在实际的工程项目中,数据批量操作的需求是比较强烈的,所以ES的API也提供了这样的应用场景。下面将演示如何进行批量的文档增加,文档删除操作。
在ES中批量的操需要使用到一个请求对象就是BulkRequest,然后将要做的请求集合添加到BulkRequest中,最后使用bulk方法发送批量请求。 批量添加文档的步骤如下
org.apache.http.HttpHost对象。RestClientBuilder,该对象由RestClient.builder(host);构建。ES服务器链接的客户端对象RestHighLevelClient, 直接创建即可。org.elasticsearch.action.bulk.BulkRequest对象,例如对象名叫bulkRequest。org.elasticsearch.action.index.IndexRequest对象,并加入到bulkRequest。client.bulk(bulkRequest, RequestOptions.DEFAULT);。package com.maomao.elastic.search.batch;
import org.apache.http.HttpHost;
import org.elasticsearch.action.bulk.BulkItemResponse;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import java.util.Arrays;
public class DocInsertBatch {
public static void main(String[] args) throws Exception {
HttpHost host = new HttpHost("127.0.0.1", 9200, "http");
RestClientBuilder builder = RestClient.builder(host);
RestHighLevelClient client = new RestHighLevelClient(builder);
// 批量操作其实就是把 一堆的request添加到bulkRequest中,所以首先要构建一个bulkRequest
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.add(new IndexRequest().index("teacher").id("7002").source(XContentType.JSON, "name", "宋江", "sex", "男", "age", "35", "title", "副教授"));
bulkRequest.add(new IndexRequest().index("teacher").id("7003").source(XContentType.JSON, "name", "花荣", "sex", "男", "age", "25", "title", "助教"));
bulkRequest.add(new IndexRequest().index("teacher").id("7004").source(XContentType.JSON, "name", "孙二娘", "sex", "女", "age", "28", "title", "副教授"));
// 调用方法为bulk
BulkResponse bulkResponse = client.bulk(bulkRequest, RequestOptions.DEFAULT);
Arrays.stream(bulkResponse.getItems()).map(BulkItemResponse::getResponse).forEach(System.out::println);
client.close();
}
}
执行查询操作。
执行完查询操作之后,继续使用PostMan进行restfulapi进行查询,看是否都被成功添加到ES服务器:
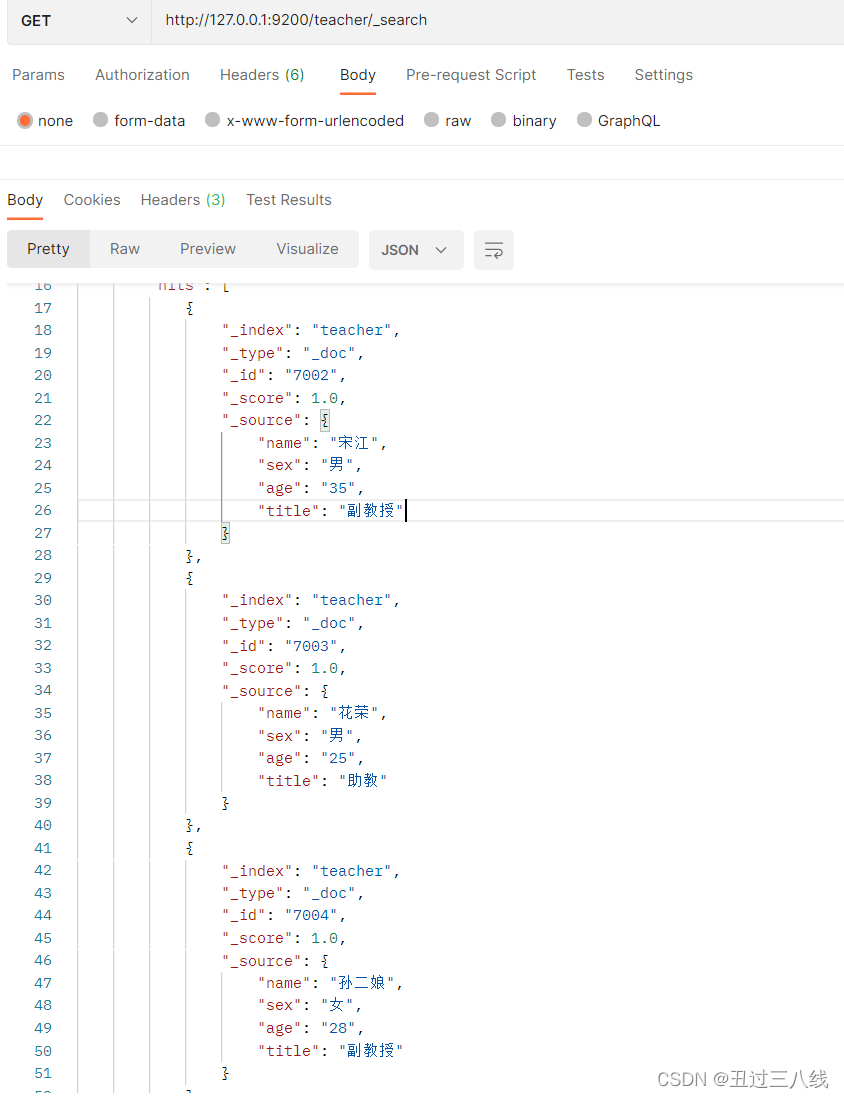
从上面可以看出,刚才批量添加的数据已经成功添加到服务器了。
操作基本与批量添加一致,只需要把刚才IndexRequest对象换成DeleteRequest就可以了。接下来实验,我们将使用批量删除的方式将刚添加的7002、7003、7004删除掉.
上代码:
package com.maomao.elastic.search.batch;
import org.apache.http.HttpHost;
import org.elasticsearch.action.bulk.BulkItemResponse;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import java.util.Arrays;
public class DocDeleteBatch {
public static void main(String[] args) throws Exception {
HttpHost host = new HttpHost("127.0.0.1", 9200, "http");
RestClientBuilder builder = RestClient.builder(host);
RestHighLevelClient client = new RestHighLevelClient(builder);
// 批量操作其实就是把 一堆的request添加到bulkRequest中,所以首先要构建一个bulkRequest
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.add(new DeleteRequest().index("teacher").id("7002"));
bulkRequest.add(new DeleteRequest().index("teacher").id("7003"));
bulkRequest.add(new DeleteRequest().index("teacher").id("7004"));
// 调用方法为bulk
BulkResponse bulkResponse = client.bulk(bulkRequest, RequestOptions.DEFAULT);
Arrays.stream(bulkResponse.getItems()).map(BulkItemResponse::getResponse).forEach(System.out::println);
client.close();
}
}
执行操作结果如下:

再继续使用PostMan继续查询一下是否服务器上已经被删除了
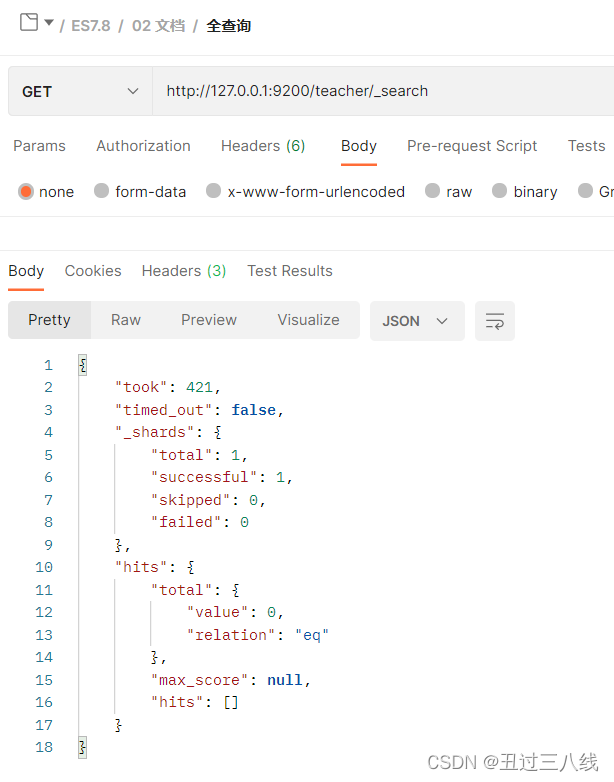
通过查询,我们发现hits字段已经为空了,也就是不在存在数据了,也就是说文档被彻底删除掉了。批量操作成功。
matlab打开matlab,用最简单的imread方法读取一个图像clcclearimg_h=imread('hua.jpg');返回一个数组(矩阵),往往是a*b*cunit8类型解释一下这个三维数组的意思,行数、数和层数,unit8:指数据类型,无符号八位整形,可理解为0~2^8的数三个层数分别代表RGB三个通道图像rgb最常用的是24-位实现方法,即RGB每个通道有256色阶(2^8)。基于这样的24-位RGB模型的色彩空间可以表现256×256×256≈1670万色当imshow传入了一个二维数组,它将以灰度方式绘制;可以把图像拆分为rgb三层,可以以灰度的方式观察它figure(1
1.postman介绍Postman一款非常流行的API调试工具。其实,开发人员用的更多。因为测试人员做接口测试会有更多选择,例如Jmeter、soapUI等。不过,对于开发过程中去调试接口,Postman确实足够的简单方便,而且功能强大。2.下载安装官网地址:https://www.postman.com/下载完成后双击安装吧,安装过程极其简单,无需任何操作3.使用教程这里以百度为例,工具使用简单,填写URL地址即可发送请求,在下方查看响应结果和响应状态码常用方法都有支持请求方法:getpostputdeleteGet、Post、Put与Delete的作用get:请求方法一般是用于数据查询,
在VMware16.2.4安装Ubuntu一、安装VMware1.打开VMwareWorkstationPro官网,点击即可进入。2.进入后向下滑动找到Workstation16ProforWindows,点击立即下载。3.下载完成,文件大小615MB,如下图:4.鼠标右击,以管理员身份运行。5.点击下一步6.勾选条款,点击下一步7.先勾选,再点击下一步8.去掉勾选,点击下一步9.点击下一步10.点击安装11.点击许可证12.在百度上搜索VM16许可证,复制填入,然后点击输入即可,亲测有效。13.点击完成14.重启系统,点击是15.双击VMwareWorkstationPro图标,进入虚拟机主
1.1.1 YARN的介绍 为克服Hadoop1.0中HDFS和MapReduce存在的各种问题⽽提出的,针对Hadoop1.0中的MapReduce在扩展性和多框架⽀持⽅⾯的不⾜,提出了全新的资源管理框架YARN. ApacheYARN(YetanotherResourceNegotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于⼀个分布式的操作系统平台,⽽MapReduce等计算程序则相当于运⾏于操作系统之上的应⽤程序。 YARN被引⼊Hadoop2,最初是为了改善MapReduce的实现,但是因为具有⾜够的通⽤性,同样可以⽀持其他的分布式计算模
我有一个使用SeleniumWebdriver和Nokogiri的Ruby应用程序。我想选择一个类,然后对于那个类对应的每个div,我想根据div的内容执行一个Action。例如,我正在解析以下页面:https://www.google.com/webhp?sourceid=chrome-instant&ion=1&espv=2&ie=UTF-8#q=puppies这是一个搜索结果页面,我正在寻找描述中包含“Adoption”一词的第一个结果。因此机器人应该寻找带有className:"result"的div,对于每个检查它的.descriptiondiv是否包含单词“adoption
我正在我的Rails项目中安装Grape以构建RESTfulAPI。现在一些端点的操作需要身份验证,而另一些则不需要身份验证。例如,我有users端点,看起来像这样:moduleBackendmoduleV1classUsers现在如您所见,除了password/forget之外的所有操作都需要用户登录/验证。创建一个新的端点也没有意义,比如passwords并且只是删除password/forget从逻辑上讲,这个端点应该与用户资源。问题是Grapebefore过滤器没有像except,only这样的选项,我可以在其中说对某些操作应用过滤器。您通常如何干净利落地处理这种情况?
在我做的一些网络开发中,我有多个操作开始,比如对外部API的GET请求,我希望它们同时开始,因为一个不依赖另一个的结果。我希望事情能够在后台运行。我找到了concurrent-rubylibrary这似乎运作良好。通过将其混合到您创建的类中,该类的方法具有在后台线程上运行的异步版本。这导致我编写如下代码,其中FirstAsyncWorker和SecondAsyncWorker是我编写的类,我在其中混合了Concurrent::Async模块,并编写了一个名为“work”的方法来发送HTTP请求:defindexop1_result=FirstAsyncWorker.new.async.
a=[3,4,7,8,3]b=[5,3,6,8,3]假设数组长度相同,是否有办法使用each或其他一些惯用方法从两个数组的每个元素中获取结果?不使用计数器?例如获取每个元素的乘积:[15,12,42,64,9](0..a.count-1).eachdo|i|太丑了...ruby1.9.3 最佳答案 使用Array.zip怎么样?:>>a=[3,4,7,8,3]=>[3,4,7,8,3]>>b=[5,3,6,8,3]=>[5,3,6,8,3]>>c=[]=>[]>>a.zip(b)do|i,j|c[[3,5],[4,3],[7,6],
我有一个非常简单的Controller来管理我的Rails应用程序中的静态页面:classPagesController我怎样才能让View模板返回它自己的名字,这样我就可以做这样的事情:#pricing.html.erb#-->"Pricing"感谢您的帮助。 最佳答案 4.3RoutingParametersTheparamshashwillalwayscontainthe:controllerand:actionkeys,butyoushouldusethemethodscontroller_nameandaction_nam
Ruby有一些不错的文档生成器,例如Yard、rDoc,甚至Glyph。问题是Sphinx可以做网站、PDF、epub、LaTex等。它在重组文本中完成所有这些事情。在Ruby世界中有替代方案吗?也许是程序的组合?如果我也能使用Markdown就更好了。 最佳答案 自1.0版以来,Sphinx有了“域”的概念,它是从Python和/或C以外的语言标记代码实体(如方法调用、对象、函数等)的方法。有一个rubydomain,所以你可以只使用Sphinx本身。您唯一会缺少的(我认为)是Sphinx使用autodoc从源代码自动创建文档