密集连接网络和卷积神经网络都有主要的特点,那就是它们没有记忆。它们单独处理每个输入,在输入和输入之间没有保存任何状态。举个例子:当你在阅读一个句子的时候,你需要记住之前的内容,我们才能动态的了解这个句子想表达的含义。生物智能已渐进的方式处理信息,同时保存一个关于所处理内容的内部模型,此模型是根据过去额信息构建的,并随着新的信息进入不断更新。比如股票预测、气温预测等等。

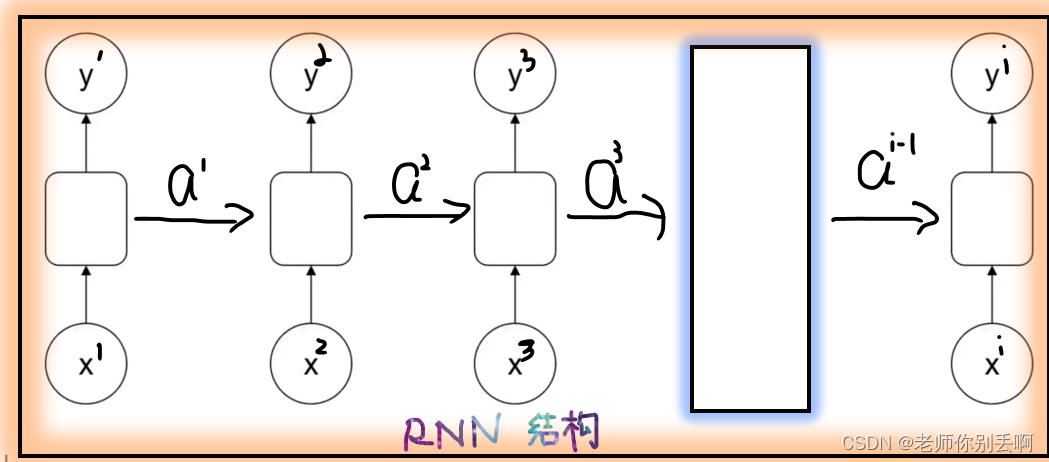
RNN特点:前部序列的信息经处理后,作为输入信息传递后部序列。
