在ubuntu20.04上利用tensorrt部署yolov5(C++和Python接口)‘下个博客是yolov7的部署’
一、CUDA、CUDNN、TensorRT以及OpenCV安装
一、CUDA、CUDNN、TensorRT以及OpenCV安装
1、CUDA安装
# CUDA=10.2
# 选择生成软链接,不需要安装驱动
sudo sh cuda_10.2.89_440.33.01_linux.run
# 查看CUDA版本
cat /usr/local/cuda/version.txt
# 测试CUDA,安装成功则显示PASS
cd /usr/local/cuda-9.0/samples/1_Utilities/deviceQuery
sudo make
./deviceQuery
2、CUDNN安装
# CUDNN=8.1.1.33
# 将压缩包解压
sudo cp cuda/include/cudnn.h /usr/local/cuda/include
sudo cp cuda/lib64/libcudnn* /usr/local/cuda/lib64/
sudo chmod a+r /usr/local/cuda/include/cudnn.h /usr/local/cuda/lib64/libcudnn*
# 查看CUDNN版本
cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
3、TensorRT安装
# TensorRT=7.2.3.4(Ubuntu18.08_cuda10.2_cudnn_8.1)
# 解压压缩包,配置环境变量
tar xzvf TensorRT
mv TensorRT-7.2.3.4 /usr/local/
sudo gedit ~/.bashrc
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/TensorRT-7.2.3.4/lib
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/TensorRT-7.2.3.4/include
# 安装TensorRT
cd /usr/local/TensorRT-7.2.3.4/
cd python
# 选择对应的Python版本
pip install tensorrt-7.2.3.4-cp38-none-linux_x86_64.whl
# 安装graphsurgeon
cd ../graphsurgeon
pip install graphsurgeon-0.4.5-py2.py3-none-any.whl
# 安装uff(TensorRT与TensorFlow配合试用时)
cd ../uff
pip install uff-0.6.9-py2.py3-none-any.whl
# 将tensorrt的库和头文件复制到系统路径
cd ..
sudo cp -r ./lib/* /usr/lib
sudo cp -r ./include/* /usr/include
# 安装测试
python # 进入Python环境
import tensorrt
4、OpenCV安装
链接: https://opencv.org/releases/page/4/
# 安装必要的软件包
sudo apt install build-essential
sudo apt install cmake git libgtk2.0-dev pkg-config libavcodec-dev libavformat-dev libswscale-dev
sudo apt install python-dev python-numpy libtbb2 libtbb-dev libjpeg-dev libpng-dev libtiff-dev libjasper-dev libdc1394-22-dev
# 若第三步报错:无法定位软件包libjasper-dev ,安装libjasper-dev的依赖包libjasper1
sudo add-apt-repository "deb http://security.ubuntu.com/ubuntu xenial-security main"
sudo apt update
sudo apt upgrade
sudo apt install libjasper1 libjasper-dev
# opencv-3.4.2
# 下载对应版本的安装包:87.3 MB
# 解压安装包
unzip opencv-3.4.2.zip
# 新建build文件夹
mv opencv-3.4.2 /usr/local/
cd opencv-3.4.2
mkdir build
cd build
# 编译
cmake -D CMAKE_BUILD_TYPE=Release -D CMAKE_INSTALL_PREFIX=/usr/local ..
```python
接下来编译就好了
make
sudo make install
完成后配置OpenCV环境:
```python
# 配置环境
# 打开配置文件
sudo gedit /etc/ld.so.conf
# 添加库文件路径,更新系统共享链接库
include /usr/local/opencv-3.4.2/build/lib
sudo gedit /etc/ld.so.conf.d/opencv.conf
# 添加文本
/usr/local/lib
# 配置文件生效
sudo ldconfig
配置bash:
# 配置 bash
sudo gedit /etc/bash.bashrc
# 添加文本
PKG_CONFIG_PATH=$PKG_CONFIG_PATH:/usr/local/lib/pkgconfig
export PKG_CONFIG_PATH
# 使配置生效
source /etc/bash.bashrc
# 更新
sudo updatedb
验证OpenCV配置完成:
# OpenCV示例测试
cd /usr/local/opencv-3.4.2/samples/cpp/example_cmake
cmake .
