
这下,ZB时代真的来了。
满足ZB时代下企业级数据存储的多方面需求,助力企业更好地应对诸多挑战,进一步挖掘和实现数据的价值。这成为所有存储厂商关注的焦点。
无论是传统企业还是新兴企业,数字化加速必然对于数据存储的需求倍增,在存储性能与容量上,长期处于旺盛的增长。
与此同时,在HDD与闪存领域的全球竞争依然非常激烈,为此,像西部数据等数据存储厂商不得不加快传统HDD与闪存的技术突破,推出更为多元化的产品组合,并联合生态伙伴,共同推进企业数字化赢得未来发展。
在用户需求与市场竞争的两大力量的作用下,迈向ZB时代的路上,西部数据再次刷新了一下HDD与SSD的定义。
HDD与SSD双驱创新,多样化赋能企业数字化未来
西部数据在2022年4月正式发布了全新的公司品牌形象,也同时带来了在全球数字化发展进程上的更大企业愿景。西部数据公司副总裁兼中国区总经理蔡耀祥分析指出,秉持"发掘数据价值,创造更多可能"的企业使命,西部数据将不断探索并挑战科技边界,持续倾听客户对于数据使用的多样化诉求,充分利用在闪存及机械硬盘领域的核心优势、战略性的市场策略以及丰富的渠道,推出强大的数据存储解决方案,满足客户从小型智能设备到大型公有云等不同规模的存储需求。

随着全球用户快速步入ZB时代,企业级用户和云数据中心的数据基础架构正在加速演进,特别是云服务市场的蓬勃发展和不断细分,用户既需要大容量,也需要高性能,还需要降低TCO,这对当下企业级HDD和SSD带来了多样化的严峻挑战。但是,面向企业数字化发展,这些挑战与机遇并存,西部数据更看重这些挑战同时带来创新技术和产品迭代的更多机遇。
“发掘数据价值,创造更多可能。”这就是西部数据一直以来的企业使命。
之前,在2021年初,西部数据成功研发出了第六代162层3D NAND闪存技术,与第五代技术相比,横向单元阵列密度提高了10%,降低了每单位的成本,使每个晶圆的存储数量增加了70%。2021年底结合闪存与HDD的双重优势,西部数据开发出用于闪存增强型硬盘的OptiNAND技术。同时在2021年11月底,还对外亮相了用OptiNAND实现20TB Ultrastar DC HC560 CMR HDD。
在HDD方面,西部数据基于OptiNAND技术创新,2022年5月正式发布22TB Ultrastar DC HC570 CMR HDD,以及基于UltraSMR的26TB Ultrastar DC HC670 UltraSMR HDD。
西部数据公司副总裁兼中国区业务总经理刘钢分析指出,DC HC570和DC HC670新品以更高的存储容量和更具优势的性能,赋能云服务提供商和企业级用户实现密度提升和存储架构的创新。尤其值得一提的是,DC HC670通过将OptiNAND技术与专有固件纠错算法和SoC增强能力相结合,推出了全新的UltraSMR技术。上代SMR技术相比普通CMR,容量能够提升10%左右,采用了基于OptiNAND的UltraSMR技术,会带来容量提升20%左右。这也是高密度大容量HDD硬盘取得新的突破关键所在。