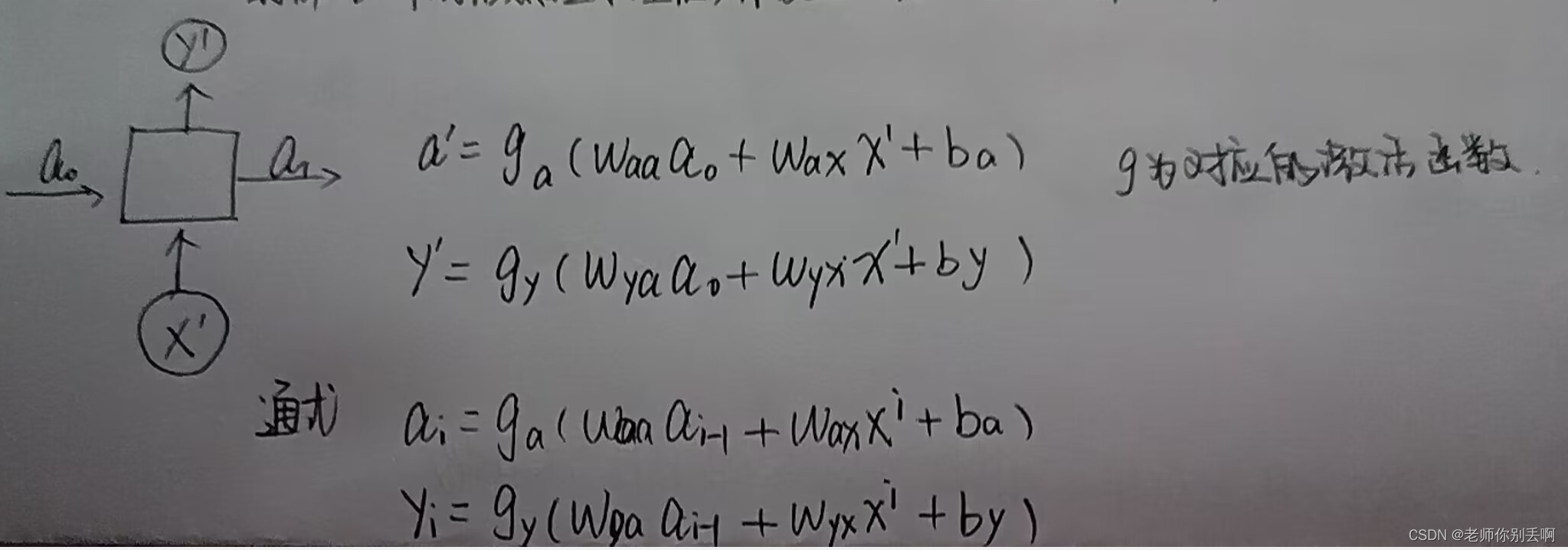
手写一下啦,本博主有点懒,懂了就阔以啦! 肯定权重是一样的。
(1)多输入多输出,维度相同RNN结构
应用:特定信息识别
结构如图:
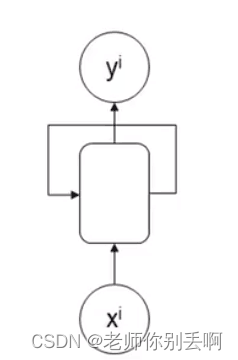
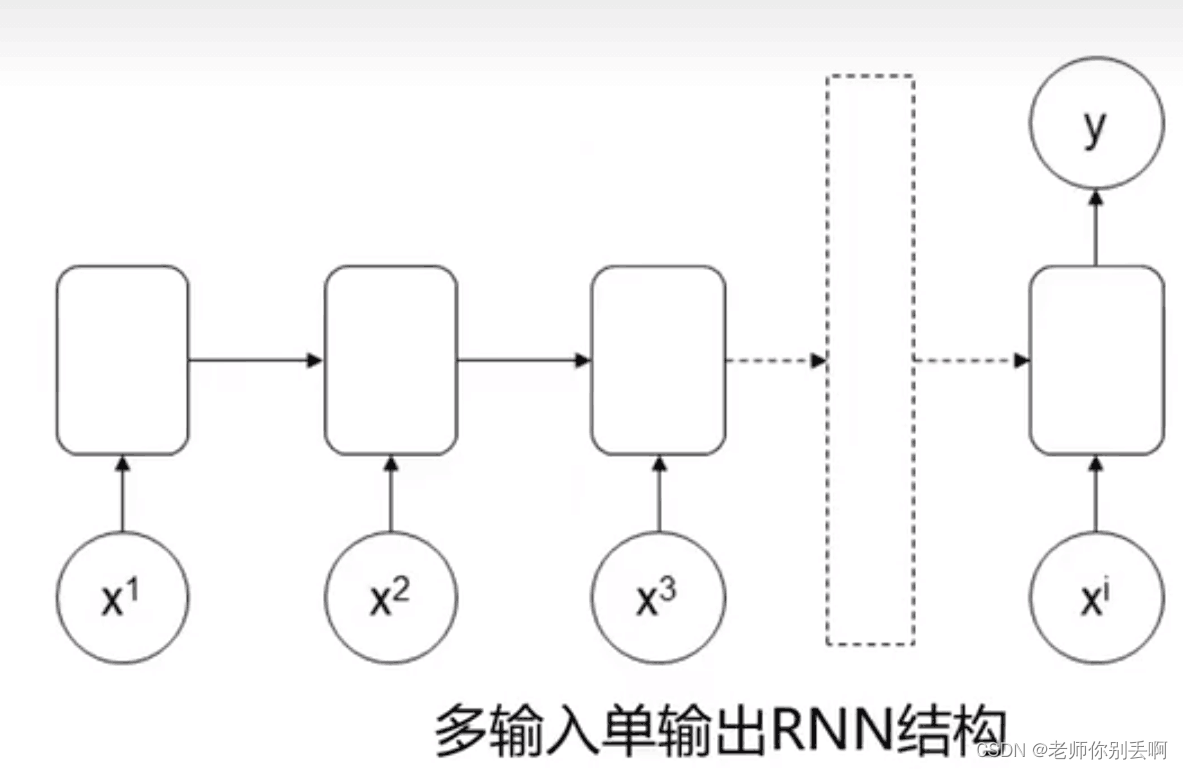
(2)多输入单输出
应用:情感识别
举例:I feel very happy.