make
./opencv_example
# 摄像头打开,出现Hello OpenCV则证明安装成功
二、YOLOv5部署:
所有的操作在Ubuntu系统中进行
深度学习模型部署途径:
方法1:pt --> onnx/torchscript/wts -–> openvino/tensorrt --> 树莓派/jetson(linux)
方法2:pt --> onnx/torchscipt --> ncnn --> 安卓端(android studio)
方法3:pt --> onnx/torchscript --> ML --> ios端(xcode)
1、文件准备:
U版yolov5,下载6.2/最新版本的都支持: https://github.com/ultralytics/yolov5/releases
tensorrtx,下载6.2/最新版本(感谢wangxinyu大神无私分享): https://github.com/wang-xinyu/tensorrtx/tree/yolov5-v6.0
#环境必备
pip install pycuda
2、生成wts文件
以预训练模型yolov5s.pt为例,将其转换为torchscript, onnx, openvino, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs, paddle
现在的yolov5和yolov7已经强大到什么地步了,几乎所有的格式转换都支持,而且现在都支持图像分割和姿态估计。
#进入tensorrt里面,找到yolov5点进去,复制gen_wts.py文件,粘贴到你的U版yolov5项目里,运行这个命令(yolov5.pt自己下载哈):
python gen_wts.py ../../weights/yolov5s.pt ./
#在当前目录生成.wts文件,把生成的wts文件拷贝到tensorrt/yolov5下面
3、生成部署引擎
进入到tensorrtx/yolov5文件中,
想改配置的可以直接在这两个文件里改,作者的注释写的很清楚了:
tensorrtx/yolov5/yololayer.h
tensorrtx/yolov5/yolov5.cpp
mkdir build
cd build
cmake ..
make -j16#电脑不求行的直接make不要-16
#sudo ./yolov5 -s [.wts] [.engine] [s/m/l/x/s6/m6/l6/x6 or c/c6 gd gw]
sudo ./yolov5 -s ../yolov5s.wts yolov5s.engine s
#这样就生成你的tensorrt .engine文件了
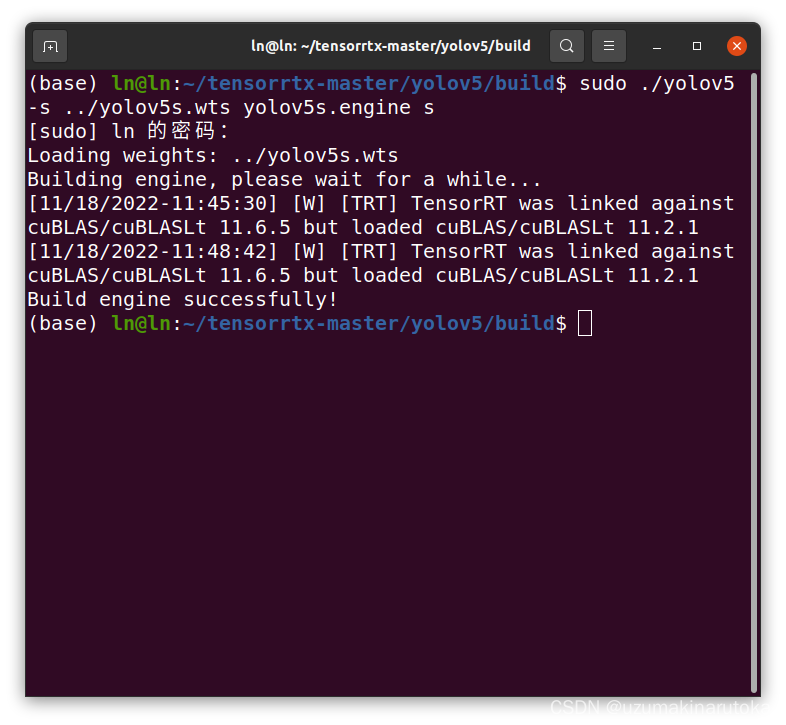
4、端侧部署模型测试图片
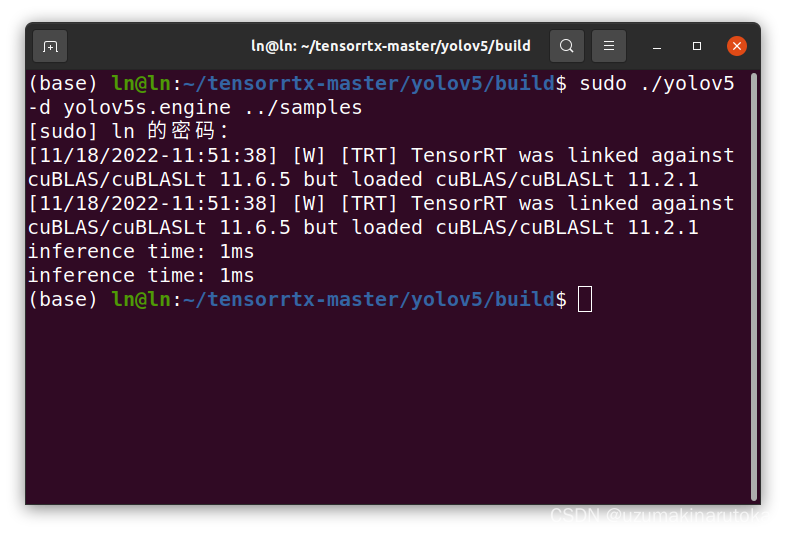
sudo ./yolov5 -d yolov5s.engine ../samples
# sudo ./yolov5 -d [.engine文件] [待检测图片的文件夹]
# 在build文件夹下输出检测图片
Python测试:
# 参数设置:阈值设置
CONF_THRESH = 0.5
IOU_THRESHOLD = 0.4
# 必要文件:
PLUGIN_LIBRARY = "build/libmyplugins.so" #自定义插件文件
engine_file_path = "build/yolov5s.engine" #模型引擎文件
cd ..
