Spring循环依赖面试中也会被常常问到。但是它的整个过程很多人都不知道,什么叫循环依赖呢。多个Bean之间相互依赖,形成一个闭环。如下图(A,B,C分别为Spring容器中3个Bean)就能很好的描述。(PS必须保证默认的Bean都是单例的循环依赖才成立)。
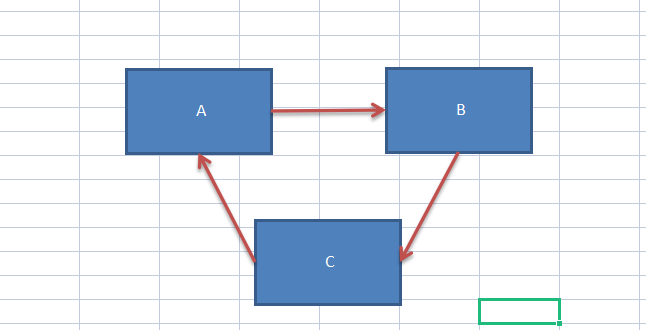
上面是对Spring循环依赖的简单解释,下图是Spring官网说明。
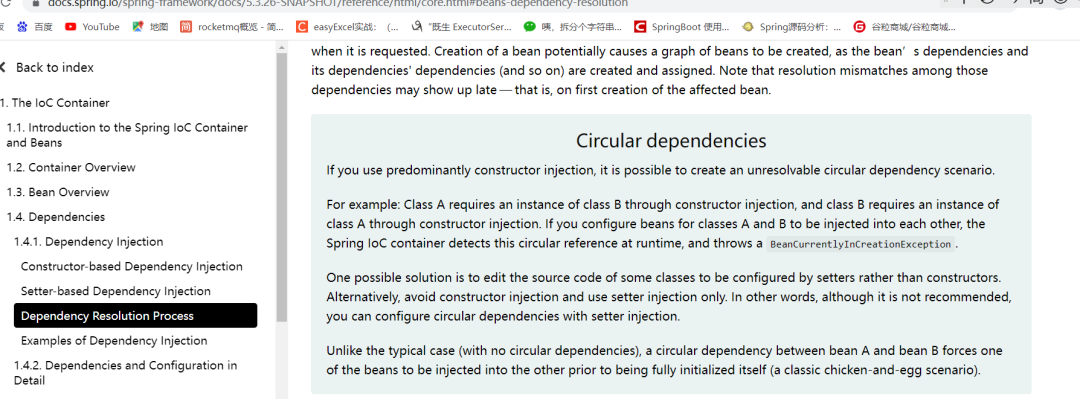
上图中重点翻译就是:循环依赖不支持构造方法的注入,使用构造方法注入会抛出BeanCurrentlyInCreationException异常 。Spring不推荐构造注入,只支持setter注入。
Spring是怎么支持和解决循环依赖的呢?

它目前解决的方案是靠自身容器中的3个Map来解决的,也称为三级缓存,如下图:
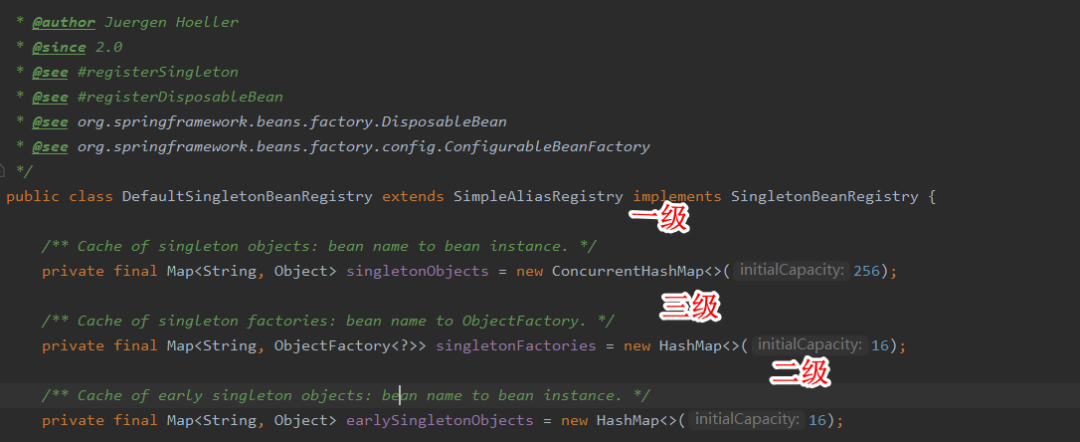
第一级缓存(也叫单例池)singleObjects:存放已经经历完整生命周期的Bean对象。
第二级缓存:earlySingletonObjects,存放早期暴漏的Bean对象,Bean周期未结束(属性未完全填充)。
第三级缓存:singletonFactories,存放可以生成Bean的工厂。
那么下面我们就通过源码来说明Spring是如何通过上面三级缓存来解决循环依赖的,我们就用2个对象来演示和理解循环依赖。
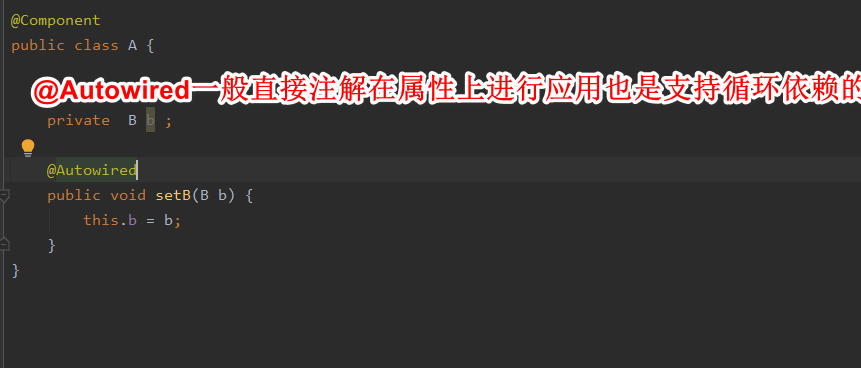
1:A创建过程中需要B,于是A将自己放到三级缓存里面,去实例化B。
2:B实例化的时候发现需要A,于是B先查一级缓存,没有再查二级缓存,还是没有,再查三级缓存,找到了A,然后把三级缓存里面的A放到二级缓存里面,并删除三级缓存里面的A。