判断:positive
结构如图:
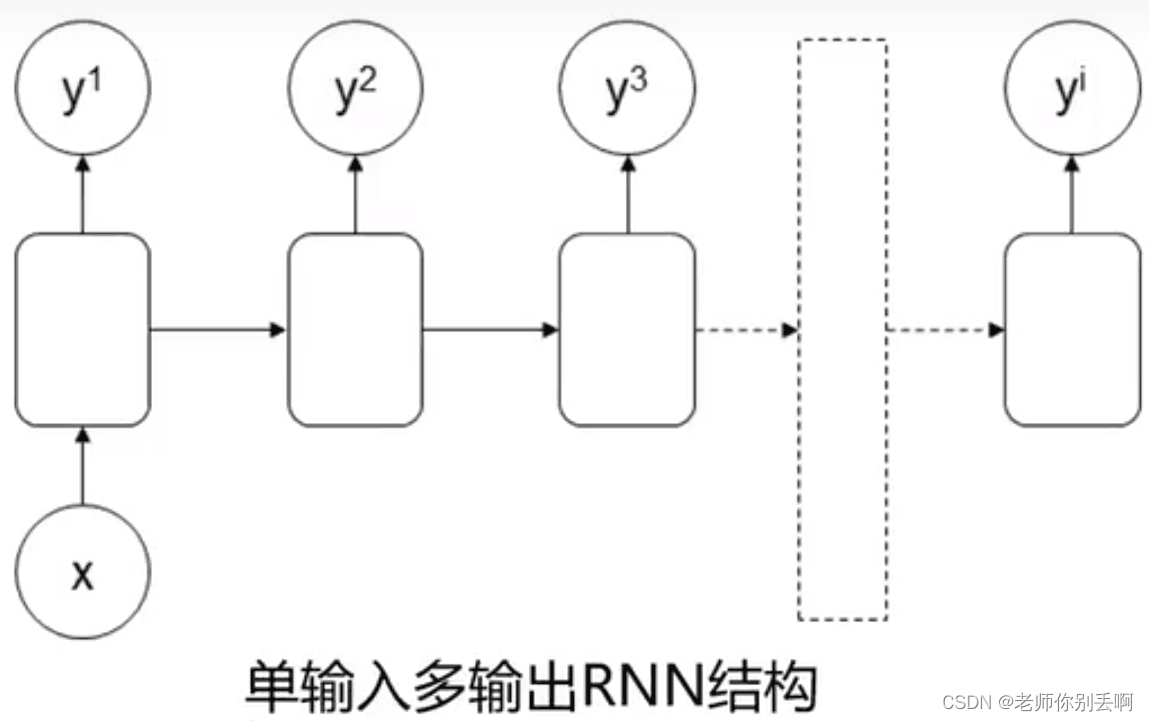
(3)单输入多输出
应用:序列数据生成
举例:文章生成(输入标题直接出文章)
结构如图:
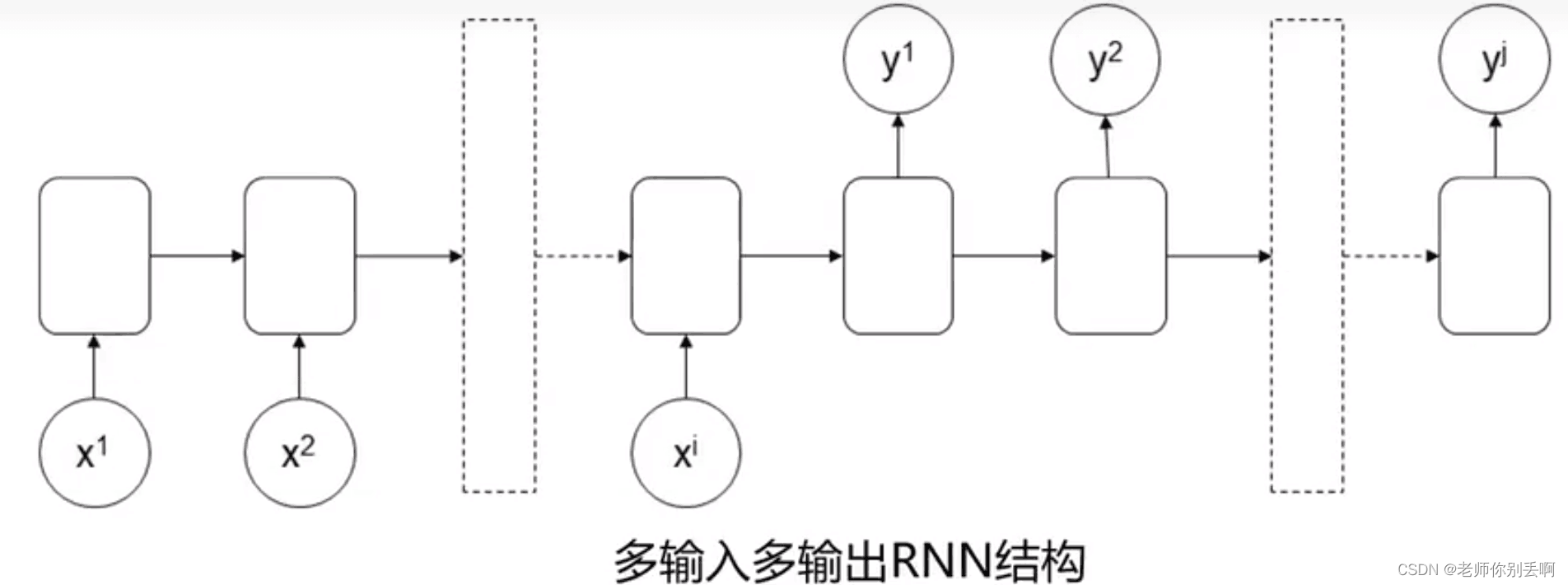
(4)多输入多输出(ij)
应用:语言翻译
举例:what is artificial intelligence?