python3 yolov5 _trt.py
# 在output文件夹下输出检测图片
5、视频检测:
#include <iostream>
#include <chrono>
#include <cmath>
#include "cuda_utils.h"
#include "logging.h"
#include "common.hpp"
#include "utils.h"
#include "calibrator.h"
#define USE_FP16 // set USE_INT8 or USE_FP16 or USE_FP32
#define DEVICE 0 // GPU id
#define NMS_THRESH 0.4
#define CONF_THRESH 0.5
#define BATCH_SIZE 1
// stuff we know about the network and the input/output blobs
static const int INPUT_H = Yolo::INPUT_H;
static const int INPUT_W = Yolo::INPUT_W;
static const int CLASS_NUM = Yolo::CLASS_NUM;
static const int OUTPUT_SIZE = Yolo::MAX_OUTPUT_BBOX_COUNT * sizeof(Yolo::Detection) / sizeof(float) + 1; // we assume the yololayer outputs no more than MAX_OUTPUT_BBOX_COUNT boxes that conf >= 0.1
const char* INPUT_BLOB_NAME = "data";
const char* OUTPUT_BLOB_NAME = "prob";
static Logger gLogger;
char *my_classes[]={ "person", "bicycle", "car", "motorcycle", "airplane", "bus", "train", "truck", "boat", "traffic light",
"fire hydrant", "stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse", "sheep", "cow",
"elephant", "bear", "zebra", "giraffe", "backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee",
"skis", "snowboard", "sports ball", "kite", "baseball bat", "baseball glove", "skateboard","surfboard",
"tennis racket", "bottle", "wine glass", "cup", "fork", "knife", "spoon", "bowl", "banana", "apple",
"sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza", "donut", "cake", "chair", "couch",
"potted plant", "bed", "dining table", "toilet", "tv", "laptop", "mouse", "remote", "keyboard", "cell phone",
"microwave", "oven", "toaster", "sink", "refrigerator", "book", "clock", "vase", "scissors", "teddy bear",
"hair drier", "toothbrush" };
static int get_width(int x, float gw, int divisor = 8) {
//return math.ceil(x / divisor) * divisor
if (int(x * gw) % divisor == 0) {
return int(x * gw);
}
return (int(x * gw / divisor) + 1) * divisor;
}
static int get_depth(int x, float gd) {
if (x == 1) {
return 1;
} else {
return round(x * gd) > 1 ? round(x * gd) : 1;
}
}
ICudaEngine* build_engine(unsigned int maxBatchSize, IBuilder* builder, IBuilderConfig* config, DataType dt, float& gd, float& gw, std::string& wts_name) {
INetworkDefinition* network = builder->createNetworkV2(0U);
// Create input tensor of shape {3, INPUT_H, INPUT_W} with name INPUT_BLOB_NAME
ITensor* data = network->addInput(INPUT_BLOB_NAME, dt, Dims3{ 3, INPUT_H, INPUT_W });
assert(data);
std::map<std::string, Weights> weightMap = loadWeights(wts_name);
/* ------ yolov5 backbone------ */
auto focus0 = focus(network, weightMap, *data, 3, get_width(64, gw), 3, "model.0");
auto conv1 = convBlock(network, weightMap, *focus0->getOutput(0), get_width(128, gw), 3, 2, 1, "model.1");
auto bottleneck_CSP2 = C3(network, weightMap, *conv1->getOutput(0), get_width(128, gw), get_width(128, gw), get_depth(3, gd), true, 1, 0.5, "model.2");
auto conv3 = convBlock(network, weightMap, *bottleneck_CSP2->getOutput(0), get_width(256, gw), 3, 2, 1, "model.3");
auto bottleneck_csp4 = C3(network, weightMap, *conv3->getOutput(0), get_width(256, gw), get_width(256, gw), get_depth(9, gd), true, 1, 0.5, "model.4");
auto conv5 = convBlock(network, weightMap, *bottleneck_csp4->getOutput(0), get_width(512, gw), 3, 2, 1, "model.5");
auto bottleneck_csp6 = C3(network, weightMap, *conv5->getOutput(0), get_width(512, gw), get_width(512, gw), get_depth(9, gd), true, 1, 0.5, "model.6");
auto conv7 = convBlock(network, weightMap, *bottleneck_csp6->getOutput(0), get_width(1024, gw), 3, 2, 1, "model.7");
auto spp8 = SPP(network, weightMap, *conv7->getOutput(0), get_width(1024, gw), get_width(1024, gw), 5, 9, 13, "model.8");