3:B顺利完成初始化,将自己放到一级缓存里面(此时B里面的A依然是创建中的状态)然后接着回来创建A,此时B已经创建结束,直接从一级缓存里面拿B,并将A自己放到一级缓存里面。
源码分析主要关注如下方法的流程:


1:调用doCreateBean()方法,想要获取a ,于是调用getSingleton()方法从缓存中获取a 。
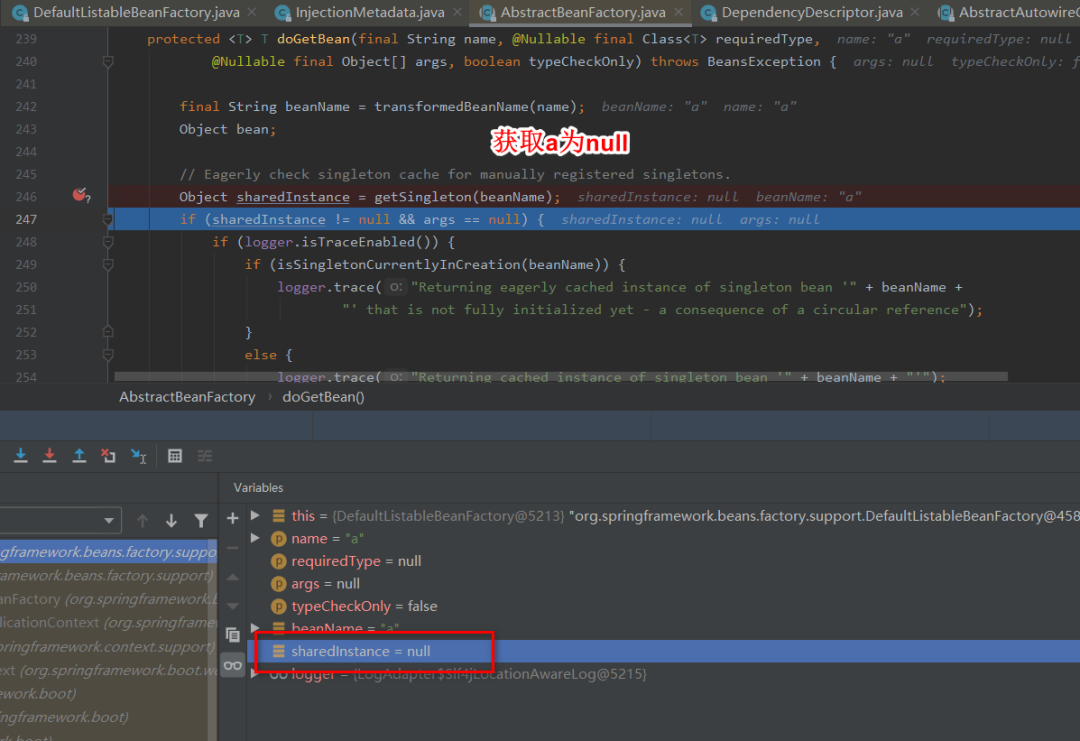
2:getSingleton()方法从一级缓存中找,没有找到返回null。
3:如果getSingleton()方法中获取到的a为null ,于是走对应的逻辑处理,调用getSingleton的重载的方法(参数为ObjectFactory)。
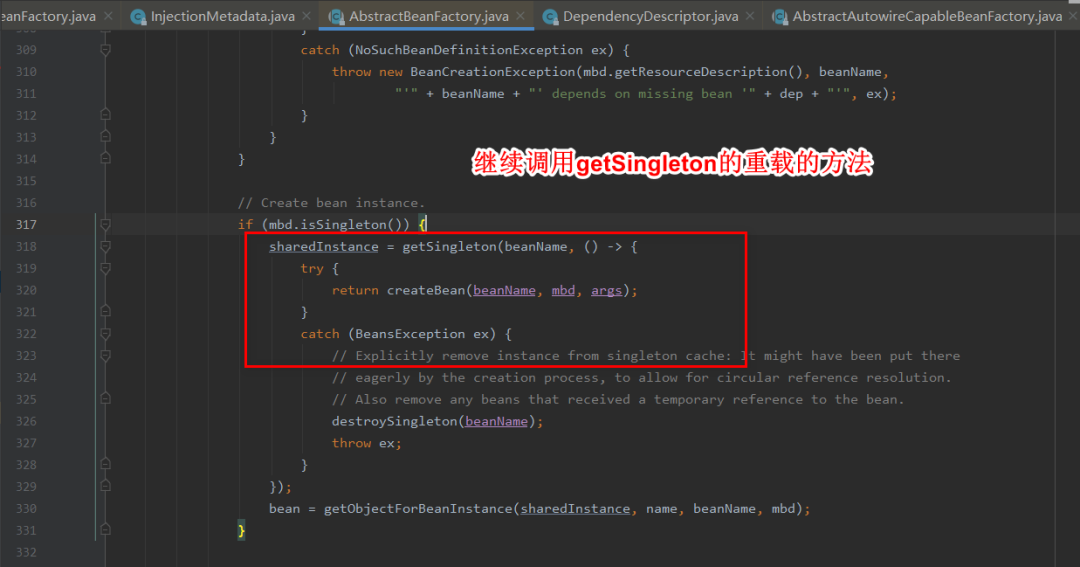
4:在getSingleton()中将a添加到一个集合中,用于标记a正在创建中,然后调用匿名内部类的creatBean方法。