什么是人工智能?
结构如图:
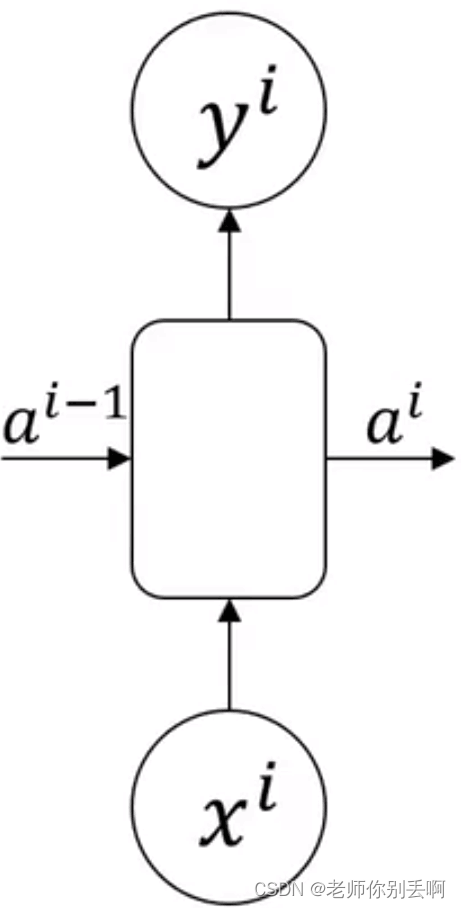
介绍了常见的RNN结构。但是这些结构在当前部序列信息在传递到后部的同时,信息权重下降,导致重要信息丢失。也称为(梯度消失)。由于这个问题接下来提出了长短期记忆网络(LSTM)。

通过传递前部序列信息,距离越远信息丢失越多(从彩色图可以很好的体现)。
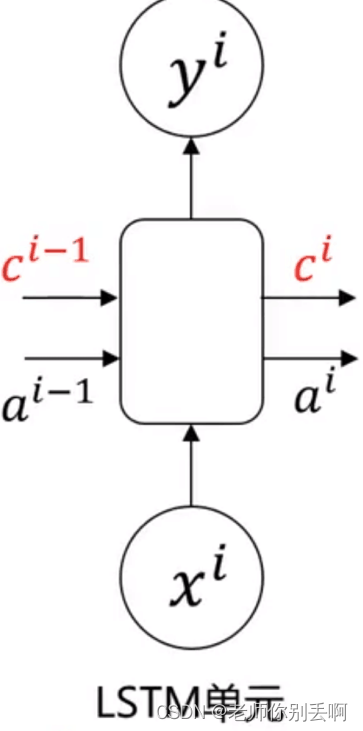 增加记忆细胞
增加记忆细胞 ,可以传递前部远处部位信息,且在传递过程中信息丢失少。
,可以传递前部远处部位信息,且在传递过程中信息丢失少。
内部结构: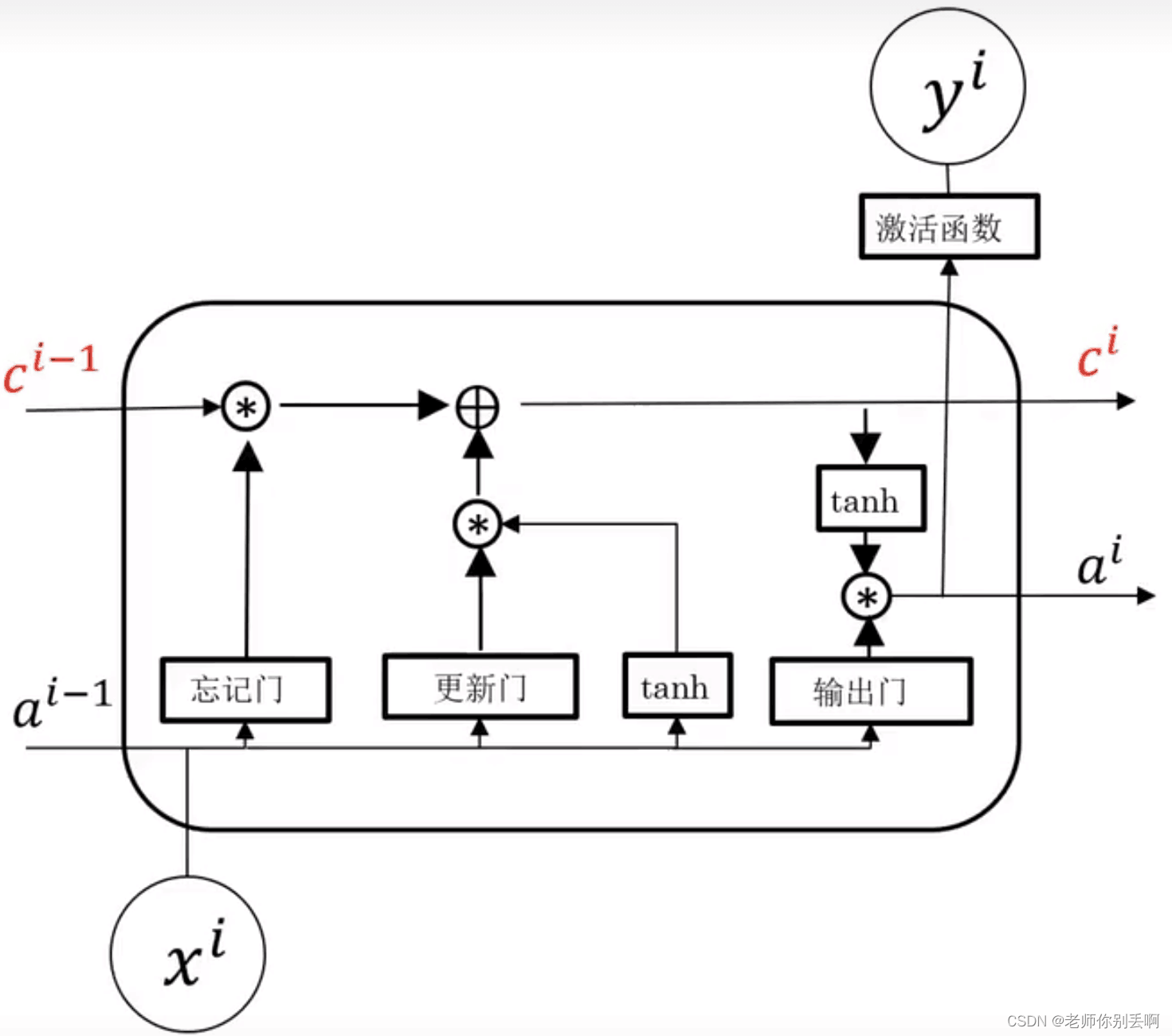
忘记门:选择性丢弃
与 中不重要的信息。
中不重要的信息。
更新门:确定给记忆细胞添加哪些信息。
输出门:筛选需要输出的信息。
结构如图:

在网络结构很深(很多层)的情况下,也能保留保留重要的信息;
解决了普通RNN求解过程中的梯度消失问题。
数据集介绍:
除了语言处理,其他许多问题中也都用到了序列数据。温度预测数据集,每十分钟记录14分不同的量(比如气温、气压、湿度、风向等)我们将利用2009-2016年的数据集构建模型,输入最近数据,预测24小时之后的气温。¶
(1)dataframe格式:
注意:
Initializing from file failed
由于文件中存在中文所以加后面engine='python'
