报错信息如下:
[2023-01-04 13:36:02.185]-ERROR-[biz:aplus-task-oms1060189862335877121][sys:aplus-cms-tran1060189866052390912][com.phfund.aplus.cms.tran.module.counter.service.impl.OcrServiceImpl-102][调用远程服务发送文件异常:]
cn.hutool.http.HttpException: Error writing to server
at cn.hutool.http.HttpResponse.init(HttpResponse.java:423)
at cn.hutool.http.HttpResponse.initWithDisconnect(HttpResponse.java:396)
at cn.hutool.http.HttpResponse.+init+(HttpResponse.java:76)
at cn.hutool.http.HttpRequest.execute(HttpRequest.java:966)
at cn.hutool.http.HttpRequest.execute(HttpRequest.java:930)
at com.phfund.aplus.cms.tran.module.counter.service.impl.OcrServiceImpl.sendDataToOcr(OcrServiceImpl.java:82)
排查出该报错为外调其他系统时发生,当传入参数数据过大(10M左右)就会必现
开始以为是hutool工具类发送请求参数过大的问题,换成apache自带的HTTP工具类,结果依然出现报错
报错如下:
Connection reset by peer: socket write error
at java.net.SocketOutputStream.socketWrite0(Native Method) ~[na:1.6.0_43]
at java.net.SocketOutputStream.socketWrite(SocketOutputStream.java:92) ~[na:1.6.0_43]
at java.net.SocketOutputStream.write(SocketOutputStream.java:136) ~[na:1.6.0_43]
初步猜测是请求方将数据上传给服务端时写入有误
1、是不是请求方HTTP链接时间过短,导致数据还没有传递完就断开了。所以设置了HTTP超时时间为30s,测试仍旧会报错。
2、或许请求方还有别的设置有问题,现在换了一个本地的服务发送同样的数据,发现成功了,所以现在开始怀疑的服务方的问题
3、用POSTMAN发送请求到服务方,报错一致,更加坚定是服务方的问题
果然在服务方有报错:
01-04 16:26:54.443 ERROR [c.d.a.framework.boot.error.RestExceptionTranslator] - 消息不能读取
01-04 16:26:54.451 ERROR [c.d.a.framework.boot.error.RestExceptionTranslator] - 消息不能读取
01-04 16:26:54.460 ERROR [c.d.a.framework.boot.error.RestExceptionTranslator] - 消息不能读取
01-04 16:26:54.471 ERROR [c.d.a.framework.boot.error.RestExceptionTranslator] - 消息不能读取
接收请求的buffer设置得有点小,然后关闭了TCP连接,请求方没拿到HTTP报错返回,再继续写TCP连接得时候,遇到了关闭TCP得错误,所以打了这个日志
查询资料,发现springboot在接收文件和request请求时,会设置默认的大小,参数如下:
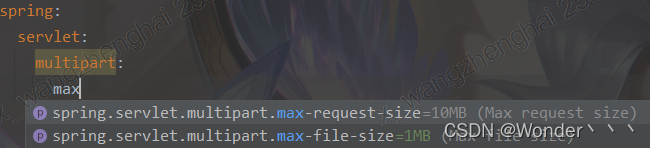
将maxRequestSize调大,测试,可行
是的,我知道最好使用webmock,但我想知道如何在RSpec中模拟此方法:defmethod_to_testurl=URI.parseurireq=Net::HTTP::Post.newurl.pathres=Net::HTTP.start(url.host,url.port)do|http|http.requestreq,foo:1endresend这是RSpec:let(:uri){'http://example.com'}specify'HTTPcall'dohttp=mock:httpNet::HTTP.stub!(:start).and_yieldhttphttp.shou
在我的Controller中,我通过以下方式在我的index方法中支持HTML和JSON:respond_todo|format|format.htmlformat.json{renderjson:@user}end在浏览器中拉起它时,它会自然地以HTML呈现。但是,当我对/user资源进行内容类型为application/json的curl调用时(因为它是索引方法),我仍然将HTML作为响应。如何获取JSON作为响应?我还需要说明什么? 最佳答案 您应该将.json附加到请求的url,提供的格式在routes.rb的路径中定义。这
