
在AIGC取得举世瞩目成就的背后,基于大模型、多模态的研究范式也在不断地推陈出新。微软研究院作为这一研究领域的佼佼者,与图灵奖得主、深度学习三巨头之一的Yoshua Bengio一起提出了AIGC新范式——Regeneration Learning。这一新范式究竟会带来哪些创新变革?本文作者将带来他的深度解读。
作者 | 谭旭
AIGC(AI-Generated Content)在近年来受到了广泛关注,基于深度学习的内容生成在图像、视频、语音、音乐、文本等生成领域取得了非常瞩目的成就。不同于传统的数据理解任务通常采用表征学习(Representation Learning)范式来学习数据的抽象表征,数据生成任务需要刻画数据的整体分布而不是抽象表征,需要一个新的学习范式来指导处理数据生成的建模问题。
为此,微软研究院的研究员和深度学习/表征学习先驱Yoshua Bengio一起,通过梳理典型的数据生成任务以及建模流程,抽象出面向数据生成任务的学习范式Regeneration Learning。该学习范式适合多种数据生成任务(图像/视频/语音/音乐/文本生成等),能够为开发设计数据生成的模型方法提供新的洞见和指导。

论文:Regeneration Learning: A Learning Paradigm for Data Generation
链接:https://arxiv.org/abs/2301.08846

为什么是Regeneration Learning?
什么是数据理解与数据生成?
机器学习中一类典型的任务是学习一个从源数据X到目标数据Y的映射,比如在图像分类中X是图像而Y是类别标签,在文本到语音合成中X是文本而Y是语音。根据X和Y含有信息量的不同,可以将这种映射分成数据理解(Data Understanding)、数据生成(Data Generation)以及两者兼有的任务。图1显示了这三种任务以及X和Y含有的相对信息。
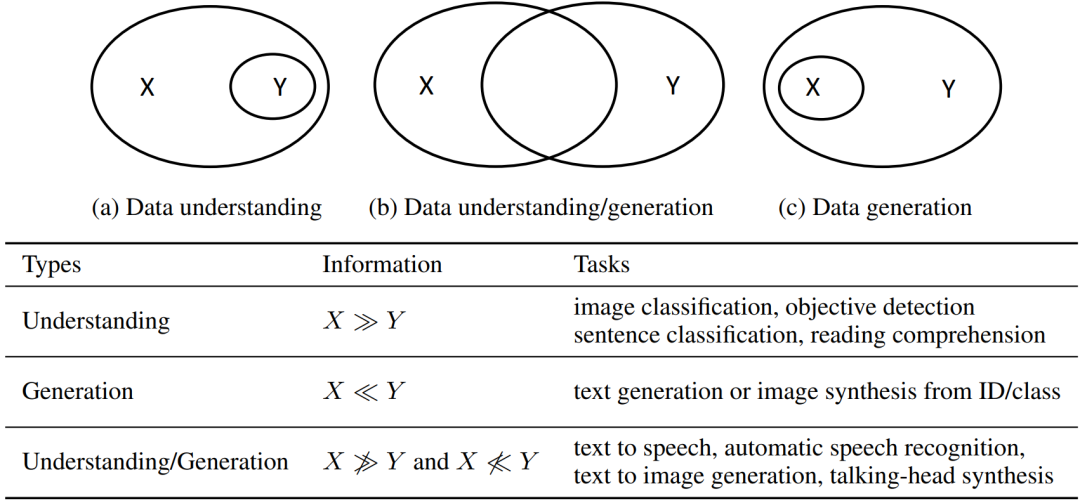
图1:机器学习中常见的三种任务类型以及X和Y含有的相对信息量
X和Y的信息差异导致了采用不同的方法来解决不同的任务:
对于数据理解任务,X通常比较高维、复杂并且比Y含有更多的信息,所以任务的核心是从X学习抽象表征来预测Y。因此,深度学习中非常火热的表征学习(Representation Learning,比如基于自监督学习的大规模预训练)适合处理这类任务。
对于数据生成任务,Y通常比较高维、复杂并且比X含有更多的信息,所以任务的核心是刻画Y的分布以及从X生成Y。
对于数据理解和生成兼有的任务,它们需要分别处理两者的问题。
数据生成任务面临的独特挑战
数据生成任务面临独特的挑战包括:
因为Y含有很多X不含有的信息,生成模型面临严重的一对多映射(One-to-Many Mapping)问题,增加了学习难度。比如在图像生成中,类别标签“狗”对应不同的狗的图片,如果没有合理地学习这种一对多的映射,会导致训练集上出现过拟合,在测试集上泛化性很差。
对于一些生成任务(比如文本到语音合成,语音到说话人脸生成等),X和Y的信息量相当,会有两种问题,一种是X到Y的映射不是一一对应,会面临上面提到的一对多映射问题,另一种是X和Y含有虚假关联(Spurious Correlation,比如在语音到说话人脸生成中,输入语音的音色和目标说话人脸视频中的头部姿态没有太大关联关系),会导致模型学习到虚假映射出现过拟合。

为什么需要Regeneration Learning
深度生成模型(比如对抗生成网络GAN、变分自编码器VAE、自回归模型AR、标准化流模型Flow、扩散模型Diffusion等)在数据生成任务上取得了非常大的进展,在理想情况下可以拟合任何数据分布以实现复杂的数据生成。但是,在实际情况中,由于数据映射太复杂,计算代价太大以及数据稀疏性问题等,它们不能很好地拟合复杂的数据分布以及一对多映射和虚假映射问题。类比于数据理解任务,尽管强大的模型,比如Transformer已经取得了不错的效果,但是表征学习(近年来的大规模自监督学习比如预训练)还是能大大提升性能。数据生成任务也迫切需要一个类似于表征学习的范式来指导建模。
因此,我们针对数据生成任务提出了Regeneration Learning学习范式。相比于直接从X生成Y,Regeneration Learning先从X生成一个目标数据的抽象表征Y’,然后再从Y’生成Y。这样做有两点好处:
X→Y’ 相比于X→Y的一对多映射和虚假映射问题会减轻;
Y’→Y的映射可以通过自监督学习利用大规模的无标注数据进行预训练。

Regeneration Learning的形式
Regeneration Learning的基本形式/Regeneration Learning的步骤
Regeneration Learning一般需要三步,包括:
将Y转化成抽象表征Y’。转换方法大体上可分为显式和隐式两种,如表1中Basic Formulation所示:显式转换包括数学变换(比如傅里叶变换,小波变换),模态转换(比如语音文本处理中使用的字形到音形的变换),数据分析挖掘(比如从音乐数据抽取音乐特征或者从人脸图片中抽取3D表征),下采样(比如将256*256图片下采样到64*64图片)等;隐式转换,比如通过端到端学习抽取中间表征(一些常用的方法包括变分自编码器VAE,量化自编码器VQ-VAE和VQ-GAN,基于扩散模型的自编码器Diffusion-AE)。
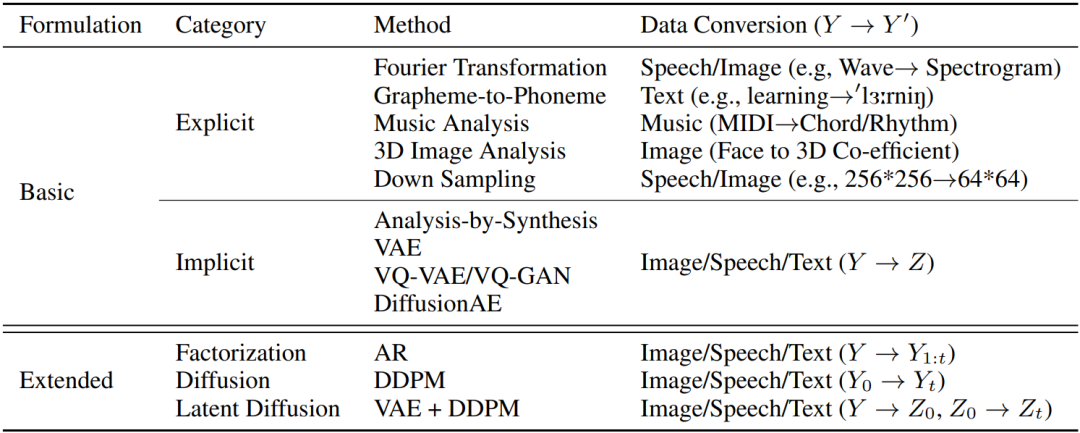
表1:Y→Y’转换的不同方法
步骤2:从X生成Y’。可以使用任何生成模型或者转换方法,以方便做X→Y’映射。
步骤3:从Y’生成Y。通常采用自监督学习,如果从Y转化为Y’采用的是隐式转换学习比如变分自编码器,那可以使用学习到的解码器来从Y’生成Y。
如表1中Extended Formulation所示,一些方法可以看成是Regeneration Learning的扩展版本,比如自回归模型AR,扩散模型Diffusion,以及迭代式的非自回归模型等。在自回归模型中,Y_{<t}可以看成是Y_{<t+1}的简化表征,在Diffusion模型中,Y_{t+1}可以看成是Y_{t}的简化表征,和基础版的Regeneration Learning不同的是,它们都需要多步生成而不是两步生成。
Regeneration Learning和Representation Learning的关系
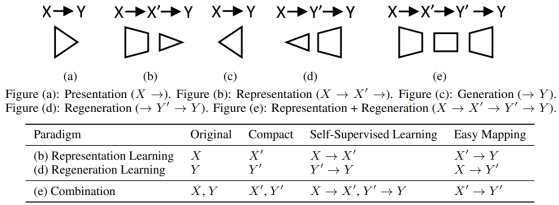
图2:Regeneration Learning和Representation Learning的对比
如图2所示,Regeneration Learning可以看成是传统的Representation Learning在数据生成任务中的对应:
Regeneration Learning处理目标数据Y的抽象表征Y’来帮助生成,而传统的Representation Learning处理源数据X的抽象表征X’来帮助理解;
Regeneration Learning中的Y’→Y和Representation Learning中的X→X’ 都可以通过自监督的方式学习(比如大规模预训练);
Regeneration Learning中的X→Y’和Representation Learning中的X’→Y都比原来的X→Y更加简单。

Regeneration Learning的方法研究以及实际应用
Regeneration Learning的研究机会
Regeneration Learning作为一种面向数据生成的学习范式,有比较多的研究问题。如表2所示,包括如何从Y获取Y’以及如何更好地学习X→Y’以及Y’→Y等,详细信息可参见论文。

表2:Regeneration Learning的研究问题
Regeneration Learning在数据生成任务中的应用条件
Regeneration Learning在语音、音频、音乐、图像、视频、文本等生成中有着广泛的应用,包括文本到语音合成,语音到文本识别,歌词/视频到旋律生成,语音到说话人脸生成,图像/视频/音频生成等,如表3所示。

表3:一些利用Regeneration Learning的数据生成任务
总的来讲,只要满足以下几点要求,都可以使用Regeneration Learning:
目标数据太高维复杂;
X和Y有比较复杂的映射关系,比如一对多映射和虚假映射;
X和Y缺少足够的配对数据。
最近流行的数据生成模型及其在Regeneration Learning范式下的表示
下面简单梳理了近年来在AIGC内容生成领域的一些典型的模型方法,比如文本到图像生成模型DALL-E 1、DALL-E 2和Stable Diffusion,文本到音频生成模型AudioLM和AudioGen,文本到音乐生成模型MusicLM,文本生成模型GPT-3/ChatGPT,它们都可以被看作是采用了Regeneration Learning类似的思想,如表4所示。
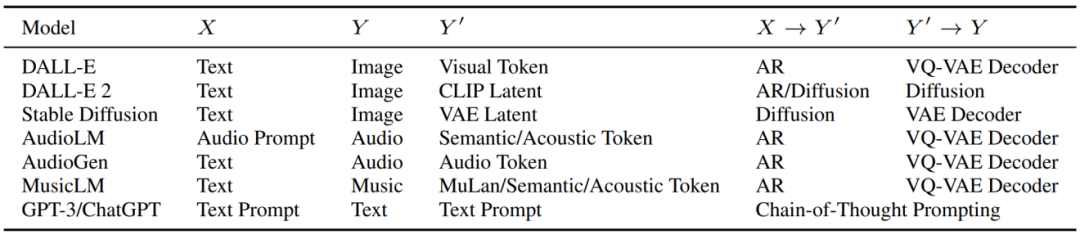
表4:最近比较受关注的数据生成模型及其在Regeneration Learning范式下的表示
机器学习/深度学习依赖于学习范式指导处理各种学习问题,例如传统的机器学习,包括有监督学习、无监督学习、强化学习等学习范式。在深度学习中,有针对数据理解任务的表征学习。微软研究员们和深度学习/表征学习先驱Yoshua Bengio一起面向数据生成任务提出了针对性的学习范式Regeneration Learning,希望能指导解决数据生成任务中的各种问题。微软亚洲研究院机器学习组的研究员们,将Regeneration Learning的思想应用到各类生成任务中,比如文本到语音合成,歌词到旋律生成,语音到说话人脸生成等,详情请见:https://ai-creation.github.io/。

结语
本篇文章介绍了微软亚洲研究院机器学习组在AIGC数据生成方面的研究范式工作,首先指出了数据生成面临的挑战以及新的学习范式的必要性,然后介绍了Regeneration Learning的具体形式、与Representation Learning的关系、当前流行的数据生成模型在该范式下的表示,以及Regeneration Learning潜在的研究机会。希望Regeneration Learning能够很好地指导解决数据生成任务中的各种问题。在这一研究方向上,机器学习组还开展了模型结构和建模方法以及具体的生成任务方面的研究,欢迎继续关注我们的其他文章!
作者简介

谭旭,微软亚洲研究院高级研究员
研究领域为深度学习及AI内容生成。发表论文100余篇,研究工作如预训练语言模型MASS、语音合成模型FastSpeech、AI音乐项目Muzic受到业界关注,多项成果应用于微软产品中。研究主页:https://ai-creation.github.io/

目录前言一、什么是AIGC?1、什么是PGC?2、什么是UGC?3、什么是PUCG?4、什么是AIGC?二、总结前言很明显,ChatGPT的爆火,带动了AIGC(AI-GeneratedContent)概念的火热。一、什么是AIGC?GC,全称GeneratedContent,是指创作内容。与之相对应的概念中,有PGC、UGC、PUGC、AIGC。1、什么是PGC?PGC,全称ProfessionalGeneratedContent,指专业生产内容。专业生产内容模式,主要表现为由专家或者机构来进行内容的生产,具备专业的内容生产能力,能够保证内容的专业性。主要应用在知识付费、在线教育、学习平台等
很难说出这里要问什么。这个问题模棱两可、含糊不清、不完整、过于宽泛或夸夸其谈,无法以目前的形式得到合理的回答。如需帮助澄清此问题以便重新打开,visitthehelpcenter.关闭11年前。哪些模板引擎/模板语言是图灵完备的?到目前为止,我听说过这些:FreeMarker(用java实现)MovableTypes模板语言(perl)xslt:-(Cheetah(Python语言)聪明(PHP)还有其他的(特别是用perl实现的)吗?Ps:不要浪费时间向我解释MVC,以及为什么图灵完整模板不好,以及为什么这不是一个有用的比较点:)
一、什么是web项目ui自动化测试?通过测试工具模拟人为操控浏览器,使软件按照测试人员的预定计划自动执行测试的一种方式,可以完成许多手工测试无法完成或者不易实现的繁琐工作。正确使用自动化测试,可以更全面的对软件进行测试,从而提高软件质量进而缩短迭代周期。二、构建测试用例的“九部曲”(一)创建流程包划分功能模块日常测试活动中,都会根据功能模块进行拆分,所以在设计器中我们可以通过创建流程包的方式来拆分需要测试的功能模块,如下图中操作创建一个电脑流程包并且取名为对应的功能模块名称,如果有多个功能模块就创建多个对应的流程包,实在RPA设计器有易用的图形可视化界面,方便管理较多的功能模块。(二)在流程包
我需要编写一个ruby脚本来连接到MSSQLServer数据库,但我发现的所有线程都指向gems以将ActiveRecord绑定(bind)到MSSQL。是否有任何gems可以让我像pg那样做这个(对于postgreshttps://github.com/ged/ruby-pg)?我只需要做一些非常简单的远程查询,非常感谢! 最佳答案 最好的方法是使用tiny_tdsgemhttps://github.com/rails-sqlserver/tiny_tds 关于ruby-微软SQL
原文题目:《ACompleteSurveyonGenerativeAI(AIGC):IsChatGPTfromGPT-4toGPT-5AllYouNeed?》文章链接:https://arxiv.org/abs/2303.11717https://arxiv.org/abs/2303.11717引言:随着ChatGPT的火热传播,生成式AI(AIGC,即AI生成的内容)因其分析和创造文本、图像等能力而在各地引起了轰动。在如此强烈的媒体关注下,我们几乎不可能错过从某个角度欣赏AIGC的机会。 “一个具有未来科幻感的机器人坐着,手握画笔正在创作一幅五颜六色的图画“由dalle2创作在AI从纯分析转
往期周报汇总地址:嵌入式周报-uCOS&uCGUI&emWin&embOS&TouchGFX&ThreadX-硬汉嵌入式论坛-PoweredbyDiscuz! 祝大家开工大吉视频版:https://www.bilibili.com/video/BV1GT411o7zr1、ThreadX老大离开微软,开发的第5代RTOS系统PX5RTOS正式上线最早是看到IAR的一条消息,全面支持PX5RTOS,然后就进一步上他们的官方下载白皮书了解相关消息当看到这两个名字时,很熟悉,这不就是ThreadX的老大BillLamie。 经过信息检索,应该是实锤了,领英上已经更新了他的工作经历: 然后再结合Azur
paddlenlp作为自然语言处理领域的全家桶,具有很多的不错的开箱即用的nlp能力。今天我们来一起看看基于paddlenlp中taskflow开箱即用的能力有哪些。第一步先升级aistudio中的paddlenlp保持最新版本。pipinstall-UpaddlenlpLookinginindexes:https://pypi.tuna.tsinghua.edu.cn/simpleRequirementalreadysatisfied:paddlenlpin/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages(2
《王牌射手》起因游戏地址游戏介绍游戏开发后续(如果有后续得话~)最后其他游戏起因之前作者借着CocosCreator得3D性能和官方活动,开发了一款点球大战得3D射门游戏。既然3D都来了,那么2D得射门游戏《王牌射手》也是如期而至了!(掌声鼓励)游戏地址体验地址:王牌射手体验源码地址:王牌射手源码游戏介绍以作者本身得能力,游戏得策划当然是需要抄袭,是借鉴呀,借鉴了微信小游戏**《天天足球》**得玩法。简单得介绍下玩法:就是足球会于场中得球员发生碰撞,如果球员碰到了我方球员,球员会90°以内左右旋转,玩家点击屏幕发射足球,在固定得发球数量内,达到进球门槛即判定为过关呀。那么有的朋友就会问了,你这
共享经济模式以合理配置网络资源、减少销售市场交易费用、推动私营经济强势来袭等优点颠覆性创新地严重影响传统商业模式,根据“自由者”的协同,共享经济模式给供需彼此更自由选择和由上而下的制度变革,提高了经济形势高效率,变成近些年更为比较热门的自主创业行业,因此各种各样共享模式集中化暴发,交通出行、货运物流、金融业、文化教育、室内空间、自媒体平台,渗入大家日常生活中的每一个环节,已是踵事增华。 如今网络平台愈来愈多,不过想要做他的私域流量池的公司也越来越多了。许多默默无闻知名品牌凭借自己的欲念总流量已不再被埋没了,那样创造自己的欲念总流量就一定要有自己的商城系统,可能你们会猜疑说:那么多网络平台,谁能
关注公众号,发现CV技术之美本文分享论文『VideoMAE:MaskedAutoencodersareData-EfficientLearnersforSelf-SupervisedVideoPre-Training』,由南大王利民团队提出第一个VideoMAE框架,使用超高maskingratio(90%-95%),性能SOTA,代码已开源!详细信息如下:论文链接:https://arxiv.org/abs/2203.12602项目链接:https://github.com/MCG-NJU/VideoMAE 01 摘要为了在相对较小的数据集上实现卓越的性能,通常需要在超大规模数据