- paper: Don't stop Pretraining: Adapt Language Models to Domains and Tasks
- GitHub: https://github.com/allenai/dont-stop-pretraining
论文针对预训练语料和领域分布,以及任务分布之间的差异,提出了DAPT领域适应预训练(domain-adaptive pretraining)和TAPT任务适应预训练(task-adaptive pretraining)两种继续预训练方案,并在医学论文,计算机论文,新闻和商品评价4个领域上进行了测试。想法很简单就是在垂直领域上使用领域语料做继续预训练,不过算是开启了新的训练范式,从之前的pretrain+fintune,到pretrain+continue pretrain+finetune
核心要点主要有以下4个
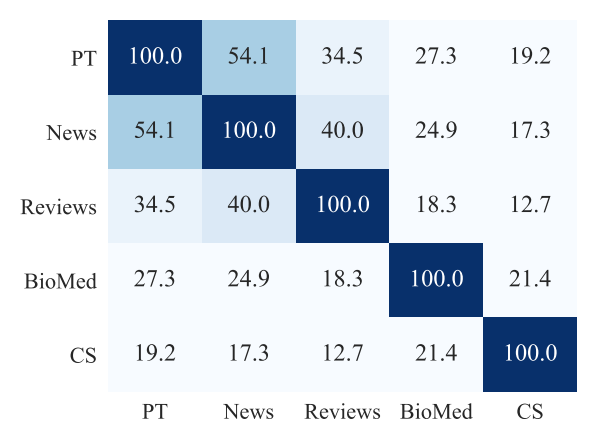
首先作者通过每个领域内的Top10K高频词的重合度,来衡量领域之间,以及领域和预训练语料的文本相似度,相似度News>Reviews>Bio>CS。我们预期DAPT的效果会和相似度相关,理论上在相似度低的领域,继续预训练应该带来更大的提升。
训练部分作者复用了Roberta的预训练方案。为了保证4个领域可比,作者通过样本采样,以及不同的batch size保证了4个领域的step相同。为了防止灾难遗忘,作者只在领域数据上继续训练了1个epoch(12.5K steps)。除了News领域,其他领域的继续预训练都带来了MLM Loss的下降。
在下游分类任务微调中,继续训练的模型效果都显著优于原始Roberta,和预训练语料差异更大的领域CS,Bio整体的效果提升更显著,如下
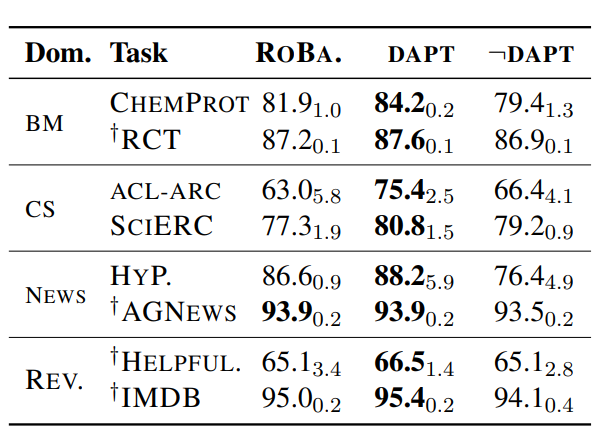
为了剔除更多的训练样本可能带来的效果提升,作者按以上的语料相关性,每个领域都选择了相关性最低的另一个领域的继续预训练模型(¬DAPT),对比在下游微调中的效果,部分场景有提升部分有下降,但是都显著低于对应领域的继续预训练模型,从而进一步证明继续预训练的收益来自对应领域信息的补充。
TAPT是使用任务样本直接进行继续训练。Task Adaptive和Domain Adaptive的主要区别是,Task对应的数据集更小训练成本更低,不过因为直接使用任务数据,所以和任务的相关度更高。对应以上DAPT训练1个epoch(12.5K steps), TAPT训练100个epoch,每个epochs使用15%的Random Delete来进行样本增强。
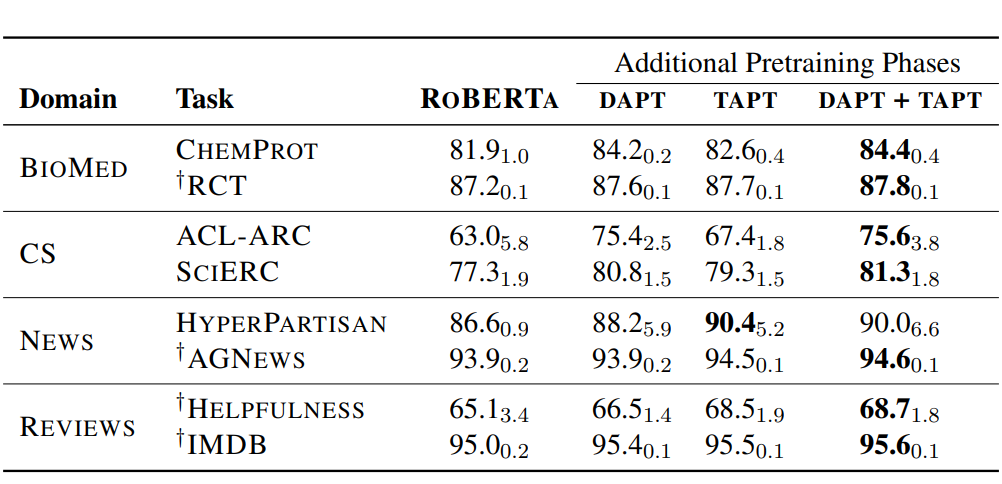
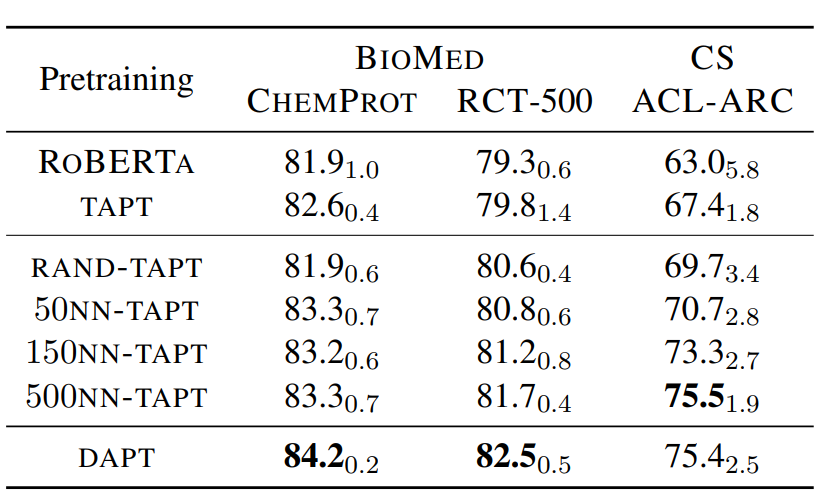
作者对比了只使用DAPT,TAPT以及先使用DAPT+TAPT的效果:整体上DAPT+TAPT的继续预训练效果最好。其中针对更加垂直(和预训练语料相关性更小)的领域DAPT更好。感觉主要是因为领域垂直,TAPT受限于样本量能提供的领域信息不足,容易过拟和。而和预训练语料更相似的新闻领域和评论领域,TAPT的效果甚至超过DAPT,如下