进一步分析来看,目前西部数据最新发布22TB的CMR HDD,包括用于智慧视频的WD Purple Pro、用于NAS系统的WD Red Pro以及用于企业客户的WD Gold。大容量HDD会出现更为细分品类的趋势,源自用户需求的多样化。毕竟用户的存储需求有多个维度,很难用一款产品满足用户所有需求。用户可能会对HDD容量有要求,对吞吐量、寿命有要求,同时对功耗和成本都有要求,因此需要从不同方向、针对不同应用场景优化产品组合。

对于企业级用户现有大容量HDD应用而言,最关键的数据中心典型应用场景在不断驱动需求的增长。比如国内互联网公司现在对于大数据存储、大容量HDD有着明确的需求。从18TB提升到22TB,所需的服务器、硬件就会相应减少,成本也会降低,TCO表现更好。因此稳定提升容量,对降低用户总体拥有成本带来可见的好处。
在SSD方面,针对企业级SSD领域的创新,西部数据当前正式发布了基于BiCS5 3D TLC NAND和PCIe 4.0接口的15.36TB Ultrastar DC SN650 NVMe SSD,目前采用2.5英寸和E1.L两种规格尺寸,帮助云服务提供商实现降低总体拥有成本的更好解决方案。
在提高存储资源利用率方面,Ultrastar DC SN650 NVMe SSD更是很有一手。通过增加单位SSD的虚拟化主机数量以及整合更大的数据集来提高存储资源利用率。用于大数据分析和AI/ML的数据集,还可通过采用DC SN650 NVMe SSD而缩短时延并提高数据吞吐量,从而实现更快的洞察和实时分析。更轻薄的E1.L规格尺寸增加了机架存储密度,在降低TCO的同时提高了存储的可管理性、可维护性和效率,并且DC SN650 NVMe SSD E1.L符合OCP云规范1.0a。
西部数据拥有自研SSD控制器设计、固件开发和垂直集成的能力,在开发创新产品方面有着持续的优势,因此,在SSD面向企业用户需求的变化上创新速度也是非常迅速。
全球存储观察分析指出,作为同时拥有HDD与闪存核心技术优势的公司,西部数据在云计算、大数据 、物联网、人工智能等创新科技蓬勃发展的新数据时代,持续坚持在HDD与SSD两个领域的深入应用与创新,多样化满足用户需求,赋能企业数字化未来。可见,西部数据“满足用户需求”的创新发展思路一直未变。
突破技术壁垒,这个技术“杀手锏”功不可没
在快速发展的数字化潮流之下,无论是终端用户、 内容创作、混合工作模式,还是计算设备、智能设施、智慧城市,都持续催生着海量的数据。从终端、边缘到数据中心所产生的数据都在快速增长,大家正加速步入ZB时代。数据增长之快,用户应用创新变化之快,各种挑战多多,唯有突破技术壁垒,才能满足用户多样化的存储需求。
在大容量硬盘的创新技术方面,西部数据一直非常认真而努力。虽然我们已经知道西部数据拥有了值得一提的能量辅助磁记录(ePMR)、三阶寻轨定位系统(TSA)、氦气封装(HelioSeal)技术,但是突破HDD技术壁垒,OptiNAND技术“杀手锏”功不可没。加上全新的UltraSMR技术增光添彩,可以实现用户在数据存储领域更多的可能。值得一提的是,在大容量硬盘革新的未来之路上,西部数据已经确认将基于ePMR来实现30+TB存储容量的未来发展方向。
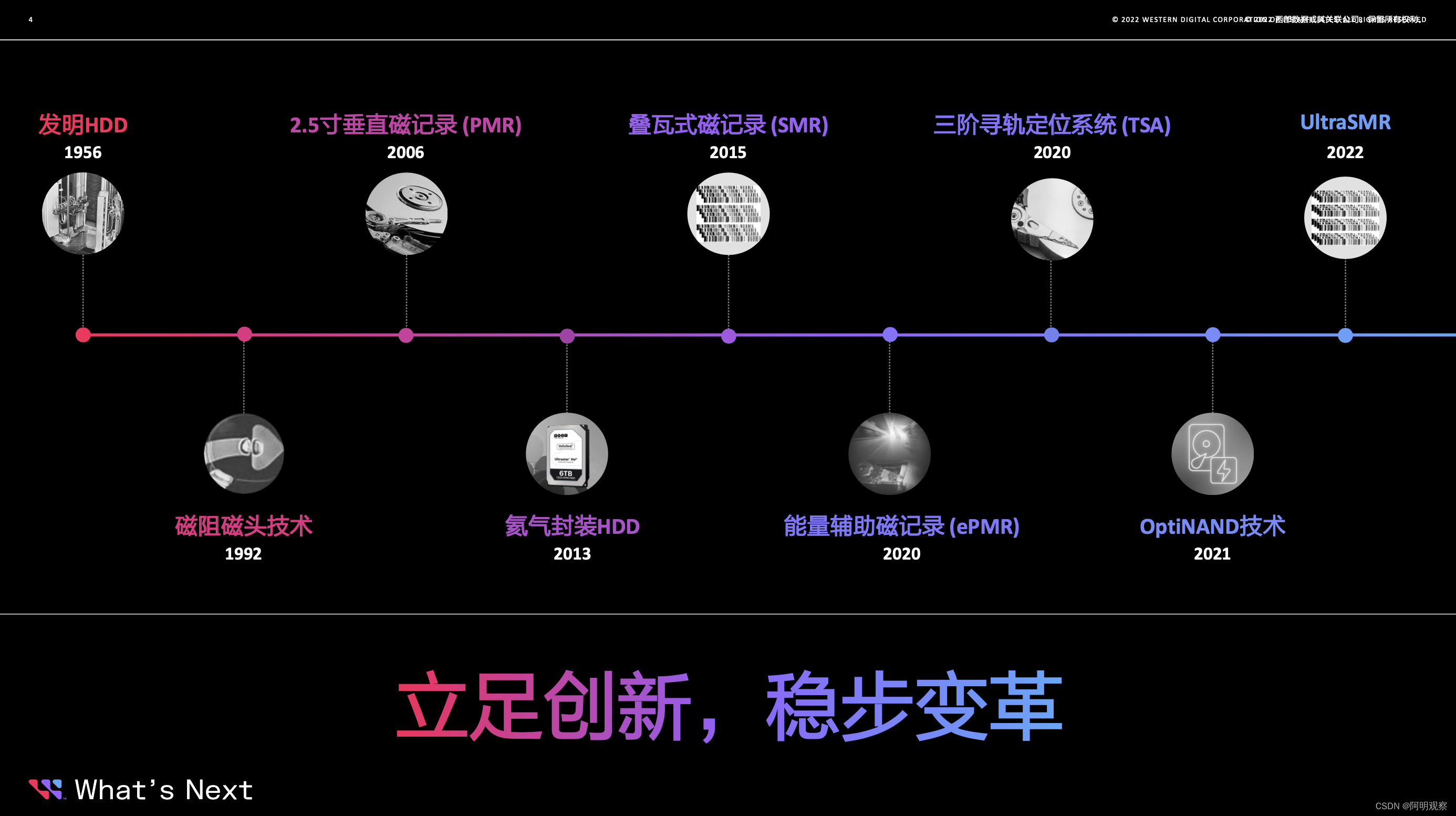
