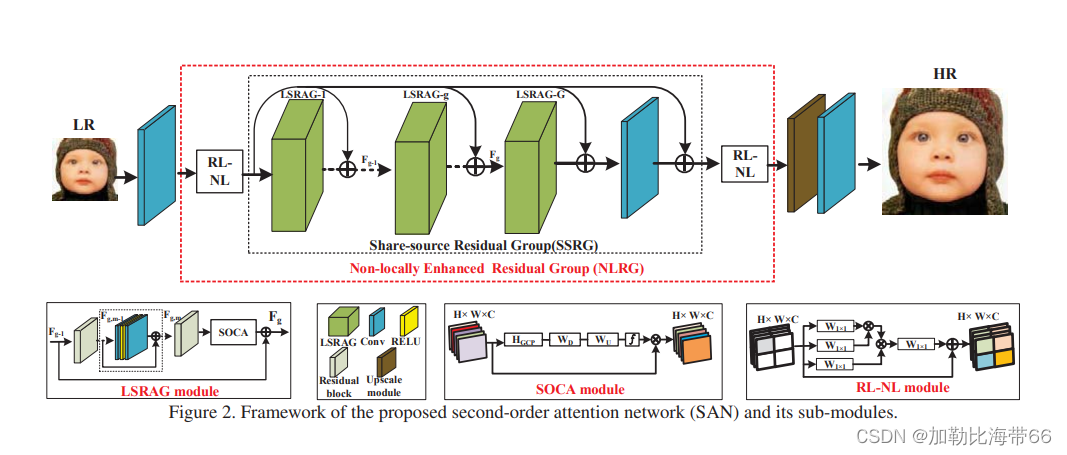

改进方法和其他注意力机制一样,分三步走:
#SOCA moudle 单幅图像超分辨率
class Covpool(Function):
@staticmethod
def forward(ctx, input):
x = input
batchSize = x.data.shape[0]
dim = x.data.shape[1]
h = x.data.shape[2]
w = x.data.shape[3]
M = h*w
x = x.reshape(batchSize,dim,M)
I_hat = (-1./M/M)*torch.ones(M,M,device = x.device) + (1./M)*torch.eye(M,M,device = x.device)
I_hat = I_hat.view(1,M,M).repeat(batchSize,1,1).type(x.dtype)
y = x.bmm(I_hat).bmm(x.transpose(1,2))
ctx.save_for_backward(input,I_hat)
return y
@staticmethod
def backward(ctx, grad_output):
input,I_hat = ctx.saved_tensors
x = input
batchSize = x.data.shape[0]
dim = x.data.shape[1]
h = x.data.shape[2]
w = x.data.shape[3]
M = h*w
x = x.reshape(batchSize,dim,M)
grad_input = grad_output + grad_output.transpose(1,2)
grad_input = grad_input.bmm(x).bmm(I_hat)
grad_input = grad_input.reshape(batchSize,dim,h,w)
return grad_input
class Sqrtm(Function):
@staticmethod
def forward(ctx, input, iterN):
x = input
batchSize = x.data.shape[0]
dim = x.data.shape[1]
dtype = x.dtype
I3 = 3.0*torch.eye(dim,dim,device = x.device).view(1, dim, dim).repeat(batchSize,1,1).type(dtype)
normA = (1.0/3.0)*x.mul(I3).sum(dim=1).sum(dim=1)
A = x.div(normA.view(batchSize,1,1).expand_as(x))
Y = torch.zeros(batchSize, iterN, dim, dim, requires_grad = False, device = x.device)
Z = torch.eye(dim,dim,device = x.device).view(1,dim,dim).repeat(batchSize,iterN,1,1)
if iterN < 2:
ZY = 0.5*(I3 - A)
Y[:,0,:,:] = A.bmm(ZY)
else:
ZY = 0.5*(I3 - A)
