文章目录
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
给定表M,存在函数f(key),对任意给定的关键字值key,代入函数后若能得到包含该关键字的记录在表中的地址,则称表M为哈希(Hash)表,函数f(key)为哈希(Hash) 函数
总的来说:
- 哈希表是一种数据结构
- 哈希表表示了关键码值和记录的映射关
- 哈希表可以加快查找速度
- 任意哈希表,都满足有哈希函数f(key),代入任意key值都可以获取包含该key值的记录在表中的地址
哈希表有多种使用方式,通常我们选择何种方式需要通过以下几点进行分析:
· 计算哈希函数所需时间
· 关键字的长度
· 哈希表的大小
· 关键字的分布情况
· 记录的查找频率
取关键字或关键字的某个线性函数值为散列地址。即H(key)=key或H(key) = a·key + b,其中a和b为常数(这种散列函数叫做自身函数)。若其中H(key)中已经有值了,就往下一个找,直到H(key)中没有值了,就放进去。
分析一组数据,比如一组员工的出生年月日,这时我们发现出生年月日的前几位数字大体相同,这样的话,出现冲突的几率就会很大,但是我们发现年月日的后几位表示月份和具体日期的数字差别很大,如果用后面的数字来构成散列地址,则冲突的几率会明显降低。因此数字分析法就是找出数字的规律,尽可能利用这些数据来构造冲突几率较低的散列地址。
当无法确定关键字中哪几位分布较均匀时,可以先求出关键字的平方值,然后按需要取平方值的中间几位作为哈希地址。这是因为:平方后中间几位和关键字中每一位都相关,故不同关键字会以较高的概率产生不同的哈希地址
将关键字分割成位数相同的几部分,最后一部分位数可以不同,然后取这几部分的叠加和(去除进位)作为散列地址。数位叠加可以有移位叠加和间界叠加两种方法。移位叠加是将分割后的每一部分的最低位对齐,然后相加;间界叠加是从一端向另一端沿分割界来回折叠,然后对齐相加。
选择一随机函数,取关键字的随机值作为散列地址,即H(key)=random(key)其中random为随机函数,通常用于关键字长度不等的场合。
取关键字被某个不大于散列表表长m的数p除后所得的余数为散列地址。即 H(key) = key MOD p,p≤m。不仅可以对关键字直接取模,也可在折叠、平方取中等运算之后取模。对p的选择很重要,一般取素数或m,若p选的不好,容易产生同义词。
对不同的关键字可能得到同一散列地址,即k1≠k2,而f(k1)=(k2),这种现象称为冲突(英语:Collision)——我们也称之为哈希碰撞
我们有两种方式来解决这个问题:拉链法和线性探测法
将发生碰撞的元素都存进哈希表中,我们通过索引去查找它们的位置,这种方法即拉链法。

其实拉链法就是要选择适当的哈希表的大小,这样既不会因为数组空值而浪费大量内存,也不会因为链表太长而在查找上浪费太多时间。
使用线性探测法,一定要保证tableSize大于dataSize。 我们需要依靠哈希表中的空位来解决碰撞问题。
例如冲突的位置有两种元素(a与b),在哈希表中存放a,那么就向下找一个空位放置b。所以要求哈希表可存放的个数一定要大于数据元素个数 ,要不然哈希表上就没有空置的位置来存放冲突的数据了。

在我们使用哈希表进行解决问题时通常有三种结构可供我们选择:
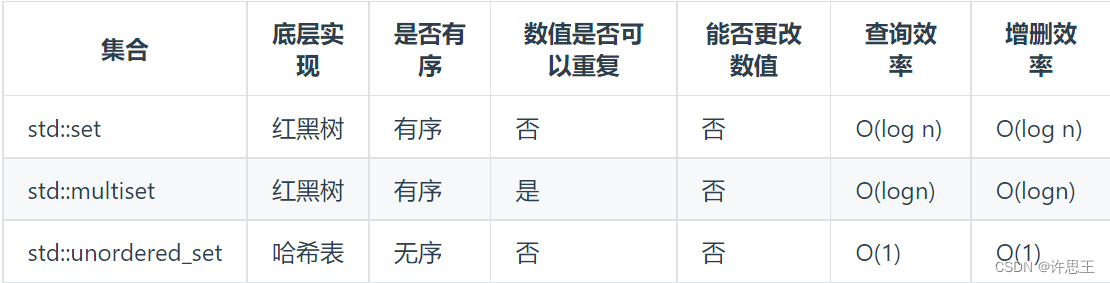
std::unordered_set底层实现为哈希表,std::set 和std::multiset 的底层实现是红黑树,红黑树是一种平衡二叉搜索树,所以key值是有序的,但key不可以修改,改动key值会导致整棵树的错乱,所以只能删除和增加。