进一步分析来看,OptiNAND是相对独立于底层的技术路线,目前来看,基于全新的产品组合,有助于西部数据实现更多差异化竞争的优势。
与之前大家熟悉的混合式驱动器(SSHD)非常不一样,OptiNAND不会在正常运行期间存储任何用户数据,而是存储来自HDD操作的元数据,从而实现容量、性能与可靠性的更好提升。OptiNAND带来了很大的优势,当真正出现断电数据损耗时,OptiNAND可以写入多几十倍数据,进一步提高可靠性。在OptiNAND加持之下,让UltraSMR提高20%的容量成为可能,这是采用传统磁盘技术很难做到的事情。
西部数据将OptiNAND技术与采用HDD系统级硬件优势的专有固件相结合,尤其是SMR技术结合在一起,推出全新UltraSMR技术,并引入了大数据块编码和先进的纠错算法,增加了每英寸磁道数(TPI),从而实现更高的容量。这里需要明确一下技术迭代带来的容量提升优势,相比CMR,SMR记录技术革新可使得存储容量增加约10%。相比CMR,UltraSMR可使得存储容量提升超过20%。
全新的ePMR HDD利用西部数据的OptiNAND技术,将HDD的存储容量、性能和数据弹性提升至新的高度。22TB CMR HDD采用了OptiNAND技术,在成熟的单碟2.2TB的氦气封装技术上实现了10碟更高的面密度。
新推出的26TB Ultrastar DC HC670 UltraSMR HDD可提供单碟2.6TB 的容量,为云服务提供商优化其堆栈来实现SMR技术优势带来了约18%的容量提升。随着越来越多的云服务提供商将SMR添加到他们的数据中心发展路线之中,26TB的容量点创新将成为他们加快部署的一个重要转折点。
OptiNAND融入到了HDD产品创新中,这也是西部数据同时拥有的闪存技术共同融合的结果。但是,不同于把NAND用SSD FLASH做缓存数据,OptiNAND存储的包括HDD内部很多操作的数据,来快速操作寻道,而且在断电时,能够把一些关键数据瞬间转存到NAND里面,既提高了容量、面密度,又得到了更好的性能。
对于搭载OptiNAND技术的HDD而言,还包括了ArmorCache写缓存数据安全功能,为客户提供写缓存启用 (WCE)的性能和写缓存禁用(WCD)的数据保护,在紧急断电(EPO)的情况下提升数据保护能力。
在HDD技术发展历程中,这种写缓存数据安全功能首次实现了无论在何种模式下,都能在保证性能的同时兼具数据保护能力。OptiNAND技术能使HDD在WCD模式下有明显的性能提升,这在较大数据块的随机写入中最为明显。在常见256KB或更高的传输带宽场景下,相对比非OptiNAND HDD,IOPS和吞吐量提高了约40%。在1MB的传输带宽下,峰值性能提高约80%。
由此可见,应对诸多存储挑战,进一步挖掘和实现数据的价值,拥有了OptiNAND、ePMR、TSA、HelioSeal、UltraSMR等技术杀手锏的西部数据,就是不一样。
生态至上,行业生态与地球生态两不误
借助技术、产品、方案的创新,西部数据帮助企业发掘数据价值,创造更多可能,但其中还离不开在生态合作上的整体构建,共同携手,推动技术与产品创新,加速新技术落地。