/* ------ yolov5 head ------ */
auto bottleneck_csp9 = C3(network, weightMap, *spp8->getOutput(0), get_width(1024, gw), get_width(1024, gw), get_depth(3, gd), false, 1, 0.5, "model.9");
auto conv10 = convBlock(network, weightMap, *bottleneck_csp9->getOutput(0), get_width(512, gw), 1, 1, 1, "model.10");
auto upsample11 = network->addResize(*conv10->getOutput(0));
assert(upsample11);
upsample11->setResizeMode(ResizeMode::kNEAREST);
upsample11->setOutputDimensions(bottleneck_csp6->getOutput(0)->getDimensions());
ITensor* inputTensors12[] = { upsample11->getOutput(0), bottleneck_csp6->getOutput(0) };
auto cat12 = network->addConcatenation(inputTensors12, 2);
auto bottleneck_csp13 = C3(network, weightMap, *cat12->getOutput(0), get_width(1024, gw), get_width(512, gw), get_depth(3, gd), false, 1, 0.5, "model.13");
auto conv14 = convBlock(network, weightMap, *bottleneck_csp13->getOutput(0), get_width(256, gw), 1, 1, 1, "model.14");
auto upsample15 = network->addResize(*conv14->getOutput(0));
assert(upsample15);
upsample15->setResizeMode(ResizeMode::kNEAREST);
upsample15->setOutputDimensions(bottleneck_csp4->getOutput(0)->getDimensions());
ITensor* inputTensors16[] = { upsample15->getOutput(0), bottleneck_csp4->getOutput(0) };
auto cat16 = network->addConcatenation(inputTensors16, 2);
auto bottleneck_csp17 = C3(network, weightMap, *cat16->getOutput(0), get_width(512, gw), get_width(256, gw), get_depth(3, gd), false, 1, 0.5, "model.17");
// yolo layer 0
IConvolutionLayer* det0 = network->addConvolutionNd(*bottleneck_csp17->getOutput(0), 3 * (Yolo::CLASS_NUM + 5), DimsHW{ 1, 1 }, weightMap["model.24.m.0.weight"], weightMap["model.24.m.0.bias"]);
auto conv18 = convBlock(network, weightMap, *bottleneck_csp17->getOutput(0), get_width(256, gw), 3, 2, 1, "model.18");
ITensor* inputTensors19[] = { conv18->getOutput(0), conv14->getOutput(0) };
auto cat19 = network->addConcatenation(inputTensors19, 2);
auto bottleneck_csp20 = C3(network, weightMap, *cat19->getOutput(0), get_width(512, gw), get_width(512, gw), get_depth(3, gd), false, 1, 0.5, "model.20");
//yolo layer 1
IConvolutionLayer* det1 = network->addConvolutionNd(*bottleneck_csp20->getOutput(0), 3 * (Yolo::CLASS_NUM + 5), DimsHW{ 1, 1 }, weightMap["model.24.m.1.weight"], weightMap["model.24.m.1.bias"]);
auto conv21 = convBlock(network, weightMap, *bottleneck_csp20->getOutput(0), get_width(512, gw), 3, 2, 1, "model.21");
ITensor* inputTensors22[] = { conv21->getOutput(0), conv10->getOutput(0) };
auto cat22 = network->addConcatenation(inputTensors22, 2);
auto bottleneck_csp23 = C3(network, weightMap, *cat22->getOutput(0), get_width(1024, gw), get_width(1024, gw), get_depth(3, gd), false, 1, 0.5, "model.23");
IConvolutionLayer* det2 = network->addConvolutionNd(*bottleneck_csp23->getOutput(0), 3 * (Yolo::CLASS_NUM + 5), DimsHW{ 1, 1 }, weightMap["model.24.m.2.weight"], weightMap["model.24.m.2.bias"]);
auto yolo = addYoLoLayer(network, weightMap, "model.24", std::vector<IConvolutionLayer*>{det0, det1, det2});
yolo->getOutput(0)->setName(OUTPUT_BLOB_NAME);
network->markOutput(*yolo->getOutput(0));
// Build engine
builder->setMaxBatchSize(maxBatchSize);
config->setMaxWorkspaceSize(16 * (1 << 20)); // 16MB
#if defined(USE_FP16)
config->setFlag(BuilderFlag::kFP16);
#elif defined(USE_INT8)
std::cout << "Your platform support int8: " << (builder->platformHasFastInt8() ? "true" : "false") << std::endl;
assert(builder->platformHasFastInt8());
config->setFlag(BuilderFlag::kINT8);
Int8EntropyCalibrator2* calibrator = new Int8EntropyCalibrator2(1, INPUT_W, INPUT_H, "./coco_calib/", "int8calib.table", INPUT_BLOB_NAME);
