hive 存储格式有很多,但常用的一般是 TextFile、ORC、Parquet 格式,在我们单位最多的也是这三种
hive 默认的文件存储格式是 TextFile。
除 TextFile 外的其他格式的表不能直接从本地文件导入数据,要先导入到 TextFile 格式的表中,再从表中用 insert 导入到其他格式的表中。
TextFile 是行式存储。
建表时无需指定,一般默认这种格式,以这种格式存储的文件,可以直接在 HDFS 上 cat 查看数据。
可以用任意分隔符对列分割,建表时需要指定分隔符。
不会对文件进行压缩,因此加载数据的时候会比较快,因为不需要解压缩;但也因此更占用存储空间。
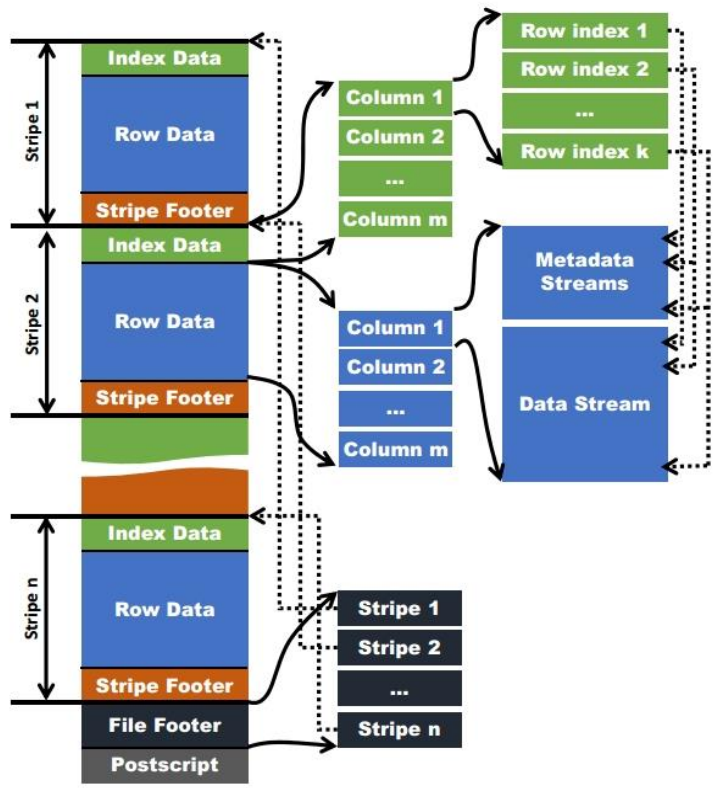
ORCFile 是列式存储。
建表时需指定 STORED AS ORC,文件存储方式为二进制文件。
Orc表支持None、Zlib、Snappy压缩,默认支持Zlib压缩。
Zlib 压缩率比 Snappy 高,Snappy 效率比 Zlib 高。
这几种压缩方式都不支持文件分割,所以压缩后的文件在执行 Map 操作时只会被一个任务所读取。
因此若压缩文件较大,处理该文件的时间比处理其它普通文件的时间要长,造成数据倾斜。
另外,hive 建事务表需要指定为 orc 存储格式。
ORC 格式如下所示:
Parquet 也是列式存储。
建表时需指定 STORED AS PARQUET,文件存储方式为二进制文件。
可以使用的压缩方式有 UNCOMPRESSED、 SNAPPY、GZP和LZO。默认值为 UNCOMPRESSED,表示页的压缩方式
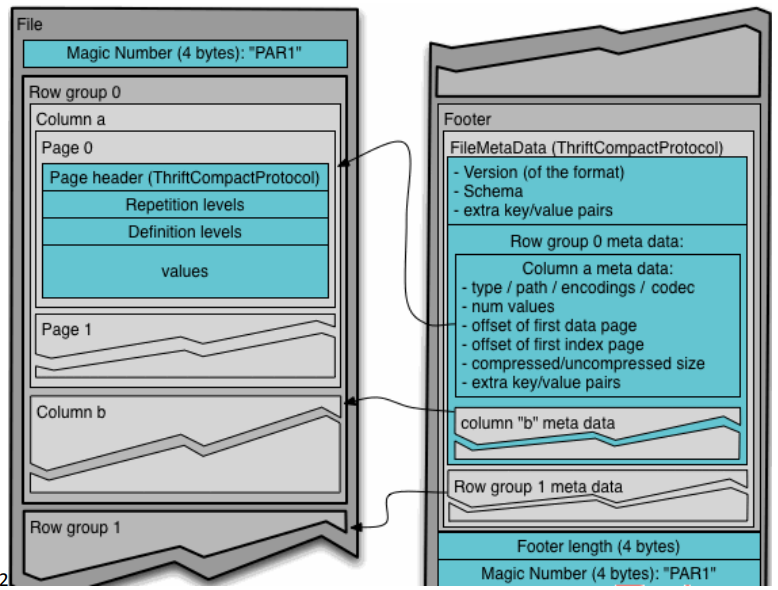
行组(Row Group):每一个行组包含一定的行数,在一个HDFS文件中至少存储一个行组,类似于orc的stripe的概念。
列块(Column Chunk):在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。一个列块中的值都是相同类型的,不同的列块可能使用不同的算法进行压缩。
同样的数据,TextFile 为 2.4G 的情况下,将原数据存放为 ORC 以及 Parquet 格式后,其占用存储大小以及查询效率大致如下:
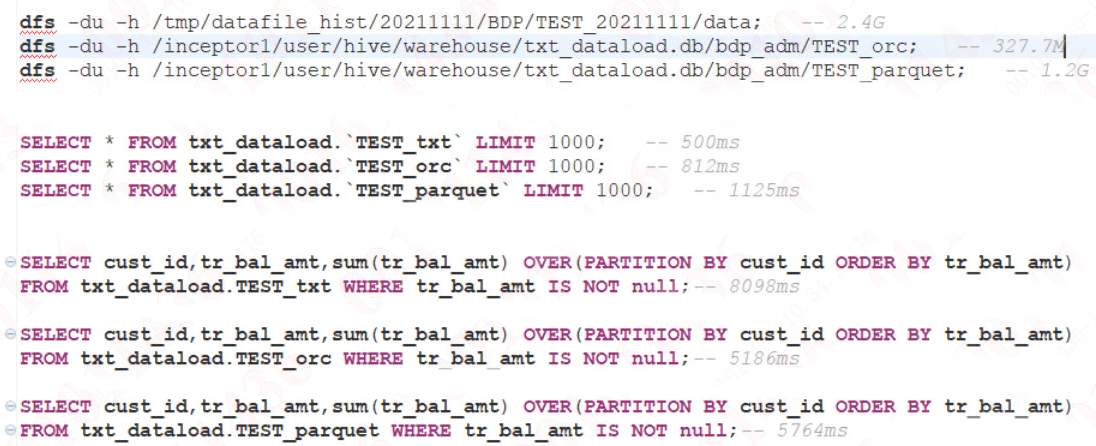
由此可以看出压缩比:ORC > Parquet > TextFile
在只有 Fecth 的情况下,由于 TextFile 不需要解压缩,因此效率较高。
对于需要 MapReduce 操作的查询,效率:ORC >= Parquet > TextFile
当然,这只是我自己简单的测试,有些变量并没有控制好。
比如在单个文件比较大的情况下,可能 Parquet 的效率会比较高。
在实际生产中,使用 Parquet 存储 lzo 压缩的方式比较常见,这种情况下可以避免由于读取不可分割的大文件引发的数据倾斜。
但是,如果数据量并不大,使用 ORC 存储 snappy 压缩的效率还是非常高的;对于需要事务的场景,还是用 ORC。
至于要用哪种存储格式,需要基于自身业务进行考量。
今天的文章到这里就结束了,如果觉得写的不错的话,可以随手点个赞和关注!
关注“大数据的奇妙冒险”,转载请注明出处!