特别是针对数字新基建的发展,西部数据对于国内合作伙伴的支持有了更多细化与深入的策略。对于超聚变、百度云等合作伙伴而言,在服务器存储以及云计算等产品创新上,西部数据给予更贴心的支持。帮助合作伙伴能够在第一时间接触到新技术、新产品,并且加快验证和引入的过程,会提高服务器厂商或者云服务商提供的服务器产品或云服务的竞争力。因此在硬件验证部分西部数据会第一时间提供紧密的技术支持,助力合作伙伴的发展。
当然在新技术的引入上,西部数据给予更开放的帮助。当合作伙伴引入UltraSMR时,会需要对上层存储的访问软件进行适当的优化。在这里,西部数据有支持开源软件社区做SMR的软件开发,使云服务商或者服务器厂商实现部分软件的优化,同时开源社区也会提供SI、ISB这类的开源软件。
此外,在云服务商和服务厂商部署时,西部数据会提供更进一步优化支持,让用户不仅能很好地应用22TB Ultrastar DC HC570,还可以应用UltraSMR技术的26TB DC HC670,以最大化地实现新技术带来的价值。
致力于用户数字化转型与升级,西部数据加快传统硬盘与闪存的技术突破,推出更为丰富的产品组合,目前已经和国际、国内云服务商和服务器制造商有深度合作。国内已经和包括百度云、超聚变在内的云服务商和服务器制造商以及其他企业级客户进行密切沟通合作,加速推进22TB CMR HDD的测试与部署。未来也将与更多本土合作伙伴开展深度合作,为整个存储市场和行业生态提供更优化的存储解决方案,进一步赋能用户挖掘数据价值,创造更多发展可能。
与此同时,在另一个生态构建上,西部数据积极履行对于地球、社会和人类发展的责任,将可持续发展作为公司核心价值观,积极投入实际行动中与业界共同构建绿色地球生态。在全球布局的智能化工厂,通过采用数据驱动的工厂管理系统、机器学习等先进技术,不断提高可持续性水平,目前位于亚洲的两座工厂也入选了世界经济论坛全球灯塔工厂网络。通过深刻理解应对气候变化的紧迫性,设立符合(Science Based Targets initiative, SBTi)标准的碳减排目标,将继续践行对未来世界和人类可持续发展的一贯承诺。
由此而言,行业生态与地球生态两不误,西部数据不仅是一个全球知名的存储公司,同时也是一个重视地球绿色生态发展的积极实践者。
(by Aming)
- END-
你
怎
么
看
?
欢迎文末评论补充!
【全球存储观察 | 科技明说】专注科技公司分析,用数据说话,带你看懂科技。本文和作者回复仅代表个人观点,不构成任何投资建议。
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在编写一个简单的静态Rack应用程序。查看下面的config.ru代码:useRack::Static,:urls=>["/elements","/img","/pages","/users","/css","/js"],:root=>"archive"map'/'dorunProc.new{|env|[200,{'Content-Type'=>'text/html','Cache-Control'=>'public,max-age=6400'},File.open('archive/splash.html',File::RDONLY)]}endmap'/pages/search.