data1=pd.read_csv('/data/jena_climate_2009_2016.csv',engine='python')后续简单操作代码如下:转化成数组
data=data1.copy()
df=data.values
data=df[:,1:]
data
data = np.array(data, dtype=np.float64)#方便后面数据标准化(2)str格式:
import os
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
data_dir='/data'
fname=os.path.join(data_dir,'jena_climate_2009_2016.csv')
f=open(fname)
data=f.read()
f.close()
lines=data.split('\n')
header=lines[0].split(',')
header后续简单操作代码如下:转化成数组
float_data=np.zeros((len(lines),len(header)-1))
for i,line in enumerate(lines):
values=[float(x) for x in line.split(',')[1:]]
float_data[i,:]=values结果如图:

补充 :enumerate()函数
英语翻译:就是枚举
names = ["Alice","Bob","Carl"]
for index,value in enumerate(names):
print(f'{index}: {value}')
看结果就懂了:
0: Alice 1: Bob 2: Carl
from matplotlib import pyplot as plt
temp=data[:,1]
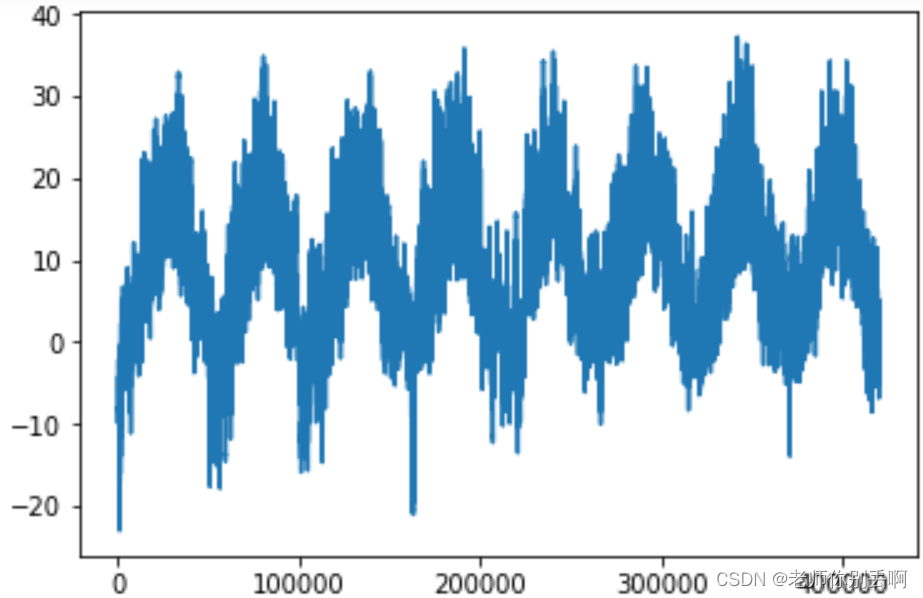
plt.plot(range(len(temp)),temp)#可以看出每年温度的周期性变化
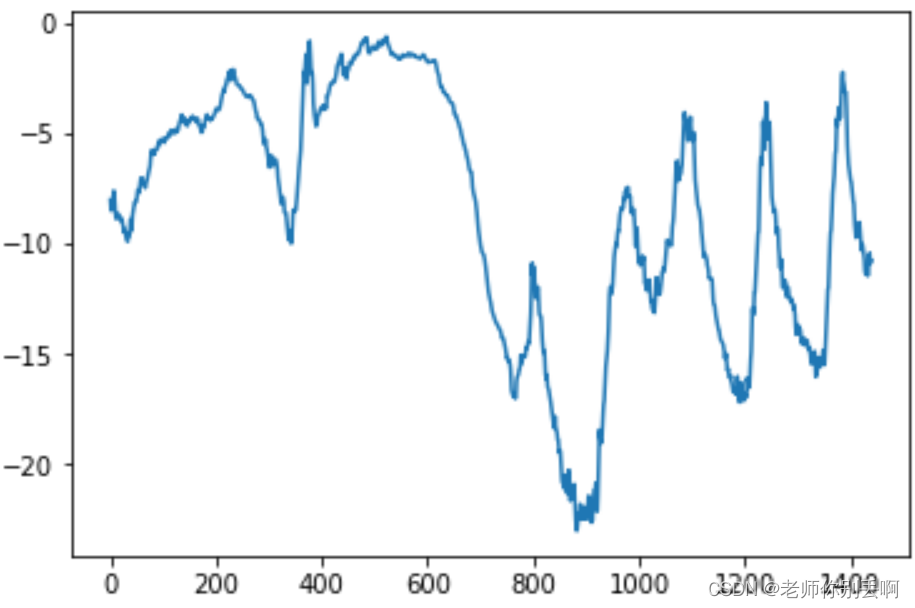
#看完整体看局部前十天的温度变化
#首先呢每十分钟记录一个数据点,一天则可以记录144个数据点,则十天记录1440个数据点
plt.plot(range(1440),temp[:1440])#后面是冬季结果如图:
(1) 首先数据预处理(将数据处理为神经网络可以处理的格式,由于已经是数值型的,所以不需要向量化)。
但是由于数据每个时间序列位于不同的范围所以我们需要对每个时间序列进行标准化,让他们在相似范围内都取较小的值。
我们采取200 000个时间作为训练数据。
mean=data[:200000].mean(axis=0)
print(mean)
std=data[:200000].std(axis=0)
print(std)
data_-=mean
data_/=std举个例子:比如700个数据,我用8个数据去预测第九个数据:
[1 , 2 , . . . ,8] ----9 ——
[2 , 3 , . . . ,9] ----10 ——
[3 , 4 , . . . ,10]
.
.
