 本文主要介绍ceph16版本集群节点系统磁盘故障后的集群恢复,虽然系统盘很多都是做了raid1,但从实际做的项目看,总是有很多未知意外发生,节点挂掉后,上面的mon和osd,mgr都会down掉,如果所在节点的mgr服务是激活状态,则其他节点所在的备用节点将会升级为激活状态。
本文主要介绍ceph16版本集群节点系统磁盘故障后的集群恢复,虽然系统盘很多都是做了raid1,但从实际做的项目看,总是有很多未知意外发生,节点挂掉后,上面的mon和osd,mgr都会down掉,如果所在节点的mgr服务是激活状态,则其他节点所在的备用节点将会升级为激活状态。ceph orch host rm node4 --offline --force
192.168.1.1 node1
192.168.1.2 node2
192.168.1.3 node3
ssh-copy-id -f -i /etc/ceph/ceph.pub node1
curl -sSL https://get.daocloud.io/docker | sh
systemctl daemon-reload
systemctl restart docker
systemctl enable docker
# curl --silent --remote-name --location https://github.com/ceph/ceph/raw/pacific/src/cephadm/cephadm
# chmod +x cephadm
# ./cephadm add-repo --release pacific
# ./cephadm install
# ./cephadm install ceph-common
[root@node2 ~]# ceph orch host add node1
Added host 'node1'
ceph orch host ls
ceph orch host label add node1 _admin
或者在添加节点时就可以把标签添加上
ceph orch host add node1 --labels=_admin
# vceph osd create
2
ceph-volume lvm activate (osdid) (fsid)
ceph auth add osd.2 osd 'allow *' mon 'allow rwx' -i /var/lib/ceph/osd/ceph-2/keyring
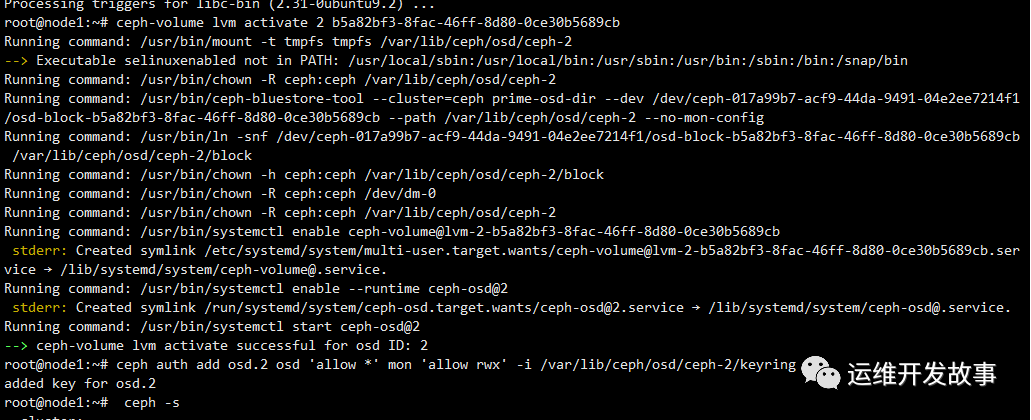
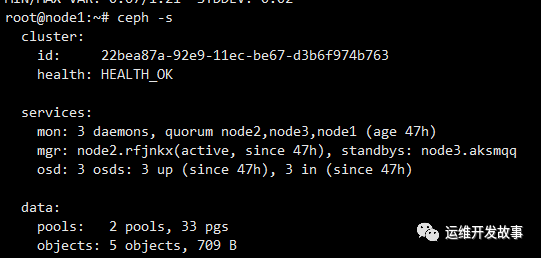
 之后三个osd都会up,但是存在osd的daemon不被cephadm管理的问题,因此我还是删掉这个osd,重新格式化后添加的,删除osd的操作如下:
之后三个osd都会up,但是存在osd的daemon不被cephadm管理的问题,因此我还是删掉这个osd,重新格式化后添加的,删除osd的操作如下:
ceph orch ps --daemon_type osd
#查看osd对应的容器id,先停止容器,我这里没有osd容器启动,所以这步可以忽略
ceph osd out 2
ceph osd crush remove osd.2
ceph auth del osd.2
ceph osd rm 2
# 显示当前设备的状态
# dmsetup status
# 删除所有映射关系
# dmsetup remove_all
# 格式化刚才删除的osd所在磁盘
mkfs -t ext4 /dev/vdb
ceph orch daemon add osd node1:/dev/vdb
我主要使用Ruby来执行此操作,但到目前为止我的攻击计划如下:使用gemsrdf、rdf-rdfa和rdf-microdata或mida来解析给定任何URI的数据。我认为最好映射到像schema.org这样的统一模式,例如使用这个yaml文件,它试图描述数据词汇表和opengraph到schema.org之间的转换:#SchemaXtoschema.orgconversion#data-vocabularyDV:name:namestreet-address:streetAddressregion:addressRegionlocality:addressLocalityphoto:i
我正在编写一个简单的静态Rack应用程序。查看下面的config.ru代码:useRack::Static,:urls=>["/elements","/img","/pages","/users","/css","/js"],:root=>"archive"map'/'dorunProc.new{|env|[200,{'Content-Type'=>'text/html','Cache-Control'=>'public,max-age=6400'},File.open('archive/splash.html',File::RDONLY)]}endmap'/pages/search.
电脑0x0000001A蓝屏错误怎么U盘重装系统教学分享。有用户电脑开机之后遇到了系统蓝屏的情况。系统蓝屏问题很多时候都是系统bug,只有通过重装系统来进行解决。那么蓝屏问题如何通过U盘重装新系统来解决呢?来看看以下的详细操作方法教学吧。 准备工作: 1、U盘一个(尽量使用8G以上的U盘)。 2、一台正常联网可使用的电脑。 3、ghost或ISO系统镜像文件(Win10系统下载_Win10专业版_windows10正式版下载-系统之家)。 4、在本页面下载U盘启动盘制作工具:系统之家U盘启动工具。 U盘启动盘制作步骤: 注意:制作期间,U盘会被格式化,因此U盘中的重要文件请注
在应用开发中,有时候我们需要获取系统的设备信息,用于数据上报和行为分析。那在鸿蒙系统中,我们应该怎么去获取设备的系统信息呢,比如说获取手机的系统版本号、手机的制造商、手机型号等数据。1、获取方式这里分为两种情况,一种是设备信息的获取,一种是系统信息的获取。1.1、获取设备信息获取设备信息,鸿蒙的SDK包为我们提供了DeviceInfo类,通过该类的一些静态方法,可以获取设备信息,DeviceInfo类的包路径为:ohos.system.DeviceInfo.具体的方法如下:ModifierandTypeMethodDescriptionstatic StringgetAbiList()Obt
需求:要创建虚拟机,就需要给他提供一个虚拟的磁盘,我们就在/opt目录下创建一个10G大小的raw格式的虚拟磁盘CentOS-7-x86_64.raw命令格式:qemu-imgcreate-f磁盘格式磁盘名称磁盘大小qemu-imgcreate-f磁盘格式-o?1.创建磁盘qemu-imgcreate-fraw/opt/CentOS-7-x86_64.raw10G执行效果#ls/opt/CentOS-7-x86_64.raw2.安装虚拟机使用virt-install命令,基于我们提供的系统镜像和虚拟磁盘来创建一个虚拟机,另外在创建虚拟机之前,提前打开vnc客户端,在创建虚拟机的时候,通过vnc
我去了这个website查看Rails5.0.0和Rails5.1.1之间的区别为什么5.1.1不再包含:config/initializers/session_store.rb?谢谢 最佳答案 这是删除它的提交:Setupdefaultsessionstoreinternally,nolongerthroughanapplicationinitializer总而言之,新应用没有该初始化器,session存储默认设置为cookie存储。即与在该初始值设定项的生成版本中指定的值相同。 关于
因为我现在正在做一些时间测量,我想知道是否可以在不使用Benchmark类或命令行实用程序time的情况下测量用户时间或系统时间。使用Time类只显示挂钟时间,而不显示系统和用户时间,但是我正在寻找具有相同灵active的解决方案,例如time=TimeUtility.now#somecodeuser,system,real=TimeUtility.now-time原因是我有点不喜欢Benchmark,因为它不能只返回数字(编辑:我错了-它可以。请参阅下面的答案。)。当然,我可以解析输出,但感觉不对。*NIX系统的time实用程序也应该可以解决我的问题,但我想知道是否已经在Ruby中实
我正在关注Hartl的railstutorial.org并已到达11.4.4:Imageuploadinproduction.我做了什么:注册亚马逊网络服务在AmazonIdentityandAccessManagement中,我创建了一个用户。用户创建成功。在AmazonS3中,我创建了一个新存储桶。设置新存储桶的权限:权限:本教程指示“授予上一步创建的用户读写权限”。但是,在存储桶的“权限”下,未提及新用户名。我只能在每个人、经过身份验证的用户、日志传送、我和亚马逊似乎根据我的名字+数字创建的用户名之间进行选择。我已经通过选择经过身份验证的用户并选中了上传/删除和查看权限的框(而不
在Ruby中,以毫秒为单位获取自纪元(1970)以来的当前系统时间的正确方法是什么?我试过了Time.now.to_i,好像不是我想要的结果。我需要结果显示毫秒并且使用long类型,而不是float或double。 最佳答案 (Time.now.to_f*1000).to_iTime.now.to_f显示包含十进制数字的时间。要获得毫秒数,只需将时间乘以1000。 关于ruby-以毫秒为单位获取当前系统时间,我们在StackOverflow上找到一个类似的问题:
我正在使用mechanize登录网站,然后检索页面。我遇到了一些问题,我怀疑这是由于cookie中的某些值造成的。当Mechanize登录网站时,我假设它存储了cookie。如何通过Mechanize打印出存储在cookie中的所有数据? 最佳答案 代理有一个cookie方法。agent=Mechanize.newpage=agent.get("http://www.google.com/")agent.cookiesagent.cookies.to_scookie返回一个Mechanize::Cookiesobject