5:进入AbstractAutowireCapableBeanFactory的doCreateBean,创建出a的实例然后将a添加到三级缓存中。
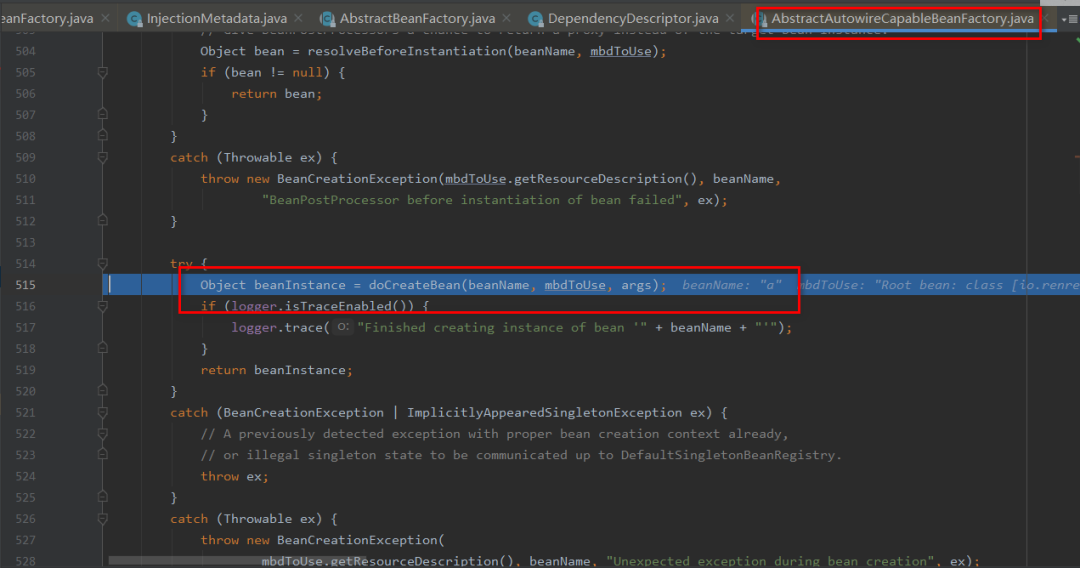
6:对a进行属性的填充,此时检测到a依赖于b,于是开始找b 。
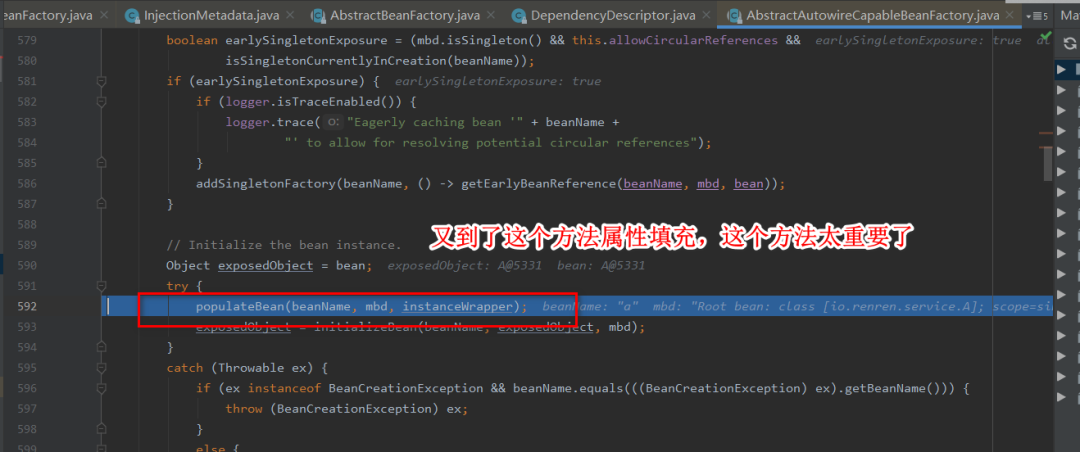
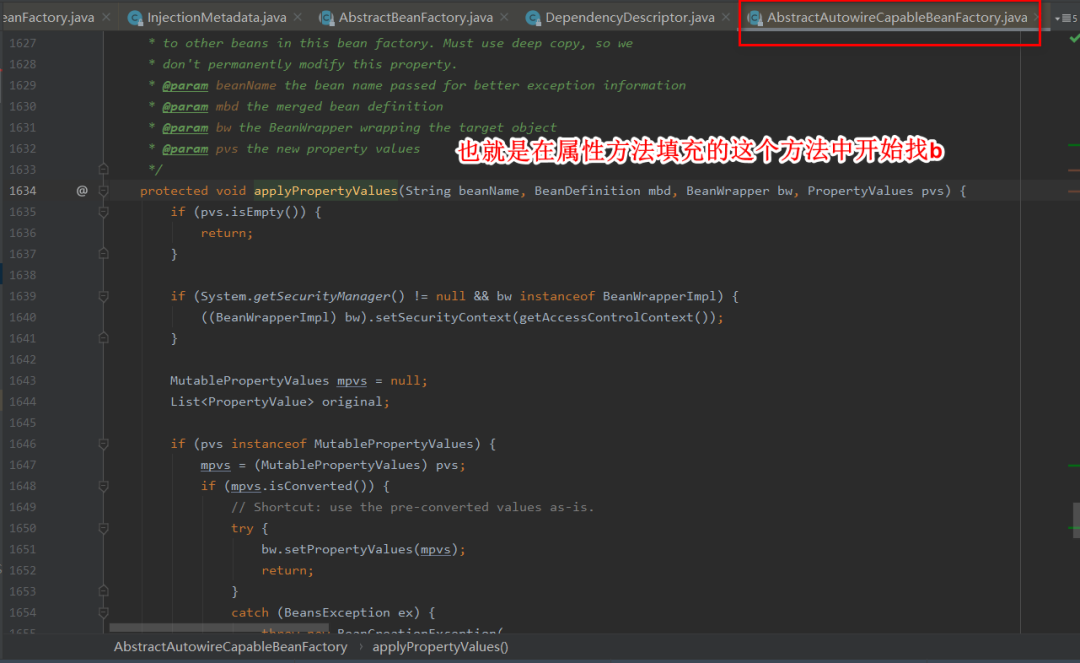
7:找b的时候调用doGetBean()方法和上面创建a的过程一样,到缓存中找b,没有则创建,然后给b填充属性。
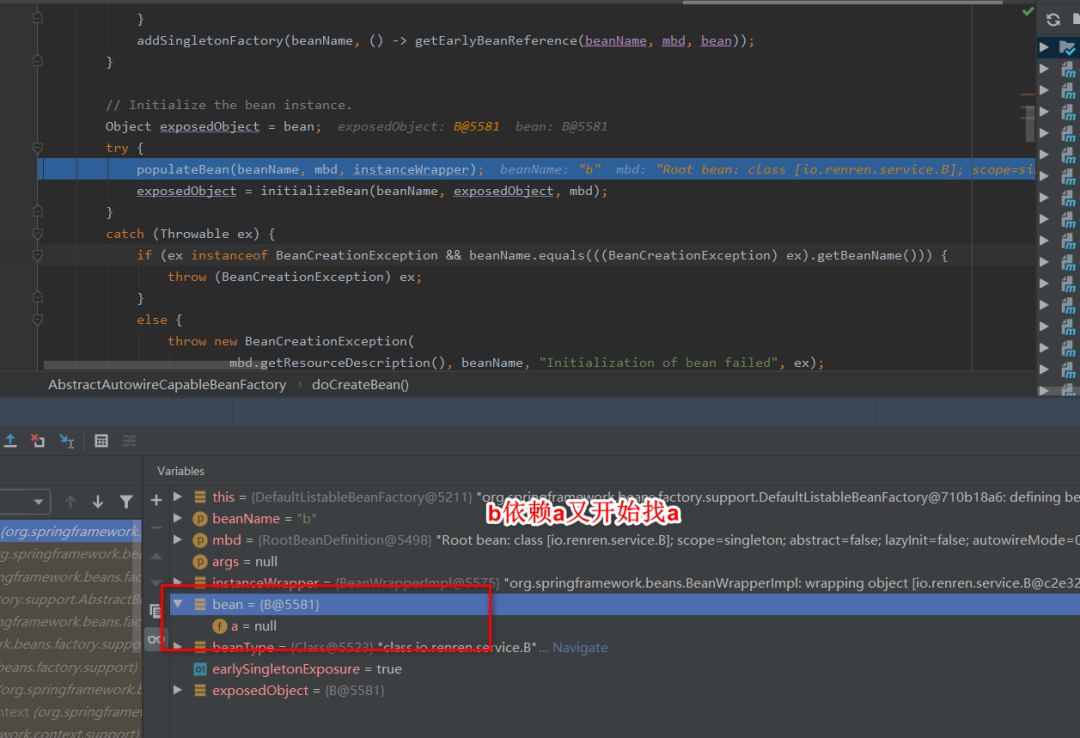
8:此时b依赖于a,调用getSingleton获取a,依次从一级,二级,三级缓存中找,此时从三级缓存中获取a的创建工厂,通过创建工厂获取到singeltonObject,此时这个singletonObject指向的就是上面的doCreateBean方法中获取的实例化的a。
