目录
HOG算法是在2005年由法国Dalal提出。HOG特征作为机器学习目标检测效果最好的特征,在其基础上发展来的DPM算法更是可以成为机器学习在目标检测领域的巅峰之作,连续三年横扫PASCAL VOC。HOG是一种在计算机视觉和图像处理中用来进行物体检测的描述子。通过计算和统计局部区域的梯度方向直方图来构成特征。其主要思想就是在一幅图像中,局部目标的表象和形状能够利用梯度或边缘的方向密度分布来进行描述。其本质是梯度的统计信息,而梯度主要存在于边缘所在的地方。HOG特征具有很多优点,比如它对图像的几何和光学形变都能保持很好的不变性,可以容许行人有一些细微的肢体动作,当然,更大的肢体动作或者别的视角的行人HOG特征的处理并不好,这时候要不增加训练模板,但这会带来更大的训练开销,要不就引入部件模型,变为DPM算法。
SVM 最早是由 Vladimir N. Vapnik 和 Alexey Ya. Chervonenkis 在1963年提出,目前的版本(soft margin)是由 Corinna Cortes 和 Vapnik 在1993年提出,并在1995年发表。深度学习(2012)出现之前,SVM 被认为机器学习中近十几年来最成功,表现最好的算法。
其算法步骤大致如下:
关于HOG和SVM的详细介绍已经原理和数学推导部分,可以参考这些文章。
HOG特征介绍(1)
HOG特征介绍(2)
SVM算法介绍
在目标检测中,常常会对同一个物体检测出多个目标框,而NMS的作用是删除重复框,保留置信度分数最大的框。传统的NMS首先根据类别置信度得分对所有的目标框进行降序排列建表,然后将每个类别中置信度最高的目标框作为可靠的目标框,并分别计算其与剩余目标框的IOU,仅保留IOU小于设定阈值的目标框,以此往复循环直到结束。IOU定义为两个目标框相交面积和面积总和之比。传统的NMS算法还有不同的变种,以适合不同的使用场景,如Soft-NMS,Weighted NMS等NMS算法。基本的NMS算法过程如下:
输入: 候选边界框集合TB(每个候选框都有一个置信度)、IoU阈值N
输出: 最终的边界框集合B(初始为空集合)
具体算法介绍可以参考下面的文章:
NMS算法介绍
数据集是INRIA 数据集,该数据集使用了软链接,需要在Linux系统或者wsl(适用于Windows的Linux的子系统)下解压。该数据集中训练集有正样本 614 张(包含 1237个行人),负样本 1218张;测试集有正样本 288张(包含 589个行人),负样本 453张。更详细的介绍可以看这里。同样,想要在Windows下使用的话,这里这位作者提供了自己整理的Windows版本。
首先需要提取图片的HOG特征
def hog_descriptor(image):
if (image.max()-image.min()) != 0:
image = (image - image.min()) / (image.max() - image.min())
image *= 255 #这两行是对图像做归一化
image = image.astype(np.uint8)
hog = cv2.HOGDescriptor((64, 128), (16, 16), (8, 8), (8, 8), 9)
hog_feature = hog.compute(image) #提取HOG特征
return hog_feature
在这里进行图像归一化是为了减小由于局部光照变化以及前景背景对比度变化带来的影响。
接下来就是正文内容了,先导入图像,我用的数据集上面介绍的那个Windows版本的。
#导入图像
poslist = os.listdir('D:/DataSet/INRIADATA/INRIADATA/normalized_images/train/pos')
neglist = os.listdir('D:/DataSet/INRIADATA/INRIADATA/normalized_images/train/neg')
testlist = os.listdir('D:/DataSet/INRIADATA/INRIADATA/normalized_images/test/pos')
testnlist = os.listdir('D:/DataSet/INRIADATA/INRIADATA/original_images/test/neg')
显然,poslist和neglist读取的是训练集,testlist和testnlist读取的是测试集。接下来,正式读取训练集的图像,将每一张图像的HOG特征都加入列表hog_list中,标签加入列表label_list中。并且,我将负样本每张图像都随机截取了10张标准大小的也就是64×128的图像。
for i in range(len(poslist)):
posimg = io.imread(osp.join('D:/DataSet/INRIADATA/INRIADATA/normalized_images/train/pos',poslist[i]))
posimg = cv2.cvtColor(posimg,cv2.COLOR_RGBA2BGR)
#所用图像已经经过标准化
posimg = cv2.resize(posimg, (64, 128), interpolation=cv2.INTER_NEAREST)
pos_hog = hog_descriptor(posimg)
hog_list.append(pos_hog)
label_list.append(1)
for i in range(len(neglist)):
negimg = io.imread(osp.join('D:/DataSet/INRIADATA/INRIADATA/normalized_images/train/neg',neglist[i]))
negimg = cv2.cvtColor(negimg, cv2.COLOR_RGBA2BGR)
#在每张negimg图像中截取10张标准大小的图片作为负样本
for j in range(10):
y = int(random.random() * (negimg.shape[0] - 128))