Y[:,0,:,:] = A.bmm(ZY)
Z[:,0,:,:] = ZY
for i in range(1, iterN-1):
ZY = 0.5*(I3 - Z[:,i-1,:,:].bmm(Y[:,i-1,:,:]))
Y[:,i,:,:] = Y[:,i-1,:,:].bmm(ZY)
Z[:,i,:,:] = ZY.bmm(Z[:,i-1,:,:])
ZY = 0.5*Y[:,iterN-2,:,:].bmm(I3 - Z[:,iterN-2,:,:].bmm(Y[:,iterN-2,:,:]))
y = ZY*torch.sqrt(normA).view(batchSize, 1, 1).expand_as(x)
ctx.save_for_backward(input, A, ZY, normA, Y, Z)
ctx.iterN = iterN
return y
@staticmethod
def backward(ctx, grad_output):
input, A, ZY, normA, Y, Z = ctx.saved_tensors
iterN = ctx.iterN
x = input
batchSize = x.data.shape[0]
dim = x.data.shape[1]
dtype = x.dtype
der_postCom = grad_output*torch.sqrt(normA).view(batchSize, 1, 1).expand_as(x)
der_postComAux = (grad_output*ZY).sum(dim=1).sum(dim=1).div(2*torch.sqrt(normA))
I3 = 3.0*torch.eye(dim,dim,device = x.device).view(1, dim, dim).repeat(batchSize,1,1).type(dtype)
if iterN < 2:
der_NSiter = 0.5*(der_postCom.bmm(I3 - A) - A.bmm(der_sacleTrace))
else:
dldY = 0.5*(der_postCom.bmm(I3 - Y[:,iterN-2,:,:].bmm(Z[:,iterN-2,:,:])) -
Z[:,iterN-2,:,:].bmm(Y[:,iterN-2,:,:]).bmm(der_postCom))
dldZ = -0.5*Y[:,iterN-2,:,:].bmm(der_postCom).bmm(Y[:,iterN-2,:,:])
for i in range(iterN-3, -1, -1):
YZ = I3 - Y[:,i,:,:].bmm(Z[:,i,:,:])
ZY = Z[:,i,:,:].bmm(Y[:,i,:,:])
dldY_ = 0.5*(dldY.bmm(YZ) -
Z[:,i,:,:].bmm(dldZ).bmm(Z[:,i,:,:]) -
ZY.bmm(dldY))
dldZ_ = 0.5*(YZ.bmm(dldZ) -
Y[:,i,:,:].bmm(dldY).bmm(Y[:,i,:,:]) -
dldZ.bmm(ZY))
dldY = dldY_
dldZ = dldZ_
der_NSiter = 0.5*(dldY.bmm(I3 - A) - dldZ - A.bmm(dldY))
grad_input = der_NSiter.div(normA.view(batchSize,1,1).expand_as(x))
