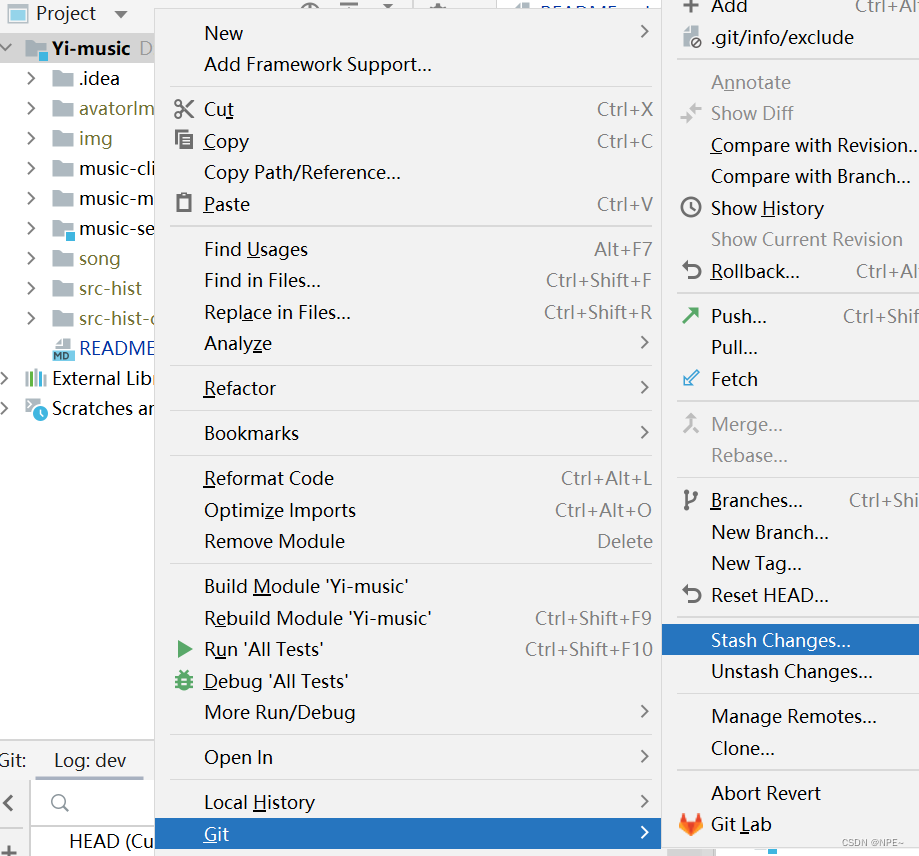
File - New - Project from Version Control
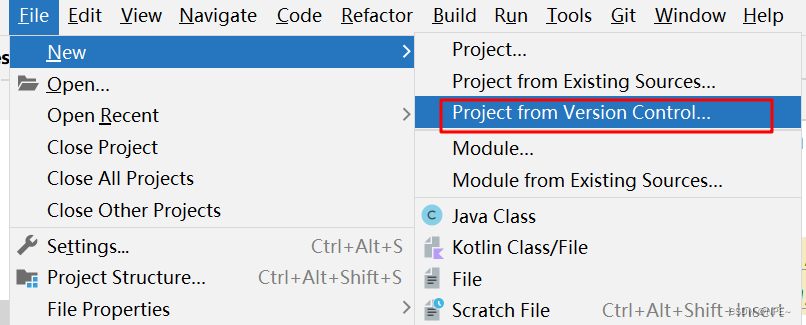
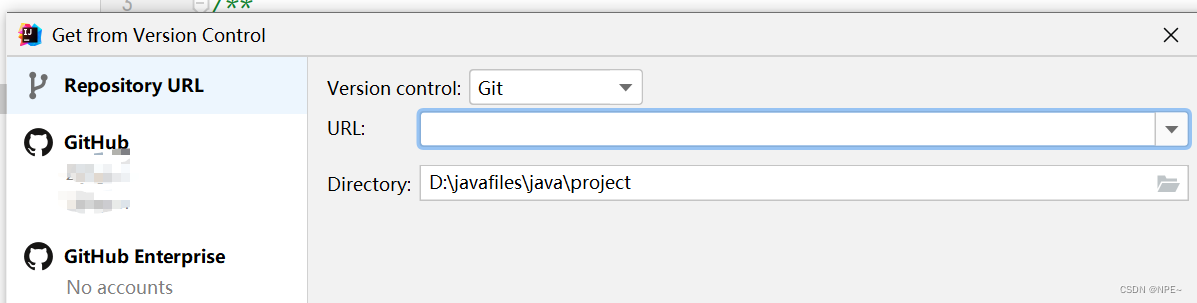
输入对应项目的URL即可
①首先在GitLab中或者任意代码托管平台创建一个自己的仓库
git clone 仓库的URL
通过上面的命令将仓库克隆下来
②在自己的项目中,任意创建一个类
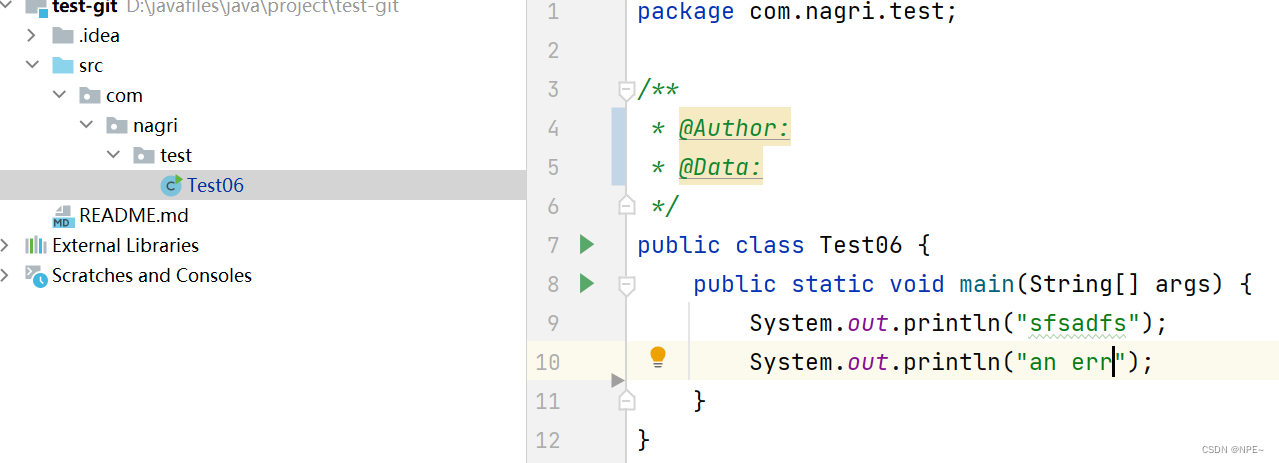
③将其提交commit到本地仓库,然后push到远程仓库
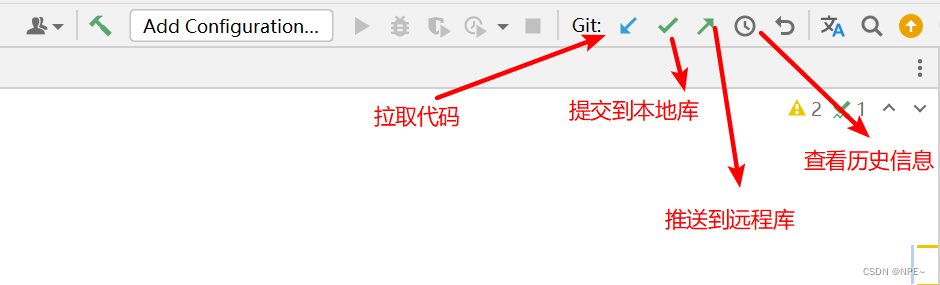
④然后在远程库任意修改代码
此处我添加了一句
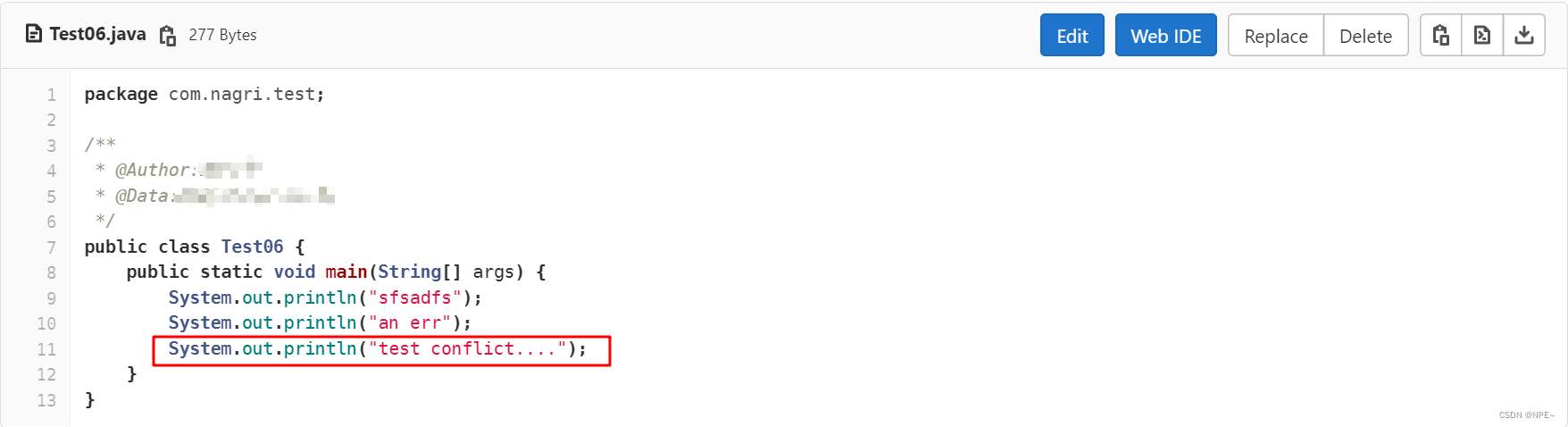
⑤修改本地代码再尝试将其推送到远程仓库
这个时候会因为我们本地的代码不是远程库最新的版本,而导致版本冲突
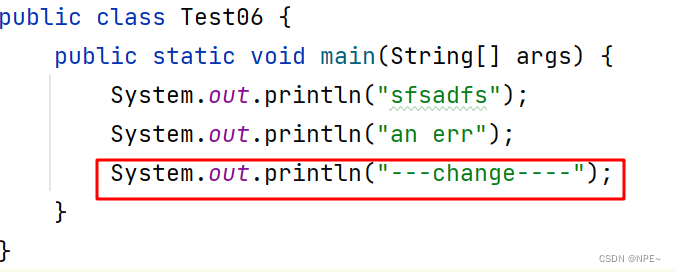
⑥产生冲突
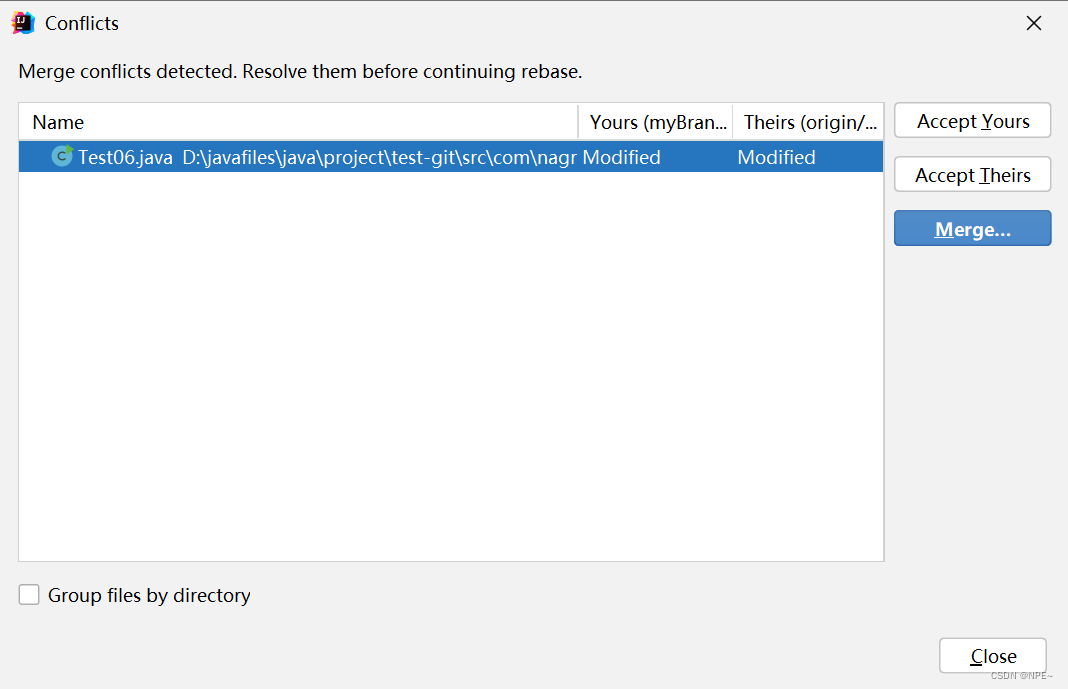
①这个时候选择rebase(一定选择rebase,企业中规范要求,直接merge,可能会导致一系列问题)
因为我之前将rebase作为默认选项,所以这里就跳过选择了
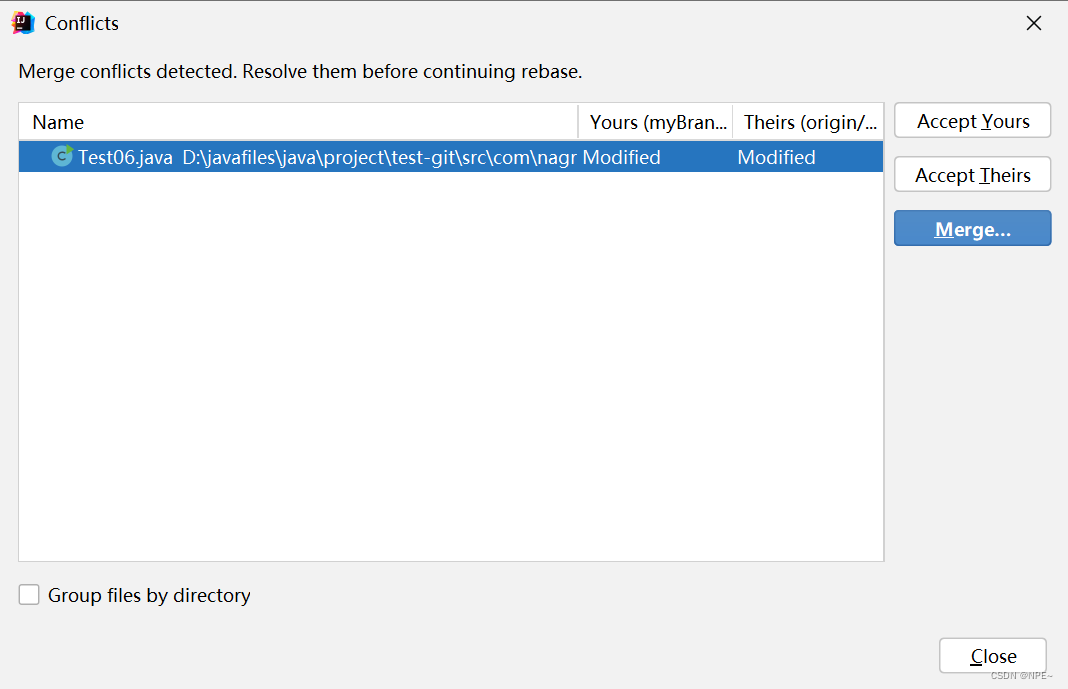
②根据自己的要求进行操作
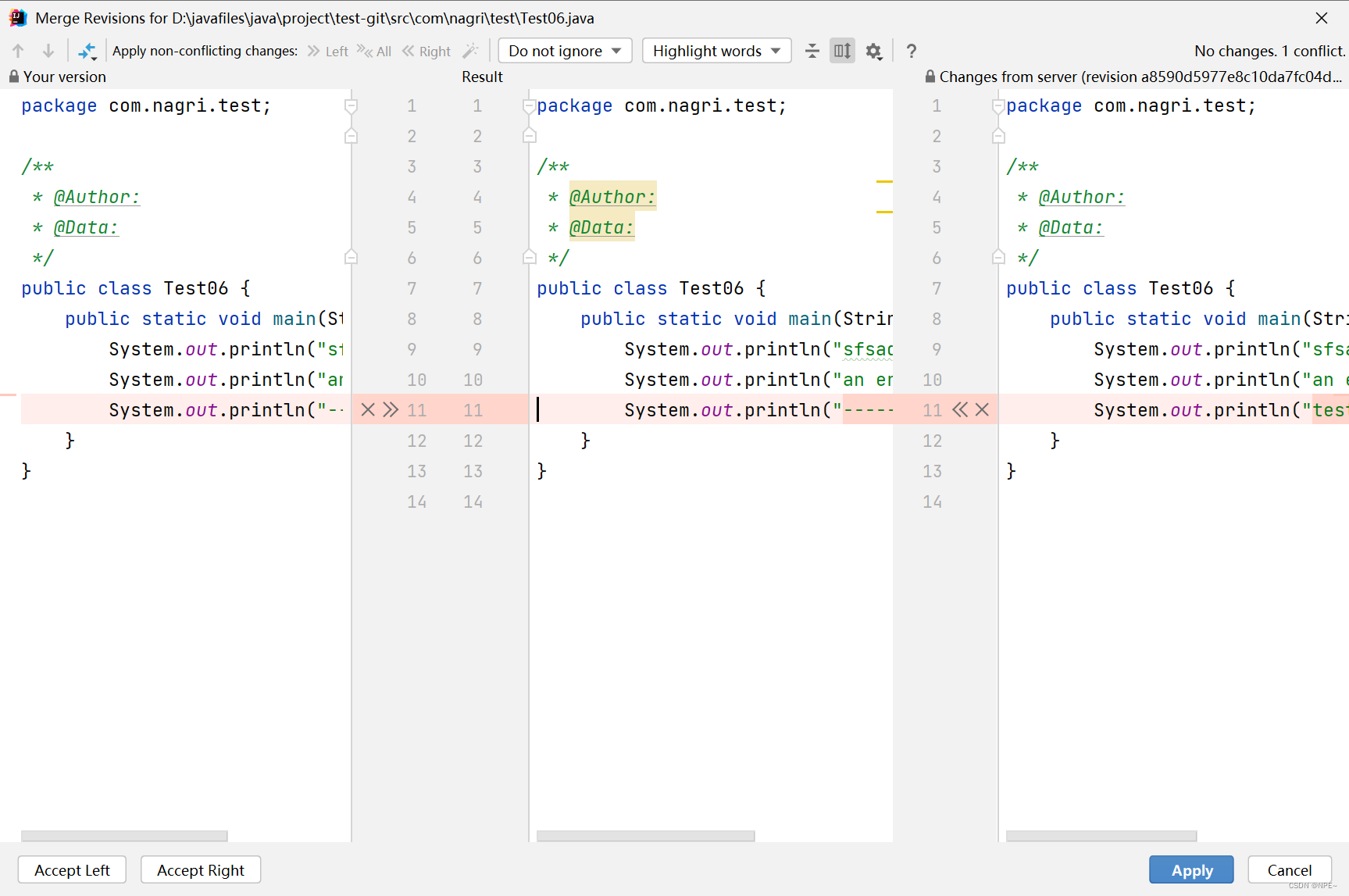
Accept Yours 就是直接选取本地的代码,覆盖掉远程仓库的
Accept Theirs是直接选取远程仓库的,覆盖掉本地的
Merge 自己手动进行选择,修改
③一般情况下我们都会手动Mege
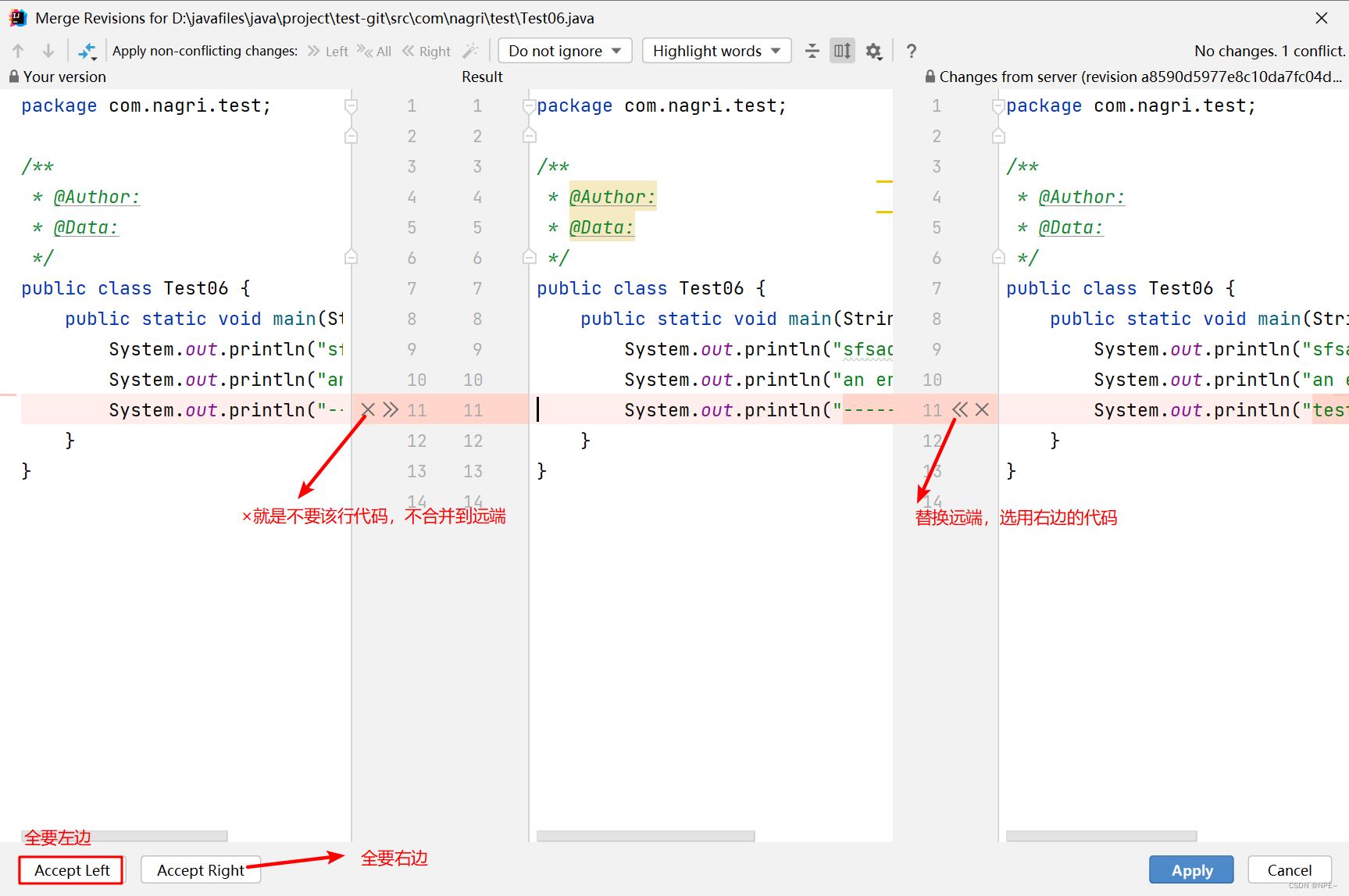
