包含27种类型的遥感地物目标
提取自Google Earth
由西北工业大学于2016年发布
采用oriented bounding boxes(OBB)标注格式
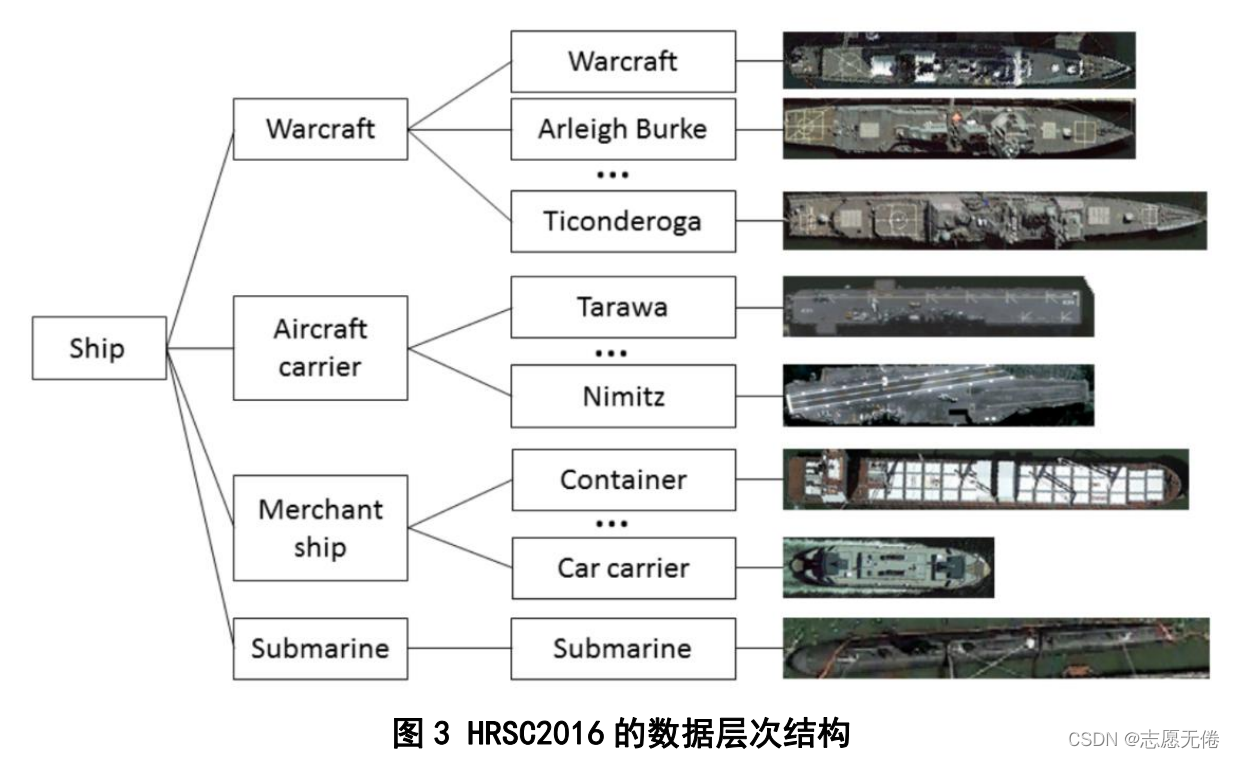
HRSC2016 (Liu et al.,2016)是西北工业大学采集的用于轮船的检测的数据,包含4个大类19个小类共2976个船只实例信息。论文中特别指出他们的数据集是高分辨率数据集,分辨率介于0.4m和2m之间。数据集所有图像均来自六个著名的港口,包括海上航行的船只和靠近海岸的船只,船只图像的尺寸范围从300到1500,大多数图像大于1000x600。
<HRSC_Image>
<Img_CusType>sealand</Img_CusType>
<Img_Location>69.040297,33.070036</Img_Location>
<Img_SizeWidth>1138</Img_SizeWidth>
<Img_SizeHeight>833</Img_SizeHeight>
<Img_SizeDepth>3</Img_SizeDepth>
<Img_Resolution>1.07</Img_Resolution>
<Img_Resolution_Layer>18</Img_Resolution_Layer>
<Img_Scale>100</Img_Scale>
<segmented>0</segmented>
<Img_Havemask>0</Img_Havemask>
<Img_Rotation>274d</Img_Rotation>
<HRSC_Objects>
<HRSC_Object>
<Object_ID>100000008</Object_ID>
<Class_ID>100000013</Class_ID>
<Object_NO>100000008</Object_NO>
<truncated>0</truncated>
<difficult>0</difficult>
<box_xmin>628</box_xmin>//bounding box坐标点
<box_ymin>40</box_ymin>
<box_xmax>815</box_xmax>
<box_ymax>783</box_ymax>
<mbox_cx>719.9324</mbox_cx>//旋转后的左上角坐标
<mbox_cy>413.0048</mbox_cy>
<mbox_w>741.8246</mbox_w>
<mbox_h>172.6959</mbox_h>
<mbox_ang>1.499893</mbox_ang>//旋转角度
<segmented>0</segmented>
<seg_color>
</seg_color>
<header_x>713</header_x>//船头部信息
<header_y>777</header_y>
</HRSC_Object>
</HRSC_Objects>
</HRSC_Image>

import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[ ('2007', 'test')]
classes = ["ship"]
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
# 转换这一张图片的坐标表示方式(格式),即读取xml文件的内容,计算后存放在txt文件中
in_file = open('./data/VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('./data/VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
# size = root.find('size')
w = int(root.find('Img_SizeWidth').text)
h = int(root.find('Img_SizeHeight').text)
if root.find('HRSC_Objects'):
for obj in root.iter('HRSC_Object'):
difficult = obj.find('difficult').text
cls = 'ship'
# cls = obj.find('name').text
# if cls not in classes or int(difficult) == 1:
if int(difficult) == 1:
continue
cls_id = classes.index(cls)
# xmlbox = obj.find('bndbox')
b = (float(obj.find('box_xmin').text), float(obj.find('box_xmax').text), float(obj.find('box_ymin').text), float(obj.find('box_ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('./data/VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('./data/VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('./data/VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('./data/%s/VOCdevkit/VOC%s/JPEGImages/%s.bmp\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