x = int(random.random() * (negimg.shape[1] - 64))
negimgs = negimg[y:y + 128, x:x + 64]
negimgs = cv2.resize(negimgs, (64, 128), interpolation=cv2.INTER_NEAREST)
neg_hog = hog_descriptor(negimgs)
hog_list.append(neg_hog)
label_list.append(0)
接下来就是训练SVM模型,这里换成别的,比如LogisticRegression模型也都是可以的。
#训练SVM
clf = SVC(C=1.0, gamma='auto', kernel='rbf', probability=True)
clf.fit(hog_list.squeeze(), label_list.squeeze())
joblib.dump(clf, "D:/python work/Hog+SVM行人检测/trained_svm.m")#保存训练好的模型
同样提取HOG特征和标签列表的制作也要对训练集中的图像来一次。这里就先不放了,完整代码在最后面给出。之后就是使用之前训练好的模型在测试集上测试,并绘制PR、ROC曲线计算AUC值,AP值。
clf = joblib.load("D:/python work/Hog+SVM行人检测/trained_svm.m")
#对训练集进行预测并绘制PR、ROC曲线计算AUC值
prob = clf.predict_proba(test_hog.squeeze())[:, 1]
precision, recall, thresholds_1 = metrics.precision_recall_curve(test_label.squeeze(), prob)
plt.figure(figsize=(20, 20), dpi=100)
plt.plot(precision, recall, c='red')
plt.scatter(precision, recall, c='blue')
plt.xlabel("precision", fontdict={'size': 16})
plt.ylabel("recall", fontdict={'size': 16})
plt.title("PR_curve", fontdict={'size': 20})
plt.savefig('D:/python work/Hog+SVM行人检测/PR.png',dpi=300)
Ap=metrics.average_precision_score(test_label.squeeze(), prob)
fpr, tpr, thresholds_2 = metrics.roc_curve(test_label.squeeze(), prob, pos_label=1)
plt.figure(figsize=(20, 20), dpi=100)
plt.plot(fpr, tpr, c='red')
plt.scatter(fpr, tpr, c='blue')
plt.xlabel("FPR", fontdict={'size': 16})
plt.ylabel("TPR", fontdict={'size': 16})
plt.title("ROC_curve", fontdict={'size': 20})
plt.savefig('D:/python work/Hog+SVM行人检测/ROC.png', dpi=300)
AUC=metrics.roc_auc_score(test_label.squeeze(), prob)
print(AUC)
print(Ap)
结果最后如下所示:
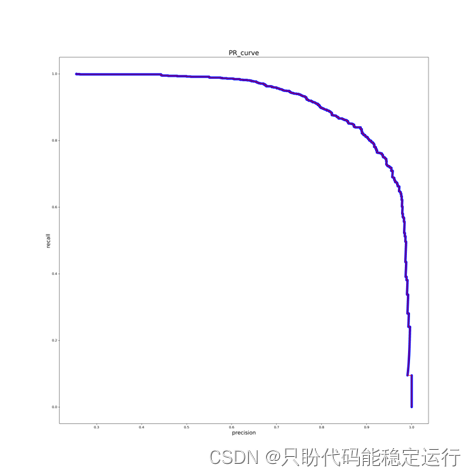
PR曲线 |
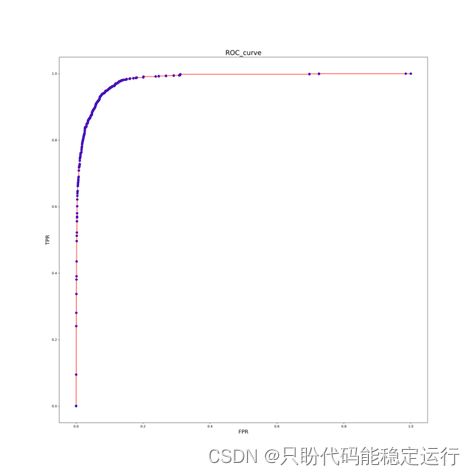
ROC曲线 |
首先是编写用于提取HOG特征的函数,这个已经在前文中讲述过了。再就是要通过原数据集的annotations文件夹中的关于训练集正样本图像中行人的大小计算适合的window大小。
#首先通过Train中的标准的box大小计算出适合的box大小
box_list = []
ANN = os.listdir('D:/tmp-from-ubt/INRIAPerson/Train/annotations')
flag = "(Xmax, Ymax)"
for i in range(len(ANN)):
for line in open('D:/tmp-from-ubt/INRIAPerson/Train/annotations/'+ANN[i],encoding="GBK"):
if flag in line:
boxsize = line.split(flag)
boxsize = str(boxsize[1])
boxsize = boxsize.replace("(","")
boxsize = boxsize.replace(",","")
boxsize = boxsize.replace(")","")
boxsize = boxsize.replace("-","")
boxsize = boxsize.replace(":","")
boxsize = boxsize.split()
box = (float(boxsize[2])-float(boxsize[0]) ,float(boxsize[3])-float(boxsize[1]))
box_list.append(box)
box_list = np.array(box_list)
minlist = np.min(box_list,axis=0)
maxlist = np.max(box_list,axis=0)