config->setInt8Calibrator(calibrator);
#endif
std::cout << "Building engine, please wait for a while..." << std::endl;
ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);
std::cout << "Build engine successfully!" << std::endl;
// Don't need the network any more
network->destroy();
// Release host memory
for (auto& mem : weightMap)
{
free((void*)(mem.second.values));
}
return engine;
}
ICudaEngine* build_engine_p6(unsigned int maxBatchSize, IBuilder* builder, IBuilderConfig* config, DataType dt, float& gd, float& gw, std::string& wts_name) {
INetworkDefinition* network = builder->createNetworkV2(0U);
// Create input tensor of shape {3, INPUT_H, INPUT_W} with name INPUT_BLOB_NAME
ITensor* data = network->addInput(INPUT_BLOB_NAME, dt, Dims3{ 3, INPUT_H, INPUT_W });
assert(data);
std::map<std::string, Weights> weightMap = loadWeights(wts_name);
/* ------ yolov5 backbone------ */
auto focus0 = focus(network, weightMap, *data, 3, get_width(64, gw), 3, "model.0");
auto conv1 = convBlock(network, weightMap, *focus0->getOutput(0), get_width(128, gw), 3, 2, 1, "model.1");
auto c3_2 = C3(network, weightMap, *conv1->getOutput(0), get_width(128, gw), get_width(128, gw), get_depth(3, gd), true, 1, 0.5, "model.2");
auto conv3 = convBlock(network, weightMap, *c3_2->getOutput(0), get_width(256, gw), 3, 2, 1, "model.3");
auto c3_4 = C3(network, weightMap, *conv3->getOutput(0), get_width(256, gw), get_width(256, gw), get_depth(9, gd), true, 1, 0.5, "model.4");
auto conv5 = convBlock(network, weightMap, *c3_4->getOutput(0), get_width(512, gw), 3, 2, 1, "model.5");
auto c3_6 = C3(network, weightMap, *conv5->getOutput(0), get_width(512, gw), get_width(512, gw), get_depth(9, gd), true, 1, 0.5, "model.6");
auto conv7 = convBlock(network, weightMap, *c3_6->getOutput(0), get_width(768, gw), 3, 2, 1, "model.7");
auto c3_8 = C3(network, weightMap, *conv7->getOutput(0), get_width(768, gw), get_width(768, gw), get_depth(3, gd), true, 1, 0.5, "model.8");
auto conv9 = convBlock(network, weightMap, *c3_8->getOutput(0), get_width(1024, gw), 3, 2, 1, "model.9");
auto spp10 = SPP(network, weightMap, *conv9->getOutput(0), get_width(1024, gw), get_width(1024, gw), 3, 5, 7, "model.10");
auto c3_11 = C3(network, weightMap, *spp10->getOutput(0), get_width(1024, gw), get_width(1024, gw), get_depth(3, gd), false, 1, 0.5, "model.11");
/* ------ yolov5 head ------ */
auto conv12 = convBlock(network, weightMap, *c3_11->getOutput(0), get_width(768, gw), 1, 1, 1, "model.12");
auto upsample13 = network->addResize(*conv12->getOutput(0));
assert(upsample13);
upsample13->setResizeMode(ResizeMode::kNEAREST);
upsample13->setOutputDimensions(c3_8->getOutput(0)->getDimensions());
ITensor* inputTensors14[] = { upsample13->getOutput(0), c3_8->getOutput(0) };
auto cat14 = network->addConcatenation(inputTensors14, 2);
auto c3_15 = C3(network, weightMap, *cat14->getOutput(0), get_width(1536, gw), get_width(768, gw), get_depth(3, gd), false, 1, 0.5, "model.15");
auto conv16 = convBlock(network, weightMap, *c3_15->getOutput(0), get_width(512, gw), 1, 1, 1, "model.16");
auto upsample17 = network->addResize(*conv16->getOutput(0));
assert(upsample17);
upsample17->setResizeMode(ResizeMode::kNEAREST);
upsample17->setOutputDimensions(c3_6->getOutput(0)->getDimensions());
ITensor* inputTensors18[] = { upsample17->getOutput(0), c3_6->getOutput(0) };
auto cat18 = network->addConcatenation(inputTensors18, 2);
auto c3_19 = C3(network, weightMap, *cat18->getOutput(0), get_width(1024, gw), get_width(512, gw), get_depth(3, gd), false, 1, 0.5, "model.19");