grad_aux = der_NSiter.mul(x).sum(dim=1).sum(dim=1)
for i in range(batchSize):
grad_input[i,:,:] += (der_postComAux[i] \
- grad_aux[i] / (normA[i] * normA[i])) \
*torch.ones(dim,device = x.device).diag()
return grad_input, None
class Triuvec(Function):
@staticmethod
def forward(ctx, input):
x = input
batchSize = x.data.shape[0]
dim = x.data.shape[1]
dtype = x.dtype
x = x.reshape(batchSize, dim*dim)
I = torch.ones(dim,dim).triu().t().reshape(dim*dim)
index = I.nonzero()
y = torch.zeros(batchSize,dim*(dim+1)/2,device = x.device)
for i in range(batchSize):
y[i, :] = x[i, index].t()
ctx.save_for_backward(input,index)
return y
@staticmethod
def backward(ctx, grad_output):
input,index = ctx.saved_tensors
x = input
batchSize = x.data.shape[0]
dim = x.data.shape[1]
dtype = x.dtype
grad_input = torch.zeros(batchSize,dim,dim,device = x.device,requires_grad=False)
grad_input = grad_input.reshape(batchSize,dim*dim)
for i in range(batchSize):
grad_input[i,index] = grad_output[i,:].reshape(index.size(),1)
grad_input = grad_input.reshape(batchSize,dim,dim)
return grad_input
def CovpoolLayer(var):
return Covpool.apply(var)
def SqrtmLayer(var, iterN):
return Sqrtm.apply(var, iterN)
def TriuvecLayer(var):
return Triuvec.apply(var)
class SOCA(nn.Module):
def __init__(self, channel, reduction=8):
super(SOCA, self).__init__()
self.max_pool = nn.MaxPool2d(kernel_size=2)
self.conv_du = nn.Sequential(
nn.Conv2d(channel, channel // reduction, 1, padding=0, bias=True),
nn.ReLU(inplace=True),
