昨晚跟我妈语音
妈:我年纪有点大了,想抱孩子了
我:妈,我都多大了,你还想抱我?
妈:我想抱小孩,谁乐意抱你呀!
我:刚好小区有人想找月嫂,要不我帮你联系下?
妈:你给我滚
然后她直接把语音给挂了

还记得记一次 Druid 超时配置的问题 → 引发对 Druid 时间配置项的探究遗留的问题吗?
如果同时设置 DataSource 的 queryTimeout 和 JdbcTemplate 的 queryTimeout ,那么哪个 queryTimeout 生效?
想快速知道答案,做法很简单,两个都设置,看生效的是哪个
示例代码:druid-timeout
我们在原来的基础上改一下:加上这两个配置项,用单线程测试就行了
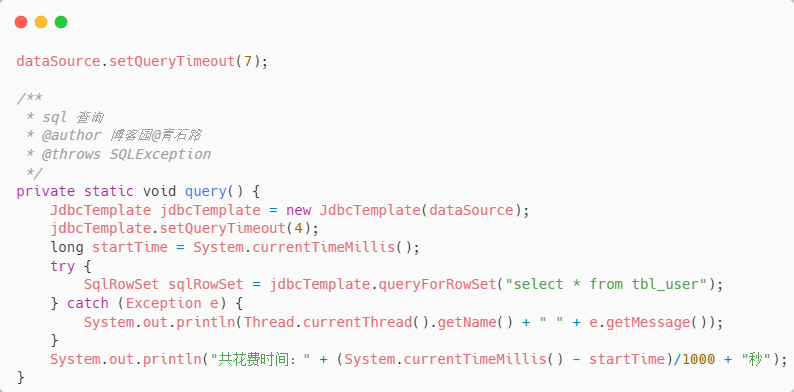
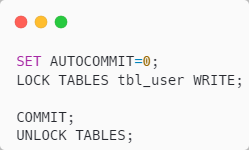
测试方式和之前一样,给 tbl_user 表加写锁
我们来看下花费时长
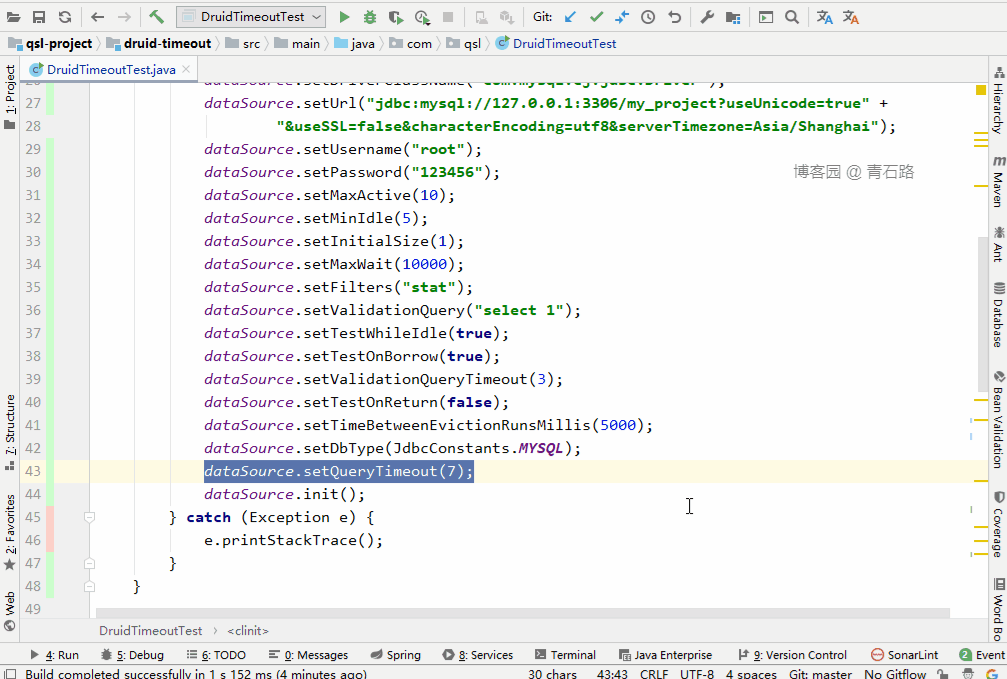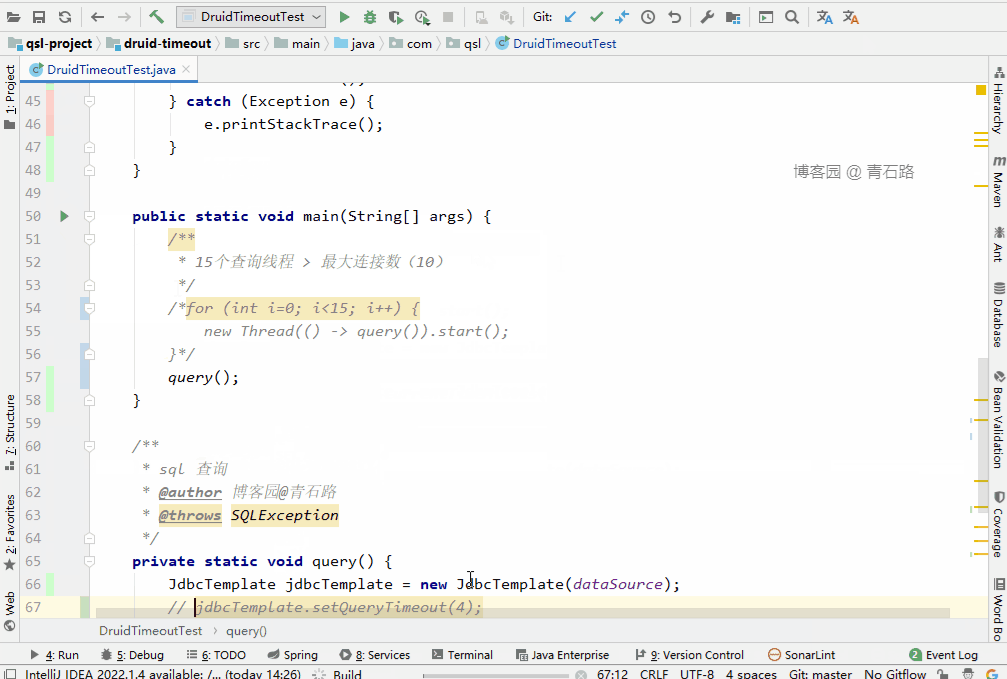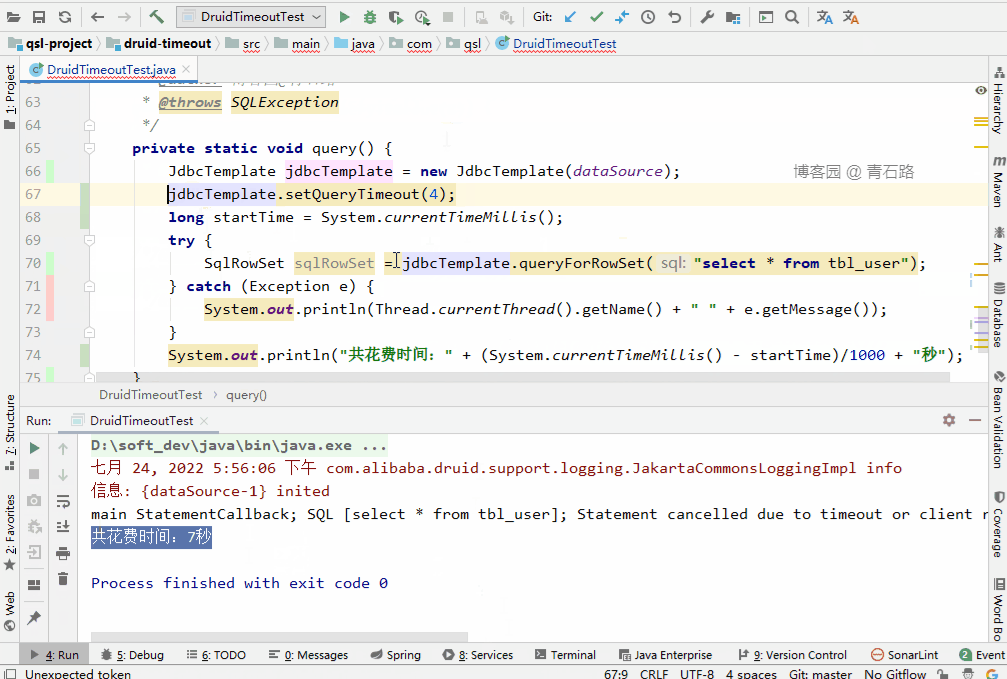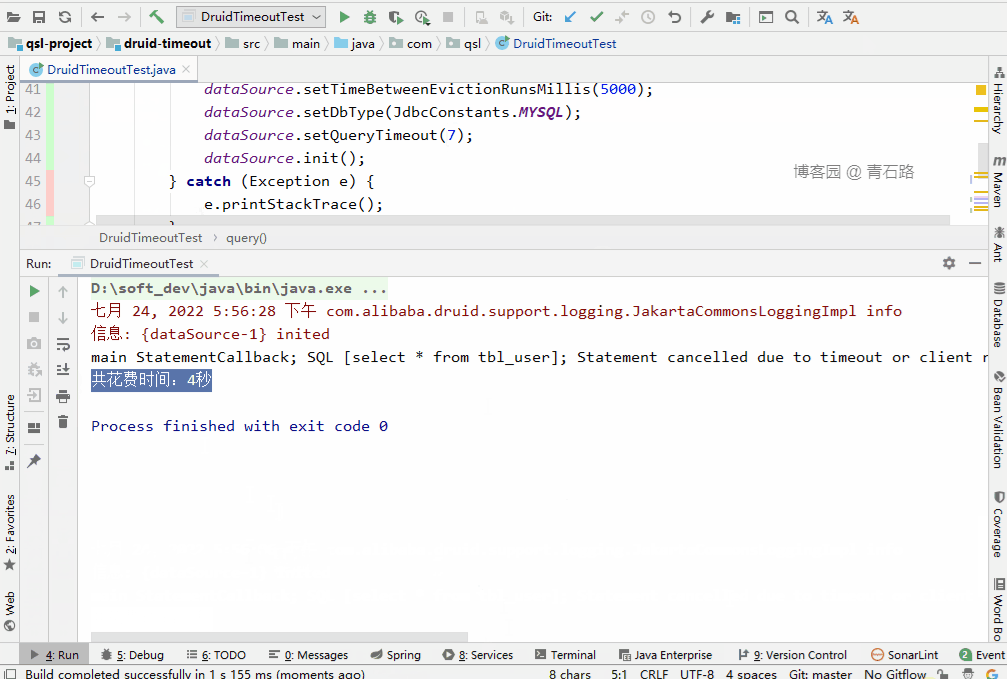
结果很明了: JdbcTemplate 的 queryTimeout 生效
想知道为什么,跟源码呗

我们重点看
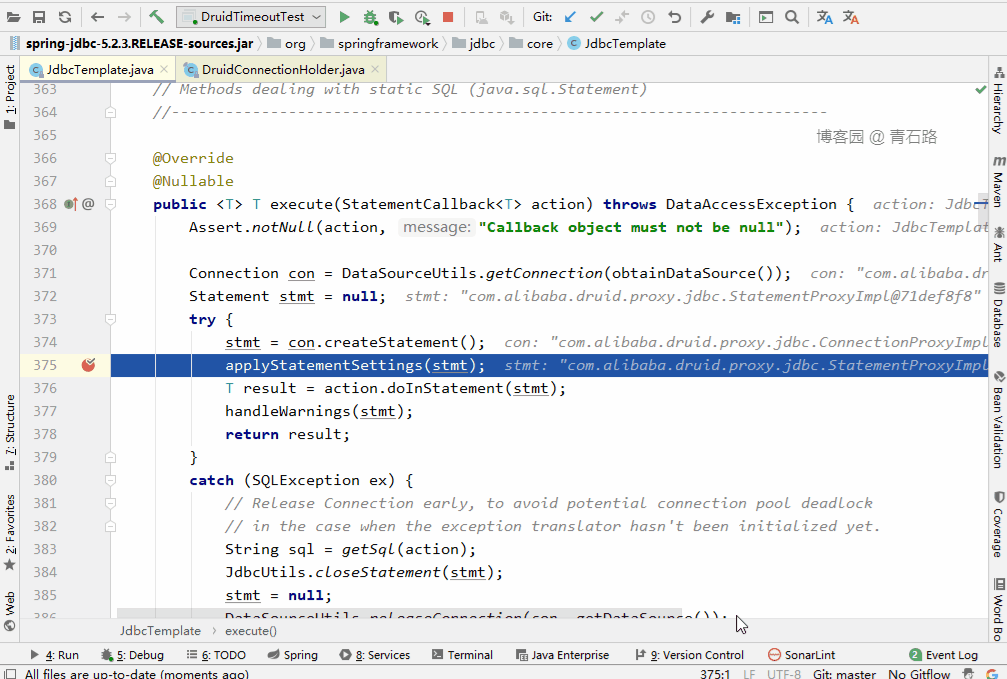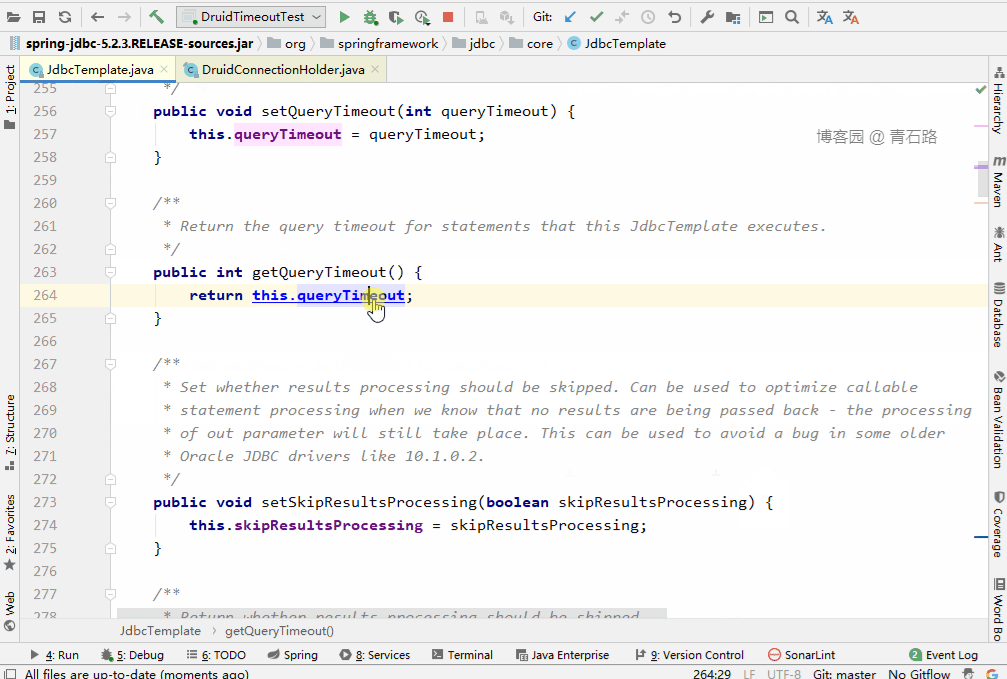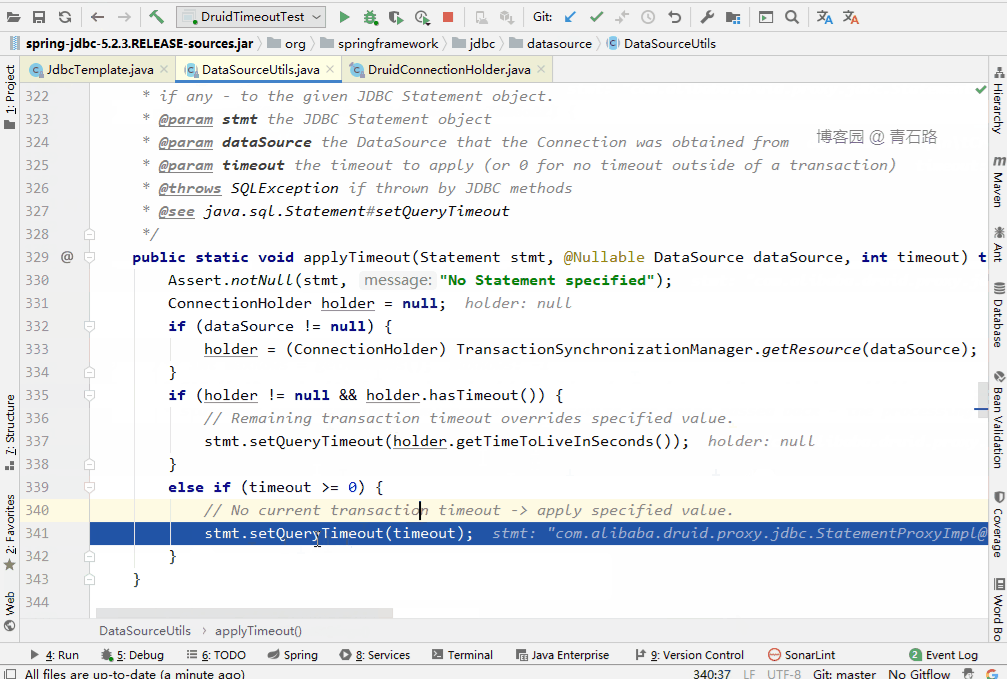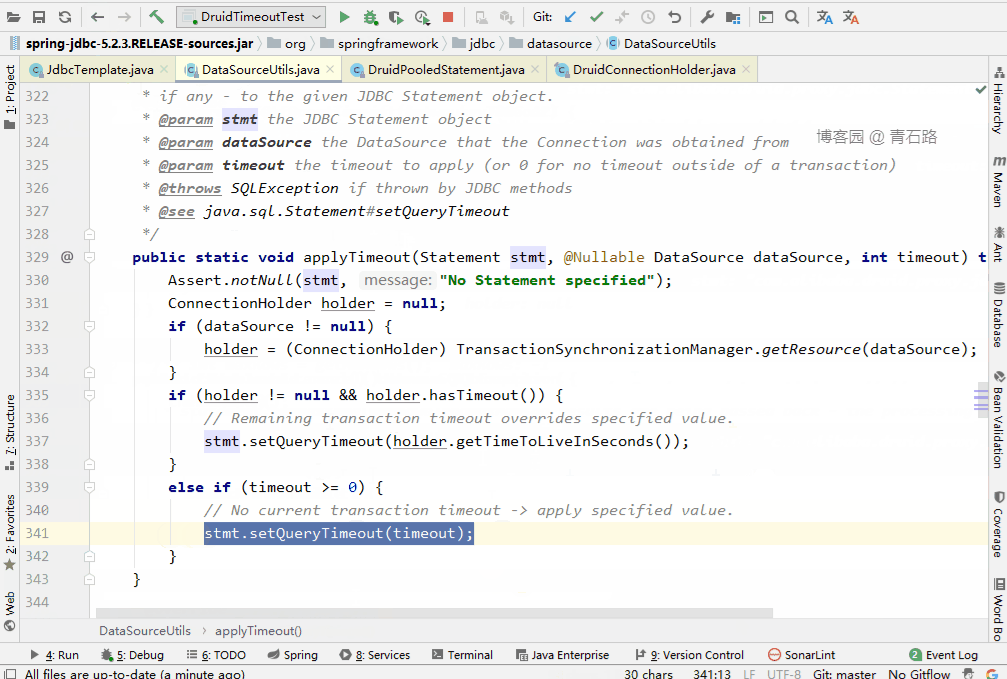
通过方法名我们大致能猜到其作用,我们具体看 queryTimeout 相关的内容
大家仔细看,别跟丢了哦
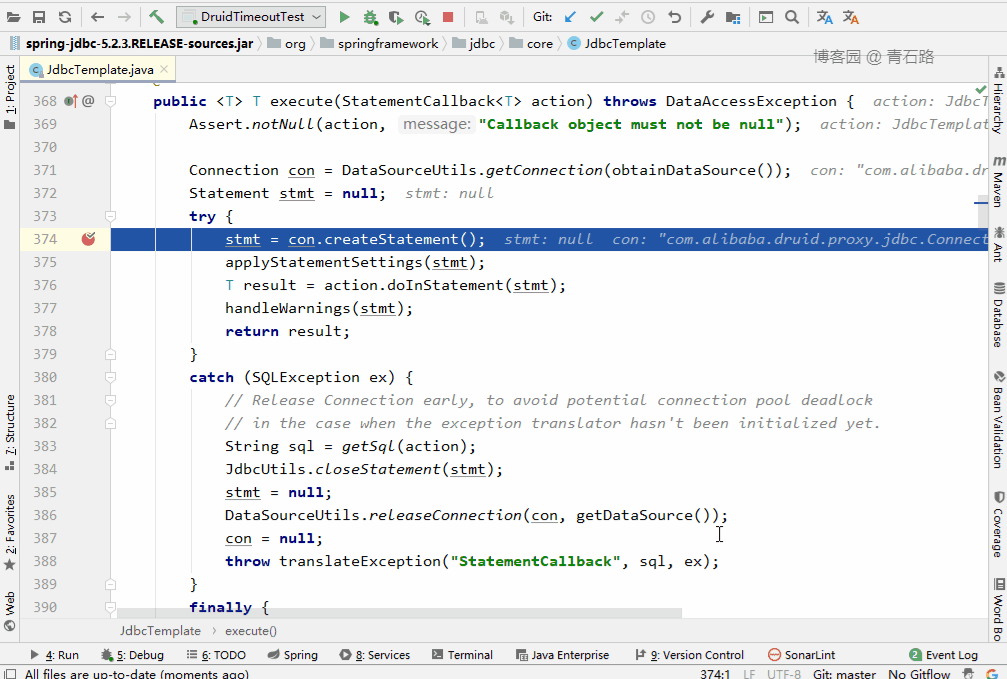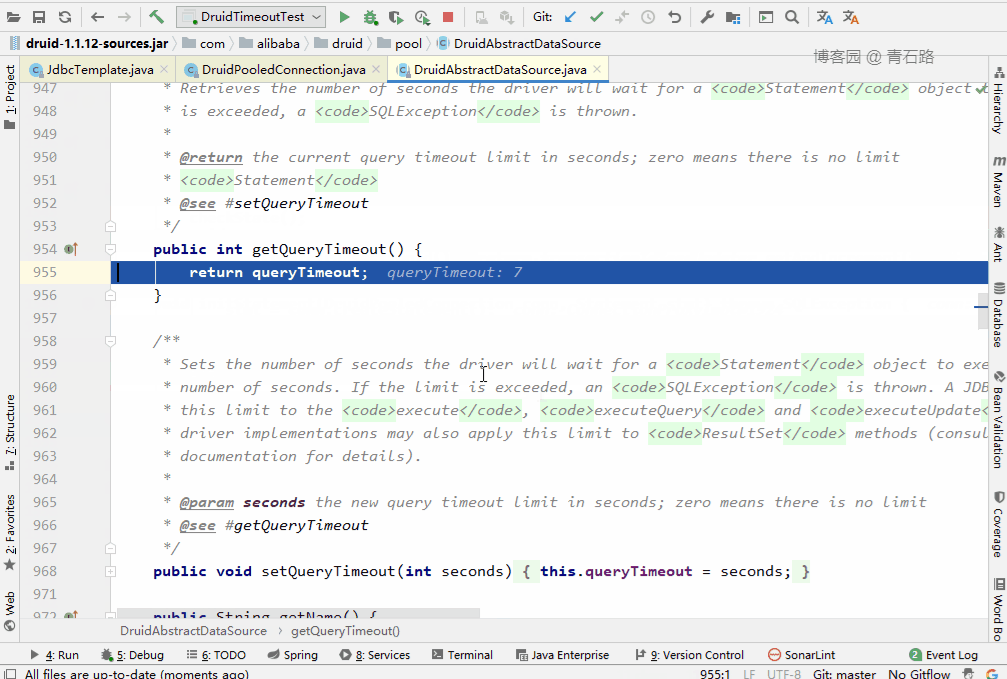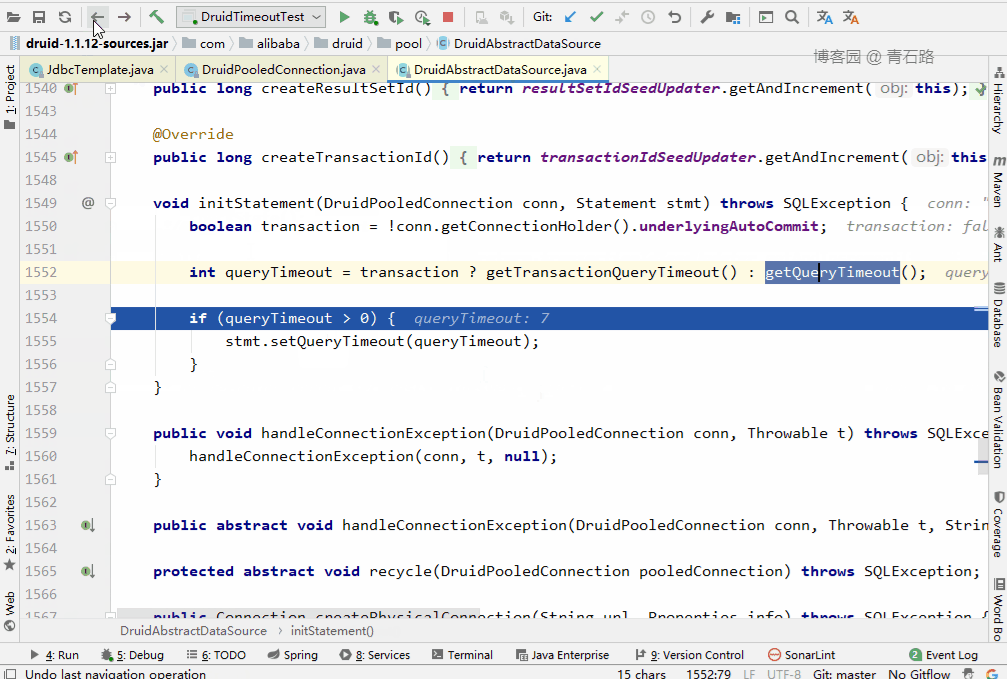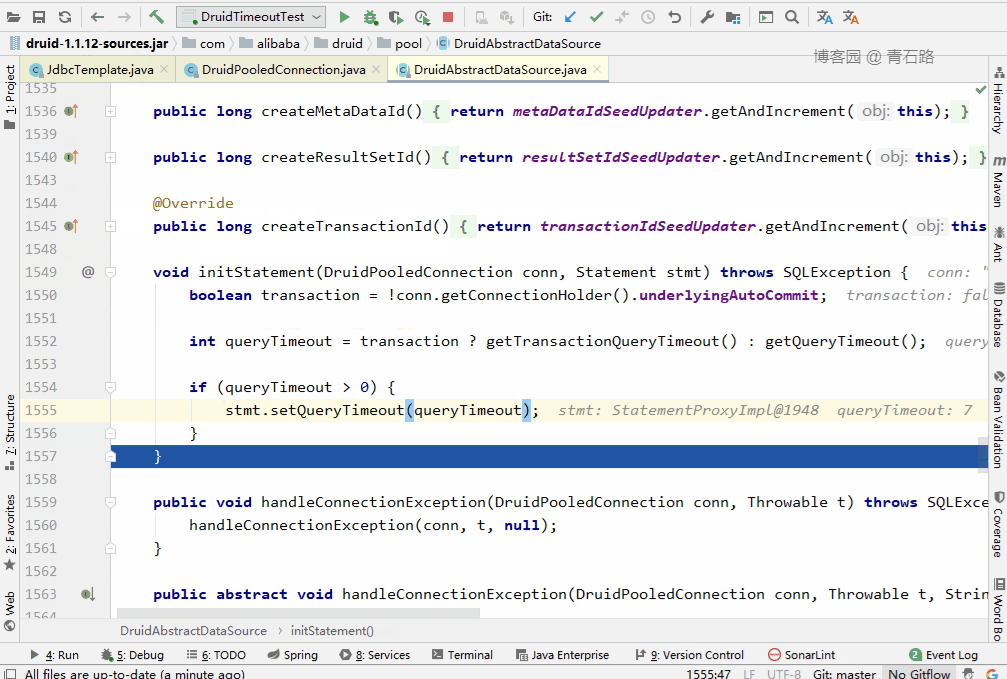
可以看到看到此时 stmt.setQueryTimeout(queryTimeout) 设置的是 DataSource 的 queryTimeout ,也就是 7 秒
这里有个细节值得大家留意下

不是简单的将 DataSource 的 queryTimeout 赋值给 Statement
有兴趣的可以去看看 DataSource 的 transactionQueryTimeout 和 defaultAutoCommit 的相关源码,这里就不跟了
可以看到,又重置成 JdbcTemplate 的 queryTimeout 了
至此,相信大家已经明了了
假设配置了 queryTimeout ,思考如下三种情况
1、如果配置 transactionQueryTimeout
2、如果配置了 defaultAutoCommit 会出现什么情况
3、如果同时配置了 transactionQueryTimeout 和 defaultAutoCommit ,又会出现什么情况
关于 queryTimeout ,相信大家已经清楚了(未考虑 transactionQueryTimeout )

从源码可以看出, queryTimeout 配置项生效的过程还有其他配置项参与了逻辑,而非简单的直接赋值,大家可以琢磨下为什么这么实现
我正在用Ruby编写一个简单的程序来检查域列表是否被占用。基本上它循环遍历列表,并使用以下函数进行检查。require'rubygems'require'whois'defcheck_domain(domain)c=Whois::Client.newc.query("google.com").available?end程序不断出错(即使我在google.com中进行硬编码),并打印以下消息。鉴于该程序非常简单,我已经没有什么想法了-有什么建议吗?/Library/Ruby/Gems/1.8/gems/whois-2.0.2/lib/whois/server/adapters/base.
我有一个在Linux服务器上运行的ruby脚本。它不使用rails或任何东西。它基本上是一个命令行ruby脚本,可以像这样传递参数:./ruby_script.rbarg1arg2如何将参数抽象到配置文件(例如yaml文件或其他文件)中?您能否举例说明如何做到这一点?提前谢谢你。 最佳答案 首先,您可以运行一个写入YAML配置文件的独立脚本:require"yaml"File.write("path_to_yaml_file",[arg1,arg2].to_yaml)然后,在您的应用中阅读它:require"yaml"arg
我知道我可以指定某些字段来使用pluck查询数据库。ids=Item.where('due_at但是我想知道,是否有一种方法可以指定我想避免从数据库查询的某些字段。某种反拔?posts=Post.where(published:true).do_not_lookup(:enormous_field) 最佳答案 Model#attribute_names应该返回列/属性数组。您可以排除其中一些并传递给pluck或select方法。像这样:posts=Post.where(published:true).select(Post.attr
我已经在Sinatra上创建了应用程序,它代表了一个简单的API。我想在生产和开发上进行部署。我想在部署时选择,是开发还是生产,一些方法的逻辑应该改变,这取决于部署类型。是否有任何想法,如何完成以及解决此问题的一些示例。例子:我有代码get'/api/test'doreturn"Itisdev"end但是在部署到生产环境之后我想在运行/api/test之后看到ItisPROD如何实现? 最佳答案 根据SinatraDocumentation:EnvironmentscanbesetthroughtheRACK_ENVenvironm
有没有办法在这个简单的get方法中添加超时选项?我正在使用法拉第3.3。Faraday.get(url)四处寻找,我只能先发起连接后应用超时选项,然后应用超时选项。或者有什么简单的方法?这就是我现在正在做的:conn=Faraday.newresponse=conn.getdo|req|req.urlurlreq.options.timeout=2#2secondsend 最佳答案 试试这个:conn=Faraday.newdo|conn|conn.options.timeout=20endresponse=conn.get(url
之前在培训新生的时候,windows环境下配置opencv环境一直教的都是网上主流的vsstudio配置属性表,但是这个似乎对新生来说难度略高(虽然个人觉得完全是他们自己的问题),加之暑假之后对cmake实在是爱不释手,且这样配置确实十分简单(其实都不需要配置),故斗胆妄言vscode下配置CV之法。其实极为简单,图比较多所以很长。如果你看此文还配不好,你应该思考一下是不是自己的问题。闲话少说,直接开始。0.CMkae简介有的人到大二了都不知道cmake是什么,我不说是谁。CMake是一个开源免费并且跨平台的构建工具,可以用简单的语句来描述所有平台的编译过程。它能够根据当前所在平台输出对应的m
注意:本文主要掌握DCN自研无线产品的基本配置方法和注意事项,能够进行一般的项目实施、调试与运维AP基本配置命令AP登录用户名和密码均为:adminAP默认IP地址为:192.168.1.10AP默认情况下DHCP开启AP静态地址配置:setmanagementstatic-ip192.168.10.1AP开启/关闭DHCP功能:setmanagementdhcp-statusup/downAP设置默认网关:setstatic-ip-routegeteway192.168.10.254查看AP基本信息:getsystemgetmanagementgetmanaged-apgetrouteAP配
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
我正在尝试查询我的Rails数据库(Postgres)中的购买表,我想查询时间范围。例如,我想知道在所有日期的下午2点到3点之间进行了多少次购买。此表中有一个created_at列,但我不知道如何在不搜索特定日期的情况下完成此操作。我试过:Purchases.where("created_atBETWEEN?and?",Time.now-1.hour,Time.now)但这最终只会搜索今天与那些时间的日期。 最佳答案 您需要使用PostgreSQL'sdate_part/extractfunction从created_at中提取小时
使用rails4,ruby2。我在rails配置中为我的cookiesession设置了30分钟的超时时间。问题是,如果我转到表单,让session超时,然后提交表单,我会收到此ActionController::InvalidAuthenticityToken错误。如何在Rails中优雅地处理这个错误?比如说,重定向到登录屏幕? 最佳答案 在您的ApplicationController:rescue_fromActionController::InvalidAuthenticityTokendoredirect_tosome_p