我正在学习Rails,并阅读了关于乐观锁的内容。我已将类型为integer的lock_version列添加到我的articles表中。但现在每当我第一次尝试更新记录时,我都会收到StaleObjectError异常。这是我的迁移:classAddLockVersionToArticle当我尝试通过Rails控制台更新文章时:article=Article.first=>#我这样做:article.title="newtitle"article.save我明白了:(0.3ms)begintransaction(0.3ms)UPDATE"articles"SET"title"='dwdwd
在Cooper的书BeginningRuby中,第166页有一个我无法重现的示例。classSongincludeComparableattr_accessor:lengthdef(other)@lengthother.lengthenddefinitialize(song_name,length)@song_name=song_name@length=lengthendenda=Song.new('Rockaroundtheclock',143)b=Song.new('BohemianRhapsody',544)c=Song.new('MinuteWaltz',60)a.betwee
这里有一个很好的答案解释了如何在Ruby中下载文件而不将其加载到内存中:https://stackoverflow.com/a/29743394/4852737require'open-uri'download=open('http://example.com/image.png')IO.copy_stream(download,'~/image.png')我如何验证下载文件的IO.copy_stream调用是否真的成功——这意味着下载的文件与我打算下载的文件完全相同,而不是下载一半的损坏文件?documentation说IO.copy_stream返回它复制的字节数,但是当我还没有下
我正在尝试解析一个文本文件,该文件每行包含可变数量的单词和数字,如下所示:foo4.500bar3.001.33foobar如何读取由空格而不是换行符分隔的文件?有什么方法可以设置File("file.txt").foreach方法以使用空格而不是换行符作为分隔符? 最佳答案 接受的答案将slurp文件,这可能是大文本文件的问题。更好的解决方案是IO.foreach.它是惯用的,将按字符流式传输文件:File.foreach(filename,""){|string|putsstring}包含“thisisanexample”结果的
我早就知道Ruby中的“常量”(即大写的变量名)不是真正常量。与其他编程语言一样,对对象的引用是唯一存储在变量/常量中的东西。(侧边栏:Ruby确实具有“卡住”引用对象不被修改的功能,据我所知,许多其他语言都没有提供这种功能。)所以这是我的问题:当您将一个值重新分配给常量时,您会收到如下警告:>>FOO='bar'=>"bar">>FOO='baz'(irb):2:warning:alreadyinitializedconstantFOO=>"baz"有没有办法强制Ruby抛出异常而不是打印警告?很难弄清楚为什么有时会发生重新分配。 最佳答案
rails中是否有任何规定允许站点的所有AJAXPOST请求在没有authenticity_token的情况下通过?我有一个调用Controller方法的JqueryPOSTajax调用,但我没有在其中放置任何真实性代码,但调用成功。我的ApplicationController确实有'request_forgery_protection'并且我已经改变了config.action_controller.consider_all_requests_local在我的environments/development.rb中为false我还搜索了我的代码以确保我没有重载ajaxSend来发送
我目前正在使用以下方法获取页面的源代码:Net::HTTP.get(URI.parse(page.url))我还想获取HTTP状态,而无需发出第二个请求。有没有办法用另一种方法做到这一点?我一直在查看文档,但似乎找不到我要找的东西。 最佳答案 在我看来,除非您需要一些真正的低级访问或控制,否则最好使用Ruby的内置Open::URI模块:require'open-uri'io=open('http://www.example.org/')#=>#body=io.read[0,50]#=>"["200","OK"]io.base_ur
1.错误信息:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:requestcanceledwhilewaitingforconnection(Client.Timeoutexceededwhileawaitingheaders)或者:Errorresponsefromdaemon:Gethttps://registry-1.docker.io/v2/:net/http:TLShandshaketimeout2.报错原因:docker使用的镜像网址默认为国外,下载容易超时,需要修改成国内镜像地址(首先阿里