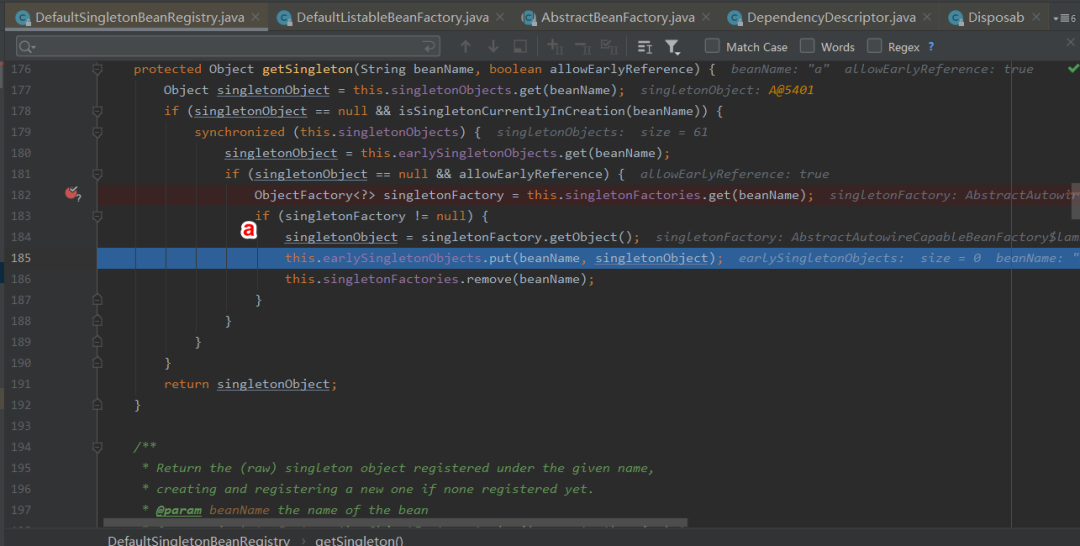
9:这样b就获取到了a的依赖,于是b顺利完成了实例化,并将a从三级缓存移到二级缓存中。
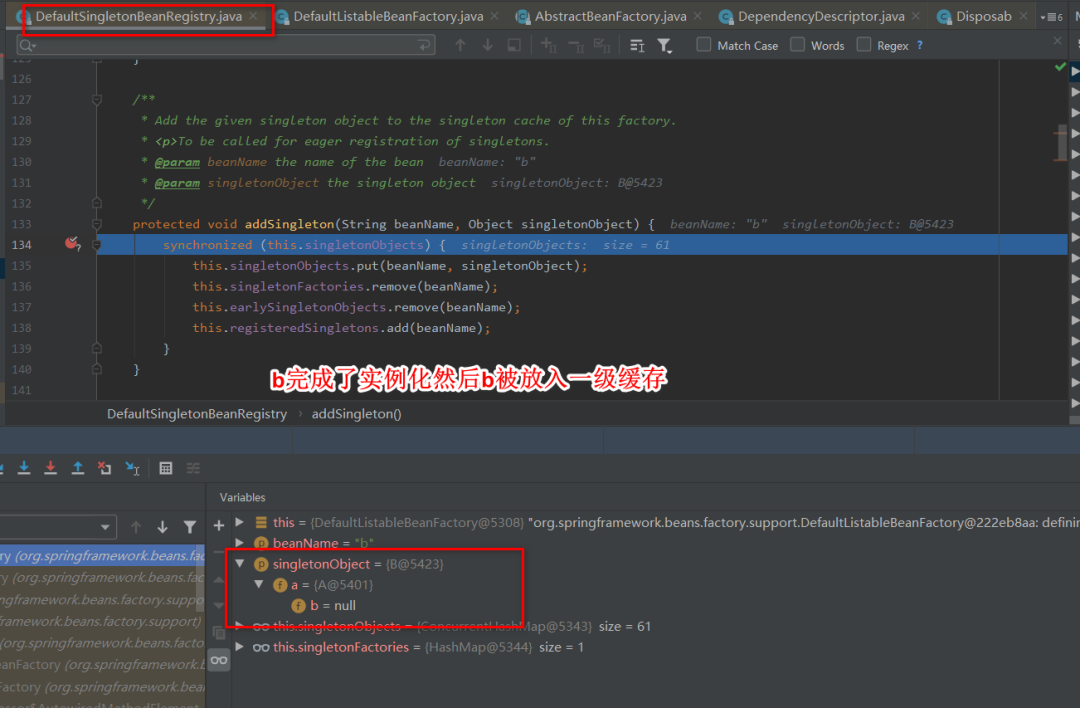
10:随后a继续属性填充的工作,此时也获取了b,然后a也就完成了创建,回到getSingleton方法中继续执行,将a从二级缓存移动到一级缓存。
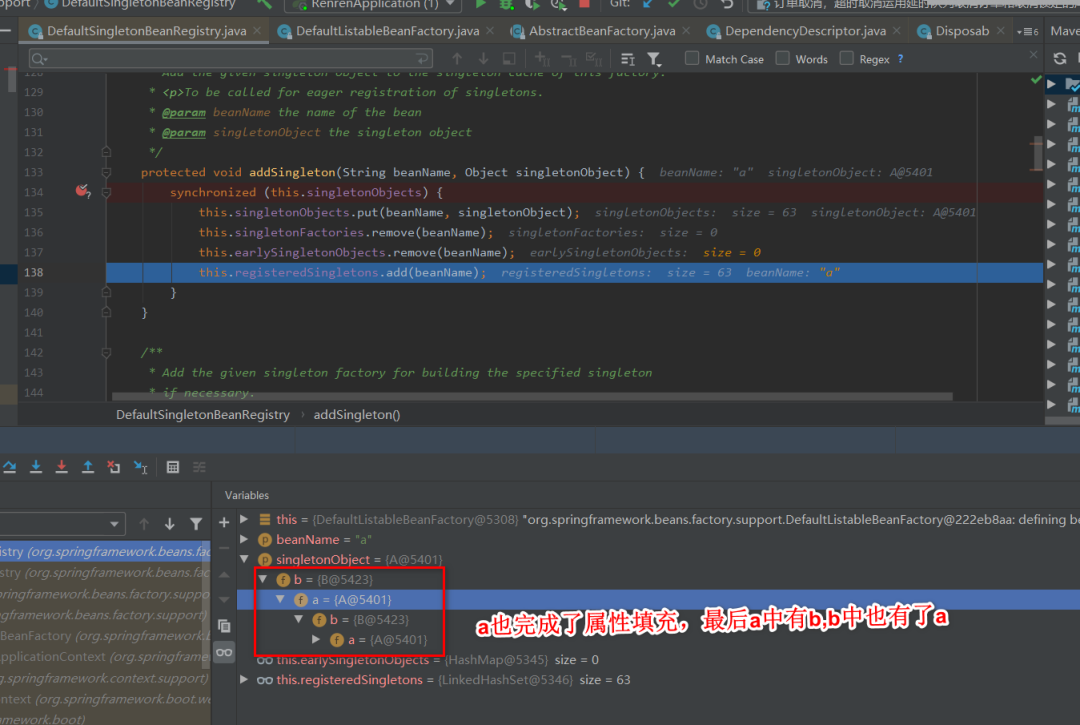
具体为什么用三级缓存不用二级缓存去解决,后面章节分析,欢迎转发,评论,点赞
微信公众号搜索:程序员xiaozhang 。如果遇到Spring的问题也可以私信我 能帮忙解决的尽量解决。


我脑子里浮现出一些关于一种新编程语言的想法,所以我想我会尝试实现它。一位friend建议我尝试使用Treetop(Rubygem)来创建一个解析器。