auto conv20 = convBlock(network, weightMap, *c3_19->getOutput(0), get_width(256, gw), 1, 1, 1, "model.20");
auto upsample21 = network->addResize(*conv20->getOutput(0));
assert(upsample21);
upsample21->setResizeMode(ResizeMode::kNEAREST);
upsample21->setOutputDimensions(c3_4->getOutput(0)->getDimensions());
ITensor* inputTensors21[] = { upsample21->getOutput(0), c3_4->getOutput(0) };
auto cat22 = network->addConcatenation(inputTensors21, 2);
auto c3_23 = C3(network, weightMap, *cat22->getOutput(0), get_width(512, gw), get_width(256, gw), get_depth(3, gd), false, 1, 0.5, "model.23");
auto conv24 = convBlock(network, weightMap, *c3_23->getOutput(0), get_width(256, gw), 3, 2, 1, "model.24");
ITensor* inputTensors25[] = { conv24->getOutput(0), conv20->getOutput(0) };
auto cat25 = network->addConcatenation(inputTensors25, 2);
auto c3_26 = C3(network, weightMap, *cat25->getOutput(0), get_width(1024, gw), get_width(512, gw), get_depth(3, gd), false, 1, 0.5, "model.26");
auto conv27 = convBlock(network, weightMap, *c3_26->getOutput(0), get_width(512, gw), 3, 2, 1, "model.27");
ITensor* inputTensors28[] = { conv27->getOutput(0), conv16->getOutput(0) };
auto cat28 = network->addConcatenation(inputTensors28, 2);
auto c3_29 = C3(network, weightMap, *cat28->getOutput(0), get_width(1536, gw), get_width(768, gw), get_depth(3, gd), false, 1, 0.5, "model.29");
auto conv30 = convBlock(network, weightMap, *c3_29->getOutput(0), get_width(768, gw), 3, 2, 1, "model.30");
ITensor* inputTensors31[] = { conv30->getOutput(0), conv12->getOutput(0) };
auto cat31 = network->addConcatenation(inputTensors31, 2);
auto c3_32 = C3(network, weightMap, *cat31->getOutput(0), get_width(2048, gw), get_width(1024, gw), get_depth(3, gd), false, 1, 0.5, "model.32");
/* ------ detect ------ */
IConvolutionLayer* det0 = network->addConvolutionNd(*c3_23->getOutput(0), 3 * (Yolo::CLASS_NUM + 5), DimsHW{ 1, 1 }, weightMap["model.33.m.0.weight"], weightMap["model.33.m.0.bias"]);
IConvolutionLayer* det1 = network->addConvolutionNd(*c3_26->getOutput(0), 3 * (Yolo::CLASS_NUM + 5), DimsHW{ 1, 1 }, weightMap["model.33.m.1.weight"], weightMap["model.33.m.1.bias"]);
IConvolutionLayer* det2 = network->addConvolutionNd(*c3_29->getOutput(0), 3 * (Yolo::CLASS_NUM + 5), DimsHW{ 1, 1 }, weightMap["model.33.m.2.weight"], weightMap["model.33.m.2.bias"]);
IConvolutionLayer* det3 = network->addConvolutionNd(*c3_32->getOutput(0), 3 * (Yolo::CLASS_NUM + 5), DimsHW{ 1, 1 }, weightMap["model.33.m.3.weight"], weightMap["model.33.m.3.bias"]);
auto yolo = addYoLoLayer(network, weightMap, "model.33", std::vector<IConvolutionLayer*>{det0, det1, det2, det3});
yolo->getOutput(0)->setName(OUTPUT_BLOB_NAME);
network->markOutput(*yolo->getOutput(0));
// Build engine
builder->setMaxBatchSize(maxBatchSize);
config->setMaxWorkspaceSize(16 * (1 << 20)); // 16MB
#if defined(USE_FP16)
config->setFlag(BuilderFlag::kFP16);
#elif defined(USE_INT8)
std::cout << "Your platform support int8: " << (builder->platformHasFastInt8() ? "true" : "false") << std::endl;
assert(builder->platformHasFastInt8());
config->setFlag(BuilderFlag::kINT8);
Int8EntropyCalibrator2* calibrator = new Int8EntropyCalibrator2(1, INPUT_W, INPUT_H, "./coco_calib/", "int8calib.table", INPUT_BLOB_NAME);
config->setInt8Calibrator(calibrator);
#endif
std::cout << "Building engine, please wait for a while..." << std::endl;
ICudaEngine* engine = builder->buildEngineWithConfig(*network, *config);
std::cout << "Build engine successfully!" << std::endl;
// Don't need the network any more
network->destroy();
// Release host memory
for (auto& mem : weightMap)
{
free((void*)(mem.second.values));
}
return engine;
}