nn.Conv2d(channel // reduction, channel, 1, padding=0, bias=True),
nn.Sigmoid()
)加入SOCA moudle模块。
添加方法灵活多变,Backbone或者Neck都可。示例如下:
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, C3, [1024, False]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[-1, 1, SOCA, [1024]],
[[17, 20, 24], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]①实验前:
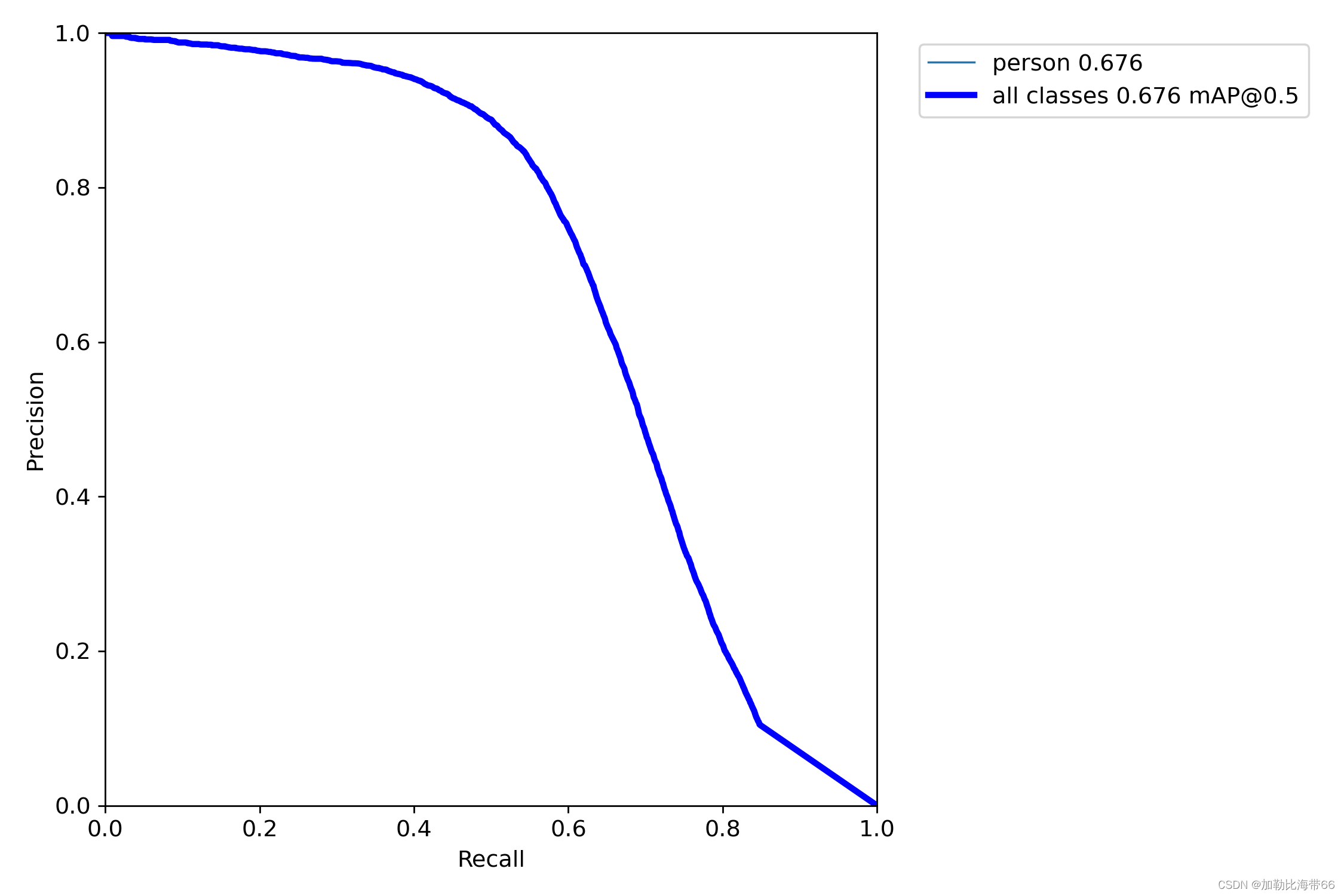
②实验后:
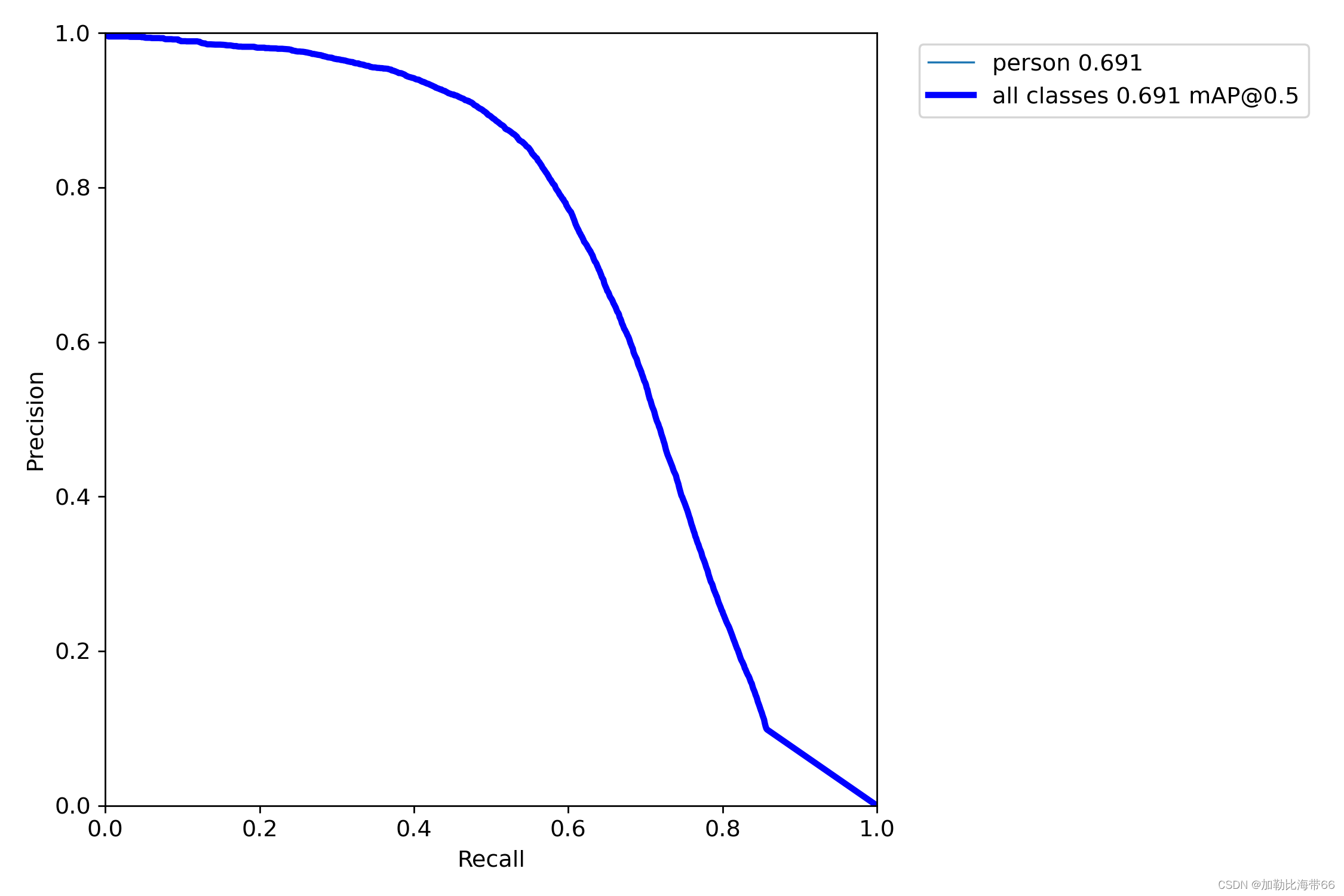
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
📢博客主页:https://blog.csdn.net/weixin_43197380📢欢迎点赞👍收藏⭐留言📝如有错误敬请指正!📢本文由Loewen丶原创,首发于CSDN,转载注明出处🙉📢现在的付出,都会是一种沉淀,只为让你成为更好的人✨文章预览:一.分辨率(Resolution)1、工业相机的分辨率是如何定义的?2、工业相机的分辨率是如何选择的?二.精度(Accuracy)1、像素精度(PixelAccuracy)2、定位精度和重复定位精度(RepeatPrecision)三.公差(Tolerance)四.课后作业(Post-ClassExercises)视觉行业的初学者,甚至是做了1~2年
我想知道我的代码是否在rspec下运行。这可能吗?原因是我正在加载一些错误记录器,这些记录器在测试期间会被故意错误(expect{x}.toraise_error)弄得乱七八糟。我查看了我的ENV变量,没有(明显的)测试环境变量的迹象。 最佳答案 在spec_helper.rb的开头添加:ENV['RACK_ENV']='test'现在您可以在代码中检查RACK_ENV是否经过测试。 关于ruby-检测由RSpec、Ruby运行的代码,我们在StackOverflow上找到一个类似的问题
我正在使用rubydaemongem。想知道如何向停止操作添加一些额外的步骤?希望我能检测到停止被调用,并向其添加一些额外的代码。任何人都知道我如何才能做到这一点? 最佳答案 查看守护程序gem代码,它似乎没有用于此目的的明显扩展点。但是,我想知道(在守护进程中)您是否可以捕获守护进程在发生“停止”时发送的KILL/TERM信号...?trap("TERM")do#executeyourextracodehereend或者你可以安装一个at_exit钩子(Hook):-at_exitdo#executeyourextracodehe
希望我没有误解“ducktyping”的含义,但从我读到的内容来看,这意味着我应该根据对象如何响应方法而不是它是什么类型/类来编写代码。代码如下:defconvert_hash(hash)ifhash.keys.all?{|k|k.is_a?(Integer)}returnhashelsifhash.keys.all?{|k|k.is_a?(Property)}new_hash={}hash.each_pair{|k,v|new_hash[k.id]=v}returnnew_hashelseraise"CustomattributekeysshouldbeID'sorPropertyo