.
and so on。 ——
n 代表samples
time_steps=8
features:样本特征维数(自然语言处理十分重要 one-hot格式比如001对应三),这里数据是单维度则为1.
def extract_data(data,time_step):
X=[]
y=[]
#0,1,2,3...,9:10个样本;time_step=8;0,1...7;2,3...8两个样本
for i in range(len(data)-time_step):
X.append([a for a in data[i:i+time_step]])
y.append(data[i+time_step])
X=np.array(X)
#X=X.reshape(X.shape[0],X.shape[1],1)
return X,y%matplotlib inline
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
data_=pd.read_csv('/data/zgpa.csv',engine='python')
data_.head()close=np.array(close,dtype=np.float64)
mean=close.mean(axis=0)
print(mean)
std=close.std(axis=0)
print(std)
close-=mean
close/=std#首先我们看一下收盘价格时间序列的趋势
close=data_['close']
close
plt.plot(range(len(close)),close)
plt.title('close price')结果如图:
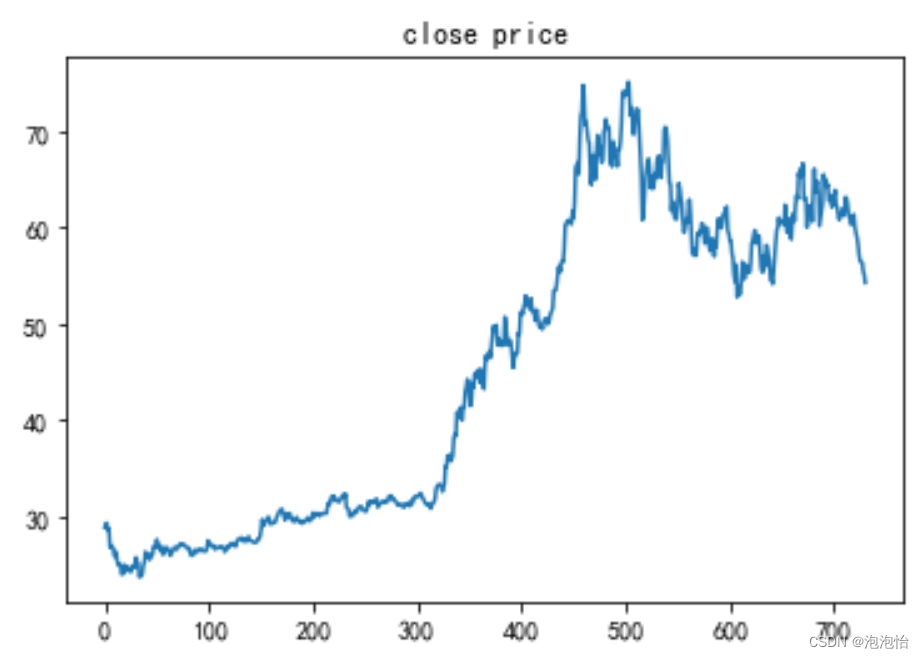
调用:
X,y=extract_data(close,time_step)
print(X[0,:,:])
print(y)from keras.models import Sequential
from keras.layers import Dense,SimpleRNN
model=Sequential()
#add rnn layer
model.add(SimpleRNN(units=8,input_shape=(time_step,1),activation='relu'))
#add output layer
model.add(Dense(units=1,activation='linear'))
#configure the model
model.compile(optimizer='adam',loss='mean_squared_error')
model.summary()结果如图:

y=np.array(y)
model.fit(X,y,batch_size=30,epochs=200)结果如图:

y_train_predict=(model.predict(X)*std)+mean
y_train=(y*std)+mean
fig1=plt.figure(figsize=(8,5))
plt.plot(y_train,label='real price')
plt.plot(y_train_predict,label='predict price')
plt.title('close price')
plt.xlabel('time')
plt.ylabel('price')
plt.legend()
plt.show()结果如图:

我脑子里浮现出一些关于一种新编程语言的想法,所以我想我会尝试实现它。一位friend建议我尝试使用Treetop(Rubygem)来创建一个解析器。Treetop的文档很少,我以前从未做过这种事情。我的解析器表现得好像有一个无限循环,但没有堆栈跟踪;事实证明很难追踪到。有人可以指出入门级解析/AST指南的方向吗?我真的需要一些列出规则、常见用法等的东西来使用像Treetop这样的工具。我的语法分析器在GitHub上,以防有人希望帮助我改进它。class{initialize=lambda(name){receiver.name=name}greet=lambda{IO.puts("He
我有多个ActiveRecord子类Item的实例数组,我需要根据最早的事件循环打印。在这种情况下,我需要打印付款和维护日期,如下所示:ItemAmaintenancerequiredin5daysItemBpaymentrequiredin6daysItemApaymentrequiredin7daysItemBmaintenancerequiredin8days我目前有两个查询,用于查找maintenance和payment项目(非排他性查询),并输出如下内容:paymentrequiredin...maintenancerequiredin...有什么方法可以改善上述(丑陋的)代