Treetop的文档很少,我以前从未做过这种事情。我的解析器表现得好像有一个无限循环,但没有堆栈跟踪;事实证明很难追踪到。有人可以指出入门级解析/AST指南的方向吗?我真的需要一些列出规则、常见用法等的东西来使用像Treetop这样的工具。我的语法分析器在GitHub上,以防有人希望帮助我改进它。class{initialize=lambda(name){receiver.name=name}greet=lambda{IO.puts("He
我有多个ActiveRecord子类Item的实例数组,我需要根据最早的事件循环打印。在这种情况下,我需要打印付款和维护日期,如下所示:ItemAmaintenancerequiredin5daysItemBpaymentrequiredin6daysItemApaymentrequiredin7daysItemBmaintenancerequiredin8days我目前有两个查询,用于查找maintenance和payment项目(非排他性查询),并输出如下内容:paymentrequiredin...maintenancerequiredin...有什么方法可以改善上述(丑陋的)代
我正在使用Ruby2.1.1和Rails4.1.0.rc1。当执行railsc时,它被锁定了。使用Ctrl-C停止,我得到以下错误日志:~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.2/lib/spring/client/run.rb:47:in`gets':Interruptfrom~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.2/lib/spring/client/run.rb:47:in`verify_server_version'from~/.rvm/gems/ruby-2.1.1/gems/spring-1.1.