这里左边部分是我们本地仓库的代码,右边部分是远程仓库的代码,中间的result就是我们修改
之后的结果,左下角的AcceptLeft和Accept Right其实就是相当于之前的Accept Yours和Accept
Theirs,右下角的Apply是确认合并,Abort是取消合并。
我们在result中修改好自己想要merge的代码之后,点击Apply就可以了,至此,冲突被解决了
详细文档:
https://www.cnblogs.com/newAndHui/p/10851807.html
如果我们rebase失败:
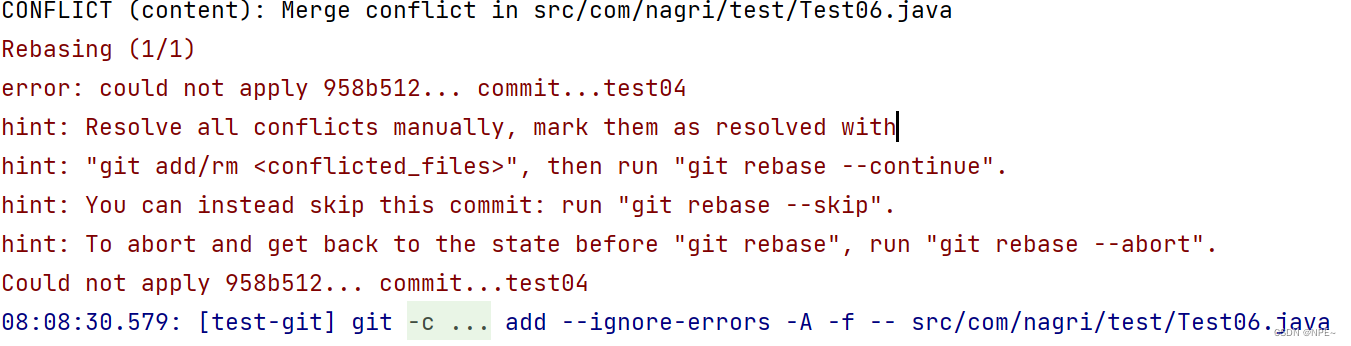
解决办法:
$ git add .(只要有修改都需要git add . 或者git add 具体的文件)
$ git rebase --continue
Applying: 【HCF】*******************
$ git push origin ******************************
git rebase --continue 就相当于 git commit
Git冲突时,不小心点了merge操作,导致本地与远程仓库的代码都凭空消失了
此处,我的是src文件夹被删除了
①通过git log查找出修改过指定文件的commit
目前项目文件已经被删除了,但是根据项目的代码结构,可以推测出原本是存在src这个文件夹的
尝试检测一下在所有的历史记录中对该文件的处理,用到的命令如下:
git log --stat --full-history --simplify-merges -- src
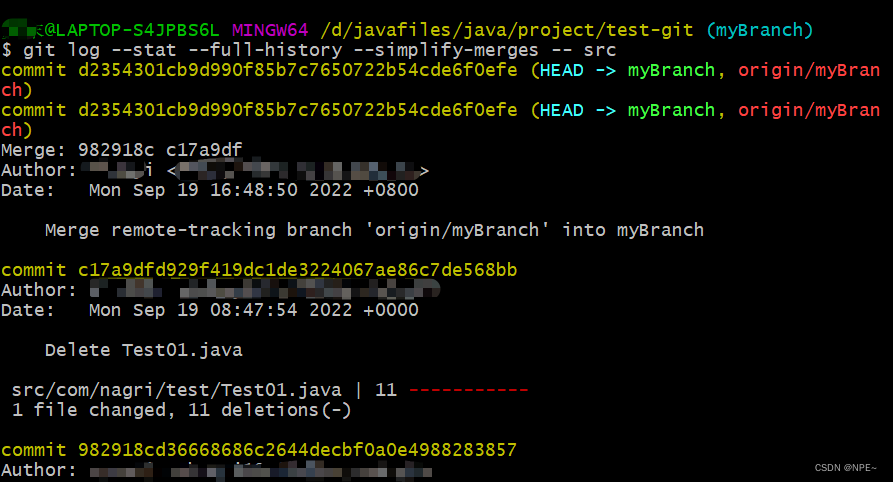
上述命令将会展示涉及到该文件夹更改的commit,从输出结果我们可以看到,在结尾为857的commit中,我们不小心删除了11行代码
②通过切换到该版本
git checkout 982918cd36668686c2644decbf0a0e4988283857
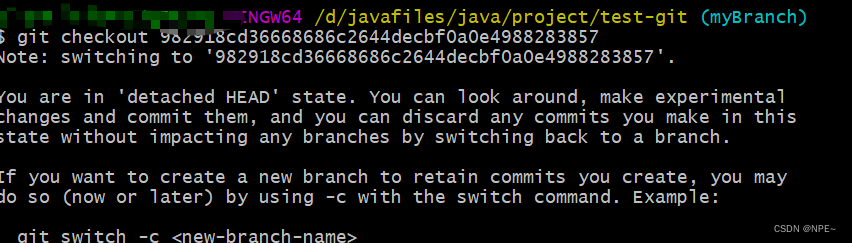
然后回到项目,可以发现我们的之前的代码已经恢复了
为什么会出现这样的情况呢?
分析:https://cloud.tencent.com/developer/article/2033888
git pull --rebase报错
error: cannot pull with rebase: Your index contains uncommitted changes.
error: please commit or stash them.
这个是因为我们本地有更改没有提交上去
如果我们需要提交,就git add, git commit;提交上去
如果不需要提交更改,就git stash,暂存
解决步骤:
根据提示进行以下操作
或者:
然后我们就可以提交了

git clone是本地没有repository,将远程的仓库整个下载过来
git pull是本地有repository,将远程仓库里新的commit数据(如果有)下载过来,并且与本地代码merge
详解:https://zhuanlan.zhihu.com/p/75499871
https://segmentfault.com/a/1190000038547167
rebase与merge实现,版本提交数风格会呈现不同的效果
- rebase会把你当前分支的 commit 放到公共分支的最后面,所以叫变基。就好像你从公共分支又重新拉出来这个分支一样。
- 举例:如果你从 master 拉了个prod分支出来,然后你提交了几个 commit,这个时候刚好有人把他开发的东西合并到 master 了,这个时候 master 就比你拉分支的时候多了几个 commit,如果这个时候你 rebase master 的话,就会把你当前的几个 commit,放到那个人 commit 的后面。
- 具体效果如下:
master 初始状态为1,2,3.在此基础上新建一个prod分支
master 提交了4,5. prod分支提交了6,7.
此时分支状态:master->1-2-3-4-5
prod ->1-2-3-6-7
在prod上使用rebase master,prod分支状态变成1-2-3-4-5-6-7 如果merge master,prod分支状态变成1-2-3-6-7-8
这里的8提交的是4-5合起来的提交
merge之后想回退到你分支上的某个提交就会很麻烦!
通常,在开发中,我们提交之前都会commit之后,再pull远程仓库,保证当前是最新版本,然后push到远程仓库
选择merge操作
选择rebase操作
也可以参考4.9的方法:change list
在开发的时候,我们难免会碰到有同事需要我们合并代码,但是这个时候我们自己也在本地写了一些,并且由于一些原因(没有测试完成),自己并不想要将这些代码提交到远程库。
那么这个时候该怎么办呢?git stash就起作用了
①右击项目名,选中git, 选择 stash changes(存放)
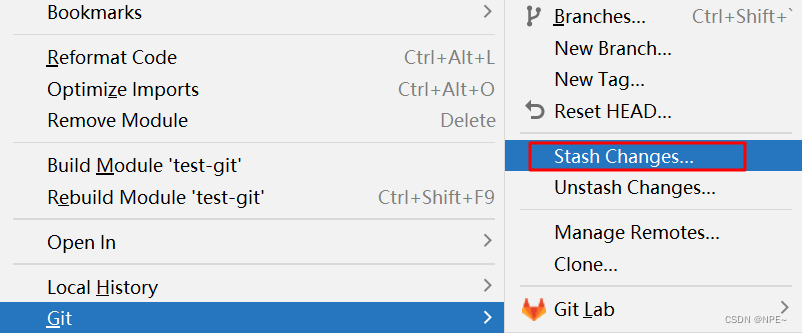
②然后git pull,从远程仓库拉取最新代码进行合并(merge)
③获取到最新代码之后,unstash,获取到之前我们在本地写的代码
POST git-upload-pack (327 bytes) From https://gitee.com/Zifasdfa/graduation-music * branch master -> FETCH_HEAD = [up to date] master -> origin/master refusing to merge unrelated histories
出现这个问题的最主要原因还是在于本地仓库和远程仓库实际上是独立的两个仓库。如果我之前是直接clone的方式在本地建立起远程github仓库的克隆本地仓库就不会有这问题了。
git pull origin master --allow-unrelated-histories
即可解决问题
git移除已经add的文件
git rm --cached "文件路径"
[其他] 请问 git rm --cache 和 git reset HEAD 的区别到底在哪里呢?