void APIToModel(unsigned int maxBatchSize, IHostMemory** modelStream, float& gd, float& gw, std::string& wts_name) {
// Create builder
IBuilder* builder = createInferBuilder(gLogger);
IBuilderConfig* config = builder->createBuilderConfig();
// Create model to populate the network, then set the outputs and create an engine
ICudaEngine* engine = build_engine(maxBatchSize, builder, config, DataType::kFLOAT, gd, gw, wts_name);
assert(engine != nullptr);
// Serialize the engine
(*modelStream) = engine->serialize();
// Close everything down
engine->destroy();
builder->destroy();
config->destroy();
}
void doInference(IExecutionContext& context, cudaStream_t& stream, void **buffers, float* input, float* output, int batchSize) {
// DMA input batch data to device, infer on the batch asynchronously, and DMA output back to host
CUDA_CHECK(cudaMemcpyAsync(buffers[0], input, batchSize * 3 * INPUT_H * INPUT_W * sizeof(float), cudaMemcpyHostToDevice, stream));
context.enqueue(batchSize, buffers, stream, nullptr);
CUDA_CHECK(cudaMemcpyAsync(output, buffers[1], batchSize * OUTPUT_SIZE * sizeof(float), cudaMemcpyDeviceToHost, stream));
cudaStreamSynchronize(stream);
}
bool parse_args(int argc, char** argv, std::string& engine) {
if (argc < 3) return false;
if (std::string(argv[1]) == "-v" && argc == 3) {
engine = std::string(argv[2]);
} else {
return false;
}
return true;
}
int main(int argc, char** argv) {
cudaSetDevice(DEVICE);
//std::string wts_name = "";
std::string engine_name = "";
//float gd = 0.0f, gw = 0.0f;
//std::string img_dir;
if(!parse_args(argc,argv,engine_name)){
std::cerr << "arguments not right!" << std::endl;
std::cerr << "./yolov5 -v [.engine] // run inference with camera" << std::endl;
return -1;
}
std::ifstream file(engine_name, std::ios::binary);
if (!file.good()) {
std::cerr<<" read "<<engine_name<<" error! "<<std::endl;
return -1;
}
char *trtModelStream{ nullptr };
size_t size = 0;
file.seekg(0, file.end);
size = file.tellg();
file.seekg(0, file.beg);
trtModelStream = new char[size];
assert(trtModelStream);
file.read(trtModelStream, size);
file.close();
// prepare input data ---------------------------
static float data[BATCH_SIZE * 3 * INPUT_H * INPUT_W];
//for (int i = 0; i < 3 * INPUT_H * INPUT_W; i++)
// data[i] = 1.0;
static float prob[BATCH_SIZE * OUTPUT_SIZE];
IRuntime* runtime = createInferRuntime(gLogger);
assert(runtime != nullptr);
ICudaEngine* engine = runtime->deserializeCudaEngine(trtModelStream, size);
assert(engine != nullptr);
IExecutionContext* context = engine->createExecutionContext();
assert(context != nullptr);
delete[] trtModelStream;
assert(engine->getNbBindings() == 2);
void* buffers[2];
// In order to bind the buffers, we need to know the names of the input and output tensors.
// Note that indices are guaranteed to be less than IEngine::getNbBindings()
const int inputIndex = engine->getBindingIndex(INPUT_BLOB_NAME);
const int outputIndex = engine->getBindingIndex(OUTPUT_BLOB_NAME);
assert(inputIndex == 0);
assert(outputIndex == 1);
// Create GPU buffers on device
CUDA_CHECK(cudaMalloc(&buffers[inputIndex], BATCH_SIZE * 3 * INPUT_H * INPUT_W * sizeof(float)));
CUDA_CHECK(cudaMalloc(&buffers[outputIndex], BATCH_SIZE * OUTPUT_SIZE * sizeof(float)));
// Create stream
cudaStream_t stream;
CUDA_CHECK(cudaStreamCreate(&stream));
cv::VideoCapture capture(0);
//cv::VideoCapture capture("../overpass.mp4");
//int fourcc = cv::VideoWriter::fourcc('M','J','P','G');
//capture.set(cv::CAP_PROP_FOURCC, fourcc);
if(!capture.isOpened()){
std::cout << "Error opening video stream or file" << std::endl;
return -1;
}
int key;
int fcount = 0;
while(1)
{
cv::Mat frame;
