Python3.6.9 Flink 1.15.2消费Kafaka Topic
PyFlink基础应用之kafka
通过PyFlink作业处理Kafka数据
(1)启动zookeeper
zkServer.sh start
(2)启动kafka
cd /usr/local/kafka/
nohup ./bin/kafka-server-start.sh ./config/server.properties >> /tmp/kafkaoutput.log 2>&1 &
或者
./bin/kafka-server-start.sh -daemon ./config/server0.properties
(3)查看进程如下
jps
10101 QuorumPeerMain
11047 Kafka
(4)kafka tools配置
C:\Windows\System32\drivers\etc\hosts
(5)查看日志文件
/tmp/kafkaoutput.log或者/usr/local/kafka/logs
(6)创建Topic主题
bin/kafka-topics.sh --create --zookeeper localhost:2181 -replication-factor 1 --partitions 1 --topic flink_kafakasource
(7)查看当前创建的Topic
bin/kafka-topics.sh --list --zookeeper localhost:2181
(8)查看kafka版本
kafka_2.12-2.2.0.jar
可以看出scala的版本是2.12,kafka的版本是2.2.0
(1)启动flink
start-cluster.sh
(2)查看是否启用成功
jps
4704 TaskManagerRunner
4443 StandaloneSessionClusterEntrypoint
(3)关闭Flink
stop-cluster.sh
PyFlink需要特定的Python版本,Python 3.6, 3.7, 3.8 or 3.9。
一、系统中安装了多个版本的python3。
编译安装python时
其中–prefix选项是配置安装的路径,
若是不配置该选项,安装后可执行文件默认放在/usr/local/bin,
库文件默认放在/usr/local/lib,
配置文件默认放在/usr/local/etc,
其它的资源文件放在/usr /local/share,比较凌乱。
/usr/local/bin/python3.6m
/usr/local/bin/python3.6m-config
/usr/include/python3.6m
/usr/local/bin/python3.6
/usr/local/bin/python3.6-config
/usr/local/lib/python3.6
/usr/local/bin/python3.10
/usr/local/bin/python3.10-config
/usr/local/lib/python3.10
二、环境变量path作用顺序
#echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/usr/local/jdk1.8.0_144/bin:/root/bin:/home/data/java/bin:/home/data/java/jre/bin
按照顺序进行显示
三、安装Pyflink
ln -s 源文件 目标文件
ln -s /usr/local/bin/python3.6 /usr/local/bin/python3
ln -s /usr/local/bin/pip3.6 /usr/local/bin/pip3
/usr/local/bin/python3.6 -m pip install --upgrade pip
pip3 install apache-flink==1.15.3 -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
包文件安装后的位置
/usr/local/lib/python3.6/site-packages
(1)在https://mvnrepository.com/里输入flink kafka寻找对应版本的连接器。
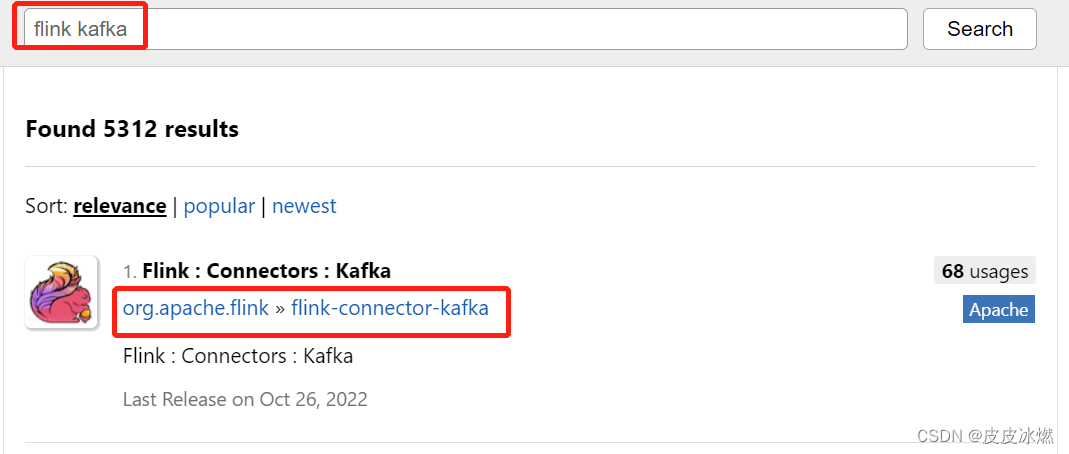
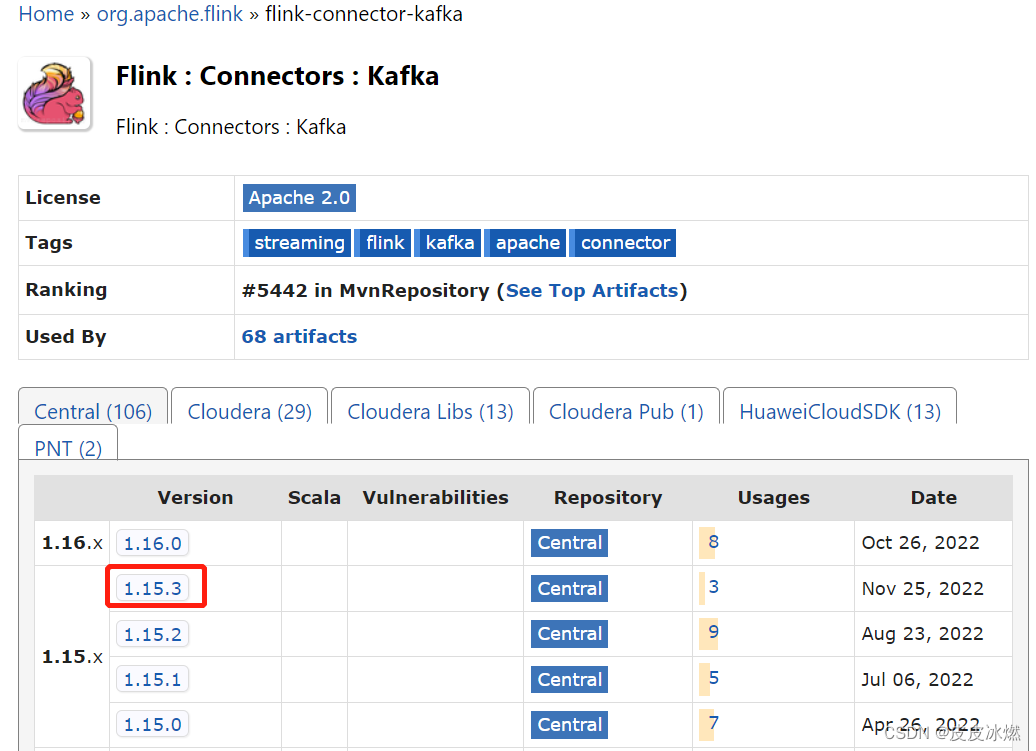
(2)选择Flink对应的版本1.15.3,点击jar。
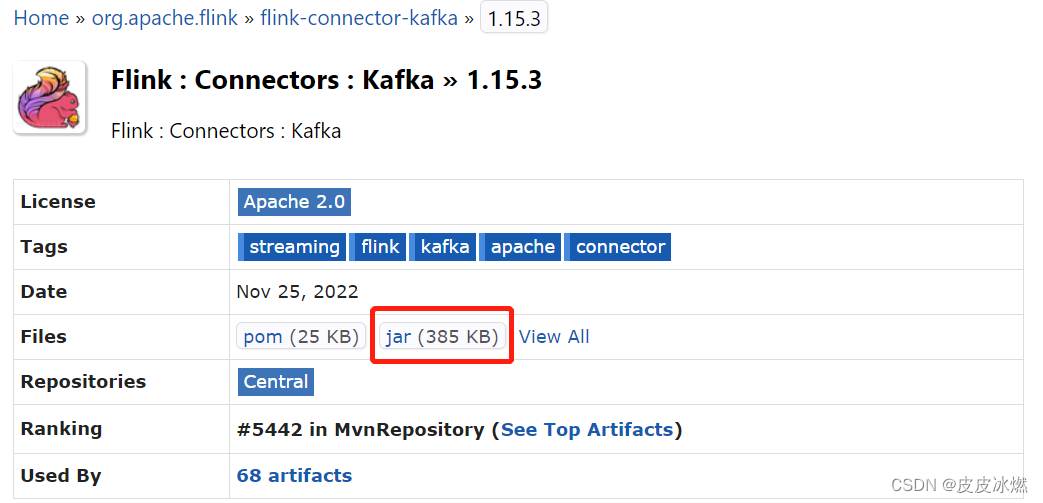
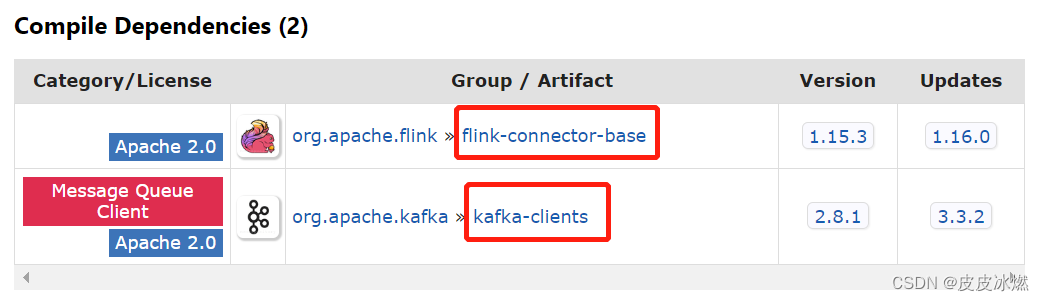
(3)分别下载flink-connector-base和kafka-clients对应的jar包。
(4)将该jar包放置在python的lib目录下
/usr/local/lib/python3.6/dist-packages/pyflink/lib。
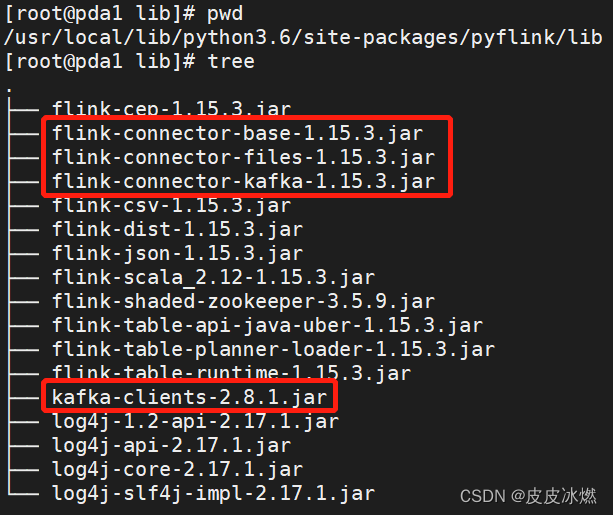
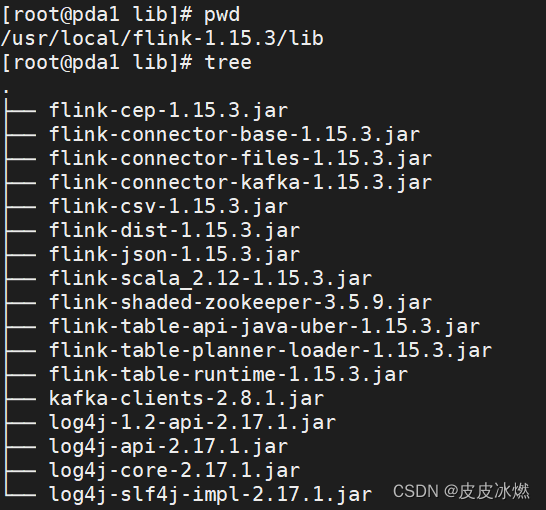
(5)将该jar包放置在Flink的lib目录下
拷贝三个jar包到FLINK_HOME/lib下。
本应用采用pyflink+sql方式编写代码。
# -*- coding: UTF-8 -*-
from pyflink.datastream import StreamExecutionEnvironment, CheckpointingMode
from pyflink.table import StreamTableEnvironment, TableConfig, DataTypes, CsvTableSink, WriteMode, SqlDialect
s_env = StreamExecutionEnvironment.get_execution_environment()
s_env.set_parallelism(1)
s_env.enable_checkpointing(3000)
st_env = StreamTableEnvironment.create(s_env) # , TableConfig())
st_env.use_catalog("default_catalog")
st_env.use_database("default_database")
sourceKafkaDdl = """
create table sourceKafka(
id int,name varchar
)
with(
'connector'='kafka',
'topic'='flink_kafakasource',
'properties.bootstrap.servers'='192.168.43.48:9092',
'scan.startup.mode'='latest-offset',
'format'='json'
)
"""
st_env.execute_sql(sourceKafkaDdl)
fieldNames = ["id", "name"]
fieldTypes = [DataTypes.INT(), DataTypes.STRING()]
csvSink = CsvTableSink(fieldNames, fieldTypes, "/tmp/result.csv", ",", 1, WriteMode.OVERWRITE)
st_env.register_table_sink("csvTableSink", csvSink)
st_env.execute_sql("""
INSERT INTO csvTableSink
select * from sourceKafka
""").wait()
无需安装flink。
(1)安装pyflink
pip3 install apache-flink==1.15.3
(2)配置pycharm的flink环境:
首先最重要的是版本问题,这里给出我的相关版本配置
kafka:2.2.0
jdk:1.8.0_201
apache-flink: 1.15.3
相应的jar包版本。
flink-connector-base-1.15.3.jar
flink-connector-kafka-1.15.3.jar
kafka-clients-2.8.1.jar
将jar包放入External Libraries下的site-packages下的pyflink下的lib中。
(3)运行
python3 flinkDemo.py
/usr/local/flink-1.15.3/bin/flink run -py flinkDemo.py
或
/usr/local/flink-1.15.3/bin/flink run --python flinkDemo.py
显示如下:
Job has been submitted with JobID 1f3d2ffc0b0c5f9274040fd008a5ec17
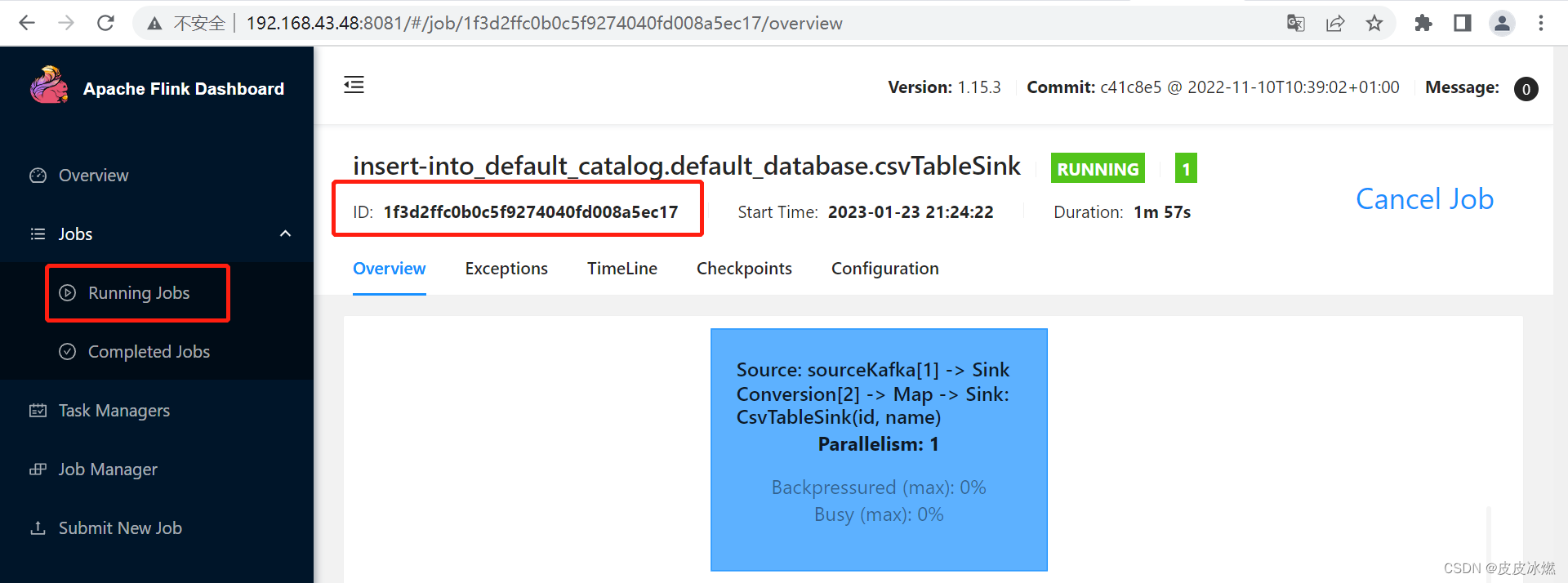
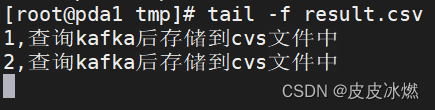
打开kafka生产者,通过客户端生产数据。
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic flink_kafakasource
{"id":2,"name":"查询kafka后存储到cvs文件中"}
直接本地IDEA中运行即可。
# -*- coding: UTF-8 -*-
from pyflink.datastream import StreamExecutionEnvironment, CheckpointingMode
from pyflink.table import StreamTableEnvironment, TableConfig, DataTypes, CsvTableSink, WriteMode, SqlDialect
s_env = StreamExecutionEnvironment.get_execution_environment()
s_env.set_parallelism(1)
s_env.enable_checkpointing(3000)
st_env = StreamTableEnvironment.create(s_env) # , TableConfig())
st_env.use_catalog("default_catalog")
st_env.use_database("default_database")
sourceKafkaDdl = """
create table sourceKafka(
id int,name varchar
)
with(
'connector'='kafka',
'topic'='flink_kafakasource',
'properties.bootstrap.servers'='192.168.43.48:9092',
'scan.startup.mode'='latest-offset',
'format'='json'
)
"""
sinkKafkaDdl = """
create table sinkKafka(
id int,name varchar
)
with(
'connector'='kafka',
'topic'='result',
'properties.bootstrap.servers'='192.168.43.48:9092',
'scan.startup.mode'='latest-offset',
'format'='json'
)
"""
st_env.execute_sql(sourceKafkaDdl)
st_env.execute_sql(sinkKafkaDdl)
st_env.execute_sql("""
INSERT INTO sinkKafka
select * from sourceKafka
""").wait()
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
这里是Ruby新手。完成一些练习后碰壁了。练习:计算一系列成绩的字母等级创建一个方法get_grade来接受测试分数数组。数组中的每个分数应介于0和100之间,其中100是最大分数。计算平均分并将字母等级作为字符串返回,即“A”、“B”、“C”、“D”、“E”或“F”。我一直返回错误:avg.rb:1:syntaxerror,unexpectedtLBRACK,expecting')'defget_grade([100,90,80])^avg.rb:1:syntaxerror,unexpected')',expecting$end这是我目前所拥有的。我想坚持使用下面的方法或.join,
我想在一个没有Sass引擎的类中使用Sass颜色函数。我已经在项目中使用了sassgem,所以我认为搭载会像以下一样简单:classRectangleincludeSass::Script::FunctionsdefcolorSass::Script::Color.new([0x82,0x39,0x06])enddefrender#hamlengineexecutedwithcontextofself#sothatwithintemlateicouldcall#%stop{offset:'0%',stop:{color:lighten(color)}}endend更新:参见上面的#re
有时我需要处理键/值数据。我不喜欢使用数组,因为它们在大小上没有限制(很容易不小心添加超过2个项目,而且您最终需要稍后验证大小)。此外,0和1的索引变成了魔数(MagicNumber),并且在传达含义方面做得很差(“当我说0时,我的意思是head...”)。散列也不合适,因为可能会不小心添加额外的条目。我写了下面的类来解决这个问题:classPairattr_accessor:head,:taildefinitialize(h,t)@head,@tail=h,tendend它工作得很好并且解决了问题,但我很想知道:Ruby标准库是否已经带有这样一个类? 最佳
我想为我的Rails网络应用程序提供推荐功能。特别是,我想向新注册的用户推荐他可能想要关注的其他用户。Rails中是否有用于此目的的引擎/gem?如果没有,我应该从哪里开始构建它?谢谢。 最佳答案 有Coletivogemhttps://github.com/diogenes/coletivo我试了一下。在MySQL上运行。Neo4jhttp://neo4j.org真的很容易实现一个“跟随谁”。事实上,大多数展示其能力的样本都涉及“跟随谁”。快速提示-只有在JRuby上运行时,Neo4j.rb才会很酷。如果不是-使用Neograph
我正在尝试使用Curbgem执行以下POST以解析云curl-XPOST\-H"X-Parse-Application-Id:PARSE_APP_ID"\-H"X-Parse-REST-API-Key:PARSE_API_KEY"\-H"Content-Type:image/jpeg"\--data-binary'@myPicture.jpg'\https://api.parse.com/1/files/pic.jpg用这个:curl=Curl::Easy.new("https://api.parse.com/1/files/lion.jpg")curl.multipart_form_
无论您是想搭建桌面端、WEB端或者移动端APP应用,HOOPSPlatform组件都可以为您提供弹性的3D集成架构,同时,由工业领域3D技术专家组成的HOOPS技术团队也能为您提供技术支持服务。如果您的客户期望有一种在多个平台(桌面/WEB/APP,而且某些客户端是“瘦”客户端)快速、方便地将数据接入到3D应用系统的解决方案,并且当访问数据时,在各个平台上的性能和用户体验保持一致,HOOPSPlatform将帮助您完成。利用HOOPSPlatform,您可以开发在任何环境下的3D基础应用架构。HOOPSPlatform可以帮您打造3D创新型产品,HOOPSSDK包含的技术有:快速且准确的CAD
导读:随着叮咚买菜业务的发展,不同的业务场景对数据分析提出了不同的需求,他们希望引入一款实时OLAP数据库,构建一个灵活的多维实时查询和分析的平台,统一数据的接入和查询方案,解决各业务线对数据高效实时查询和精细化运营的需求。经过调研选型,最终引入ApacheDoris作为最终的OLAP分析引擎,Doris作为核心的OLAP引擎支持复杂地分析操作、提供多维的数据视图,在叮咚买菜数十个业务场景中广泛应用。作者|叮咚买菜资深数据工程师韩青叮咚买菜创立于2017年5月,是一家专注美好食物的创业公司。叮咚买菜专注吃的事业,为满足更多人“想吃什么”而努力,通过美好食材的供应、美好滋味的开发以及美食品牌的孵
一、引擎主循环UE版本:4.27一、引擎主循环的位置:Launch.cpp:GuardedMain函数二、、GuardedMain函数执行逻辑:1、EnginePreInit:加载大多数模块int32ErrorLevel=EnginePreInit(CmdLine);PreInit模块加载顺序:模块加载过程:(1)注册模块中定义的UObject,同时为每个类构造一个类默认对象(CDO,记录类的默认状态,作为模板用于子类实例创建)(2)调用模块的StartUpModule方法2、FEngineLoop::Init()1、检查Engine的配置文件找出使用了哪一个GameEngine类(UGame
本教程将在Unity3D中混合Optitrack与数据手套的数据流,在人体运动的基础上,添加双手手指部分的运动。双手手背的角度仍由Optitrack提供,数据手套提供双手手指的角度。 01 客户端软件分别安装MotiveBody与MotionVenus并校准人体与数据手套。MotiveBodyMotionVenus数据手套使用、校准流程参照:https://gitee.com/foheart_1/foheart-h1-data-summary.git02 数据转发打开MotiveBody软件的Streaming,开始向Unity3D广播数据;MotionVenus中设置->选项选择Unit