如果要删除文件,最好用 git rm file_name,而不应该直接在工作区直接 rm file_name。
如果一个文件已经add到暂存区,还没有 commit,此时如果不想要这个文件了,有两种方法:
1,用版本库内容清空暂存区,git reset HEAD 但要慎重使用
2,只把特定文件从暂存区删除,git rm --cached xxx
git rm --f "文件路径"
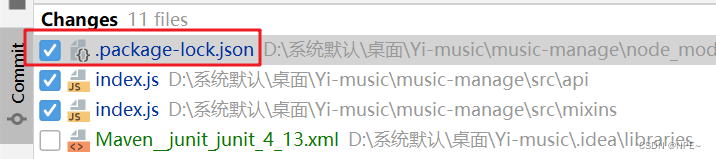

可以暂时选择搁置
在commit的时候,选中想要搁置的文件,鼠标右击,选择Shelve Changes
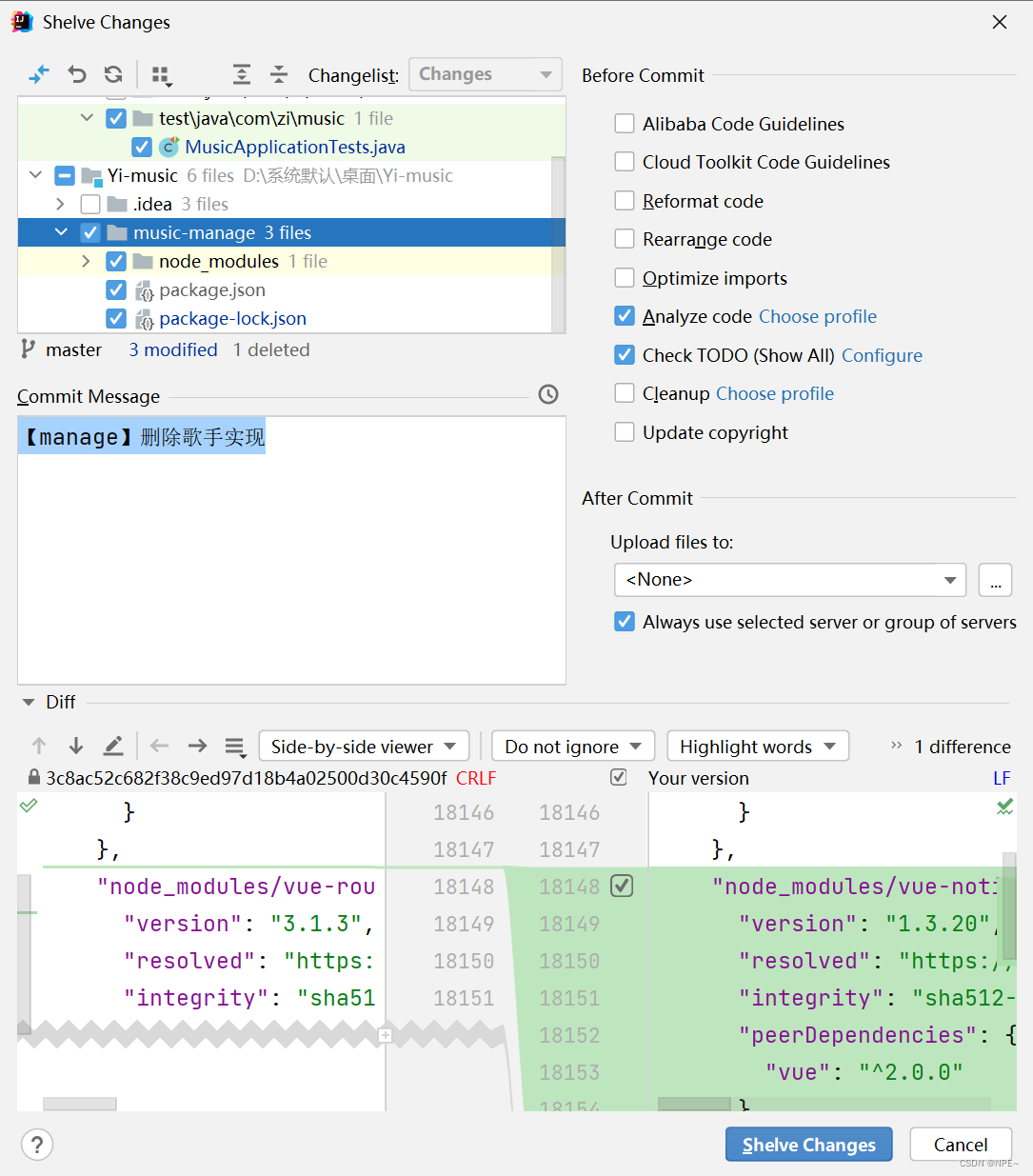
可以选择stash changes
选中项目,鼠标右击选中git,找到stash changes
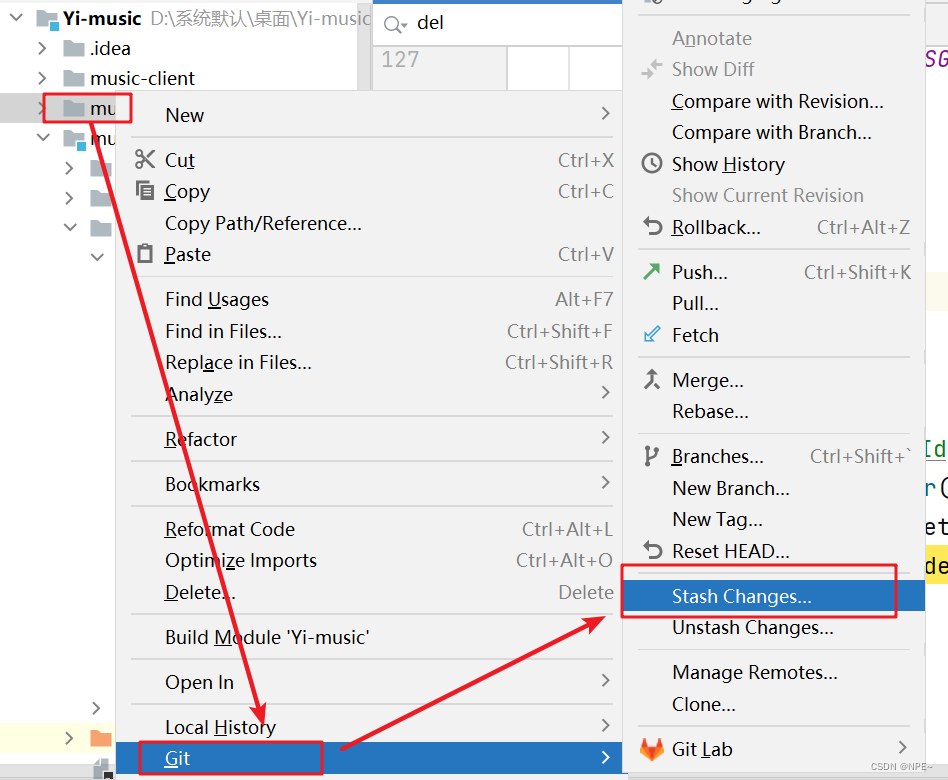
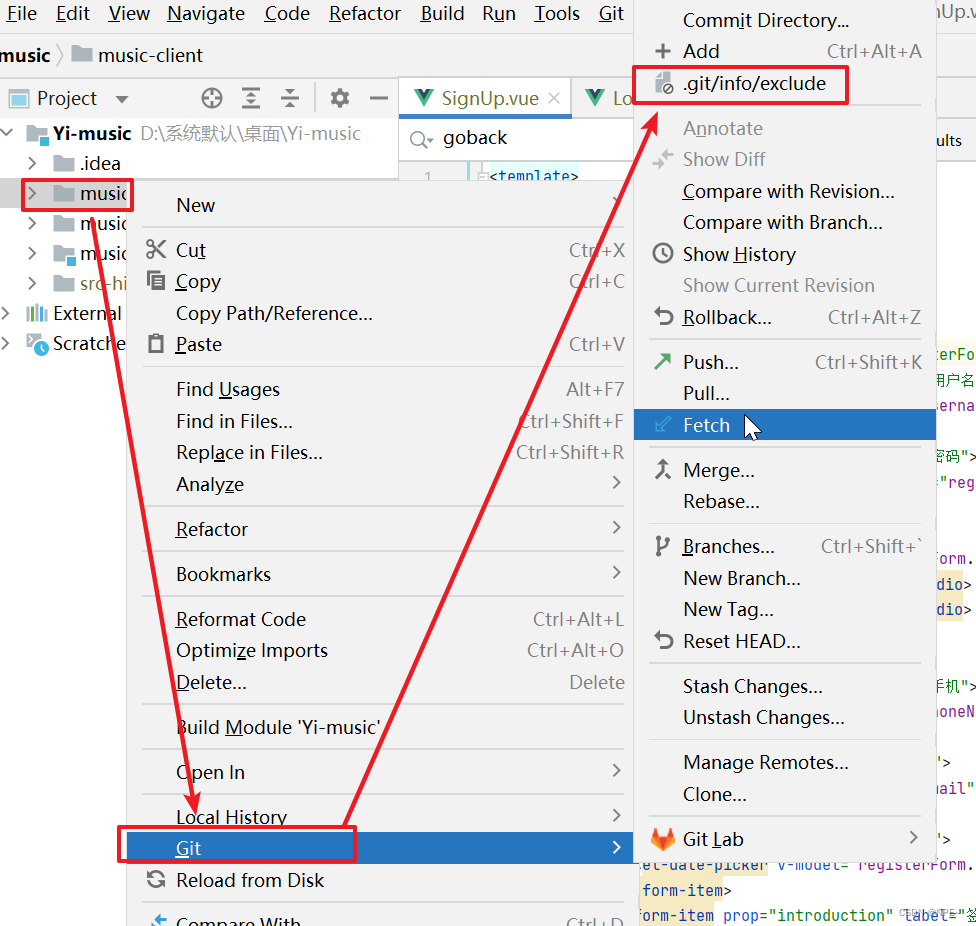
右击项目 - git - .git/info/exclude
3. 也可以通过回退的方式来实现
如图:我不小心把README.md也添加到了git本地仓库
通过rollback解决:
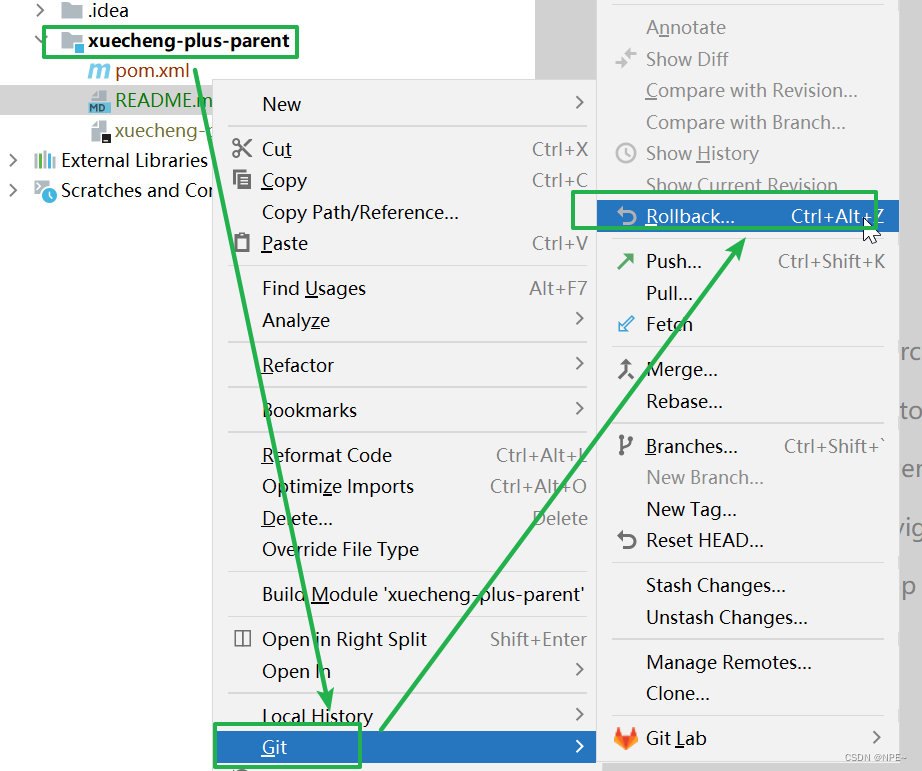
选中要rollback的文件,点击rollback
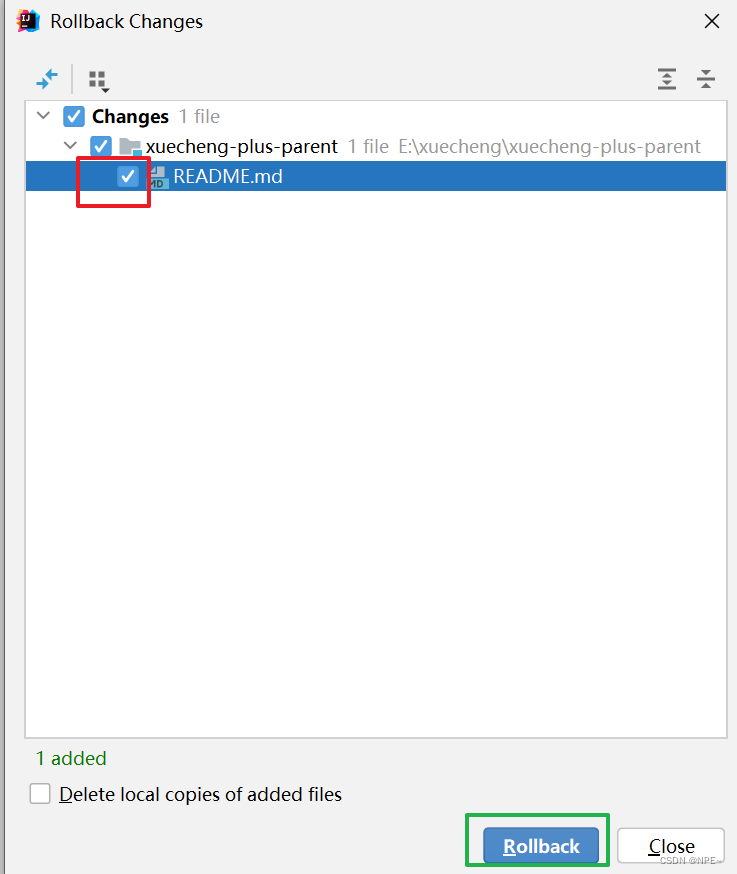
可以看到README.md已经变为红色,表明没有被add到本地仓库
大家在开发中可能会遇到这样的问题,就是自己提交了错误的代码到远程仓库,想要同时回退远程和本地的。
有两种方法:1、Revert操作 2、利用IDEA的Reset Head指针
- 方法1的Revert操作会当成一个新的提交记录,追加到提交日志当中,这样便保留了原来的提交记录。(推荐)
- 方法2的Reset Head指针,会抛弃原来的提交记录,使Head指针强制指向指定的版本。
当在版本1基础上进行修改内容,并提交本地、远程仓库后,发现提交的内容不是我想要的,或者是完全错误的,需要回退版本1。
① 目前本地和远程的分支都是在第二次提交的位置

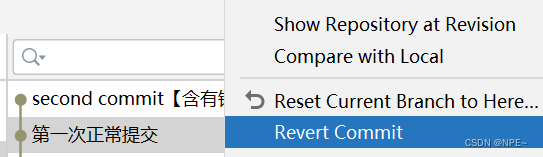
这时弹出冲突对话框,双击冲突文件以解决冲突。(见下图)
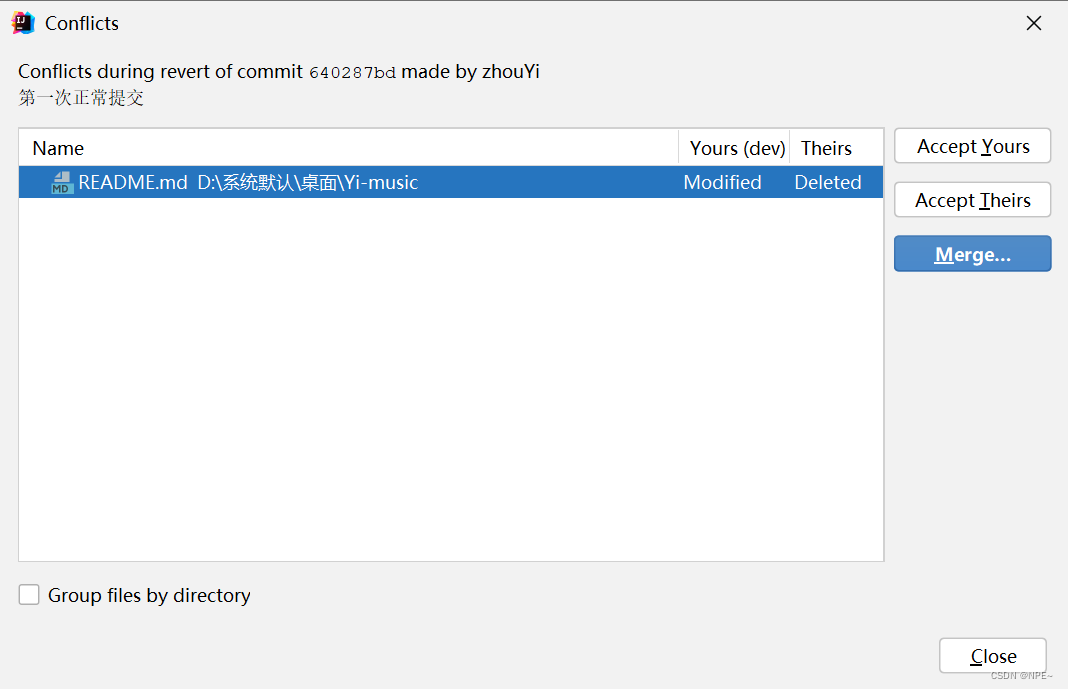
注意:如果回退失败,那么可能是你本地还有其他修改未提交,可以通过stash方式暂存起来
your local changes would be overwritten by revert.
hint: commit your changes or stash them to proceed.
revert failed
stash操作:
③ 解决冲突后,本地就回到之前的正确代码了
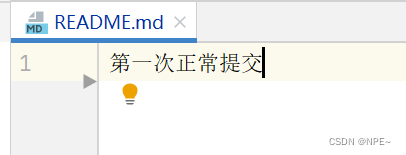
④本地再commit,可以发现日志中增加了回退记录,同时再push到远程,可以发现远程和本地都同步了【origin】

远程:
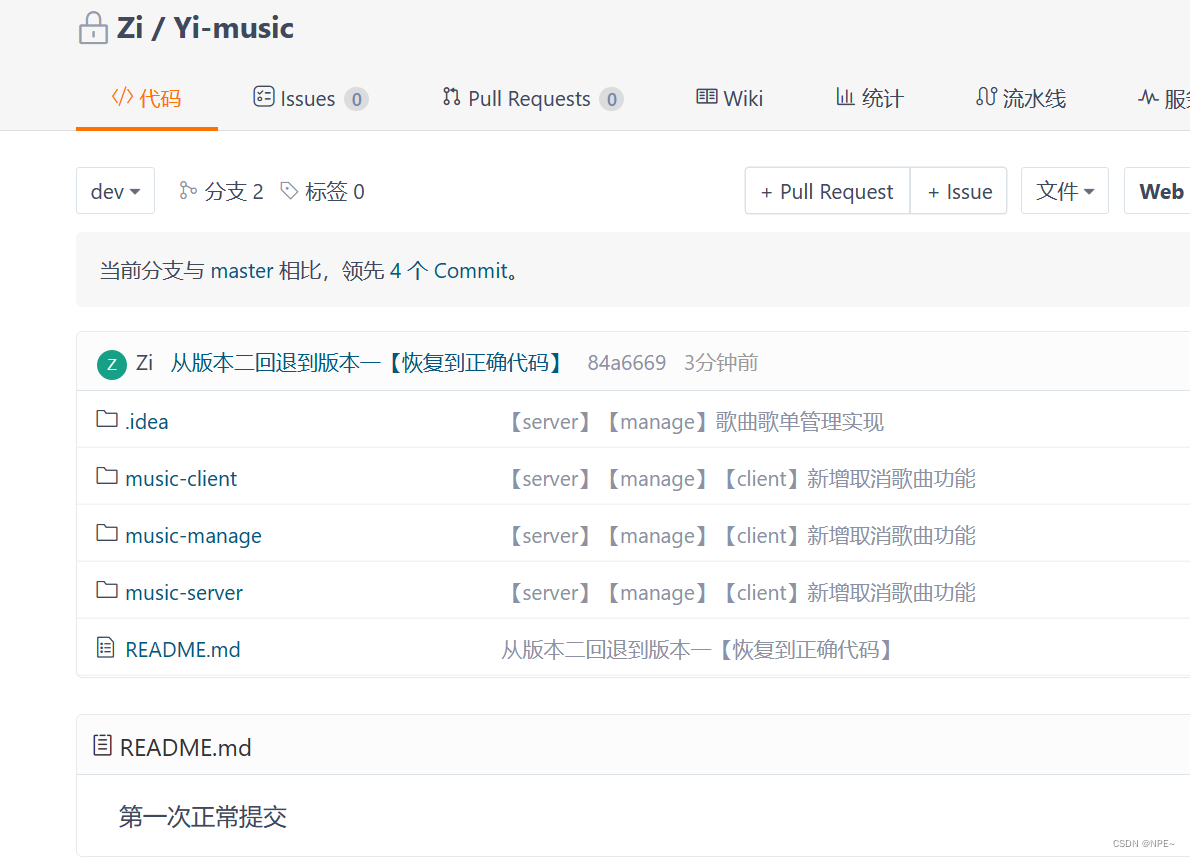
这种回退的好处在于,如果后悔了“回退”这个操作,也可以回退到没有回退之前的版本。因为历史记录还保留提交记录。
cherry pick:最佳选择
对于多分支的代码,,将代码从一个分支转移到另一个分支是常见的。
此时分两种情况:
git merge 合并)cherry pick )举例来说,代码仓库有master和feature两个分支。
a - b - c - d Master
\
e - f - g Feature
现在将提交f应用到master分支。
# 切换到 master 分支
$ git checkout master
# Cherry pick 操作
$ git cherry-pick f
上面的操作完成以后,代码库就变成了下面的样子。
a - b - c - d - f Master
\
e - f - g Feature
从上面可以看到,master分支的末尾增加了一个提交f。
- git cherry-pick命令的参数,不一定是提交的哈希值,分支名也是可以的,表示转移该分支的最新提交。
$ git cherry-pick feature
上面代码表示将feature分支的最近一次提交,转移到当前分支。
有时候我们在拉取了多个项目的时候,经常会碰到这样的问题:
修改了多个项目,但是只想提交一个项目中的代码,这时就可以创建一个changelist
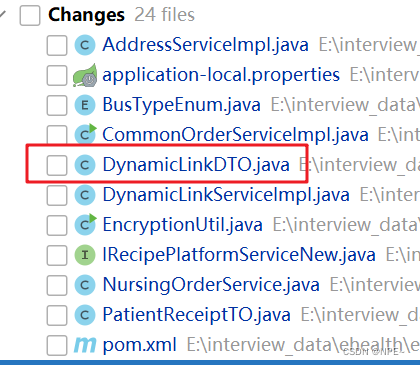
比如此处我们只想提交DynamicLinkDTO
那么我们可以本地创建一个changelist
new changelist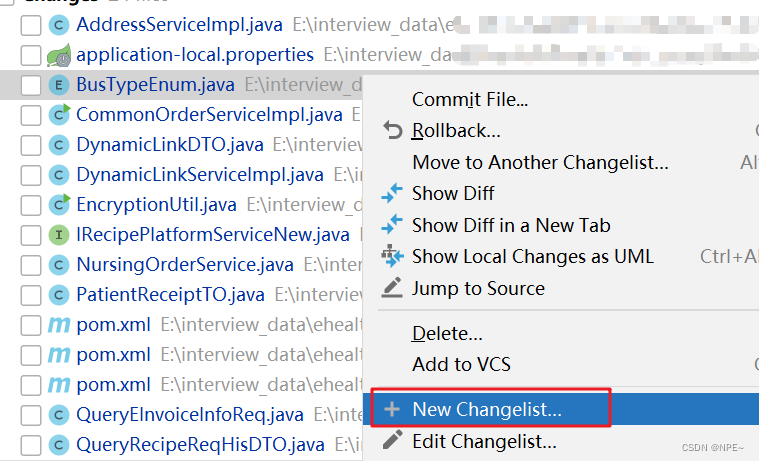
changelist,如:default_change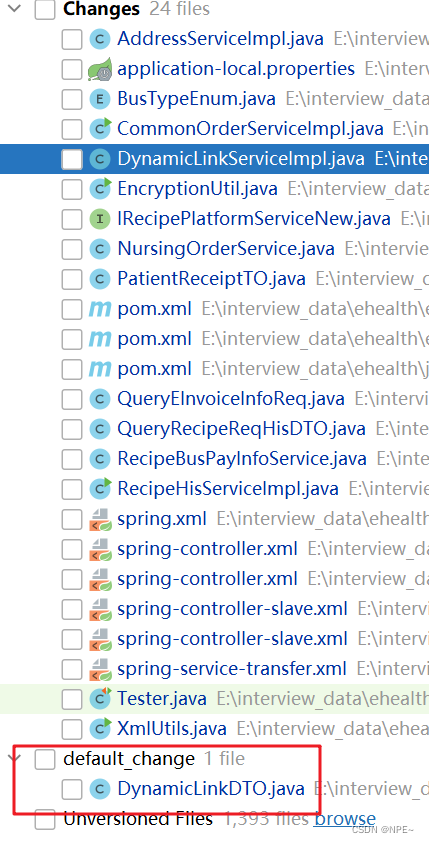
git pull origin master --allow-unrelated-histories
找到git的设置,然后关闭
analyze code
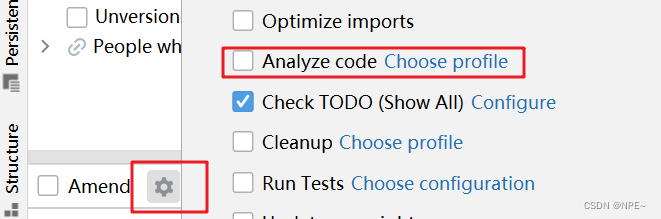
IDEA当在一个分支上修改了内容没有提交,然后切换到其他分支时,可能会发生冲突。
这时IDEA会弹出提示,问你要选择Smart Checkout还是Force Checkout:
如果想保留你在原分支上的修改内容,那么选择Smart Checkout,
Force Checkout不会保留你的修改,切到另一个分支内容就消失了,且切回来原来分支也找不回,白写了。
原理:选择Smart Checkout,IDEA会先执行stash命令,贮存这些未提交的修改,然后checkout 到分支B,在切换到分支B后,unstash 这些修改,所以A分支本地的这些修改会带到B分支上。
我们有时候在开发的时候,会将自己github或者gitee上的邮箱与公司gitlab上的来回切换。
如果我们在修改公司代码并push时,遇到了如下问题,则:
remote: Push 异常: 本次提交a84887a5d29a8643fd6ef45904b47f2067dbcc35检测到你本地客户端设置的邮箱(xxxxx@163.com)不是你在GitLab中设置的邮箱(yyyss@xxxx.com.cn),请确保你本地和远端的邮箱地址一致!
此时我们应该检查自己本地git邮箱配置是否与gitlab上设置的一致:
# 查看git全局邮箱配置
git config --global user.email
# 修改git全局邮箱配置
git config --gloabl user.email yyyss@xxx.com.cn
# 修改私有配置(某个git文件的)
git config user.email ziyi@163.com
然后我们再重新push,发现还是报错的话,可能是因为我们的commit使用的还是之前的邮箱,我们没有产生新的commit,因此没有成功使用新的邮箱。
修改注释或者增加空行,然后commit即可解决
参考文章:
https://blog.csdn.net/Torey_Li/article/details/87442355
https://blog.csdn.net/woshi1226a/article/details/86664159
https://blog.csdn.net/Deronn/article/details/106574498
我想为Heroku构建一个Rails3应用程序。他们使用Postgres作为他们的数据库,所以我通过MacPorts安装了postgres9.0。现在我需要一个postgresgem并且共识是出于性能原因你想要pggem。但是我对我得到的错误感到非常困惑当我尝试在rvm下通过geminstall安装pg时。我已经非常明确地指定了所有postgres目录的位置可以找到但仍然无法完成安装:$envARCHFLAGS='-archx86_64'geminstallpg--\--with-pg-config=/opt/local/var/db/postgresql90/defaultdb/po
如何在buildr项目中使用Ruby?我在很多不同的项目中使用过Ruby、JRuby、Java和Clojure。我目前正在使用我的标准Ruby开发一个模拟应用程序,我想尝试使用Clojure后端(我确实喜欢功能代码)以及JRubygui和测试套件。我还可以看到在未来的不同项目中使用Scala作为后端。我想我要为我的项目尝试一下buildr(http://buildr.apache.org/),但我注意到buildr似乎没有设置为在项目中使用JRuby代码本身!这看起来有点傻,因为该工具旨在统一通用的JVM语言并且是在ruby中构建的。除了将输出的jar包含在一个独特的、仅限ruby
尝试通过RVM将RubyGems升级到版本1.8.10并出现此错误:$rvmrubygemslatestRemovingoldRubygemsfiles...Installingrubygems-1.8.10forruby-1.9.2-p180...ERROR:Errorrunning'GEM_PATH="/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/ruby-1.9.2-p180@global:/Users/foo/.rvm/gems/ruby-1.9.2-p180:/Users/foo/.rvm/gems/rub
在rails源中:https://github.com/rails/rails/blob/master/activesupport/lib/active_support/lazy_load_hooks.rb可以看到以下内容@load_hooks=Hash.new{|h,k|h[k]=[]}在IRB中,它只是初始化一个空哈希。和做有什么区别@load_hooks=Hash.new 最佳答案 查看rubydocumentationforHashnew→new_hashclicktotogglesourcenew(obj)→new_has
我的最终目标是安装当前版本的RubyonRails。我在OSXMountainLion上运行。到目前为止,这是我的过程:已安装的RVM$\curl-Lhttps://get.rvm.io|bash-sstable检查已知(我假设已批准)安装$rvmlistknown我看到当前的稳定版本可用[ruby-]2.0.0[-p247]输入命令安装$rvminstall2.0.0-p247注意:我也试过这些安装命令$rvminstallruby-2.0.0-p247$rvminstallruby=2.0.0-p247我很快就无处可去了。结果:$rvminstall2.0.0-p247Search
由于fast-stemmer的问题,我很难安装我想要的任何rubygem。我把我得到的错误放在下面。Buildingnativeextensions.Thiscouldtakeawhile...ERROR:Errorinstallingfast-stemmer:ERROR:Failedtobuildgemnativeextension./System/Library/Frameworks/Ruby.framework/Versions/2.0/usr/bin/rubyextconf.rbcreatingMakefilemake"DESTDIR="cleanmake"DESTDIR=
两者都可以defsetup(options={})options.reverse_merge:size=>25,:velocity=>10end和defsetup(options={}){:size=>25,:velocity=>10}.merge(options)end在方法的参数中分配默认值。问题是:哪个更好?您更愿意使用哪一个?在性能、代码可读性或其他方面有什么不同吗?编辑:我无意中添加了bang(!)...并不是要询问nobang方法与bang方法之间的区别 最佳答案 我倾向于使用reverse_merge方法:option
我的主要目标是能够完全理解我正在使用的库/gem。我尝试在Github上从头到尾阅读源代码,但这真的很难。我认为更有趣、更温和的踏脚石就是在使用时阅读每个库/gem方法的源代码。例如,我想知道RubyonRails中的redirect_to方法是如何工作的:如何查找redirect_to方法的源代码?我知道在pry中我可以执行类似show-methodmethod的操作,但我如何才能对Rails框架中的方法执行此操作?您对我如何更好地理解Gem及其API有什么建议吗?仅仅阅读源代码似乎真的很难,尤其是对于框架。谢谢! 最佳答案 Ru
当我尝试安装Ruby时遇到此错误。我试过查看this和this但无济于事➜~brewinstallrubyWarning:YouareusingOSX10.12.Wedonotprovidesupportforthispre-releaseversion.Youmayencounterbuildfailuresorotherbreakages.Pleasecreatepull-requestsinsteadoffilingissues.==>Installingdependenciesforruby:readline,libyaml,makedepend==>Installingrub
我的假设是moduleAmoduleBendend和moduleA::Bend是一样的。我能够从thisblog找到解决方案,thisSOthread和andthisSOthread.为什么以及什么时候应该更喜欢紧凑语法A::B而不是另一个,因为它显然有一个缺点?我有一种直觉,它可能与性能有关,因为在更多命名空间中查找常量需要更多计算。但是我无法通过对普通类进行基准测试来验证这一点。 最佳答案 这两种写作方法经常被混淆。首先要说的是,据我所知,没有可衡量的性能差异。(在下面的书面示例中不断查找)最明显的区别,可能也是最著名的,是你的