image size:300 × 300 ~ 1500 × 900
image number:1061 在训练集、验证集和测试集中分别包含436、181和444张图像
object number:2976
https://aistudio.baidu.com/aistudio/datasetdetail/54106
本文参考
CSDN博主「Marlowee」的原创文章,遵循CC 4.0 BY-SA版权协议,附上
原文链接:https://blog.csdn.net/weixin_43427721/article/details/122057389
我想将html转换为纯文本。不过,我不想只删除标签,我想智能地保留尽可能多的格式。为插入换行符标签,检测段落并格式化它们等。输入非常简单,通常是格式良好的html(不是整个文档,只是一堆内容,通常没有anchor或图像)。我可以将几个正则表达式放在一起,让我达到80%,但我认为可能有一些现有的解决方案更智能。 最佳答案 首先,不要尝试为此使用正则表达式。很有可能你会想出一个脆弱/脆弱的解决方案,它会随着HTML的变化而崩溃,或者很难管理和维护。您可以使用Nokogiri快速解析HTML并提取文本:require'nokogiri'h
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我有一个对象has_many应呈现为xml的子对象。这不是问题。我的问题是我创建了一个Hash包含此数据,就像解析器需要它一样。但是rails自动将整个文件包含在.........我需要摆脱type="array"和我该如何处理?我没有在文档中找到任何内容。 最佳答案 我遇到了同样的问题;这是我的XML:我在用这个:entries.to_xml将散列数据转换为XML,但这会将条目的数据包装到中所以我修改了:entries.to_xml(root:"Contacts")但这仍然将转换后的XML包装在“联系人”中,将我的XML代码修改为
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
这个问题在这里已经有了答案:Railsformattingdate(4个答案)关闭4年前。我想格式化Time.Now函数以显示YYYY-MM-DDHH:MM:SS而不是:“2018-03-0909:47:19+0000”该函数需要放在时间中.现在功能。require‘roo’require‘roo-xls’require‘byebug’file_name=ARGV.first||“Template.xlsx”excel_file=Roo::Spreadsheet.open(“./#{file_name}“,extension::xlsx)xml=Nokogiri::XML::Build
我喜欢使用Textile或Markdown为我的项目编写自述文件,但是当我生成RDoc时,自述文件被解释为RDoc并且看起来非常糟糕。有没有办法让RDoc通过RedCloth或BlueCloth而不是它自己的格式化程序运行文件?它可以配置为自动检测文件后缀的格式吗?(例如README.textile通过RedCloth运行,但README.mdown通过BlueCloth运行) 最佳答案 使用YARD直接代替RDoc将允许您包含Textile或Markdown文件,只要它们的文件后缀是合理的。我经常使用类似于以下Rake任务的东西:
给定一个复杂的对象层次结构,幸运的是它不包含循环引用,我如何实现支持各种格式的序列化?我不是来讨论实际实现的。相反,我正在寻找可能会派上用场的设计模式提示。更准确地说:我正在使用Ruby,我想解析XML和JSON数据以构建复杂的对象层次结构。此外,应该可以将该层次结构序列化为JSON、XML和可能的HTML。我可以为此使用Builder模式吗?在任何提到的情况下,我都有某种结构化数据-无论是在内存中还是文本中-我想用它来构建其他东西。我认为将序列化逻辑与实际业务逻辑分开会很好,这样我以后就可以轻松支持多种XML格式。 最佳答案 我最
是否有简单的方法来更改默认ISO格式(yyyy-mm-dd)的ActiveAdmin日期过滤器显示格式? 最佳答案 您可以像这样为日期选择器提供额外的选项,而不是覆盖js:=f.input:my_date,as::datepicker,datepicker_options:{dateFormat:"mm/dd/yy"} 关于ruby-on-rails-事件管理员日期过滤器日期格式自定义,我们在StackOverflow上找到一个类似的问题: https://s
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD