一、Vitis-AI Pytorch框架量化(vai_q_pytorch)
虽然Xilinx提供了Vitis-AI用户手册Vitis-AI 2.5用户手册,但是其中对于一些安装和使用介绍极为简略,在安装和使用过程中碰到了一系列问题,所以在这里记录一下使用Vitis-AI过程中遇到的各种坑。
我们使用的是pytorch框架的yolo模型,在使用vitis-ai量化前根据指导手册,要安装vai_q_pytorch,但是需要注意,我们在安装过程中一直在报错,如下图。
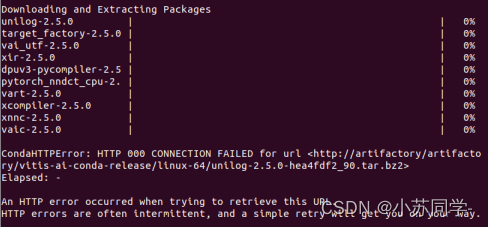
上图中几个package一直无法下载,一开始根据下方报错,以为是代理问题,我们尝试寻找代理服务器去下载,发现还是这几个包无法正常下载。
仔细观察了无法下载的几个package,发现有一个共同特点,就是版本号均为2.5.0,这就很奇怪了,为什么全都是2.5.0版本的package无法下载,于是去看xilinx提供的下载脚本,突然发现这么一行,该行命令是提供下载地址的,如下图:

此时恍然大悟啊!官方提供的最新脚本中版本号是2.0.0,而执行安装命令时默认安装版本号是2.5.0,所以下载好的package里没有所需要的版本号,自然无法安装对应package。知道问题后,接下来就是寻找2.5.0版本的下载包地址(个人觉得Xilinx很狗,这么大的企业,对这些软件的维护,修改信息全都放在GitHub上)。在GitHub Xilinx账号下找到了其更新后的下载脚本,接下来就很简单了,将更新后的脚本copy到conda环境中,重新运行命令即可正常安装。可以看到下图中版本号为正确的2.5.0。

(Ps:正确脚本地址:val_q_pytorch2.5.0脚本)
Xilinx用户手册提供的语言可以看一下:
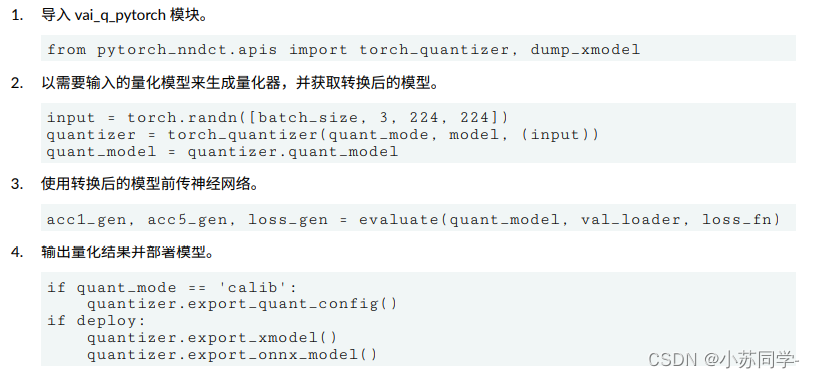
???一脸问号,这只提供了API接口,里面对于模型的处理,数据的导入完全没有介绍,那就只能自己来写,可以参考官方量化脚本。pytorch模型量化代码(minst数据集手写体识别)![]() https://github.com/Xilinx/Vitis-AI-Tutorials/blob/1.4/Design_Tutorials/09-mnist_pyt/files/quantize.py
https://github.com/Xilinx/Vitis-AI-Tutorials/blob/1.4/Design_Tutorials/09-mnist_pyt/files/quantize.py
可以发现主要包括几部分:读取模型、调用数据集、常规预测函数(包括Detect、前向传播等等)、量化校准、Xmodel生成。
首先我们来看一下模型的读取。
model = model.to(device)
model_name = "yolov5"
file_path = os.path.join(args.model_dir, model_name + '.pt')根据自己选择使用GPU还是CPU。
if (torch.cuda.device_count() > 0):
print('You have',torch.cuda.device_count(),'CUDA devices available')
for i in range(torch.cuda.device_count()):
print(' Device',str(i),': ',torch.cuda.get_device_name(i))
print('Selecting device 0..')
device = torch.device('cuda:0')
else:
print('No CUDA devices available..selecting CPU')
device = torch.device('cpu')加载数据集,因为我使用的是Coco数据集,所以Class数为80(具体数字根据自己数据集和所训练的模型决定)。
parser.add_argument('--data_dir',default="datasets/val",
help='Data set directory, when quant_mode=calib, it is for calibration, while quant_mode=test it is for evaluation')
dataloader = create_dataloader(args.data_dir, imgsz=imgsz, batch_size=batch_size, pad=0.5,stride=32,
workers=workers, prefix=colorstr(f'quant: '))[0]
model.eval()
nc =80 # number of classes在脚本中加入Detect时需要注意,在用户手册中有这么一段话,如下图。

可以看到,脚本中只能包含前传函数,所以需要将特征提取中多余的部分注释掉,仅保留下面代码即可。
z = []
for i in range(nl):
bs, _, ny, nx, _no= x[i].shape
# x[i] = x[i].view(bs, na, no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if grid[i].shape[2:4] != x[i].shape[2:4]:
grid[i], anchor_grid[i] = _make_grid(anchors,stride,nx, ny, i)之后是模型推理部分(部分代码)。
x=model(im)
# ckpt = torch.load(file_path, map_location=device)
# paras=ckpt['model'].yaml
nc = 10 # number of classfication
no = nc+5 #each anchor's output,include nc(class)+conf(1)+xywh(4),故nc+5