capture >> frame;
if(frame.empty())
{
std::cout << "Fail to read image from camera!" << std::endl;
break;
}
fcount++;
//if (fcount < BATCH_SIZE && f + 1 != (int)file_names.size()) continue;
for (int b = 0; b < fcount; b++) {
//cv::Mat img = cv::imread(img_dir + "/" + file_names[f - fcount + 1 + b]);
cv::Mat img = frame;
if (img.empty()) continue;
cv::Mat pr_img = preprocess_img(img, INPUT_W, INPUT_H); // letterbox BGR to RGB
int i = 0;
for (int row = 0; row < INPUT_H; ++row) {
uchar* uc_pixel = pr_img.data + row * pr_img.step;
for (int col = 0; col < INPUT_W; ++col) {
data[b * 3 * INPUT_H * INPUT_W + i] = (float)uc_pixel[2] / 255.0;
data[b * 3 * INPUT_H * INPUT_W + i + INPUT_H * INPUT_W] = (float)uc_pixel[1] / 255.0;
data[b * 3 * INPUT_H * INPUT_W + i + 2 * INPUT_H * INPUT_W] = (float)uc_pixel[0] / 255.0;
uc_pixel += 3;
++i;
}
}
}
// Run inference
auto start = std::chrono::system_clock::now();
doInference(*context, stream, buffers, data, prob, BATCH_SIZE);
auto end = std::chrono::system_clock::now();
//std::cout << std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count() << "ms" << std::endl;
int fps = 1000.0/std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();
std::vector<std::vector<Yolo::Detection>> batch_res(fcount);
for (int b = 0; b < fcount; b++) {
auto& res = batch_res[b];
nms(res, &prob[b * OUTPUT_SIZE], CONF_THRESH, NMS_THRESH);
}
for (int b = 0; b < fcount; b++) {
auto& res = batch_res[b];
//std::cout << res.size() << std::endl;
//cv::Mat img = cv::imread(img_dir + "/" + file_names[f - fcount + 1 + b]);
for (size_t j = 0; j < res.size(); j++) {
cv::Rect r = get_rect(frame, res[j].bbox);
cv::rectangle(frame, r, cv::Scalar(0x27, 0xC1, 0x36), 2);
std::string label = my_classes[(int)res[j].class_id];
cv::putText(frame, label, cv::Point(r.x, r.y - 1), cv::FONT_HERSHEY_PLAIN, 1.2, cv::Scalar(0xFF, 0xFF, 0xFF), 2);
//add FPS in the windows
// std::string jetson_fps = "Jetson NX FPS: " + std::to_string(fps);
// cv::putText(frame, jetson_fps, cv::Point(11,80), cv::FONT_HERSHEY_PLAIN, 3, cv::Scalar(0, 0, 255), 2, cv::LINE_AA);
}
//cv::imwrite("_" + file_names[f - fcount + 1 + b], img);
}
cv::imshow("yolov5",frame);
key = cv::waitKey(1);
if (key == 'q'){
break;
}
fcount = 0;
}
capture.release();
// Release stream and buffers
cudaStreamDestroy(stream);
CUDA_CHECK(cudaFree(buffers[inputIndex]));
CUDA_CHECK(cudaFree(buffers[outputIndex]));
// Destroy the engine
context->destroy();
engine->destroy();
runtime->destroy();
return 0;
}
用以上代码替换原来的yolov5.cpp,然后重新编译:
cd tensorrtx/yolov5/build
cmake ..
make
sudo ./yolov5 -v yolov5s.engine
https://blog.csdn.net/qq_36786467/article/details/121218402
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我试过重新启动apache,缓存的页面仍然出现,所以一定有一个文件夹在某个地方。我没有“公共(public)/缓存”,那么我还应该查看哪些其他地方?是否有一个URL标志也可以触发此效果? 最佳答案 您需要触摸一个文件才能清除phusion,例如:touch/webapps/mycook/tmp/restart.txt参见docs 关于ruby-如何在Ubuntu中清除RubyPhusionPassenger的缓存?,我们在StackOverflow上找到一个类似的问题:
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m
我想解析一个已经存在的.mid文件,改变它的乐器,例如从“acousticgrandpiano”到“violin”,然后将它保存回去或作为另一个.mid文件。根据我在文档中看到的内容,该乐器通过program_change或patch_change指令进行了更改,但我找不到任何在已经存在的MIDI文件中执行此操作的库.他们似乎都只支持从头开始创建的MIDI文件。 最佳答案 MIDIpackage会为您完成此操作,但具体方法取决于midi文件的原始内容。一个MIDI文件由一个或多个音轨组成,每个音轨是十六个channel中任何一个上的
本文主要介绍在使用Selenium进行自动化测试或者任务时,对于使用了iframe的页面,如何定位iframe中的元素文章目录场景描述解决方案具体代码场景描述当我们在使用Selenium进行自动化测试的时候,可能会遇到一些界面或者窗体是使用HTML的iframe标签进行承载的。对于iframe中的标签,如果直接查找是无法找到的,会抛出没有找到元素的异常。比如近在咫尺的例子就是,CSDN的登录窗体就是使用的iframe,大家可以尝试通过F12开发者模式查看到的tag_name,class_name,id或者xpath来定位中的页面元素,会抛出NoSuchElementException异常。解决
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc