💂 个人网站:【紫陌】【笔记分享网】
💅 想寻找共同学习交流、共同成长的伙伴,请点击【前端学习交流群】
pinia 是 Vue 的存储库,它允许您跨组件/页面共享状态。就是和vuex一样的实现数据共享。
依据Pinia官方文档,Pinia是2019年由vue.js官方成员重新设计的新一代状态管理器,更替Vuex4成为Vuex5。
Pinia 目前也已经是 vue 官方正式的状态库。适用于 vue2 和 vue3。可以简单的理解成 Pinia 就是 Vuex5。也就是说, Vue3 项目,建议使用Pinia。
Pinia 的优点
更多查看文档…
npm install pinia
//引入stores暴露出的pinia的实例
import pinia from './stores'
createApp(App).use(pinia).mount('#app')
import { createPinia } from "pinia";
const pinia = createPinia()
export default pinia
defineStore 是需要传参数的,
//定义关于counter的store
import {defineStore} from 'pinia'
/*defineStore 是需要传参数的,其中第一个参数是id,就是一个唯一的值,
简单点说就可以理解成是一个命名空间.
第二个参数就是一个对象,里面有三个模块需要处理,第一个是 state,
第二个是 getters,第三个是 actions。
*/
const useCounter = defineStore("counter",{
state:() => ({
count:66,
}),
getters: {
},
actions: {
}
})
//暴露这个useCounter模块
export default useCounter
注意:返回的函数统一使用useXXX作为命名方案,这是约定的规矩。例如上面的useCounter
<template>
<!-- 在页面中直接使用就可以了 不用 .state-->
<div>展示pinia的counter的count值:{{counterStore.count}}</div>
</template>
<script setup>
// 首先需要引入一下我们刚刚创建的store
import useCounter from '../stores/counter'
// 因为是个方法,所以我们得调用一下
const counterStore = useCounter()
</script>
注意:在模板使用 ,不用和vuex一样还要.state,直接点state里面的K
运行效果: 可以用vue3的调试工具看pinia
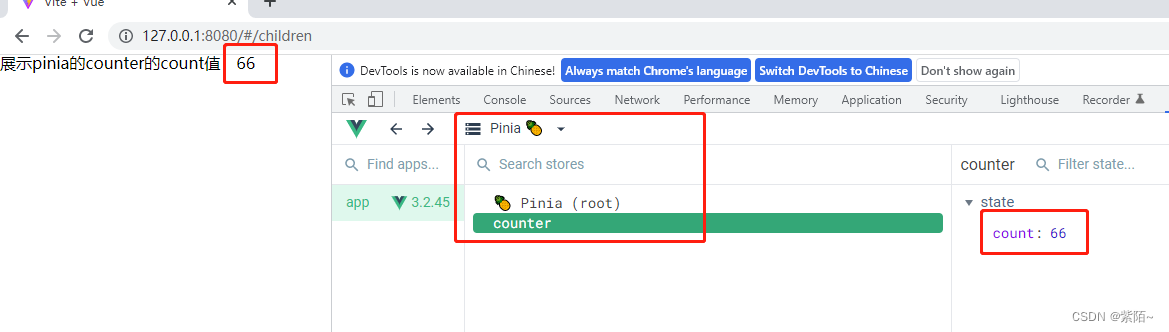
案例需求,点击按钮加一:
一个不解构,一个不解构看看区别。
<template>
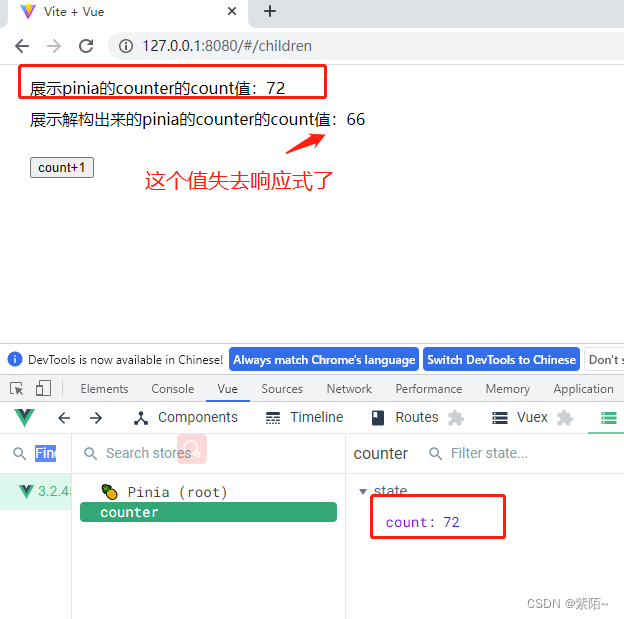
<div>展示pinia的counter的count值:{{counterStore.count}}</div>
<div>展示解构出来的pinia的counter的count值:{{count}}</div>
<button @click="addCount">count+1</button>
</template>
<script setup>
import useCounter from '../stores/counter'
const counterStore = useCounter()
const {count} = counterStore
function addCount(){
//这里可以直接操作count,这就是pinia好处,在vuex还要commit在mutaitions修改数据
counterStore.count++
}
<script/>
在 vuex 里面是坚决不允许这样子直接操作 state 数据的,pinia是可以的,看看上面的addCount函数直接操作。
运行结果:
解决方案:
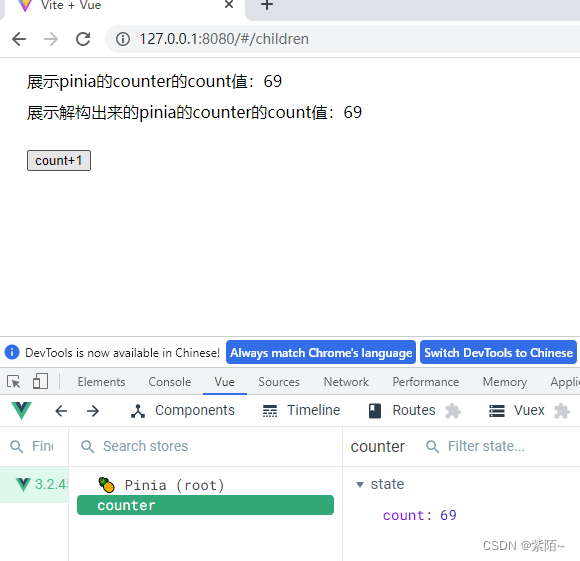
pinia提供了一个函数storeToRefs解决。引用官方API storeToRef 作用就是把结构的数据使用ref做代理
import {storeToRefs} from 'pinia'
const counterStore = useCounter()
const {count} = storeToRefs(counterStore)
现在数据都是响应式的了
重新新建一个user模块
stores/user.js
//定义一个关于user的store
import {defineStore} from 'pinia'
const useUser = defineStore("user",{
state:()=>({
name:"紫陌",
age:18
})
})
export default useUser
组件中修改数据:
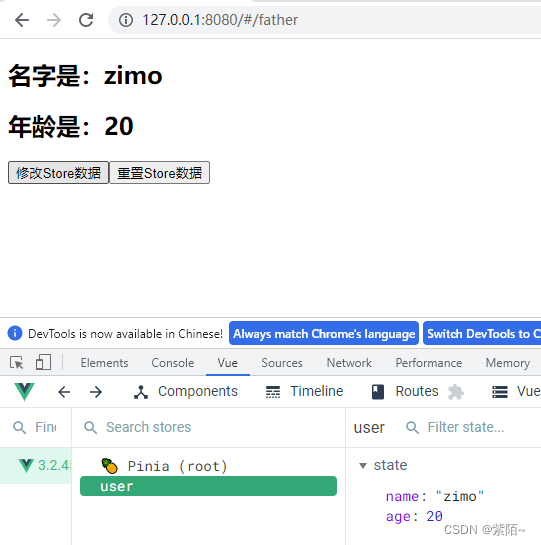
**第一种方法:**点击按钮修改数据,这种方法是最直接的修改数据
<template>
<div>
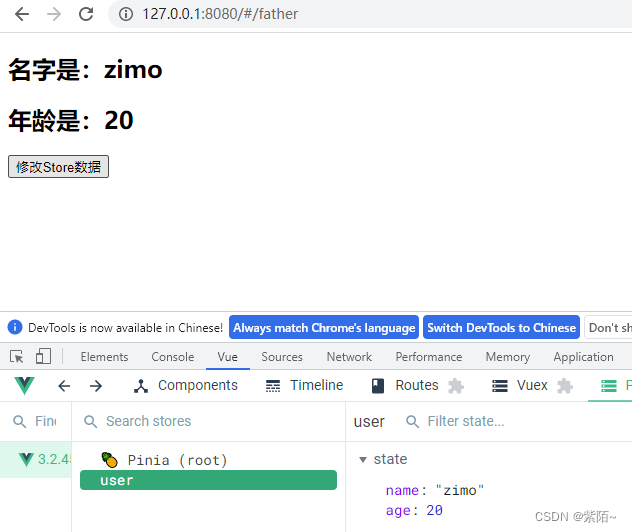
<h2>名字是:{{name}}</h2>
<h2>年龄是:{{age}}</h2>
<button @click="updateStore">修改Store数据</button>
</div>
</template>
<script setup>
import useUser from '../stores/user'
import {storeToRefs} from 'pinia'
const userStore = useUser()
const {name,age} = storeToRefs(userStore)
function updateStore(){
//一个个的修改状态
userStore.name = "zimo"
userStore.age = 20
}
效果:点击也修改了
第二种方法:$patch函数修改
function updateStore(){
//一个个的修改状态
// userStore.name = "zimo"
// userStore.age = 20
// 一次性修改多个状态
userStore.$patch({
name:"zimo",
age:20
})
}
这个方式也可以,效果一样。
第三种方法:$state 方式(这个是替换的方式。)这个基本不用,这里就不多说。可以看查阅文档。
第四种方法:$reset()函数是重置state数据的
新增一个重置按钮:
function resetStore(){
userStore.$reset()
}
运行结果:点击了修改数据按钮之后在点重置按钮就恢复原始的数据。
getters 类似于 vue 里面的计算属性,可以对已有的数据进行修饰。不管调用多少次,getters中的函数只会执行一次,且都会缓存。
//定义关于counter的store
import {defineStore} from 'pinia'
const useCounter = defineStore("counter",{
state:() => ({
count:66,
}),
getters:{
//基本使用
doubleCount(state) {
return state.count * 2
},
},
})
//暴露这个useCounter模块
export default useCounter
组件中:
<div>
<h1>getters的使用</h1>
<h2>doubleCount:{{counterStore.doubleCount}}</h2>
</div>
运行效果:
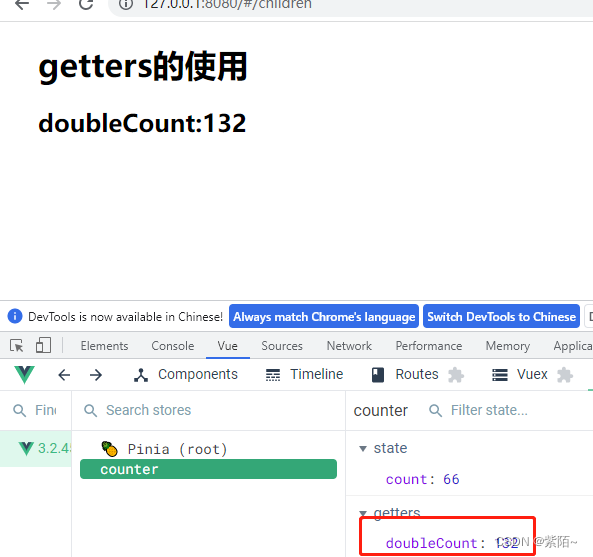
这样就是最基本的使用了。
couter模块:
getters:{
//基本使用
doubleCount(state) {
return state.count * 2
},
//一个getter引入另外一个getter
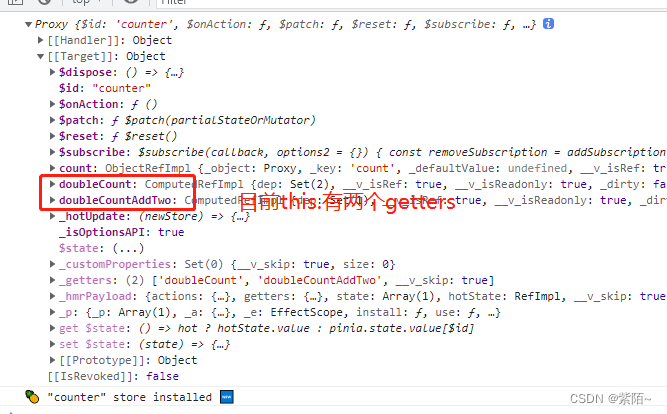
doubleCountAddTwo(){
console.log(this);
//this.是store实例
return this.doubleCount + 2
}
},
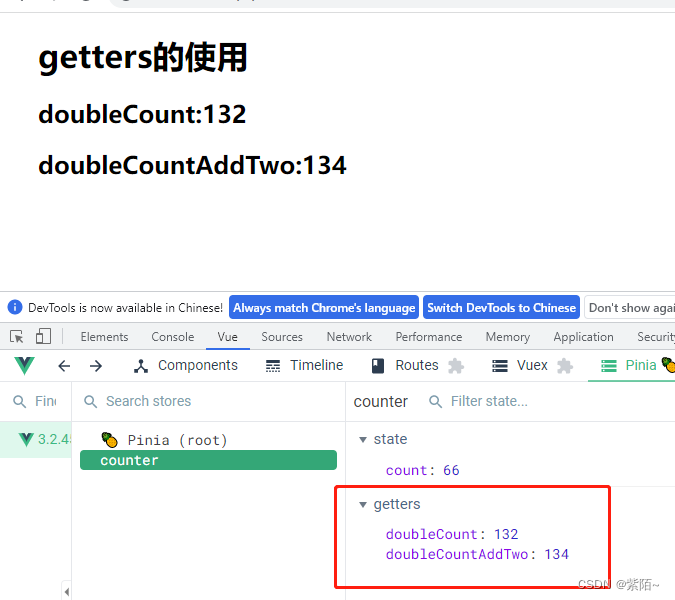
组件中使用:
<div>
<h1>getters的使用</h1>
<h2>doubleCount:{{counterStore.doubleCount}}</h2>
<h2>doubleCountAddTwo:{{counterStore.doubleCountAddTwo}}</h2>
</div>
运行效果并且看看打印的this:
3.getters中用别的store中的数据
在counter模块中拿user模块的store数据。
count模块:
//定义关于counter的store
import {defineStore} from 'pinia'
import useUser from "./user"
const useCounter = defineStore("counter",{
state:() => ({
count:66,
}),
getters:{
//基本使用
doubleCount(state) {
return state.count * 2
},
//一个getter引入另外一个getter
doubleCountAddTwo(){
console.log(this);
//this.是store实例
return this.doubleCount + 2
},
//getters中用别的store中的数据
showMessage(state){
console.log(state);
console.log(this)
//获取user信息,拿到useUser模块
const userStore = useUser()
//拼接信息
return `name:${userStore.name}--count:${state.count}`
}
},
})
//暴露这个useCounter模块
export default useCounter
注意:要引入user模块
组件中:
<div>
<h1>getters的使用</h1>
<h2>doubleCount:{{counterStore.doubleCount}}</h2>
<h2>doubleCountAddTwo:{{counterStore.doubleCountAddTwo}}</h2>
<h2>showMessage:{{counterStore.showMessage}}</h2>
</div>
运行结果:
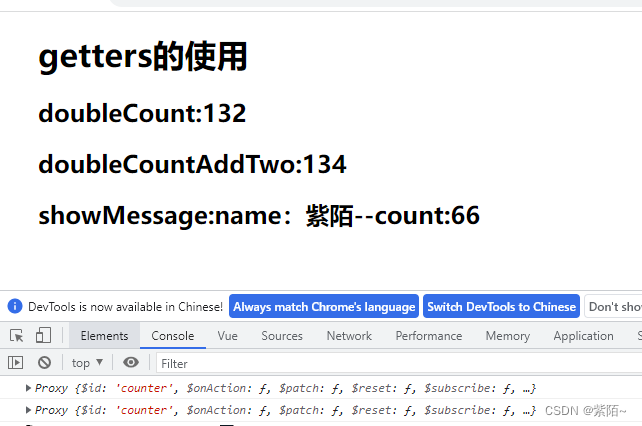
注意:我打印了this和store,他们都是当前这这个模块的实例
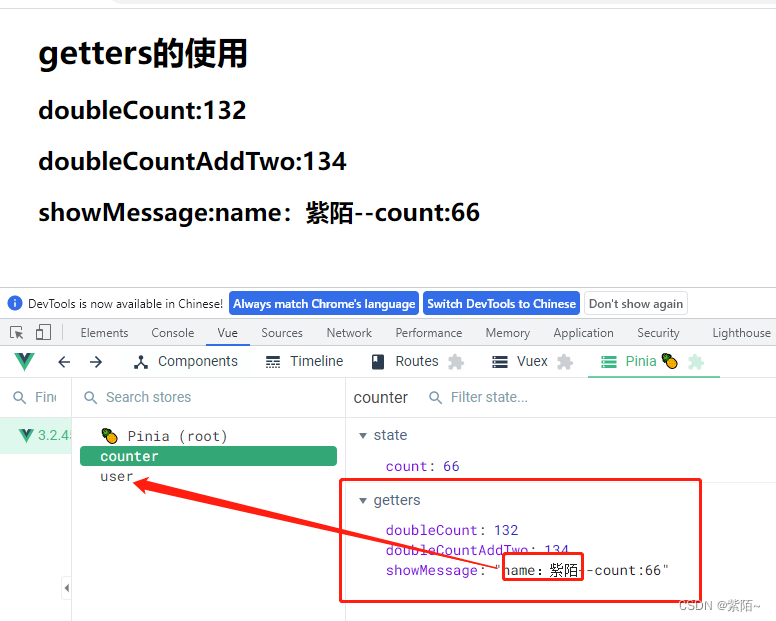
这样就在counter模块拿到了user模块的数据了。
actions 是可以处理同步,也可以处理异步,同步的话相对来说简单一点.actions类似methods
//定义关于counter的store
import {defineStore} from 'pinia'
const useCounter = defineStore("counter",{
state:() => ({
count:66,
}),
actions:{
increment(state){
//actions没有state,只能通过this拿store,这里打印
console.log(state);
this.count++
},
incrementNum(num){
this.count += num
}
}
})
//暴露这个useCounter模块
export default useCounter
组件中:
actions函数在组件中使用
<div>
<h1>actions的使用</h1>
<h2>count的事值:{{counterStore.count}}</h2>
<button @click="changeState">count+1</button>
<button @click="incrementNum">count+20</button>
</div>
<script setup>
import useCounter from '../stores/counter'
const counterStore = useCounter()
function changeState(){
counterStore.increment()
}
function incrementNum(){
counterStore.incrementNum(20)
}
</script>
运行结果并且看看state是什么
初始值是66,点了一次加1和点了一次加20
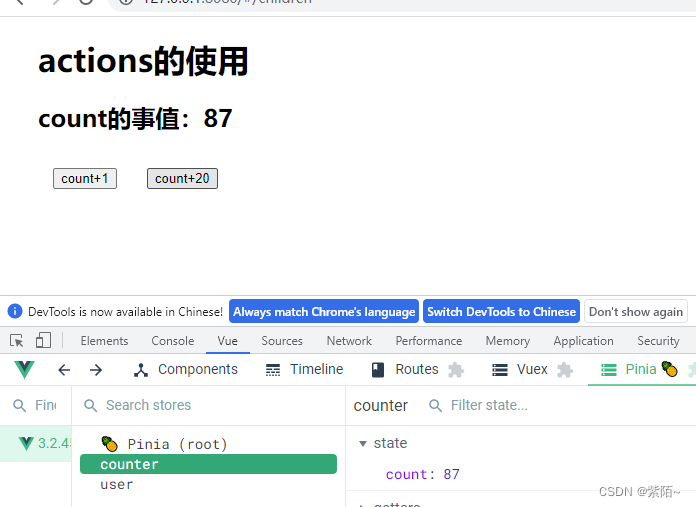
注意:state的结果是undefined 所以actions只能通过this访问store。getter的话state和this都能访问。
在 actions 处理异步的时候呢,我们一般是与 async 和 await 连用。
counter模块: 这里大致演示,具体还看自己怎么使用。
state:() => ({
count:66,
list:[]
}),
actions:{
//大概演示这个异步流程
async axiosData(){
const res = await fetch("http://-----------------")
if(code ==200){
//收到数据保存到store
this.list = res.data.list
return "ok"
}
}
}
组件使用:
<template>
<!-- 遍历store的数据 -->
<div v-for="item in counterStore.list"></div>
</template>
<script setup>
import useCounter from '../stores/counter'
const counterStore = useCounter()
counterStore.axiosData().then(res =>{
console.log("成功",res);
})
</script>
就这样可以啦!!!
是不是比vuex简洁很多。。。
pinia支持扩展插件
我们想实现数据持久化
npm i pinia-plugin-persist
export const useUserStore = defineStore({
state () {
return {
count: 0,
num: 101,
list: [1, 2, 3, 4 ]
}
},
persist: {
enabled: true, // 开启缓存 默认会存储在本地localstorage
storage: sessionStorage, // 缓存使用方式
paths:[] // 需要缓存键
}
})
效果:

文章有写的不当的地方,欢迎指正修改。如果感觉文章实用对你有帮助,欢迎点赞收藏和关注,你的点赞关注就是我动力,大家一起学习进步。
我正在学习如何使用Nokogiri,根据这段代码我遇到了一些问题:require'rubygems'require'mechanize'post_agent=WWW::Mechanize.newpost_page=post_agent.get('http://www.vbulletin.org/forum/showthread.php?t=230708')puts"\nabsolutepathwithtbodygivesnil"putspost_page.parser.xpath('/html/body/div/div/div/div/div/table/tbody/tr/td/div
总的来说,我对ruby还比较陌生,我正在为我正在创建的对象编写一些rspec测试用例。许多测试用例都非常基础,我只是想确保正确填充和返回值。我想知道是否有办法使用循环结构来执行此操作。不必为我要测试的每个方法都设置一个assertEquals。例如:describeitem,"TestingtheItem"doit"willhaveanullvaluetostart"doitem=Item.new#HereIcoulddotheitem.name.shouldbe_nil#thenIcoulddoitem.category.shouldbe_nilendend但我想要一些方法来使用
我有一个Ruby程序,它使用rubyzip压缩XML文件的目录树。gem。我的问题是文件开始变得很重,我想提高压缩级别,因为压缩时间不是问题。我在rubyzipdocumentation中找不到一种为创建的ZIP文件指定压缩级别的方法。有人知道如何更改此设置吗?是否有另一个允许指定压缩级别的Ruby库? 最佳答案 这是我通过查看rubyzip内部创建的代码。level=Zlib::BEST_COMPRESSIONZip::ZipOutputStream.open(zip_file)do|zip|Dir.glob("**/*")d
类classAprivatedeffooputs:fooendpublicdefbarputs:barendprivatedefzimputs:zimendprotecteddefdibputs:dibendendA的实例a=A.new测试a.foorescueputs:faila.barrescueputs:faila.zimrescueputs:faila.dibrescueputs:faila.gazrescueputs:fail测试输出failbarfailfailfail.发送测试[:foo,:bar,:zim,:dib,:gaz].each{|m|a.send(m)resc
很好奇,就使用rubyonrails自动化单元测试而言,你们正在做什么?您是否创建了一个脚本来在cron中运行rake作业并将结果邮寄给您?git中的预提交Hook?只是手动调用?我完全理解测试,但想知道在错误发生之前捕获错误的最佳实践是什么。让我们理所当然地认为测试本身是完美无缺的,并且可以正常工作。下一步是什么以确保他们在正确的时间将可能有害的结果传达给您? 最佳答案 不确定您到底想听什么,但是有几个级别的自动代码库控制:在处理某项功能时,您可以使用类似autotest的内容获得关于哪些有效,哪些无效的即时反馈。要确保您的提
