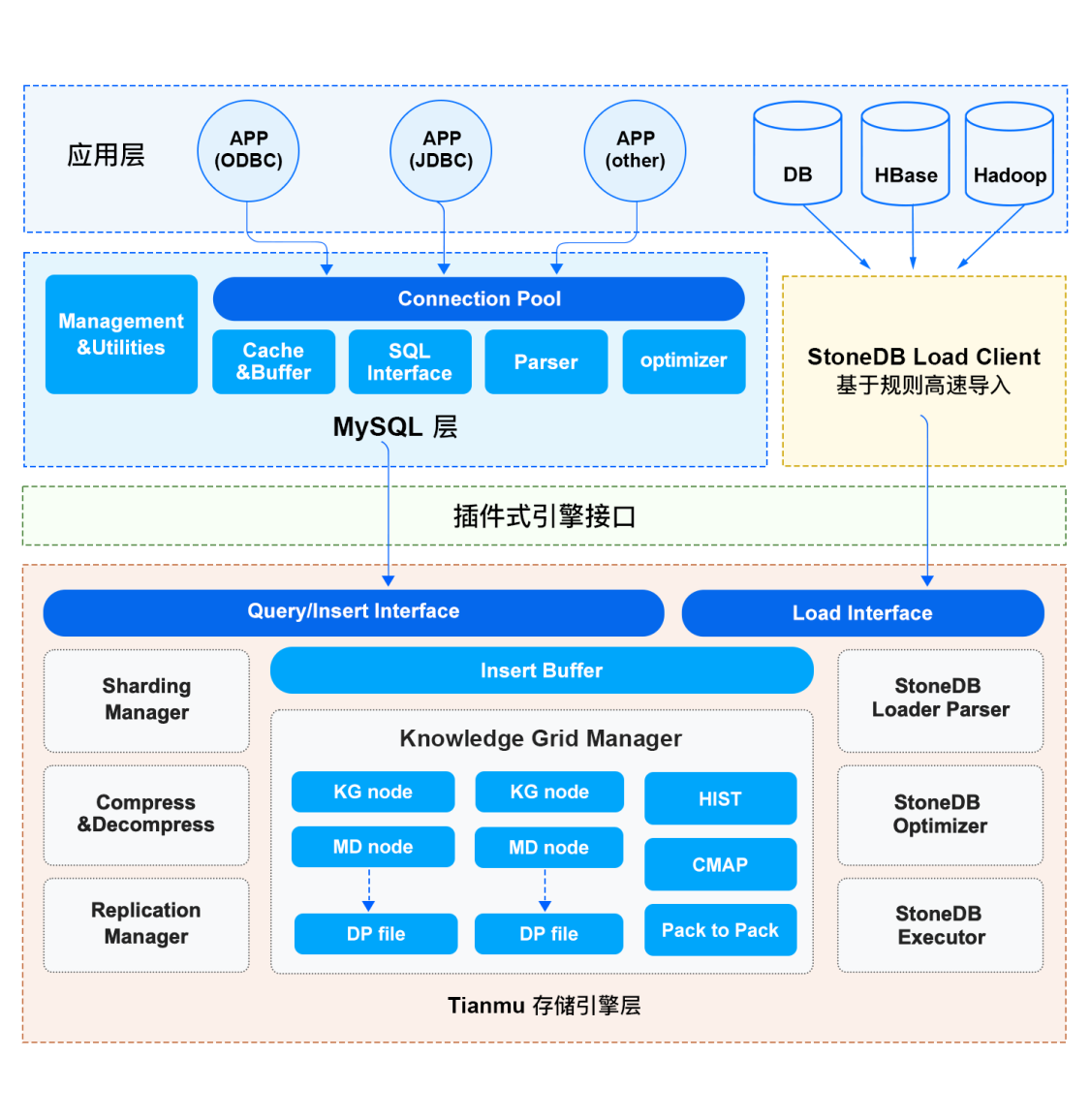
StoneDB 的整体架构分为三层,分别是应用层、服务层和存储引擎层。应用层主要负责客户端的连接管理和权限验证;服务层提供了 SQL 接口、查询缓存、解析器、优化器、执行器等组件;Tianmu 引擎所在的存储引擎层是 StoneDB 的核心,数据的组织和压缩、以及基于知识网格的查询优化均是在 Tianmu 引擎实现。下面为大家详细介绍 StoneDB 整体架构中的主要特性。
StoneDB 创建的表在磁盘上是以列模式进行存储的,由于关系型数据库中每一列的数据类型都相同,所以这种连续的空间存储与行式存储相比,更加能够实现数据的高压缩比。在读取数据方面,如果只想查询一个字段的结果,在行式存储中,引擎层向服务层返回的是一整行的数据,需要消耗更多的网络带宽和 IO。而列式存储只需要返回一个字段,极大减少了网络带宽和 IO 的消耗。另外,列式存储无需再为列创建索引和维护索引。
| id | name | age |
|---|---|---|
| 1 | Jack | 37 |
| 2 | Rose | 18 |
| 3 | Jason | 26 |

上面提到同一数据类型的列存储在一起,能够实现数据的高压缩比。StoneDB 会根据不同的数据类型选择不同的压缩算法,目前支持的压缩算法主要有 PPM、LZ4、B2、Delta 等。数据被压缩后,数据量变得更小,在读取数据时,对网络带宽和磁盘 IO 的压力也就越小。由于列式存储相比行式存储有十倍甚至更高的压缩比,StoneDB 可以节省大量的存储空间,降低存储成本。
当表的数据量达到千万、亿级,在做统计分析类查询时,使用 MySQL 的 InnoDB 存储引擎或其它关系型数据库的行式存储引擎可能需要几分钟到几十分钟才能得到结果集。这是因为基于成本的优化器需要根据表或者索引的统计信息生成执行计划,然后再去读取数据,中间过程会发生 IO,如果统计信息不准,生成了一个错误的执行计划,那么可能会发生更多的 IO。而 StoneDB 的 Tianmu 引擎在相同的数据量下,比 MySQL 的 InnoDB 存储引擎或或其它关系型数据库的行式存储引擎要快数十倍。Tianmu 引擎除了列式存储、数据压缩特性外,还有知识网格技术。在了解知识网格前,需要了解以下几个基本概念。
数据包用于存放实际数据,是最底层的数据存储单元,每列按照65536行切分成一个数据包。每个数据包比列更小,具有更高的压缩比,而每个数据包又比每行更大,具有更好的查询性能。数据包是知识网格的解压缩单元。
粗糙集是一门数学学科,用来研究不完整的数据,不精确的知识表达、学习、归纳等的一套理论。在 StoneDB 中,粗糙集用于对数据包的划分,根据 SQL 的查询条件的数据在数据包中的确认范围,数据包分为以下几类:
1)不相关的数据包:表示不满足查询条件的数据包,这类数据包直接被忽略。
2)相关的数据包:表示满足查询条件的数据包,如果要查询相关的数据包里面的具体数据,需要对数据包进行解压缩,如果根据数据包的元数据节点就能得到数据,那么就不需要解压缩数据包。