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我的目标是转换表单输入,例如“100兆字节”或“1GB”,并将其转换为我可以存储在数据库中的文件大小(以千字节为单位)。目前,我有这个:defquota_convert@regex=/([0-9]+)(.*)s/@sizes=%w{kilobytemegabytegigabyte}m=self.quota.match(@regex)if@sizes.include?m[2]eval("self.quota=#{m[1]}.#{m[2]}")endend这有效,但前提是输入是倍数(“gigabytes”,而不是“gigabyte”)并且由于使用了eval看起来疯狂不安全。所以,功能正常,
Rails2.3可以选择随时使用RouteSet#add_configuration_file添加更多路由。是否可以在Rails3项目中做同样的事情? 最佳答案 在config/application.rb中:config.paths.config.routes在Rails3.2(也可能是Rails3.1)中,使用:config.paths["config/routes"] 关于ruby-on-rails-Rails3中的多个路由文件,我们在StackOverflow上找到一个类似的问题
对于具有离线功能的智能手机应用程序,我正在为Xml文件创建单向文本同步。我希望我的服务器将增量/差异(例如GNU差异补丁)发送到目标设备。这是计划:Time=0Server:hasversion_1ofXmlfile(~800kiB)Client:hasversion_1ofXmlfile(~800kiB)Time=1Server:hasversion_1andversion_2ofXmlfile(each~800kiB)computesdeltaoftheseversions(=patch)(~10kiB)sendspatchtoClient(~10kiBtransferred)Cl
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
大约一年前,我决定确保每个包含非唯一文本的Flash通知都将从模块中的方法中获取文本。我这样做的最初原因是为了避免一遍又一遍地输入相同的字符串。如果我想更改措辞,我可以在一个地方轻松完成,而且一遍又一遍地重复同一件事而出现拼写错误的可能性也会降低。我最终得到的是这样的:moduleMessagesdefformat_error_messages(errors)errors.map{|attribute,message|"Error:#{attribute.to_s.titleize}#{message}."}enddeferror_message_could_not_find(obje
我正在寻找执行以下操作的正确语法(在Perl、Shell或Ruby中):#variabletoaccessthedatalinesappendedasafileEND_OF_SCRIPT_MARKERrawdatastartshereanditcontinues. 最佳答案 Perl用__DATA__做这个:#!/usr/bin/perlusestrict;usewarnings;while(){print;}__DATA__Texttoprintgoeshere 关于ruby-如何将脚
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
使用带有Rails插件的vim,您可以创建一个迁移文件,然后一次性打开该文件吗?textmate也可以这样吗? 最佳答案 你可以使用rails.vim然后做类似的事情::Rgeneratemigratonadd_foo_to_bar插件将打开迁移生成的文件,这正是您想要的。我不能代表textmate。 关于ruby-使用VimRails,您可以创建一个新的迁移文件并一次性打开它吗?,我们在StackOverflow上找到一个类似的问题: https://sta