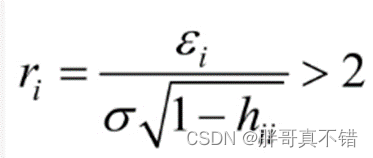说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解),如需数据+代码+文档+视频讲解可以直接到文章最后获取。
1.项目背景
回归问题是一类预测连续值的问题,而能满足这样要求的数学模型称作回归模型,本项目介绍的线性回归就是回归模型中的一种。线性回归模型属于经典的统计学模型,该模型的应用场景是根据已知的变量(即自变量)来预测某个连续的数值变量(即因变量)。例如餐厅根据每天的营业数据(包括菜谱价格、就餐人数、预定人数、特价菜折扣等)预测就餐规模或营业额;网站根据访问的历史数据(包括新用户的注册量、老用户的活跃度、网页内容的更新频率等)预测用户的支付转化率;医院根据患者的病历数据(如体检指标、药物服用情况、平时的饮食习惯等)预测某种疾病发生的概率。本项目应用OLS多元线程回归模型进行广告销售收入的预测分析。
2.数据获取
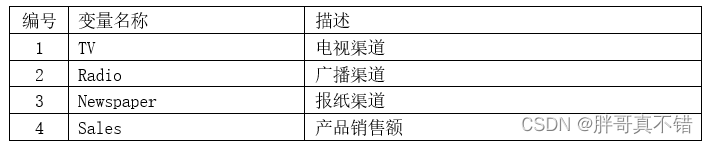
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
数据详情如下(部分展示):
3.数据预处理
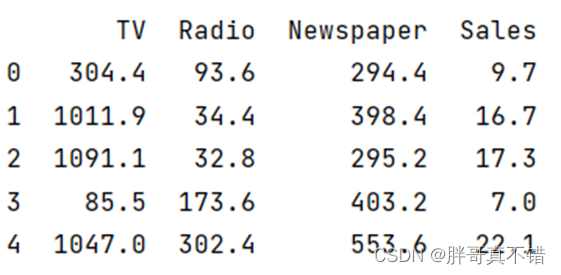
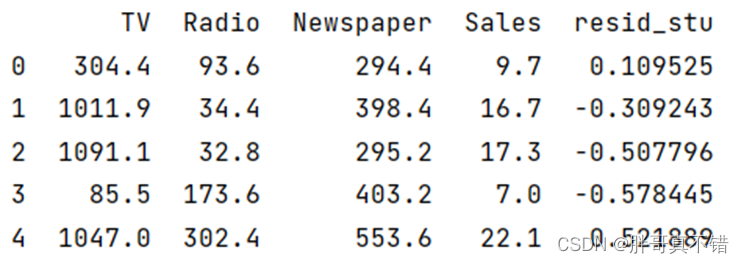
3.1 用Pandas工具查看数据
使用Pandas工具的head()方法查看前五行数据:
关键代码:
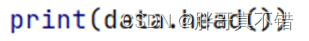