我有一个定义类的Ruby脚本。我希望脚本执行语句BoolParser.generate:file_base=>'bool_parser'仅当脚本作为可执行文件被调用时,而不是当它被irbrequire(或通过-r在命令行上传递)时。我可以用什么来包装上面的语句,以防止它在我的Ruby文件加载时执行? 最佳答案 条件$0==__FILE__...!/usr/bin/ruby1.8classBoolParserdefself.generate(args)p['BoolParser.generate',args]endendif$0==_
我有以下字符串,我想检测那里的换行符。但是Ruby的字符串方法include?检测不到它。我正在运行Ruby1.9.2p290。我哪里出错了?"/'ædres/\nYour".include?('\n')=>false 最佳答案 \n需要在双引号内,否则无法转义。>>"\n".include?'\n'=>false>>"\n".include?"\n"=>true 关于Ruby无法检测字符串中的换行符,我们在StackOverflow上找到一个类似的问题: h
文章目录1.自动驾驶实战:基于Paddle3D的点云障碍物检测1.1环境信息1.2准备点云数据1.3安装Paddle3D1.4模型训练1.5模型评估1.6模型导出1.7模型部署效果附录show_lidar_pred_on_image.py1.自动驾驶实战:基于Paddle3D的点云障碍物检测项目地址——自动驾驶实战:基于Paddle3D的点云障碍物检测课程地址——自动驾驶感知系统揭秘1.1环境信息硬件信息CPU:2核AI加速卡:v100总显存:16GB总内存:16GB总硬盘:100GB环境配置Python:3.7.4框架信息框架版本:PaddlePaddle2.4.0(项目默认框架版本为2.3
我有一个连接到服务器的rubytcpsocket客户端。在发送数据之前如何检查套接字是否已连接?我是否尝试“拯救”断开连接的tcpsocket,重新连接然后重新发送?如果是这样,有没有人有一个简单的代码示例,因为我不知道从哪里开始:(我很自豪我设法在rails中获得了一个持久连接的客户端tcpsocket。然后服务器决定杀死客户端,一切都崩溃了;)编辑我已经使用此代码解决了一些问题-如果未连接,它将尝试重新连接,但如果服务器已关闭则不会处理这种情况(它将继续重试)。这是正确方法的开始吗?谢谢defself.write(data)begin@@my_connection.write(
我在一台Windows764位机器上使用Sass和Ruby(最新版本),我正在我的家庭服务器上处理一个共享文件夹。(但是,我不得不承认问题本身也出现在服务器上,因为我试图安装Ruby并直接-watch服务器上的文件)。问题如下:如果我第一次保存,检测到变化,我的style.css被直接覆盖。之后,我总是需要保存多达7次才能覆盖style.css。每次都会检测到更改,但不会编译任何内容。这是一个屏幕:>>>Sassiswatchingforchanges.PressCtrl-Ctostop.overwritestyle.css>>>Changedetectedto:E:/Websites