作者进一步尝试了Cross Task Transfer,就是使用相同领域中任务1做继续预训练,然后在任务2上进行微调。效果显著低于使用相同任务的语料做T继续训练,这进一步说明了相同领域不同任务间的语料分布也是存在差异的,所以在部分任务上TAPT的效果要优于DAPT。
那能否在保留当前任务分布的前提下,拓展任务相关语料,解决TAPT样本量不足的问题呢?比较直观的方案就是使用文本Embedding,从相同领域的样本中,使用KNN抽取任务对应的K个相似样本来扩充任务样本。作者使用的是词袋模型VAMPIRE来计算文本表征,对比了不同参数K的效果,500KNN已经逼近DAPT。如果你有耐心>_<的话,KNN配合TAPT确实算是更优的方案,它的预训练成本显著低于DAPT,但又比TAPT的效果以及泛化性要显著更好
说了半天继续预训练可以提高下游任务的效果,不过究竟继续预训练干了啥??这部分在作者也没有很详细的证明,所以我们只能借助相关paper来猜想一哈~
总结下,针对单任务模型,直接使用TAPT成本最低实用性最高,针对领域底层大模型,使用DAPT效果更好。不过使用起来具体使用哪种预训练方案,以及如何避免灾难遗忘,感觉还是要case by case的来看。一些相关的案例有
最近在复现一些比赛方案时,尝试了下在金融负面主体这个任务中引入TAPT,因为是实体相关的情感分类问题,因此在TAPT上使用了Whole Word和Entity粒度结合的MLM作为预训练目标。在使用多任务的基础上,使用TAPT进一步训练后F1进一步有0.2%个点的提升,不过这个提升只有当预训练使用全部语料的时候才显著,如果和下游微调一样保留部分数据用于测试,则不会有显著的效果提升,这里的效果对比更支持上面的提高模型泛化能力这个假设~具体实现详见ClassicSolution/fin_neg_entity
BERT手册相关论文和博客详见BertManual
在神经网络方面,我完全是个初学者。我整天都在与ruby-fann和ai4r搏斗,不幸的是我没有任何东西可以展示,所以我想我会来到StackOverflow并询问这里的知识渊博的人。我有一组样本——每天都有一个数据点,但它们不符合我能够找出的任何明确模式(我尝试了几次回归)。不过,我认为看看是否有任何方法可以仅从日期预测future的数据会很好,而且我认为神经网络将是生成希望表达这种关系的函数的好方法.日期是DateTime对象,数据点是十进制数,例如7.68。我一直在将DateTime对象转换为float,然后除以10,000,000,000得到一个介于0和1之间的数字,我一直在将
我有在服务器上运行的代码,在服务器硬关闭之前,发送了一个信号SIGTERM让我的代码知道它需要清理。我想在发生这种情况时运行代码并将信号发送回同一个程序,以便任何其他需要清理的代码都可以这样做。我不想捕获信号或改变信号行为,我只需要在我的程序的其余部分解释SIGTERM之前运行一些东西。目前我可以做类似的事情Signal.trap('TERM')doputs"Gracefulshutdown"exitend但如果同一个应用中的多段代码试图做同样的事情,它就不起作用了。例如:Signal.trap('TERM')doputs"Gracefulshutdown"exitendSignal.
我正在尝试训练一个前馈网络来使用Ruby库AI4R执行异或运算。然而,当我在训练后评估XOR时。我没有得到正确的输出。有没有人以前使用过这个库并得到它来学习异或运算。我使用了两个输入神经元,一个隐藏层中的三个神经元,一个输出层,正如我看到的预计算XOR前馈神经网络就像这样。require"rubygems"require"ai4r"#Createthenetworkwith:#2inputs#1hiddenlayerwith3neurons#1outputsnet=Ai4r::NeuralNetwork::Backpropagation.new([2,3,1])example=[[0,
关于yolov5训练时参数workers和batch-size的理解yolov5训练命令workers和batch-size参数的理解两个参数的调优总结yolov5训练命令python.\train.py--datamy.yaml--workers8--batch-size32--epochs100yolov5的训练很简单,下载好仓库,装好依赖后,只需自定义一下data目录中的yaml文件就可以了。这里我使用自定义的my.yaml文件,里面就是定义数据集位置和训练种类数和名字。workers和batch-size参数的理解一般训练主要需要调整的参数是这两个:workers指数据装载时cpu所使
我想在Rails中打印出以逗号分隔的链接列表。这是我得到的:">,这是我想要的:ThingA,ThingB,ThingC但是现在我在循环的最后一次迭代中得到了一个额外的逗号!我该怎么办? 最佳答案 一种方法是使用map然后Array#join: 关于ruby-on-rails-Rails中每个循环的最后一次迭代不要有逗号,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/266957
1.深度优先搜索(DFS)深度优先遍历主要思路是从图中一个未访问的顶点V开始,沿着一条路一直走到底,然后从这条路尽头的节点回退到上一个节点,再从另一条路开始走到底…,不断递归重复此过程,直到所有的顶点都遍历完成。例题P1605迷宫题目描述给定一个N×MN\timesMN×M方格的迷宫,迷宫里有TTT处障碍,障碍处不可通过。在迷宫中移动有上下左右四种方式,每次只能移动一个方格。数据保证起点上没有障碍。给定起点坐标和终点坐标,每个方格最多经过一次,问有多少种从起点坐标到终点坐标的方案。输入格式第一行为三个正整数N,M,TN,M,TN,M,T,分别表示迷宫的长宽和障碍总数。第二行为四个正整数SX,S
如何为super调用设置一个block为nil?classAdeffooifblock_given?result=yield#dostuffwiththeyieldresultend#somemorecodeendendclassBblockcalled#=>blockcalled我不想让block两次。block_given?在类A中是否有可能返回false?背景是我不拥有A类,我无法更改它的foo方法,但我想避免调用我的block两次。我也不想将虚拟/空block传递给super,因为A的foo方法的行为在给定block时发生变化。 最佳答案
绝对详细的RabbitMQ实践操作手册,看完本系列就够了。一、什么是MQ?1、MQ的概念2、理解消息队列二、MQ的优势和劣势1、优势和作用2、劣势三、MQ的应用场景四、AMQP五、工作原理一、什么是MQ?1、MQ的概念MQ全称MessageQueue(消息队列),是在消息的传输过程中保存消息的容器。多用于系统之间的异步通信。下面用图来理解异步通信,并阐明与同步通信的区别。同步通信:甲乙两人面对面交流,你一句我一句必须同步进行,两人除此之外不做任何事情异步通信:异步通信相当于通过第三方转述对话,可能有消息的延迟,但不需要二人时刻保持联系,消息传给第三方后,两人可以做其他自己想做的事情,当需要获取
如果我尝试在具有require'xxx'语句的Ruby文件中自动完成smth,它会开始扫描所需的所有文件(以及所需文件所需的文件)。而且它每次都怪怪的!是否可以让vim自动完成不扫描所需文件或只扫描特定路径中的文件(例如app/only)? 最佳答案 以下其中一项应该有效:setpath=.,/myinclude1,/myinclude2设置自己的包含路径:setcomplete-=i禁止在默认补全中使用包含的文件:setinclude=取消设置包含文件匹配模式我建议你使用第二个,这样CTRL-XCTRL-I仍然可以正常工作
ruby-1.8.7-p249>xml=Builder::XmlMarkup.new=>ruby-1.8.7-p249>xml.foo'wow'=>"<b>wow</b>"ruby-1.8.7-p249>Builder正在转义内容并将b标记转换为转义值。我如何告诉Builder不要逃避它?我正在使用Ruby1.8.7。 最佳答案 Builder::XmlMarkup#xml.foodoxmlwow'end 关于ruby-on-rails-如何告诉Builder不要