3)可疑的数据包:表示数据包中的数据部分满足查询条件,需要进一步解压缩数据包才能得到满足条件的数据。
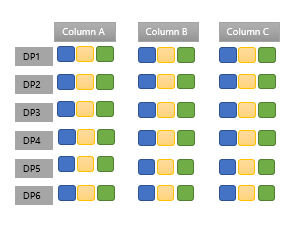
数据包节点也称为元数据节点,记录了每个数据包中列的最大值、最小值、平均值、总和、总记录数、null值的数量、压缩方式、占用的字节数。每一个元数据节点对应一个数据包。
元数据节点的上一层是知识节点,除了记录数据包之间或者列之间关系的元数据集合,比如数据包的最小值与最大值范围、列之间的关联关系外,还记录了数据特征以及更深度的统计信息。大部分的知识节点数据是装载数据的时候产生的,另外一部分是查询的时候产生的。
知识节点的3种基本类型:
数据类型为整型、日期型、浮点型的列的统计值以直方图的形式存在。将一个数据包的最小值到最大值之间分为1024段,每段占用一个 bit,如果数据包中的实际值处于段中的范围,则标记为1,否则标记为0。Histogam 在数据被加载时自动创建。
如下的例子中,说明数据包中有值落在0100和102301102400两个区间。
| 0‒100 | 101‒200 | 201‒300 | ... | 102301‒102400 |
|---|---|---|---|---|
| 1 | 0 | 0 | ... | 1 |
如果想要执行以下 SQL:
select * from table where id>199 and id<299;
通过直方图可知,这个查询没有在这个数据包命中,即当前数据包不满足查询条件,这个数据包直接被丢弃。
数据类型为字符串的列的字符映射表。统计当前数据包内 1~64 长度中 ASCII 字符是否存在。如果存在,则标记为1,否则标记为0。字符检索时,按照字符顺序依次对比字符标识值即可知道该数据包是否包含匹配数据。Character Map 在数据被加载时自动创建。
如下的例子中,说明 A 在字符串的第1个和第64个位置。
| Char/Char pos | 1 | 2 | ... | 64 |
|---|---|---|---|---|
| A | 1 | 0 | ... | 1 |
| B | 0 | 1 | ... | 0 |
| C | 1 | 1 | ... | 1 |
| ... | ... | ... | ... | ... |
包对包关系表示不同表的两个列之间的等值映射表,并以二进制矩阵的形式进行存储,如果符合表关联条件,则标记为1,否则标记为0。包对包关系能帮助在表关联查询的时候快速判断出符合查询条件的数据包,从而提升表关联查询的效率。表关联查询时,Pack to Pack 被自动创建。
如下的例子中,表关联的查询条件是"A.C=B.D",在 A.C1 这个数据包中,只有 B.D2 和 B.D5 这两个数据包中有符合表关联条件的值。
| B.D1 | B.D2 | B.D3 | B.D4 | B.D5 | |
|---|---|---|---|---|---|
| A.C1 | 0 | 1 | 0 | 0 | 1 |
| A.C2 | 1 | 1 | 0 | 0 | 0 |
| A.C3 | 1 | 1 | 0 | 1 | 1 |
知识网格由元数据节点和知识节点组成,在做统计分析类查询时,StoneDB 根据知识网格技术过滤掉不相关的数据包,如果只剩下相关数据包,那么只需要读取元数据就能返回查询结果。这样就消除了解压缩数据包的过程和降低 IO 消耗,提高了查询响应时间和网络利用率。
接下来,我们通过一个例子来理解一个查询语句在存储引擎层使用知识网格技术的查询优化过程。
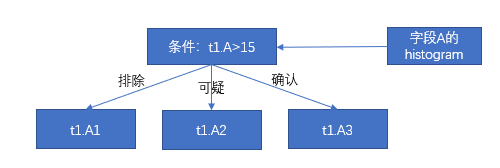
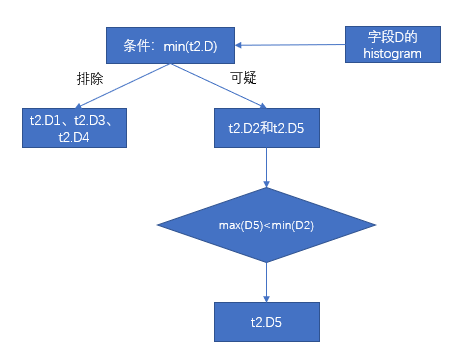
有如下的查询语句和数据包节点的数据值分布范围。
select min(t2.D) from t1,t2 where t1.B=t2.C and t1.A>15;
| Min. | Max. | |
|---|---|---|
| t1.A1 | 1 | 9 |
| t1.A2 | 10 | 30 |
| t1.A3 | 40 | 100 |
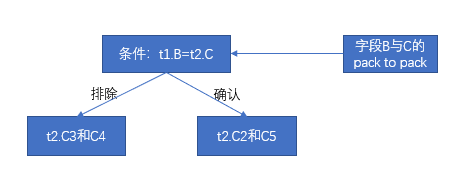
| t2.C1 | t2.C2 | t2.C3 | t2.C4 | t2.C5 | |
|---|---|---|---|---|---|
| t1.B1 | 1 | 1 | 1 | 0 | 1 |
| t1.B2 | 0 | 1 | 0 | 0 | 0 |
| t1.B3 | 1 | 1 | 0 | 0 | 1 |
| Min. | Max. | |
|---|---|---|
| t2.D1 | 0 | 500 |
| t2.D2 | 101 | 440 |
| t2.D3 | 300 | 6879 |
| t2.D4 | 1 | 432 |
| t2.D5 | 3 | 100 |
StoneDB 提供独立的数据导入客户端,支持不同的数据源环境,支持多语言架构。数据在导入前,首先会进行预处理,如数据压缩和知识节点的构建。数据经过预处理后,进入存储引擎无需再次执行解析、数据验证以及事务处理等操作。
于StoneDB的任何问题,都可以加我V咨询:StoneDB_2022 。
我有一个字符串input="maybe(thisis|thatwas)some((nice|ugly)(day|night)|(strange(weather|time)))"Ruby中解析该字符串的最佳方法是什么?我的意思是脚本应该能够像这样构建句子:maybethisissomeuglynightmaybethatwassomenicenightmaybethiswassomestrangetime等等,你明白了......我应该一个字符一个字符地读取字符串并构建一个带有堆栈的状态机来存储括号值以供以后计算,还是有更好的方法?也许为此目的准备了一个开箱即用的库?
