通常选取前12个系数,再拼接一个当前frame的能量,共13个。
越靠前的系数,包含越多的基频和共振峰的信息。
取得13个系数后,还会在时序上,对13个系数求一阶差分和二阶差分,二阶差分等价于对一阶差分求一阶差分。一阶差分有后向差分、前向差分的区别,也可以对后向差分和前向差分求均值得到中心差分,中心差分误差最小:
其中, x [ n ] x[n] x[n]表示第n帧的13个系数,将一阶差分和二阶差分与原函数值拼接起来,得到39个系数。
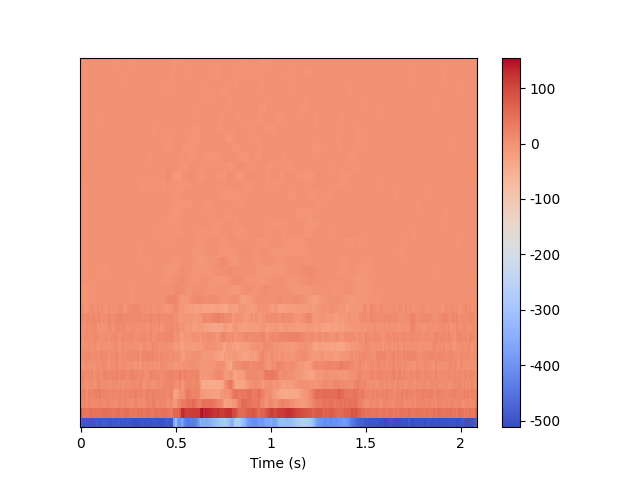
MFCC的输出可以表示为一个二维数组,shape为 [ n m f c c , f r a m e s ] [n_{mfcc},frames] [nmfcc,frames],由于是二维数组,所以可以用热力图可视化。
import librosa
import librosa.display
import matplotlib.pyplot as plt
import numpy as np
if "__main__" == __name__:
filepath = r"20- Extracting MFCCs with Python\female_audio.wav"
signal, sr = librosa.load(path=filepath, sr=16000)
N_FFT = 512
N_MELS = 80
N_MFCC = 13
mel_spec = librosa.feature.melspectrogram(y=signal,
sr=sr,
n_fft=N_FFT,
hop_length=sr // 100,
win_length=sr // 40,
n_mels=N_MELS)
mfcc = librosa.feature.mfcc(S=librosa.power_to_db(mel_spec), n_mfcc=N_MFCC)
delta_mfcc = librosa.feature.delta(data=mfcc)
delta2_mfcc = librosa.feature.delta(data=mfcc, order=2)
mfcc = np.concatenate([mfcc, delta_mfcc, delta2_mfcc], axis=0)
librosa.display.specshow(data=mfcc,
sr=sr,
n_fft=N_FFT,
hop_length=sr // 100,
win_length=sr // 40,
x_axis="s")
plt.colorbar(format="%d")
plt.show()
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
Transformers开始在视频识别领域的“猪突猛进”,各种改进和魔改层出不穷。由此作者将开启VideoTransformer系列的讲解,本篇主要介绍了FBAI团队的TimeSformer,这也是第一篇使用纯Transformer结构在视频识别上的文章。如果觉得有用,就请点赞、收藏、关注!paper:https://arxiv.org/abs/2102.05095code(offical):https://github.com/facebookresearch/TimeSformeraccept:ICML2021author:FacebookAI一、前言Transformers(VIT)在图
关闭。这个问题不符合StackOverflowguidelines.它目前不接受答案。我们不允许提问寻求书籍、工具、软件库等的推荐。您可以编辑问题,以便用事实和引用来回答。关闭3年前。Improvethisquestion我正处于学习Ruby的阶段,我想查看一些小型库的源代码以了解它们是如何构建的。我不知道什么是小型图书馆,但希望SO能推荐一些易于理解的图书馆来学习。因此,如果有人知道一两个非常小的库,这是新手Rubyists学习的好例子,请推荐!我想使用Manveru'sInnatelib,因为它试图保持在2000LOC以下,但我还不熟悉其中经常使用的Ruby速记。也许大约100-5
由于匿名block和散列block看起来大致相同。我正在玩它。我做了一些严肃的观察,如下所示:{}.class#=>Hash好的,这很酷。空block被视为Hash。print{}.class#=>NilClassputs{}.class#=>NilClass为什么上面的代码和NilClass一样,下面的代码又显示了Hash?puts({}.class)#Hash#=>nilprint({}.class)#Hash=>nil谁能帮我理解上面发生了什么?我完全不同意@Lindydancer的观点你如何解释下面几行:print{}.class#NilClassprint[].class#A
我很难理解Ruby中sender和receiver的实际含义。它们一般是什么意思?到目前为止,我只是将它们理解为方法调用和获取其返回值的调用。但是,我知道我的理解还远远不够。谁能给我一个Ruby中发送者和接收者的具体解释? 最佳答案 面向对象中的一个核心概念是消息传递和早期概念化,这在很大程度上借鉴了计算的Actor模型。艾伦·凯(AlanKay)创造了面向对象一词并发明了最早的OO语言之一SmallTalk,他拥有voicedregretatusingatermwhichputthefocusonobjectsinsteadofo
rails新手。只是想了解\assests目录中的这两个文件。例如,application.js文件有如下行://=requirejquery//=requirejquery_ujs//=require_tree.我理解require_tree。只是将所有JS文件添加到当前目录中。根据上下文,我可以看出requirejquery添加了jQuery库。但是它从哪里得到这些jQuery库呢?我没有在我的Assets文件夹中看到任何jquery.js文件——或者直接在我的整个应用程序中没有看到任何jquery.js文件?同样,我正在按照一些说明安装TwitterBootstrap(http:
有没有一种有效的方法来做到这一点。我有一个数组a=[1,2,2,3,1,2]我想按升序输出出现的频率。示例[[3,1],[1,2],[2,3]]这是我的ruby代码。b=a.group_by{|x|x}out={}b.eachdo|k,v|out[k]=v.sizeendout.sort_by{|k,v|v} 最佳答案 a=[1,2,2,3,1,2]a.each_with_object(Hash.new(0)){|m,h|h[m]+=1}.sort_by{|k,v|v}#=>[[3,1],[1,2],[2,3]]
我在某些代码中遇到了三元组,但我无法理解条件:str.split(/',\s*'/).mapdo|match|match[0]==?,?match:"somestring"end.join我确实理解我是在某些点上拆分字符串并将总结果转换为数组,然后依次处理数组的每个元素。除此之外,我不知道发生了什么。 最佳答案 一种(稍微)不那么令人困惑的写法是:str.split(/',\s*'/).mapdo|match|ifmatch[0]==?,matchelse"somestring"endend.join我认为多行三元语句很糟糕,尤其是
有没有人成功地将S3存储桶读取为子文件夹?文件夹1--子文件夹2----文件3----文件4--文件1--文件2文件夹2--子文件夹3--文件5--文件6我的任务是读取文件夹1。我希望看到子文件夹2、文件1和文件2,但看不到文件3或文件4。现在,因为我将存储桶键限制为prefix=>'folder1/',你仍然会得到file3和4,因为它们在技术上具有folder1前缀。似乎真正做到这一点的唯一方法是吸收folder1下的所有键,然后使用字符串搜索从结果数组中实际排除file3和file4。有没有人有过这方面的经验?我知道像Transmit和Cyberduck这样的FTP风格的S3
关于yolov5训练时参数workers和batch-size的理解yolov5训练命令workers和batch-size参数的理解两个参数的调优总结yolov5训练命令python.\train.py--datamy.yaml--workers8--batch-size32--epochs100yolov5的训练很简单,下载好仓库,装好依赖后,只需自定义一下data目录中的yaml文件就可以了。这里我使用自定义的my.yaml文件,里面就是定义数据集位置和训练种类数和名字。workers和batch-size参数的理解一般训练主要需要调整的参数是这两个:workers指数据装载时cpu所使