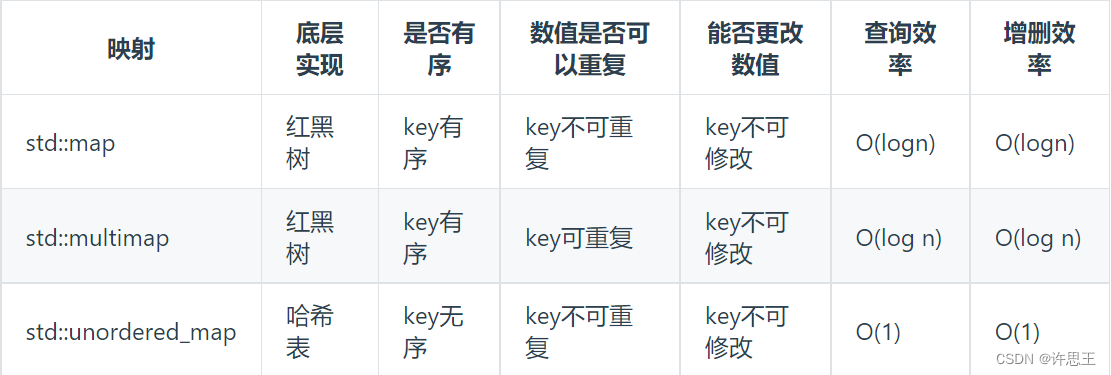
std::unordered_map 底层实现为哈希表,std::map 和std::multimap 的底层实现是红黑树。同理,std::map 和std::multimap 的key也是有序的
大多数情况下,使用哈希表和哈希集合的场景都会使用 HashMap 类和 HashSet 类的对象。如果哈希表的键范围有限或者哈希集合的元素范围有限,例如只能是数字或者只能是字母,则可以用数组代替哈希表。虽然从复杂度分析的角度而言,数组和哈希表的时间复杂度和空间复杂度相同,但是在实际运行时,数组的操作时间和占用空间都优于哈希表。

(图片与部分内容来源于网络,侵权请联系删除)
我有一个这样的哈希数组:[{:foo=>2,:date=>Sat,01Sep2014},{:foo2=>2,:date=>Sat,02Sep2014},{:foo3=>3,:date=>Sat,01Sep2014},{:foo4=>4,:date=>Sat,03Sep2014},{:foo5=>5,:date=>Sat,02Sep2014}]如果:date相同,我想合并哈希值。我对上面数组的期望是:[{:foo=>2,:foo3=>3,:date=>Sat,01Sep2014},{:foo2=>2,:foo5=>5:date=>Sat,02Sep2014},{:foo4=>4,:dat
我使用Ember作为我的前端和GrapeAPI来为我的API提供服务。前端发送类似:{"service"=>{"name"=>"Name","duration"=>"30","user"=>nil,"organization"=>"org","category"=>nil,"description"=>"description","disabled"=>true,"color"=>nil,"availabilities"=>[{"day"=>"Saturday","enabled"=>false,"timeSlots"=>[{"startAt"=>"09:00AM","endAt"=>
查看我的Ruby代码:h=Hash.new([])h[0]=:word1h[1]=h[1]输出是:Hash={0=>:word1,1=>[:word2,:word3],2=>[:word2,:word3]}我希望有Hash={0=>:word1,1=>[:word2],2=>[:word3]}为什么要附加第二个哈希元素(数组)?如何将新数组元素附加到第三个哈希元素? 最佳答案 如果您提供单个值作为Hash.new的参数(例如Hash.new([]),完全相同的对象将用作每个缺失键的默认值。这就是您所拥有的,那是你不想要的。您可以改用
假设我有一个在Ruby中看起来像这样的哈希:{:ie0=>"Hi",:ex0=>"Hey",:eg0=>"Howdy",:ie1=>"Hello",:ex1=>"Greetings",:eg1=>"Goodday"}有什么好的方法可以将它变成如下内容:{"0"=>{"ie"=>"Hi","ex"=>"Hey","eg"=>"Howdy"},"1"=>{"ie"=>"Hello","ex"=>"Greetings","eg"=>"Goodday"}} 最佳答案 您要求一个好的方法来做到这一点,所以答案是:一种您或同事可以在六个月后理解
我在搜索我的值是方法的散列时遇到问题。我只是不想运行plan_type与键匹配的方法。defmethod(plan_type,plan,user){foo:plan_is_foo(plan,user),bar:plan_is_bar(plan,user),waa:plan_is_waa(plan,user),har:plan_is_har(user)}[plan_type]end目前如果我传入“bar”作为plan_type,所有方法都会运行,我怎么能只运行plan_is_bar方法呢? 最佳答案 这个变体怎么样?defmethod
你好,我无法成功如何在散列中删除key后释放内存。当我从哈希中删除键时,内存不会释放,也不会在手动调用GC.start后释放。当从Hash中删除键并且这些对象在某处泄漏时,这是预期的行为还是GC不释放内存?如何在Ruby中删除Hash中的键并在内存中取消分配它?例子:irb(main):001:0>`ps-orss=-p#{Process.pid}`.to_i=>4748irb(main):002:0>a={}=>{}irb(main):003:0>1000000.times{|i|a[i]="test#{i}"}=>1000000irb(main):004:0>`ps-orss=-p
有什么区别:@attr[:field]=new_value和@attr.merge(:field=>new_value) 最佳答案 如果您使用的是merge!而不是merge,则没有区别。唯一的区别是您可以在合并参数中使用多个字段(意思是:另一个散列)。例子:h1={"a"=>100,"b"=>200}h2={"b"=>254,"c"=>300}h3=h1.merge(h2)putsh1#=>{"a"=>100,"b"=>200}putsh3#=>{"a"=>100,"b"=>254,"c"=>300}h1.merge!(h2)pu
因此,对于普通哈希,您可以使用它来获取key:hash.keys如何获取如下所示的多维哈希的第二维键:{""=>{"first_name"=>"test","last_name"=>"test_l","username"=>"test_user","title"=>"SalesManager","office"=>"test","email"=>"test@test.com"}}每个项目都是唯一的。所以我想从上面得到的键是:first_name,last_name,username,title,officeandemail 最佳答案
我正在尝试循环哈希数组。当我到达获取枚举器开始循环的位置时,出现以下错误:undefinedmethod`[]'fornil:NilClass我的代码如下所示:defextraireAttributs(attributsParam)classeTrouvee=falsescanTrouve=falseownerOSTrouve=falseownerAppTrouve=falseresultat=Hash.new(0)attributs=Array(attributsParam)attributs.eachdo|attribut|#CRASHESHERE!!!typeAttribut=a
这个问题在这里已经有了答案:HashsyntaxinRuby[duplicate](1个回答)关闭5年前。我有一个Recipe,其中包含以下未通过lint测试的代码:service'apache'dosupports:status=>true,:restart=>true,:reload=>trueend失败并出现错误:UsethenewRuby1.9hashsyntax.supports:status=>true,:restart=>true,:reload=>true不确定新语法是什么样的...有人可以帮忙吗?