3.2数据缺失查看
使用Pandas工具的info()方法查看数据信息:
从上图可以看到,总共有4个变量,数据中无缺失值。
关键代码:
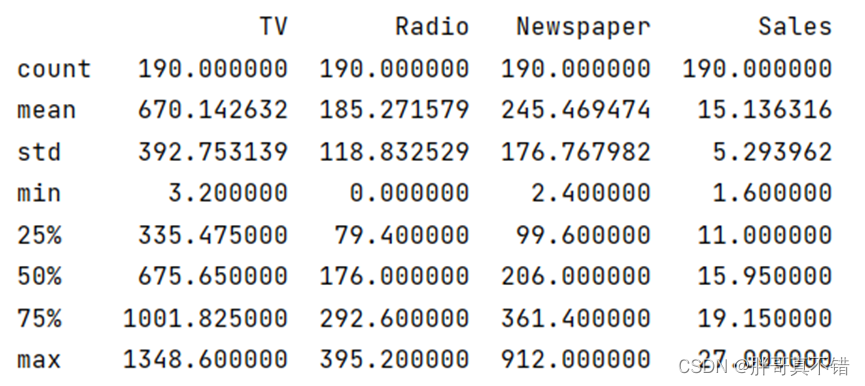
3.3数据描述性统计
通过Pandas工具的describe()方法来查看数据的平均值、标准差、最小值、分位数、最大值。
关键代码如下:
4.探索性数据分析
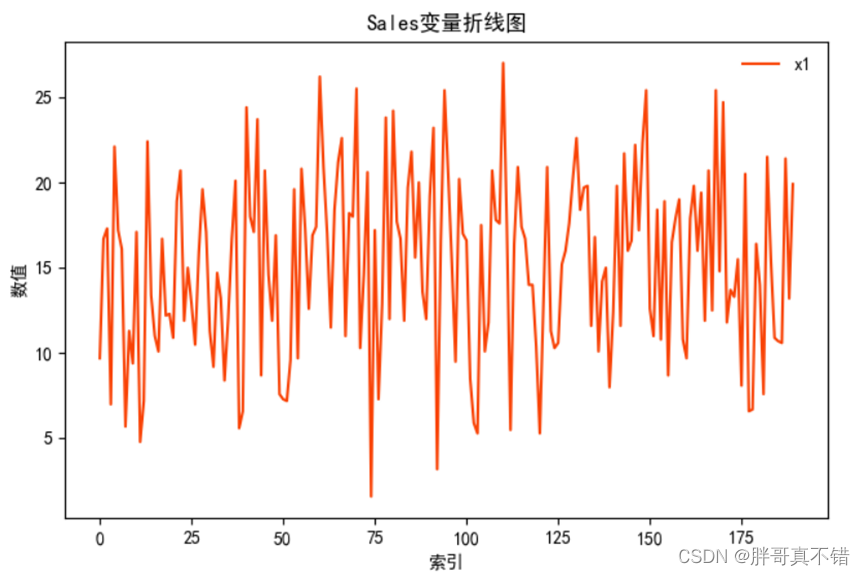
4.1 Sales变量的折线图
用Matplotlib工具的plot()方法绘制折线图:
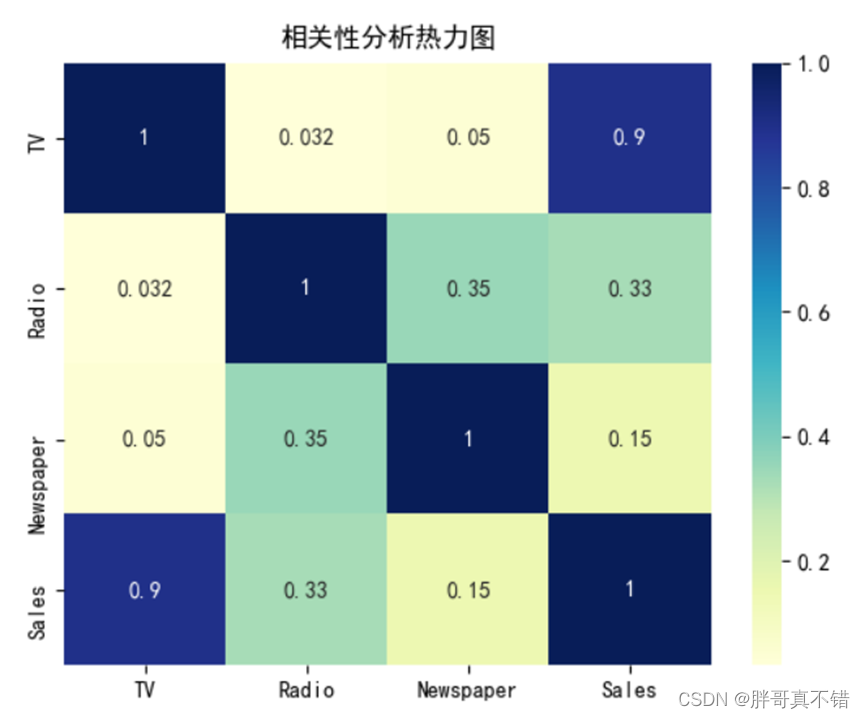
4.2 相关性分析
从上图中可以看到,数值越大相关性越强,正值是正相关、负值是负相关。
4.3 散点图拟合线分析
从上面图中可以看到,TV变量和Sales变量成线性相关,在电视渠道投放的广告金额越大,产品的销售额也越大。
5.构建多元线性回归模型
主要使用OLS算法,用于目标回归。
5.1模型构建
关键代码如下:
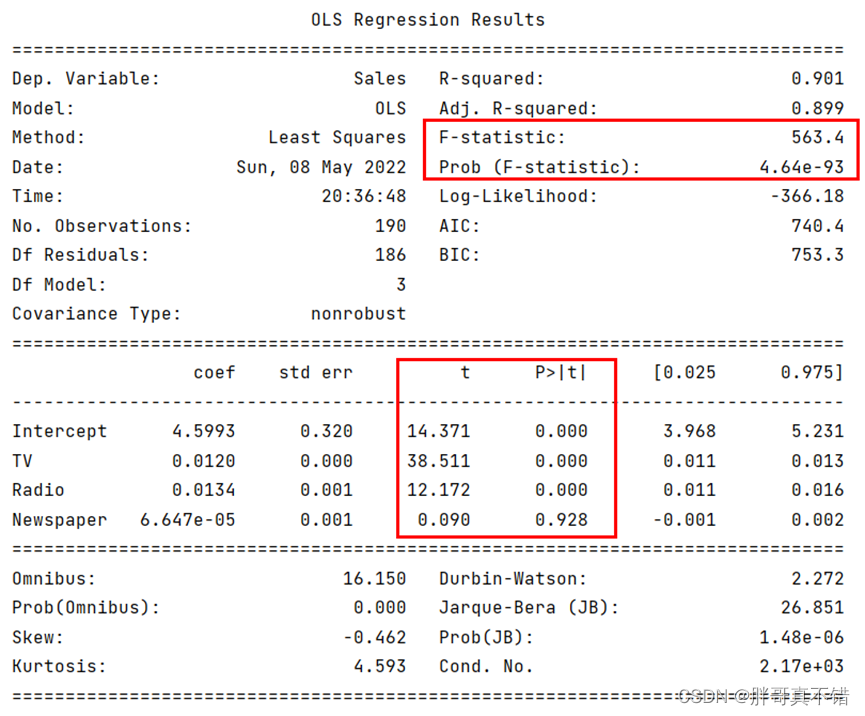
模型总结输出:
结果显示,有两种广告渠道的回归系数为正值(TV和Radio),说明这两种渠道的广告可以给销售额带来正向的支撑,而报纸渠道却无法使销售额得到提升(其回归系数为6.647e-05 无限接近于0)。所以,可以得到多元线性回归模型:
在返回的模型概览中,包含F检验和t检验的结果,其中F统计量值为563.4,对应的概率值p(4.64e-93)远远小于0.05,说明应该拒绝原假设,认为模型是显著的;在各自变量的t统计量中,唯有Newspaper变量所对应的概率值p(0.928)大于0.05,说明不能拒绝原假设,认为该变量是不显著的,无法认定其是影响销售额的重要因素。