我正在尝试修改当前依赖于定义为activeresource的gem:s.add_dependency"activeresource","~>3.0"为了让gem与Rails4一起工作,我需要扩展依赖关系以与activeresource的版本3或4一起工作。我不想简单地添加以下内容,因为它可能会在以后引起问题:s.add_dependency"activeresource",">=3.0"有没有办法指定可接受版本的列表?~>3.0还是~>4.0? 最佳答案 根据thedocumentation,如果你想要3到4之间的所有版本,你可以这
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
转自:spring.profiles.active和spring.profiles.include的使用及区别说明下文笔者讲述spring.profiles.active和spring.profiles.include的区别简介说明,如下所示我们都知道,在日常开发中,开发|测试|生产环境都拥有不同的配置信息如:jdbc地址、ip、端口等此时为了避免每次都修改全部信息,我们则可以采用以上的属性处理此类异常spring.profiles.active属性例:配置文件,可使用以下方式定义application-${profile}.properties开发环境配置文件:application-dev
我是Ruby的新手,有些闭包逻辑让我感到困惑。考虑这段代码:array=[]foriin(1..5)array[5,5,5,5,5]这对我来说很有意义,因为i被绑定(bind)在循环之外,所以每次循环都会捕获相同的变量。使用每个block可以解决这个问题对我来说也很有意义:array=[](1..5).each{|i|array[1,2,3,4,5]...因为现在每次通过时都单独声明i。但现在我迷路了:为什么我不能通过引入一个中间变量来修复它?array=[]foriin1..5j=iarray[5,5,5,5,5]因为j每次循环都是新的,我认为每次循环都会捕获不同的变量。例如,这绝对
有什么方法可以告诉sidekiq一项工作依赖于另一项工作,并且在后者完成之前无法开始? 最佳答案 仅使用Sidekiq;答案是否定的。正如DickieBoy所建议的那样,您应该能够在依赖作业完成时将其启动。像这样。#app/workers/hard_worker.rbclassHardWorkerincludeSidekiq::Workerdefperform()puts'Doinghardwork'LazyWorker.perform_async()endend#app/workers/lazy_worker.rbclassLaz
我无法运行Spring。这是错误日志。myid-no-MacBook-Pro:myid$spring/Users/myid/.rbenv/versions/1.9.3-p484/lib/ruby/gems/1.9.1/gems/spring-0.0.10/lib/spring/sid.rb:17:in`fiddle_func':uninitializedconstantSpring::SID::DL(NameError)from/Users/myid/.rbenv/versions/1.9.3-p484/lib/ruby/gems/1.9.1/gems/spring-0.0.10/li
假设我有一个没有特定顺序的随机数数组。假设这些是参加马拉松比赛的人的ID#,他们按照完成的顺序添加到数组中,例如:race1=[8,102,67,58,91,16,27]race2=[51,31,7,15,99,58,22]这是一个简化且有些做作的示例,但我认为它传达了基本思想。现在有几个问题:首先,我如何获得特定条目之前和之后的ID?假设我正在查看运行者58,我想知道谁在他之前和之后完成了比赛。race1,runner58:previousfinisher=67,nextfinisher=91race2,runner58:previousfinisher=99,nextfinishe