假设我做了一个模块如下:m=Module.newdoclassCendend三个问题:除了对m的引用之外,还有什么方法可以访问C和m中的其他内容?我可以在创建匿名模块后为其命名吗(就像我输入“module...”一样)?如何在使用完匿名模块后将其删除,使其定义的常量不再存在? 最佳答案 三个答案:是的,使用ObjectSpace.此代码使c引用你的类(class)C不引用m:c=nilObjectSpace.each_object{|obj|c=objif(Class===objandobj.name=~/::C$/)}当然这取决于
我试图在一个项目中使用rake,如果我把所有东西都放到Rakefile中,它会很大并且很难读取/找到东西,所以我试着将每个命名空间放在lib/rake中它自己的文件中,我添加了这个到我的rake文件的顶部:Dir['#{File.dirname(__FILE__)}/lib/rake/*.rake'].map{|f|requiref}它加载文件没问题,但没有任务。我现在只有一个.rake文件作为测试,名为“servers.rake”,它看起来像这样:namespace:serverdotask:testdoputs"test"endend所以当我运行rakeserver:testid时
作为我的Rails应用程序的一部分,我编写了一个小导入程序,它从我们的LDAP系统中吸取数据并将其塞入一个用户表中。不幸的是,与LDAP相关的代码在遍历我们的32K用户时泄漏了大量内存,我一直无法弄清楚如何解决这个问题。这个问题似乎在某种程度上与LDAP库有关,因为当我删除对LDAP内容的调用时,内存使用情况会很好地稳定下来。此外,不断增加的对象是Net::BER::BerIdentifiedString和Net::BER::BerIdentifiedArray,它们都是LDAP库的一部分。当我运行导入时,内存使用量最终达到超过1GB的峰值。如果问题存在,我需要找到一些方法来更正我的代
我正在尝试使用ruby和Savon来使用网络服务。测试服务为http://www.webservicex.net/WS/WSDetails.aspx?WSID=9&CATID=2require'rubygems'require'savon'client=Savon::Client.new"http://www.webservicex.net/stockquote.asmx?WSDL"client.get_quotedo|soap|soap.body={:symbol=>"AAPL"}end返回SOAP异常。检查soap信封,在我看来soap请求没有正确的命名空间。任何人都可以建议我
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。