anchors = [[1.25, 1.625, 2, 3.75, 4.125, 2.875], [1.875, 3.8125, 3.875, 2.8125, 3.6875, 7.4375], [3.625, 2.8125, 4.875, 6.1875, 11.65625, 10.1875]]
nl = 3 # number of detection layers
na = 3 # number of anchors
grid = [torch.zeros(1)] * nl # init grid
anchors = torch.tensor(anchors).float().view(nl, -1, 2)
# register_buffer('anchors', a)
anchor_grid=[torch.zeros(1)] * nl
stride = [8, 16, 32]脚本写好之后便可以开始模型的量化,分为两步,第一步是量化校准,使用如下命令。可以看到校准过程。
python quantize.py --quant_mode calib --subset_len 1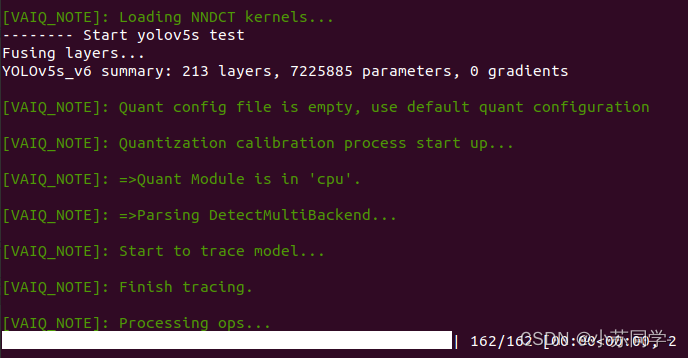
第二部便是生成.Xmodel文件,使用如下命令,可以看到生成过程。
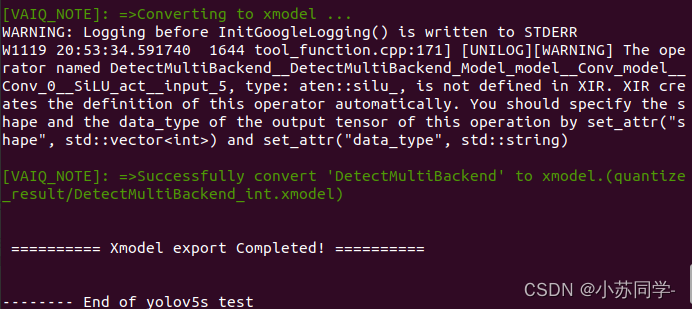
查看量化后F1参数,精度并没有过多损失。
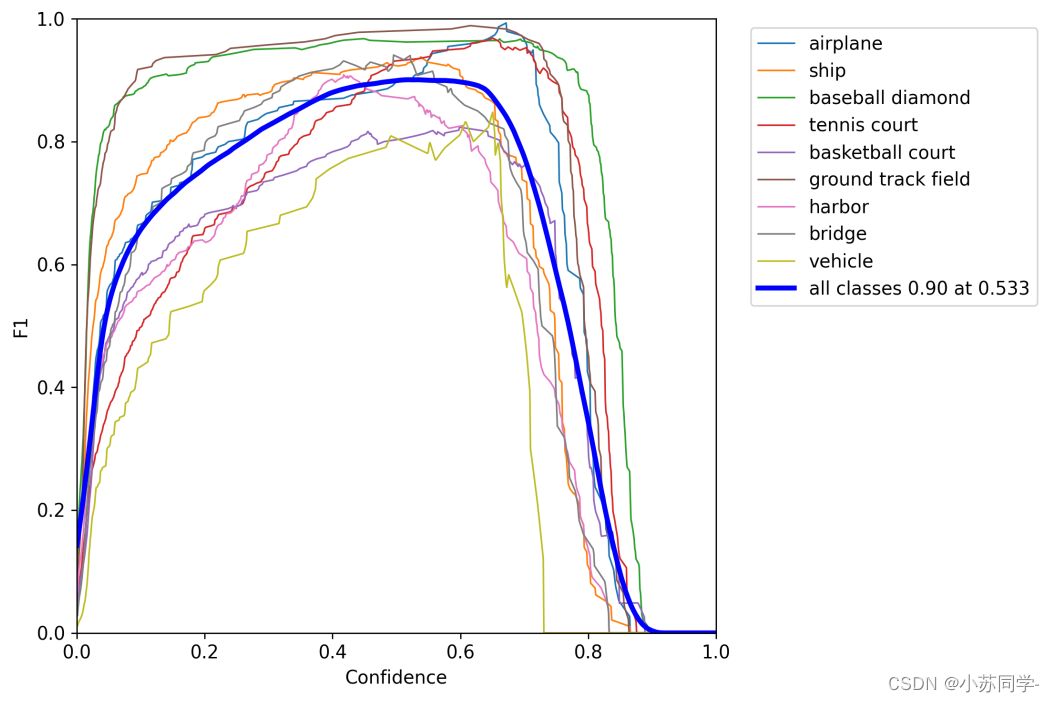
这一步才是最容易踩坑的地方!!可以看到上一步量化后精度还是很不错的!此时大部分工作已经完成,编译时候仅需要一行命令就可以解决,选择相对应FPGA开发板DPU的型号:
vai_c_xir -x ./quantize_result/DetectMultiBackend_int.xmodel -a /opt/vitis_ai/compiler/arch/DPUCZDX8G/ZCU104/arch.json -o ./ -n model很简单对吧!但是编译结束后,我们发现有多个DPU子图的模型(下图红框位置),说明此时模型并没有被完整的量化编译过来。
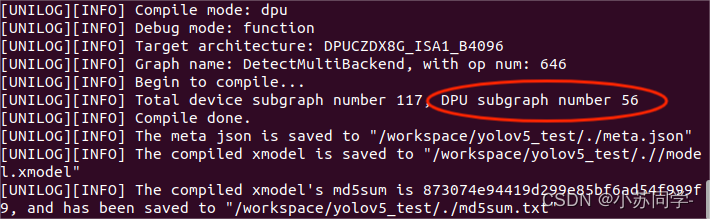
红框位置正确编译后应该只会生成一个子图,也就是DPU subgraph number为1,那么问题出在哪里呢?
首先需要检查量化脚本中是否按照手册要求仅保留前传函数,其余函数均移除,经过检查是没有问题的。
那么问题只能是模型中存在了DPU不能够识别的算子,才会导致生成多个子图,我们打开DPUCZDX8G产品指南,可以清楚看到该型号下DPU所支持的算子,如下图。

相信大家看到后肯定明白问题出在哪里了!那就是激活函数的问题,我们本次yolo模型选用的是yolov5 6.0及以上版本,这些版本中一个显著的变化就是激活函数已经更改为SiLu,我们可以看到SiLu并不在该型号DPU支持算子目录下,为了验证猜想,我们将生成的.Xmodel用Netron工具打开,我们可以看到量化后模型结构(其中一小部分)如下图:
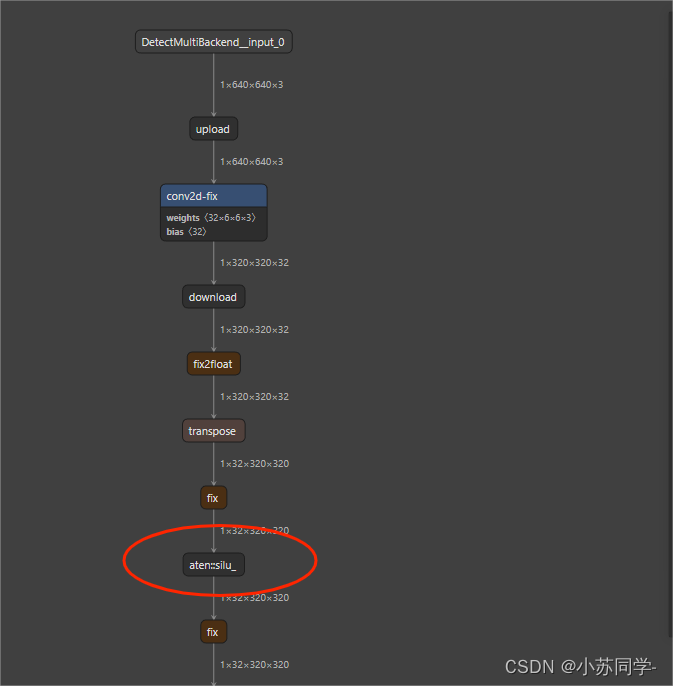
可以看到红框部分就是我们所用模型的激活函数,果然!激活函数是silu,不是DPU所支持的算子类型,我们将其改为ReLu,之后重新编译,得到下图:
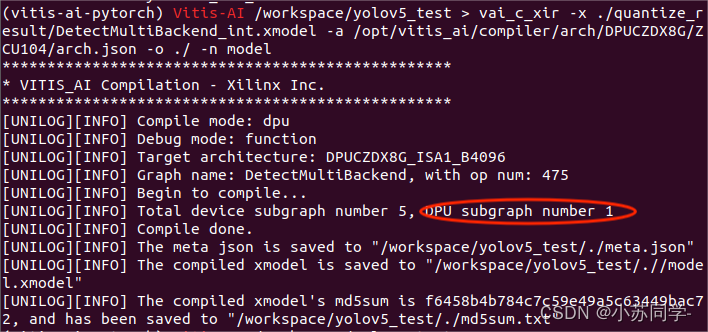
可以看到,DPU subgraph number为1!编译成功!!
以上就是今天要讲的我在使用Vitis-AI过程中才的一些坑,本文仅仅简单介绍了Vitis-AI量化编译的过程,后续在ZCU104开发板的部署将持续更新。
我正在使用这个:4.times{|i|assert_not_equal("content#{i+2}".constantize,object.first_content)}我之前声明过局部变量content1content2content3content4content5我得到的错误NameError:wrongconstantnamecontent2这个错误是什么意思?我很确定我想要content2=\ 最佳答案 你必须用一个大字母来调用ruby常量:Content2而不是content2。Aconstantnamestart
写在前面前两天学习并整理的大气散射基础知识:【Unity大气渲染】关于单次大气散射的理论知识,收获了很多,但不得不承认的是,这其实已经是最早的、90年代的非常古老的方法了,后来也出现了一些优化性的计算思路和方法。因此,我打算先不急着跟各种教程在Unity中实现大气散射,而是再花时间来看看最近的游戏是如何去实现大气渲染的:06.游戏中地形大气和云的渲染(下)|GAMES104-现代游戏引擎:从入门到实践接下来就跟着GAMES104讲地形大气和云渲染的部分学习并做简单的记录,涉及到之前没提到的Mie散射也只选择直接截图PPT的方式记录啦!毕竟对于做作品来说,之后实现出来才是重要的~当然,May佬的
文章目录前言1.AI的发展历程2.我是如何接触到人工智能的概念和产品的3.对于ChatGPT的一点看法4.AI对大学毕业生的职业发展的利与弊5.对于AI的思考和问题前言随着ChatGPT的爆火,生成式AI,大模型的人工智能被越来越多的人注意到,同时他也带来了许多问题。本文将对几方面进行探讨。1.AI的发展历程远古时期在公元前第一个千禧年,中国,印度和希腊哲学家都提出了一些推理的研究理论,比如亚里士多德(Aristotle)进行了演绎推理三段论的完整分析,欧几里得(Euclid)所著Elements是一种形式推理的模型,MuḥammadibnMūsāal-Khwārizmī,发明了代数学,即我们
目录1古彝文与古典保护2古文识别的挑战2.1西文与汉文OCR2.2古彝文识别难点3合合信息:古彝文保护新思路3.1图像矫正3.2图像增强3.3语义理解3.4工程技巧4总结1古彝文与古典保护彝文指的是云南、贵州、四川等地的彝族人使用的文字,区别于现代意义上的彝文,古彝文指的是在民间流通使用的原生态彝文,多达87046字。古彝文的起源距今至少数千年,是世界上最古老的文字之一。对古彝文字集研究有助于理解尚未被翻译成汉文、用字尚未规范化的古籍,更深层、透彻地作用于传统文化保护。古彝文字义对照图(网络资料+邵文苑供图)古籍是不可再生的宝贵资源,应当得到妥善保护。中国的古籍在历史上迭经水火兵燹等自然灾害、
关于yolov5训练时参数workers和batch-size的理解yolov5训练命令workers和batch-size参数的理解两个参数的调优总结yolov5训练命令python.\train.py--datamy.yaml--workers8--batch-size32--epochs100yolov5的训练很简单,下载好仓库,装好依赖后,只需自定义一下data目录中的yaml文件就可以了。这里我使用自定义的my.yaml文件,里面就是定义数据集位置和训练种类数和名字。workers和batch-size参数的理解一般训练主要需要调整的参数是这两个:workers指数据装载时cpu所使
我有一个单表继承设置,我有一个Controller(我觉得有多个Controller会重复)。但是,对于某些方法,我想调用模型的子类。我想我可以让浏览器发送一个参数,我会针对该参数编写一个case语句。像这样的东西:case@model[:type]when"A"@results=Subclass1.search(params[:term])when"B"@results=Subclass2.search(params[:term])...end或者,我了解到Ruby的所有技巧都可以用字符串创建模型。像这样的东西:@results=params[:model].constantize.
在我的Rails应用程序中,我收到来自brakeman的以下安全警告。使用模型属性调用的不安全反射方法常量化。这是我的代码正在执行的操作。chart_type=Chart.where(id:chart_id,).pluck(:type).firstbeginChartPresenter.new(chart_type.camelize.constantize.find(chart_id))rescueraise"Unabletofindthechartpresenter"end根据我的研究,我还没有找到任何具体的解决方案。我听说你可以创建一个白名单,但我不确定brakeman在寻找什么。
文章目录1.价差套利原理1.1概述1.2以BTC为例2.投研分析3.veighna的价差交易回测引擎4.实盘交易1.价差套利原理1.1概述在数字货币交易市场,我们会发现大多数行情下,相同币种之间的不同交割合约会存在一定的价差,由于它们属于同一品种,本身价值不会有任何差别,而且涨跌趋势一致,相关性高。那么如果在它们价差低的时候买入,价差高的时候卖出,这样我们就可以赚取中间的这部分差价。不过在实际交易过程中,我们还需要考虑到交易滑点、手续费、极端行情下,价差走出趋势特征…1.2以BTC为例图一、不同合约的比特币行情图由上图可以看出比特币远月合约与永续合约之间存在一定的价差。图二、某一时刻比特币价差
Anaconda+PyCharm+PyTorch(GPU)+虚拟环境声明一、安装Anaconda二、安装PyCharm三、创建虚拟环境并安装PyTorch四、关联虚拟环境五、致谢声明感谢姜小敏同学对我的支持、鼓励和鞭策!默认你的电脑上已经装有GPU,如果没有GPU,可以正常的进行各种下载安装操作,但是最终结果会有所不同。一、安装Anaconda首先,进入Anaconda官网,单击Download按钮,稍微等待即可下载安装包。下载好之后,双击打开安装包,进行一系列安装操作。建议安装路径全英文,并且一定要记住安装地址。此处不勾选第二项,因此之后需要人为配置环境变量。没啥用,不用勾选,就是跳出两个打
量化交易-因子有效性分析一、因子的IC分析2.信息系数3.举例4.因子处理4.1去极值4.2标准化4.3市值中性化一、因子的IC分析判断因子与收益的相关性强度分析结果因子平均收益ICmeanICstdIC>0.02:IC大约0.02的比例,越大越严格IR:信息比率(历史表现的稳定性),IR=ICmean/ICstd2.信息系数定义:某一期的IC指的是该期因子暴露度和股票下期的实际回报值在横截面上的相关系数。因子暴露度:因子本身数值周期一天:该期的因子值(2023.1.11)、下期(2023.1.12)收益率(截面数据)计算方式:斯皮尔曼相关系数(RankIC)斯皮尔曼相关系数表明X(独立变量)