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
目录前言滤波电路科普主要分类实际情况单位的概念常用评价参数函数型滤波器简单分析滤波电路构成低通滤波器RC低通滤波器RL低通滤波器高通滤波器RC高通滤波器RL高通滤波器部分摘自《LC滤波器设计与制作》,侵权删。前言最近需要学习放大电路和滤波电路,但是由于只在之前做音乐频谱分析仪的时候简单了解过一点点运放,所以也是相当从零开始学习了。滤波电路科普主要分类滤波器:主要是从不同频率的成分中提取出特定频率的信号。有源滤波器:由RC元件与运算放大器组成的滤波器。可滤除某一次或多次谐波,最普通易于采用的无源滤波器结构是将电感与电容串联,可对主要次谐波(3、5、7)构成低阻抗旁路。无源滤波器:无源滤波器,又称
最近在学习CAN,记录一下,也供大家参考交流。推荐几个我觉得很好的CAN学习,本文也是在看了他们的好文之后做的笔记首先是瑞萨的CAN入门,真的通透;秀!靠这篇我竟然2天理解了CAN协议!实战STM32F4CAN!原文链接:https://blog.csdn.net/XiaoXiaoPengBo/article/details/116206252CAN详解(小白教程)原文链接:https://blog.csdn.net/xwwwj/article/details/105372234一篇易懂的CAN通讯协议指南1一篇易懂的CAN通讯协议指南1-知乎(zhihu.com)视频推荐CAN总线个人知识总
深度学习部署:Windows安装pycocotools报错解决方法1.pycocotools库的简介2.pycocotools安装的坑3.解决办法更多Ai资讯:公主号AiCharm本系列是作者在跑一些深度学习实例时,遇到的各种各样的问题及解决办法,希望能够帮助到大家。ERROR:Commanderroredoutwithexitstatus1:'D:\Anaconda3\python.exe'-u-c'importsys,setuptools,tokenize;sys.argv[0]='"'"'C:\\Users\\46653\\AppData\\Local\\Temp\\pip-instal
我是Ruby的新手,有些闭包逻辑让我感到困惑。考虑这段代码:array=[]foriin(1..5)array[5,5,5,5,5]这对我来说很有意义,因为i被绑定(bind)在循环之外,所以每次循环都会捕获相同的变量。使用每个block可以解决这个问题对我来说也很有意义:array=[](1..5).each{|i|array[1,2,3,4,5]...因为现在每次通过时都单独声明i。但现在我迷路了:为什么我不能通过引入一个中间变量来修复它?array=[]foriin1..5j=iarray[5,5,5,5,5]因为j每次循环都是新的,我认为每次循环都会捕获不同的变量。例如,这绝对
我完全不是程序员,正在学习使用Ruby和Rails框架进行编程。我目前正在使用Ruby1.8.7和Rails3.0.3,但我想知道我是否应该升级到Ruby1.9,因为我真的没有任何升级的“遗留”成本。缺点是什么?我是否会遇到与普通gem的兼容性问题,或者甚至其他我不太了解甚至无法预料的问题? 最佳答案 你应该升级。不要坚持从1.8.7开始。如果您发现不支持1.9.2的gem,请避免使用它们(因为它们很可能不被维护)。如果您对gem是否兼容1.9.2有任何疑问,您可以在以下位置查看:http://www.railsplugins.or
如何学习ruby的正则表达式?(对于假人) 最佳答案 http://www.rubular.com/在Ruby中使用正则表达式时是一个很棒的工具,因为它可以立即将结果可视化。 关于ruby-我如何学习ruby的正则表达式?,我们在StackOverflow上找到一个类似的问题: https://stackoverflow.com/questions/1881231/
假设我有一个没有特定顺序的随机数数组。假设这些是参加马拉松比赛的人的ID#,他们按照完成的顺序添加到数组中,例如:race1=[8,102,67,58,91,16,27]race2=[51,31,7,15,99,58,22]这是一个简化且有些做作的示例,但我认为它传达了基本思想。现在有几个问题:首先,我如何获得特定条目之前和之后的ID?假设我正在查看运行者58,我想知道谁在他之前和之后完成了比赛。race1,runner58:previousfinisher=67,nextfinisher=91race2,runner58:previousfinisher=99,nextfinishe