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在使用ruby1.9解析以下带有MacRoman字符的csv文件#encoding:ISO-8859-1#csv_parse.csvName,main-dialogue"Marceu","Giveittohimóhe,hiswife."我做了以下解析。require'csv'input_string=File.read("../csv_parse.rb").force_encoding("ISO-8859-1").encode("UTF-8")#=>"Name,main-dialogue\r\n\"Marceu\",\"Giveittohim\x97he,hiswife.\"\
简而言之错误:NOTE:Gem::SourceIndex#add_specisdeprecated,useSpecification.add_spec.Itwillberemovedonorafter2011-11-01.Gem::SourceIndex#add_speccalledfrom/opt/local/lib/ruby/site_ruby/1.8/rubygems/source_index.rb:91./opt/local/lib/ruby/gems/1.8/gems/rails-2.3.8/lib/rails/gem_dependency.rb:275:in`==':und
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
@作者:SYFStrive @博客首页:HomePage📜:微信小程序📌:个人社区(欢迎大佬们加入)👉:社区链接🔗📌:觉得文章不错可以点点关注👉:专栏连接🔗💃:感谢支持,学累了可以先看小段由小胖给大家带来的街舞👉微信小程序(🔥)目录自定义组件-behaviors 1、什么是behaviors 2、behaviors的工作方式 3、创建behavior 4、导入并使用behavior 5、behavior中所有可用的节点 6、同名字段的覆盖和组合规则总结最后自定义组件-behaviors 1、什么是behaviorsbehaviors是小程序中,用于实现
遍历文件夹我们通常是使用递归进行操作,这种方式比较简单,也比较容易理解。本文为大家介绍另一种不使用递归的方式,由于没有使用递归,只用到了循环和集合,所以效率更高一些!一、使用递归遍历文件夹整体思路1、使用File封装初始目录,2、打印这个目录3、获取这个目录下所有的子文件和子目录的数组。4、遍历这个数组,取出每个File对象4-1、如果File是否是一个文件,打印4-2、否则就是一个目录,递归调用代码实现publicclassSearchFile{publicstaticvoidmain(String[]args){//初始目录Filedir=newFile("d:/Dev");Datebeg
ES一、简介1、ElasticStackES技术栈:ElasticSearch:存数据+搜索;QL;Kibana:Web可视化平台,分析。LogStash:日志收集,Log4j:产生日志;log.info(xxx)。。。。使用场景:metrics:指标监控…2、基本概念Index(索引)动词:保存(插入)名词:类似MySQL数据库,给数据Type(类型)已废弃,以前类似MySQL的表现在用索引对数据分类Document(文档)真正要保存的一个JSON数据{name:"tcx"}二、入门实战{"name":"DESKTOP-1TSVGKG","cluster_name":"elasticsear
我正在使用ruby2.1.0我有一个json文件。例如:test.json{"item":[{"apple":1},{"banana":2}]}用YAML.load加载这个文件安全吗?YAML.load(File.read('test.json'))我正在尝试加载一个json或yaml格式的文件。 最佳答案 YAML可以加载JSONYAML.load('{"something":"test","other":4}')=>{"something"=>"test","other"=>4}JSON将无法加载YAML。JSON.load("
我想用Nokogiri解析HTML页面。页面的一部分有一个表,它没有使用任何特定的ID。是否可以提取如下内容:Today,3,455,34Today,1,1300,3664Today,10,100000,3444,Yesterday,3454,5656,3Yesterday,3545,1000,10Yesterday,3411,36223,15来自这个HTML:TodayYesterdayQntySizeLengthLengthSizeQnty345534345456563113003664354510001010100000344434113622315