这里面的数据集INRIAPerson是原作者Dalal的那个用软链接的数据集,这是我当时为了练习WSL采用的,用Windows版本也是可以的。将所有行人大小提取出来后,算得最小的行人框和最大的行人框分别为(23,47)和(465,831)。因此,我设计的标准行人框是64×128的,scale的倍数应当从1变化到7,才是适合所有行人大小的目标框大小。将目标框在测试集正样本的原始图像上滑动,步长为20个像素。
对每张图像截取window,并将window中的图像用之前训练好的模型检测,将框的坐标(左上角和右下角)加入边框列表,注意最后只保留了概率prob大于0.99的边框,将这些边框都传入NMS算法中(这里是mynms)。注意到给图像画框是选择了从第101个样本到最后,这里推荐只对十几二十几张图片画框就可以了,因为代码运行时间比较长,所以我最后也在i=150的时候就跳出了。
clf = joblib.load("D:/python work/Hog+SVM行人检测/trained_svm.m")
imglist = os.listdir('D:/DataSet/INRIADATA/INRIADATA/original_images/test/pos')
for i in range(101,len(imglist)):
img = io.imread(osp.join('D:/DataSet/INRIADATA/INRIADATA/original_images/test/pos', imglist[i]))
img = cv2.cvtColor(img, cv2.COLOR_RGBA2BGR)
h,w,c= img.shape
patch_list = []
hog_feature = []
box_list = []
for j in range(minscale,maxscale+1,1):
winsize = [j*64,j*128]
for m in range(0,h-winsize[1],20):
for n in range(0,w-winsize[0],20):
patch = img[m:m+winsize[1],n:n+winsize[0]]
patch = cv2.resize(patch, (64,128), interpolation = cv2.INTER_NEAREST)
boxcoord = (m,n,m+winsize[1],n+winsize[0])
hogfea = hog_descriptor(patch)
hog_feature.append(hogfea)
box_list.append(boxcoord)
patch_list.append(patch)
hog_feature = np.array(hog_feature).squeeze()
box_list = np.array(box_list)
prob = clf.predict_proba(hog_feature)[:, 1]
mask = (prob>= 0.99)
box_list = box_list[mask]
prob = prob[mask]
boxzhong = mynms(box_list,prob)
for k in range(len(boxzhong)):
cv2.rectangle(img, (boxzhong[k][1], boxzhong[k][0]), (boxzhong[k][3], boxzhong[k][2]),(0, 0, 255),3)
cv2.imwrite('D:/jupyterwork/result/'+imglist[i]+".jpg",img)
print(str(i))
if i == 150:
break
接下来展示一下具体的NMS算法如何实现。这里我阈值选择的是0.8。
def mynms(box_list,prob_list,threshold=0.8):
x1 = box_list[:,0]
y1 = box_list[:,1]
x2 = box_list[:,2]
y2 = box_list[:,3]
areas = (x2-x1+1)*(y2-y1+1)
box_result = []
flag = []
index = prob_list.argsort()[::-1] #想要从大到小排序
while index.size>0:
i = index[0] #第一个,也就是概率最大(得分最高)的那个框
flag.append(i)
x11 = np.maximum(x1[i], x1[index[1:]]) # calculate the points of overlap
y11 = np.maximum(y1[i], y1[index[1:]])
x22 = np.minimum(x2[i], x2[index[1:]])
y22 = np.minimum(y2[i], y2[index[1:]])
w = np.maximum(0, x22 - x11 + 1)
h = np.maximum(0, y22 - y11 + 1)
overlaps = w * h
ious = overlaps / (areas[i] + areas[index[1:]] - overlaps)
#idx = np.where(ious < threshold)[0]
index = np.delete(index,np.concatenate(([0],np.where(ious < threshold)[0])))
#index = index[idx + 1]
return box_list[flag].astype("int")
注意一下,代码中间有些注释什么的是在调试过程中加的,加不加都无所谓。
目标检测
import cv2
import os
import numpy as np
import os.path as osp
from skimage import io
import random
from sklearn import metrics
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import joblib
#对数据进行处理,提取正负样本的Hog特征
#计算传入图像的HOG特征
def hog_descriptor(image):
if (image.max()-image.min()) != 0:
image = (image - image.min()) / (image.max() - image.min())
image *= 255
image = image.astype(np.uint8)
hog = cv2.HOGDescriptor((64, 128), (16, 16), (8, 8), (8, 8), 9)
hog_feature = hog.compute(image)
return hog_feature
#导入图像
poslist = os.listdir('D:/DataSet/INRIADATA/INRIADATA/normalized_images/train/pos')
neglist = os.listdir('D:/DataSet/INRIADATA/INRIADATA/normalized_images/train/neg')
testlist = os.listdir('D:/DataSet/INRIADATA/INRIADATA/normalized_images/test/pos')
testnlist = os.listdir('D:/DataSet/INRIADATA/INRIADATA/original_images/test/neg')
#获得正样本和负样本的HOG特征,并标记
hog_list = []
label_list = []
print("正样本图像有"+str(len(poslist)))
print("负样本原始图像有"+str(len(neglist))+",每个原始图像提供十个负样本")
for i in range(len(poslist)):
posimg = io.imread(osp.join('D:/DataSet/INRIADATA/INRIADATA/normalized_images/train/pos',poslist[i]))
posimg = cv2.cvtColor(posimg,cv2.COLOR_RGBA2BGR)
#所用图像已经经过标准化
posimg = cv2.resize(posimg, (64, 128), interpolation=cv2.INTER_NEAREST)
pos_hog = hog_descriptor(posimg)
hog_list.append(pos_hog)
label_list.append(1)
for i in range(len(neglist)):
negimg = io.imread(osp.join('D:/DataSet/INRIADATA/INRIADATA/normalized_images/train/neg',neglist[i]))
negimg = cv2.cvtColor(negimg, cv2.COLOR_RGBA2BGR)
#在每张negimg图像中截取10张标准大小的图片作为负样本
for j in range(10):
y = int(random.random() * (negimg.shape[0] - 128))
x = int(random.random() * (negimg.shape[1] - 64))
negimgs = negimg[y:y + 128, x:x + 64]
negimgs = cv2.resize(negimgs, (64, 128), interpolation=cv2.INTER_NEAREST)
neg_hog = hog_descriptor(negimgs)
hog_list.append(neg_hog)
label_list.append(0)
print(type(hog_list[10]))
print(type(hog_list[-10]))
hog_list = np.float32(hog_list)
label_list = np.int32(label_list).reshape(len(label_list),1)
#训练SVM,并在Test上测试
clf = SVC(C=1.0, gamma='auto', kernel='rbf', probability=True)
clf.fit(hog_list.squeeze(), label_list.squeeze())
joblib.dump(clf, "D:/python work/Hog+SVM行人检测/trained_svm.m")
#提取训练集样本和标签
test_hog = []
test_label = []
for i in range(len(testlist)):
testimg = io.imread(osp.join('D:/DataSet/INRIADATA/INRIADATA/normalized_images/test/pos', testlist[i]))
testimg = cv2.cvtColor(testimg, cv2.COLOR_RGBA2BGR)
testimg = cv2.resize(testimg, (64, 128), interpolation=cv2.INTER_NEAREST)
testhog = hog_descriptor(testimg)
test_hog.append(testhog)
test_label.append(1)
for i in range(len(testnlist)):
testnegimg = io.imread(osp.join('D:/DataSet/INRIADATA/INRIADATA/original_images/test/neg',testnlist[i]))
testnegimg = cv2.cvtColor(testnegimg, cv2.COLOR_RGBA2BGR)
#在每张negimg图像中截取10张标准大小的图片作为负样本
for j in range(10):
y = int(random.random() * (testnegimg.shape[0] - 128))
x = int(random.random() * (testnegimg.shape[1] - 64))
testnegimgs = testnegimg[y:y + 128, x:x + 64]
testnegimgs = cv2.resize(testnegimgs, (64, 128), interpolation=cv2.INTER_NEAREST)
testneg_hog = hog_descriptor(testnegimgs)
test_hog.append(testneg_hog)
test_label.append(0)
test_hog = np.float32(test_hog)
test_label = np.int32(test_label).reshape(len(test_label),1)
#可以导入训练后的SVM
clf = joblib.load("D:/python work/Hog+SVM行人检测/trained_svm.m")
#对训练集进行预测并绘制PR、ROC曲线计算AUC值
prob = clf.predict_proba(test_hog.squeeze())[:, 1]
precision, recall, thresholds_1 = metrics.precision_recall_curve(test_label.squeeze(), prob)
plt.figure(figsize=(20, 20), dpi=100)
plt.plot(precision, recall, c='red')
plt.scatter(precision, recall, c='blue')
plt.xlabel("precision", fontdict={'size': 16})
plt.ylabel("recall", fontdict={'size': 16})
plt.title("PR_curve", fontdict={'size': 20})
plt.savefig('D:/python work/Hog+SVM行人检测/PR.png',dpi=300)
Ap=metrics.average_precision_score(test_label.squeeze(), prob)
fpr, tpr, thresholds_2 = metrics.roc_curve(test_label.squeeze(), prob, pos_label=1)
plt.figure(figsize=(20, 20), dpi=100)
plt.plot(fpr, tpr, c='red')
plt.scatter(fpr, tpr, c='blue')
plt.xlabel("FPR", fontdict={'size': 16})
plt.ylabel("TPR", fontdict={'size': 16})
plt.title("ROC_curve", fontdict={'size': 20})
plt.savefig('D:/python work/Hog+SVM行人检测/ROC.png', dpi=300)
AUC=metrics.roc_auc_score(test_label.squeeze(), prob)
print(AUC)
print(Ap)
给图像画框
import cv2
import os
import numpy as np
import os.path as osp
from skimage import io
import random
from sklearn import metrics
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import joblib
import math
def hog_descriptor(image):
if (image.max()-image.min()) != 0:
image = (image - image.min()) / (image.max() - image.min())
image *= 255
image = image.astype(np.uint8)
hog = cv2.HOGDescriptor((64, 128), (16, 16), (8, 8), (8, 8), 9)
hog_feature = hog.compute(image)
return hog_feature
def mynms(box_list,prob_list,threshold=0.8):
x1 = box_list[:,0]
y1 = box_list[:,1]
x2 = box_list[:,2]
y2 = box_list[:,3]
areas = (x2-x1+1)*(y2-y1+1)
box_result = []
flag = []
index = prob_list.argsort()[::-1] #想要从大到小排序
while index.size>0:
i = index[0]
flag.append(i)
x11 = np.maximum(x1[i], x1[index[1:]]) # calculate the points of overlap
y11 = np.maximum(y1[i], y1[index[1:]])
x22 = np.minimum(x2[i], x2[index[1:]])
y22 = np.minimum(y2[i], y2[index[1:]])
w = np.maximum(0, x22 - x11 + 1)
h = np.maximum(0, y22 - y11 + 1)
overlaps = w * h
ious = overlaps / (areas[i] + areas[index[1:]] - overlaps)
#idx = np.where(ious < threshold)[0]
index = np.delete(index,np.concatenate(([0],np.where(ious < threshold)[0])))
#index = index[idx + 1]
return box_list[flag].astype("int")
#首先通过Train中的标准的box大小计算出适合的box大小
box_list = []
ANN = os.listdir('D:/tmp-from-ubt/INRIAPerson/Train/annotations')
flag = "(Xmax, Ymax)"
for i in range(len(ANN)):
for line in open('D:/tmp-from-ubt/INRIAPerson/Train/annotations/'+ANN[i],encoding="GBK"):
if flag in line:
boxsize = line.split(flag)
boxsize = str(boxsize[1])
boxsize = boxsize.replace("(","")
boxsize = boxsize.replace(",","")
boxsize = boxsize.replace(")","")
boxsize = boxsize.replace("-","")
boxsize = boxsize.replace(":","")
boxsize = boxsize.split()
box = (float(boxsize[2])-float(boxsize[0]) ,float(boxsize[3])-float(boxsize[1]))
box_list.append(box)
box_list = np.array(box_list)
minlist = np.min(box_list,axis=0)
maxlist = np.max(box_list,axis=0)
"""
print(minlist)
print(maxlist)
"""
minscale = min(minlist[0]/64,minlist[1]/128)
maxscale = min(maxlist[0]/64,maxlist[1]/128)
"""
print(minscale)
print(maxscale)
"""
minscale = math.ceil(minscale)
maxscale = math.ceil(maxscale)
print(minscale)
print(maxscale)
clf = joblib.load("D:/python work/Hog+SVM行人检测/trained_svm.m")
imglist = os.listdir('D:/DataSet/INRIADATA/INRIADATA/original_images/test/pos')
for i in range(101,len(imglist)):
img = io.imread(osp.join('D:/DataSet/INRIADATA/INRIADATA/original_images/test/pos', imglist[i]))
img = cv2.cvtColor(img, cv2.COLOR_RGBA2BGR)
h,w,c= img.shape
patch_list = []
hog_feature = []
box_list = []
for j in range(minscale,maxscale+1,1):
winsize = [j*64,j*128]
for m in range(0,h-winsize[1],20):
for n in range(0,w-winsize[0],20):
patch = img[m:m+winsize[1],n:n+winsize[0]]
patch = cv2.resize(patch, (64,128), interpolation = cv2.INTER_NEAREST)
boxcoord = (m,n,m+winsize[1],n+winsize[0])
hogfea = hog_descriptor(patch)
hog_feature.append(hogfea)
box_list.append(boxcoord)
patch_list.append(patch)
hog_feature = np.array(hog_feature).squeeze()
box_list = np.array(box_list)
prob = clf.predict_proba(hog_feature)[:, 1]
mask = (prob>= 0.99)
box_list = box_list[mask]
prob = prob[mask]
boxzhong = mynms(box_list,prob)
for k in range(len(boxzhong)):
cv2.rectangle(img, (boxzhong[k][1], boxzhong[k][0]), (boxzhong[k][3], boxzhong[k][2]),(0, 0, 255),3)
cv2.imwrite('D:/jupyterwork/result/'+imglist[i]+".jpg",img)
print(str(i))
if i == 150:
break
print("结束")
https://blog.csdn.net/weixin_44505390/article/details/107161828
https://zhuanlan.zhihu.com/p/40960756
https://zhuanlan.zhihu.com/p/74591258
https://zhuanlan.zhihu.com/p/405527616
https://blog.csdn.net/c2250645962/article/details/106476147
关闭。这个问题是opinion-based.它目前不接受答案。想要改进这个问题?更新问题,以便editingthispost可以用事实和引用来回答它.关闭4年前。Improvethisquestion我想在固定时间创建一系列低音和高音调的哔哔声。例如:在150毫秒时发出高音调的蜂鸣声在151毫秒时发出低音调的蜂鸣声200毫秒时发出低音调的蜂鸣声250毫秒的高音调蜂鸣声有没有办法在Ruby或Python中做到这一点?我真的不在乎输出编码是什么(.wav、.mp3、.ogg等等),但我确实想创建一个输出文件。
我收到这个错误:RuntimeError(自动加载常量Apps时检测到循环依赖当我使用多线程时。下面是我的代码。为什么会这样?我尝试多线程的原因是因为我正在编写一个HTML抓取应用程序。对Nokogiri::HTML(open())的调用是一个同步阻塞调用,需要1秒才能返回,我有100,000多个页面要访问,所以我试图运行多个线程来解决这个问题。有更好的方法吗?classToolsController0)app.website=array.join(',')putsapp.websiteelseapp.website="NONE"endapp.saveapps=Apps.order("
我有一个用户工厂。我希望默认情况下确认用户。但是鉴于unconfirmed特征,我不希望它们被确认。虽然我有一个基于实现细节而不是抽象的工作实现,但我想知道如何正确地做到这一点。factory:userdoafter(:create)do|user,evaluator|#unwantedimplementationdetailshereunlessFactoryGirl.factories[:user].defined_traits.map(&:name).include?(:unconfirmed)user.confirm!endendtrait:unconfirmeddoenden
这个问题在这里已经有了答案:关闭10年前。PossibleDuplicate:Pythonconditionalassignmentoperator对于这样一个简单的问题表示歉意,但是谷歌搜索||=并不是很有帮助;)Python中是否有与Ruby和Perl中的||=语句等效的语句?例如:foo="hey"foo||="what"#assignfooifit'sundefined#fooisstill"hey"bar||="yeah"#baris"yeah"另外,类似这样的东西的通用术语是什么?条件分配是我的第一个猜测,但Wikipediapage跟我想的不太一样。
什么是ruby的rack或python的Java的wsgi?还有一个路由库。 最佳答案 来自Python标准PEP333:Bycontrast,althoughJavahasjustasmanywebapplicationframeworksavailable,Java's"servlet"APImakesitpossibleforapplicationswrittenwithanyJavawebapplicationframeworktoruninanywebserverthatsupportstheservletAPI.ht
华为OD机试题本篇题目:明明的随机数题目输入描述输出描述:示例1输入输出说明代码编写思路最近更新的博客华为od2023|什么是华为od,od薪资待遇,od机试题清单华为OD机试真题大全,用Python解华为机试题|机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为o
我想解析一个已经存在的.mid文件,改变它的乐器,例如从“acousticgrandpiano”到“violin”,然后将它保存回去或作为另一个.mid文件。根据我在文档中看到的内容,该乐器通过program_change或patch_change指令进行了更改,但我找不到任何在已经存在的MIDI文件中执行此操作的库.他们似乎都只支持从头开始创建的MIDI文件。 最佳答案 MIDIpackage会为您完成此操作,但具体方法取决于midi文件的原始内容。一个MIDI文件由一个或多个音轨组成,每个音轨是十六个channel中任何一个上的
C#实现简易绘图工具一.引言实验目的:通过制作窗体应用程序(C#画图软件),熟悉基本的窗体设计过程以及控件设计,事件处理等,熟悉使用C#的winform窗体进行绘图的基本步骤,对于面向对象编程有更加深刻的体会.Tutorial任务设计一个具有基本功能的画图软件**·包括简单的新建文件,保存,重新绘图等功能**·实现一些基本图形的绘制,包括铅笔和基本形状等,学习橡皮工具的创建**·设计一个合理舒适的UI界面**注明:你可能需要先了解一些关于winform窗体应用程序绘图的基本知识,以及关于GDI+类和结构的知识二.实验环境Windows系统下的visualstudio2017C#窗体应用程序三.
本文主要介绍在使用Selenium进行自动化测试或者任务时,对于使用了iframe的页面,如何定位iframe中的元素文章目录场景描述解决方案具体代码场景描述当我们在使用Selenium进行自动化测试的时候,可能会遇到一些界面或者窗体是使用HTML的iframe标签进行承载的。对于iframe中的标签,如果直接查找是无法找到的,会抛出没有找到元素的异常。比如近在咫尺的例子就是,CSDN的登录窗体就是使用的iframe,大家可以尝试通过F12开发者模式查看到的tag_name,class_name,id或者xpath来定位中的页面元素,会抛出NoSuchElementException异常。解决
MIMO技术的优缺点优点通过下面三个增益来总体概括:阵列增益。阵列增益是指由于接收机通过对接收信号的相干合并而活得的平均SNR的提高。在发射机不知道信道信息的情况下,MIMO系统可以获得的阵列增益与接收天线数成正比复用增益。在采用空间复用方案的MIMO系统中,可以获得复用增益,即信道容量成倍增加。信道容量的增加与min(Nt,Nr)成正比分集增益。在采用空间分集方案的MIMO系统中,可以获得分集增益,即可靠性性能的改善。分集增益用独立衰落支路数来描述,即分集指数。在使用了空时编码的MIMO系统中,由于接收天线或发射天线之间的间距较远,可认为它们各自的大尺度衰落是相互独立的,因此分布式MIMO