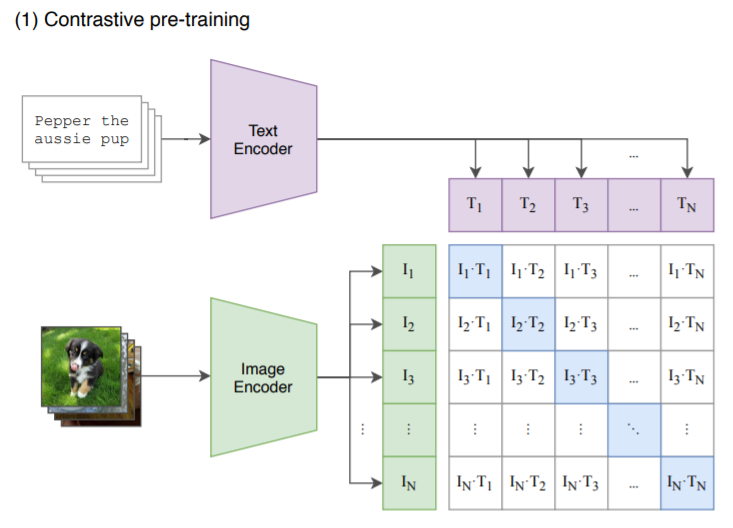
模型架构分为两部分,图像编码器和文本编码器,图像编码器可以是比如 resnet50,然后文本编码器可以是 transformer。
训练数据是网络社交媒体上搜集的图像文本对。在训练阶段,对于一个batch 的数据,首先通过文本编码器和图像编码器,得到文本和图像的特征,接着将所有的文本和图像特征分别计算内积,就能得到一个矩阵,然后从图像的角度看,行方向就是一个分类器,从文本角度看,列方向也是一个分类器。
而由于我们已经知道一个batch中的文本和图像的匹配关系,所以目标函数就是最大化同一对图像和文本特征的内积,也就是矩阵对角线上的元素,而最小化与不相关特征的内积。文章的作者从社交媒体上搜集了有大约4亿对的数据
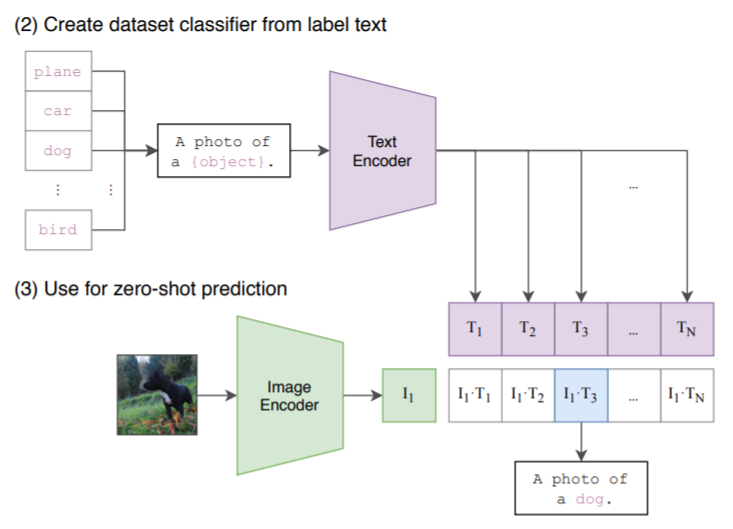
在测试阶段,可以直接将训练好的CLIP用于其他数据集而不需要finetune。和训练阶段类似,首先将需要分类的图像经过编码器得到特征,然后对于目标任务数据集的每一个标签,或者你自己定义的标签,都构造一段对应的文本,如上图中的 dog 会改造成 “A photo of a dog”,以此类推。然后经过编码器得到文本和图像特征,接着将文本特征与图像特征做内积,内积最大对应的标签就是图像的分类结果。这就完成了目标任务上的 zero-shot 分类。
import os
import clip
import torch
from torchvision.datasets import CIFAR100
from PIL import Image
img_pah = 'cup3.jpg'
classes = ['cup', 'not_cup']
#加载模型
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load('ViT-B/32', device)
#准备输入集
image = Image.open(img_pah)
image_input = preprocess(image).unsqueeze(0).to(device)
text_inputs = torch.cat([clip.tokenize(f"a photo of a {c}") for c in classes]).to(device) #生成文字描述
#特征编码
with torch.no_grad():
image_features = model.encode_image(image_input)
text_features = model.encode_text(text_inputs)
#选取参数最高的标签
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1) #对图像描述和图像特征
values, indices = similarity[0].topk(1)
#输出结果
print("\nTop predictions:\n")
print('classes:{} score:{:.2f}'.format(classes[indices.item()], values.item()))
针对与其他分类任务,只需要更改classes即可
import os
from torch.utils.data import DataLoader
import clip
import torch
import torchvision
import time
device = "cuda" if torch.cuda.is_available() else "cpu"
def model_load(model_name):
# 加载模型
model, preprocess = clip.load(model_name, device) #ViT-B/32 RN50x16
return model, preprocess
def data_load(data_path):
#加载数据集和文字描述
celeba = torchvision.datasets.CelebA(root='CELEBA', split='test', download=True)
text_inputs = torch.cat([clip.tokenize(f"a photo of a {c}") for c in celeba.attr_names]).to(device)
return celeba, text_inputs
def test_model(start, end, celeba, text_inputs, model, preprocess):
#测试模型
length = end - start + 1
face_accuracy = 0
face_score = 0
for i, data in enumerate(celeba):
face_result = 0
if i < start:
continue
image, target = data
image_input = preprocess(image).unsqueeze(0).to(device)
with torch.no_grad():
image_features = model.encode_image(image_input)
text_features = model.encode_text(text_inputs)
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
top_score, top_label = text_probs.topk(6, dim=-1)
for k, score in zip(top_label[0], top_score[0]):
if k.item() < 40 and target[k.item()] == 1:
face_result = 1
face_score += score.item()
print('Predict right! The predicted is {}'.format(celeba.attr_names[k.item()]))
else:
print('Predict flase! The predicted is {}'.format(celeba.attr_names[k.item()]))
face_accuracy += face_result
if i == end:
break
face_score = face_score / length
face_accuracy = face_accuracy / length
return face_score, face_accuracy
def main():
start = 0
end = 1000
model_name = 'ViT-B/32' #ViT-B/32 RN50x16
data_path = 'CELEBA'
time_start = time.time()
model, preprocess = model_load(model_name)
celeba, text_inputs = data_load(data_path)
face_score, face_accuracy = test_model(start, end, celeba, text_inputs, model, preprocess)
time_end = time.time()
print('The prediction:')
print('face_accuracy: {:.2f} face_score: {}%'.format(face_accuracy, face_score*100))
print('runing time: %.4f'%(time_end - time_start))
if __name__ == '__main__':
main()
from torch.utils.data import Dataset, DataLoader
import torch
import clip
from torch import nn, optim
import pandas as pd
from PIL import Image
import os
device = 'cuda' if torch.cuda.is_available() else 'cpu'
class image_caption_dataset(Dataset):
def __init__(self, df, preprocess):
self.images = df["image"]
self.caption = df["caption"]
self.preprocess = preprocess
def __len__(self):
return len(self.caption)
def __getitem__(self, idx):
images = self.preprocess(Image.open(self.images[idx]))
caption = self.caption[idx]
return images, caption
def load_data(cup_path, cupnot_path, batch_size, preprocess):
df = {'image': [], 'caption':[]}
cup_list = os.listdir(cup_path)
cupnot_list = os.listdir(cupnot_path)
caption = cup_path.split('/')[-1]
for img in cup_list:
img_path = os.path.join(cup_path, img)
df['image'].append(img_path)
df['caption'].append(caption)
caption = cupnot_path.split('/')[-1]
for img in cupnot_list:
img_path = os.path.join(cupnot_path, img)
df['image'].append(img_path)
df['caption'].append(caption)
dataset = image_caption_dataset(df, preprocess)
train_dataloader = DataLoader(dataset, batch_size=batch_size)
return train_dataloader
def convert_models_to_fp32(model):
for p in model.parameters():
p.data = p.data.float()
p.grad.data = p.grad.data.float()
def load_pretrian_model(model_path):
model, preprocess = clip.load(model_path, device=device, jit=False) # 训练时 jit必须设置为false
if device == "cpu":
model.float()
else:
clip.model.convert_weights(model)
return model, preprocess
def train(epoch, batch_size, learning_rate, cup_path, cupnot_path):
# 加载模型
model, preprocess = load_pretrian_model('ViT-B/32')
#加载数据集
train_dataloader = load_data(cup_path, cupnot_path, batch_size, preprocess)
#设置参数
loss_img = nn.CrossEntropyLoss().to(device)
loss_txt = nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.parameters(), lr=learning_rate, betas=(0.9, 0.98), eps=1e-6, weight_decay=0.2)
for i in range(epoch):
for batch in train_dataloader:
list_image, list_txt = batch # list_images is list of image in numpy array(np.uint8), or list of PIL images
#list_image = list_image.to(device)
texts = clip.tokenize(list_txt).to(device)
images = list_image.to(device)
logits_per_image, logits_per_text = model(images, texts)
if device == "cpu":
ground_truth = torch.arange(batch_size).long().to(device)
else:
#ground_truth = torch.arange(batch_size).half().to(device)
ground_truth = torch.arange(batch_size, dtype=torch.long, device=device)
#反向传播
total_loss = (loss_img(logits_per_image, ground_truth) + loss_txt(logits_per_text, ground_truth)) / 2
optimizer.zero_grad()
total_loss.backward()
if device == "cpu":
optimizer.step()
else:
convert_models_to_fp32(model)
optimizer.step()
clip.model.convert_weights(model)
print('[%d] loss: %.3f' %(i + 1, total_loss))
torch.save(model, './model/model1.pkl')
def main():
epoch = 100
batch_size = 6
learning_rate = 5e-5
cup_path = './data/It is photo with cup'
cupnot_path = './data/It is photo without cup'
train(epoch, batch_size, learning_rate, cup_path, cupnot_path)
if __name__ == '__main__':
main()
更新工程文件:
「CLIP」https://www.aliyundrive.com/s/mM8n836Km5M 提取码: te40
点击链接保存,或者复制本段内容,打开「阿里云盘」APP ,无需下载极速在线查看,视频原画倍速播放。
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我有一个模型:classItem项目有一个属性“商店”基于存储的值,我希望Item对象对特定方法具有不同的行为。Rails中是否有针对此的通用设计模式?如果方法中没有大的if-else语句,这是如何干净利落地完成的? 最佳答案 通常通过Single-TableInheritance. 关于ruby-on-rails-Rails-子类化模型的设计模式是什么?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.co
我在我的项目目录中完成了compasscreate.和compassinitrails。几个问题:我已将我的.sass文件放在public/stylesheets中。这是放置它们的正确位置吗?当我运行compasswatch时,它不会自动编译这些.sass文件。我必须手动指定文件:compasswatchpublic/stylesheets/myfile.sass等。如何让它自动运行?文件ie.css、print.css和screen.css已放在stylesheets/compiled。如何在编译后不让它们重新出现的情况下删除它们?我自己编译的.sass文件编译成compiled/t