我去了这个website查看Rails5.0.0和Rails5.1.1之间的区别为什么5.1.1不再包含:config/initializers/session_store.rb?谢谢 最佳答案 这是删除它的提交:Setupdefaultsessionstoreinternally,nolongerthroughanapplicationinitializer总而言之,新应用没有该初始化器,session存储默认设置为cookie存储。即与在该初始值设定项的生成版本中指定的值相同。 关于
我正在关注Hartl的railstutorial.org并已到达11.4.4:Imageuploadinproduction.我做了什么:注册亚马逊网络服务在AmazonIdentityandAccessManagement中,我创建了一个用户。用户创建成功。在AmazonS3中,我创建了一个新存储桶。设置新存储桶的权限:权限:本教程指示“授予上一步创建的用户读写权限”。但是,在存储桶的“权限”下,未提及新用户名。我只能在每个人、经过身份验证的用户、日志传送、我和亚马逊似乎根据我的名字+数字创建的用户名之间进行选择。我已经通过选择经过身份验证的用户并选中了上传/删除和查看权限的框(而不
我正在使用mechanize登录网站,然后检索页面。我遇到了一些问题,我怀疑这是由于cookie中的某些值造成的。当Mechanize登录网站时,我假设它存储了cookie。如何通过Mechanize打印出存储在cookie中的所有数据? 最佳答案 代理有一个cookie方法。agent=Mechanize.newpage=agent.get("http://www.google.com/")agent.cookiesagent.cookies.to_scookie返回一个Mechanize::Cookiesobject
我以为它们存储在cookie中-但不,检查cookie没有任何结果。session也不存储它们。那么,我在哪里可以找到它们?我需要这个来直接设置它们(而不是通过flashhash)。 最佳答案 它们存储在inyoursessionstore.自rails2.0以来的默认设置是cookie存储,但请检查config/initializers/session_store.rb以检查您是否使用默认设置以外的东西。 关于ruby-on-rails-闪存消息存储在哪里?,我们在StackOverf
我正在学习Ruby,遇到了inject。我正处于理解它的风口浪尖,但当我是那种需要真实世界的例子来学习一些东西的人时。我遇到的最常见的例子是人们使用inject来添加一个(1..10)范围的总和,我不太关心这个。这是一个任意的例子。在实际程序中我会用它做什么?我正在学习,所以我可以继续使用Rails,但我不必有一个以Web为中心的示例。我只需要一些我可以全神贯注的目标。谢谢大家。 最佳答案 inject有时可以通过它的“其他”名称reduce更好地理解。它是一个对Enumerable进行操作(迭代一次)并返回单个值的函数。它有许多有
对于我正在编写的Rails3应用程序,我正在考虑从本地文件系统上的XML、YAML或JSON文件中读取一些配置数据。重点是:我应该把这些文件放在哪里?Rails应用程序中是否有用于存储此类内容的默认位置?附带说明一下,我的应用程序部署在Heroku上。 最佳答案 我经常做的是:如果文件是通用配置文件:我在目录/config中创建一个YAML文件,每个环境有一个上层key如果我为每个环境(大项目)创建一个文件:我为每个环境创建一个YAML并将它们存储在/config/environments/然后我在加载YAML的地方创建了一个初始化
有没有办法将RubyVM::InstructionSequence存储到文件中并稍后读取?我尝试了Marshal.dump但没有成功。我收到以下错误:`dump':no_dump_dataisdefinedforclassRubyVM::InstructionSequence(TypeError) 最佳答案 是的,有办法。首先,您需要使InstructionSequence的load方法可访问,默认情况下该方法是禁用的:require'fiddle'classRubyVM::InstructionSequence#RetrieveR
下面是我用来从应用程序中解析CSV的代码,但我想解析位于AmazonS3存储桶中的文件。当推送到Heroku时它也需要工作。namespace:csvimportdodesc"ImportCSVDatatoInventory."task:wiwt=>:environmentdorequire'csv'csv_file_path=Rails.root.join('public','wiwt.csv.txt')CSV.foreach(csv_file_path)do|row|p=Wiwt.create!({:user_id=>row[0],:date_worn=>row[1],:inven