对于F检验来说,如果无法拒绝原假设,则认为模型是无效的,通常的解决办法是增加数据量、改变自变量或选择其他的模型;对于t检验来说,如果无法拒绝原假设,则认为对应的自变量与因变量之间不存在线性关系,通常的解决办法是剔除该变量或修正该变量(如因变量与自变量存在非线性关系时,选择对应的数学转换函数,对其修正处理)。根据返回的fit模型的概览信息,由于Newspaper变量的t检验结果是不显著的,故可以探索其与因变量Sales之间的散点关系,如果二者确实没有线性关系,可以将Newspaper从模型中剔除。
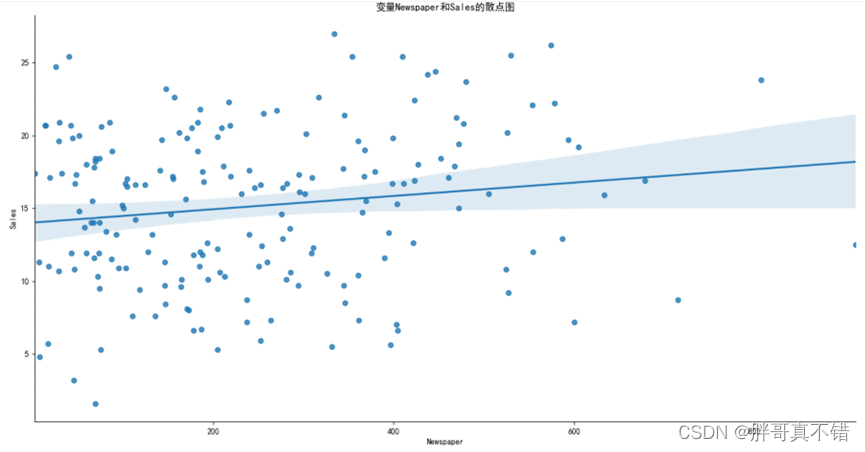
报纸广告与销售额之间的散点关系图图中自变量Newspaper与因变量Sales之间的散点关系并没有呈现明显的线性关系或非线性关系,故可以认为两者不存在互相依赖关系。既然如此,接下来要做的就是将Newspaper变量从模型中剔除。
5.2模型优化
关键代码:
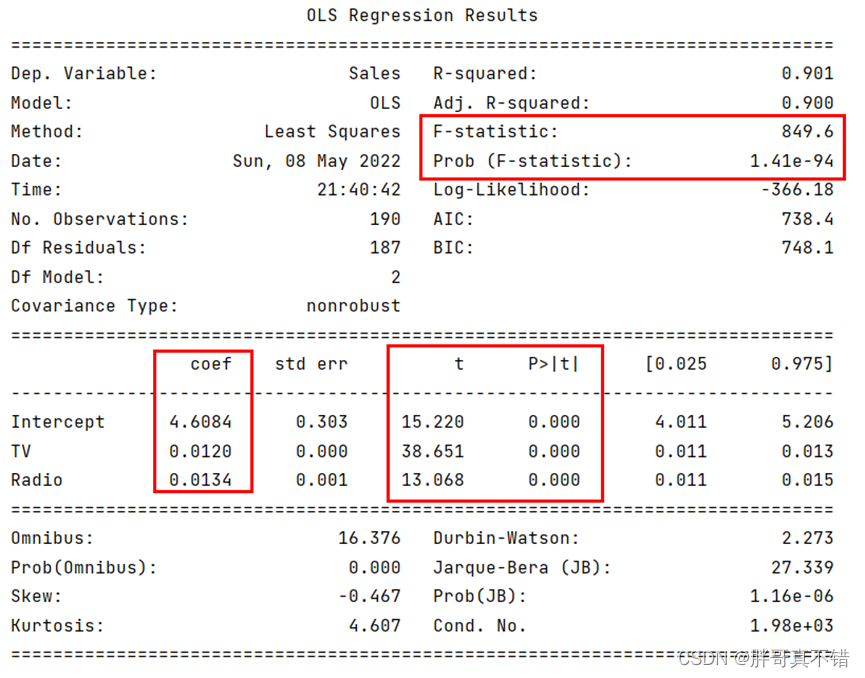
模型摘要输出:
多元线性回归模型拟合后的概览信息对模型重新调整后,得到的新模型仍然通过了显著性检验,而且每个自变量所对应的系数也是通过显著性检验的。故最终得到的模型为:
对于该回归模型中的系数是这样解释的:在其他条件不变的情况下,TV渠道的成本每增加一个单位,将使销售额增加0.0120个单位;广播渠道的成本每增加一个单位,会使销售0.0134个单位。
5.3基于回归模型识别异常点
回归模型其计算过程会依赖于自变量的均值,,均值的最大弊端是其容易受到异常点(或极端值)的影响。所以,如果建模数据中存在异常点,一定程度上会影响到模型的有效性,那么该如何利用模型来识别样本中的异常点,并对其做相应的处理呢?对于线性回归模型来说,通常利用帽子矩阵、DFFITS准则学生化残差进行异常点检测。
学生化残差需要注意的是,在DFFITS准则的公式中,乘积的第二项实际上是学生化残差,它也可以用来判定第i个样本是否为异常点,判断标准如下:
关键代码:
这里使用学生化残差,当学生化残差大于2时,即认为对应的数据点为异常值。结果显示,通过学生化残差识别出了异常值,并且异常比例为3.68%。由于异常比例非常小,故可以考虑将其直接从数据集中删除,由此继续建模将会得到更加稳定且合理的模型。具体代码如下:
模型摘要信息:
多元线性回归模型的概览信息如图所示,排除异常点之后得到模型,不管是模型的显著性检验还是系数的显著性检验,各自的概率p值均小于0.05,说明它们均通过显著性检验。
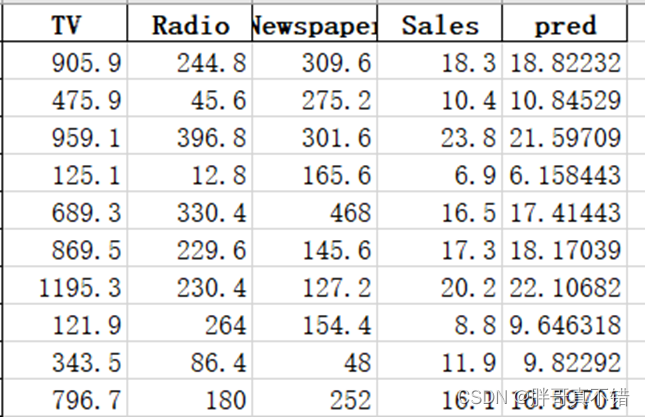
5.4模型预测
关键代码:
预测结果:
6.模型评估
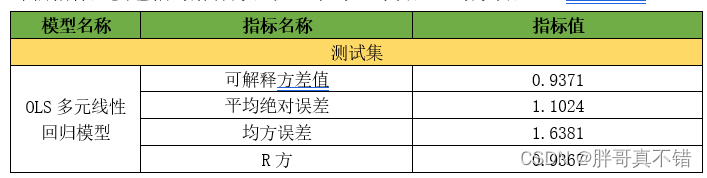
6.1评估指标及结果
评估指标主要包括可解释方差值、平均绝对误差、均方误差、R方值等等。
从上表可以看出,R方为93.67%% 可解释方差值为93.71%,OLS多元线性回归模型比较优秀,效果非常好。
关键代码如下:
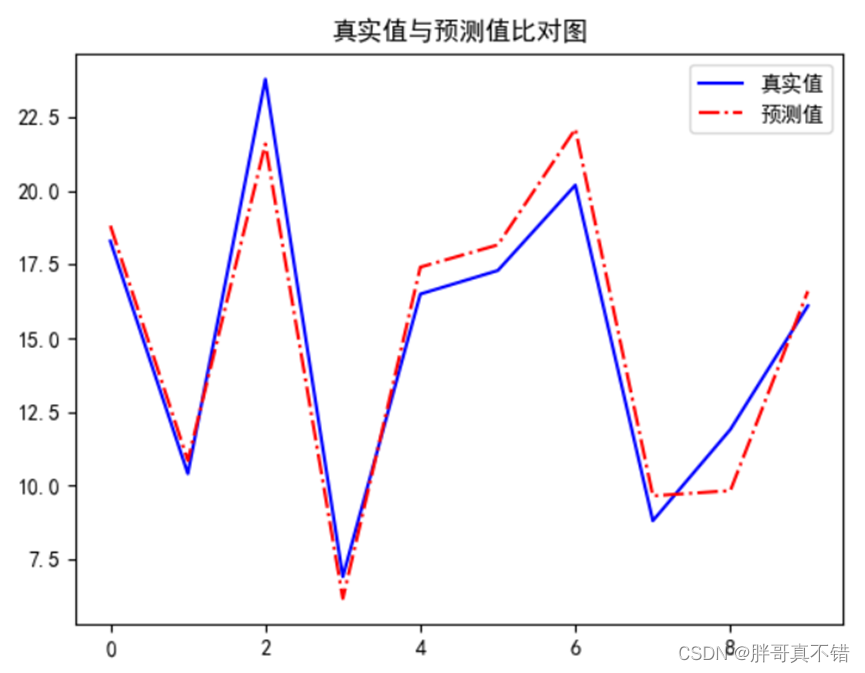
6.2 真实值与预测值对比图
从上图可以看出真实值和预测值波动基本一致,模型拟合效果非常棒。
7.结论与展望
综上所述,本文采用了OLS多元线性回归模型,最终证明了我们提出的模型效果良好。可用于日常产品销售额的研究。
本次机器学习项目实战所需的资料,项目资源如下:
项目说明:
链接:https://pan.baidu.com/s/1dW3S1a6KGdUHK90W-lmA4w
提取码:bcbp
网盘如果失效,可以添加博主微信:zy10178083
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
我在我的Rails项目中使用Pow和powifygem。现在我尝试升级我的ruby版本(从1.9.3到2.0.0,我使用RVM)当我切换ruby版本、安装所有gem依赖项时,我通过运行railss并访问localhost:3000确保该应用程序正常运行以前,我通过使用pow访问http://my_app.dev来浏览我的应用程序。升级后,由于错误Bundler::RubyVersionMismatch:YourRubyversionis1.9.3,butyourGemfilespecified2.0.0,此url不起作用我尝试过的:重新创建pow应用程序重启pow服务器更新战俘
我已经像这样安装了一个新的Rails项目:$railsnewsite它执行并到达:bundleinstall但是当它似乎尝试安装依赖项时我得到了这个错误Gem::Ext::BuildError:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcheckingforlibkern/OSAtomic.h...yescreatingMakefilemake"DESTDIR="cleanmake"DESTDIR="
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
假设我有这个范围:("aaaaa".."zzzzz")如何在不事先/每次生成整个项目的情况下从范围中获取第N个项目? 最佳答案 一种快速简便的方法:("aaaaa".."zzzzz").first(42).last#==>"aaabp"如果出于某种原因你不得不一遍又一遍地这样做,或者如果你需要避免为前N个元素构建中间数组,你可以这样写:moduleEnumerabledefskip(n)returnto_enum:skip,nunlessblock_given?each_with_indexdo|item,index|yieldit
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
我想解析一个已经存在的.mid文件,改变它的乐器,例如从“acousticgrandpiano”到“violin”,然后将它保存回去或作为另一个.mid文件。根据我在文档中看到的内容,该乐器通过program_change或patch_change指令进行了更改,但我找不到任何在已经存在的MIDI文件中执行此操作的库.他们似乎都只支持从头开始创建的MIDI文件。 最佳答案 MIDIpackage会为您完成此操作,但具体方法取决于midi文件的原始内容。一个MIDI文件由一个或多个音轨组成,每个音轨是十六个channel中任何一个上的